Blogs on OLake
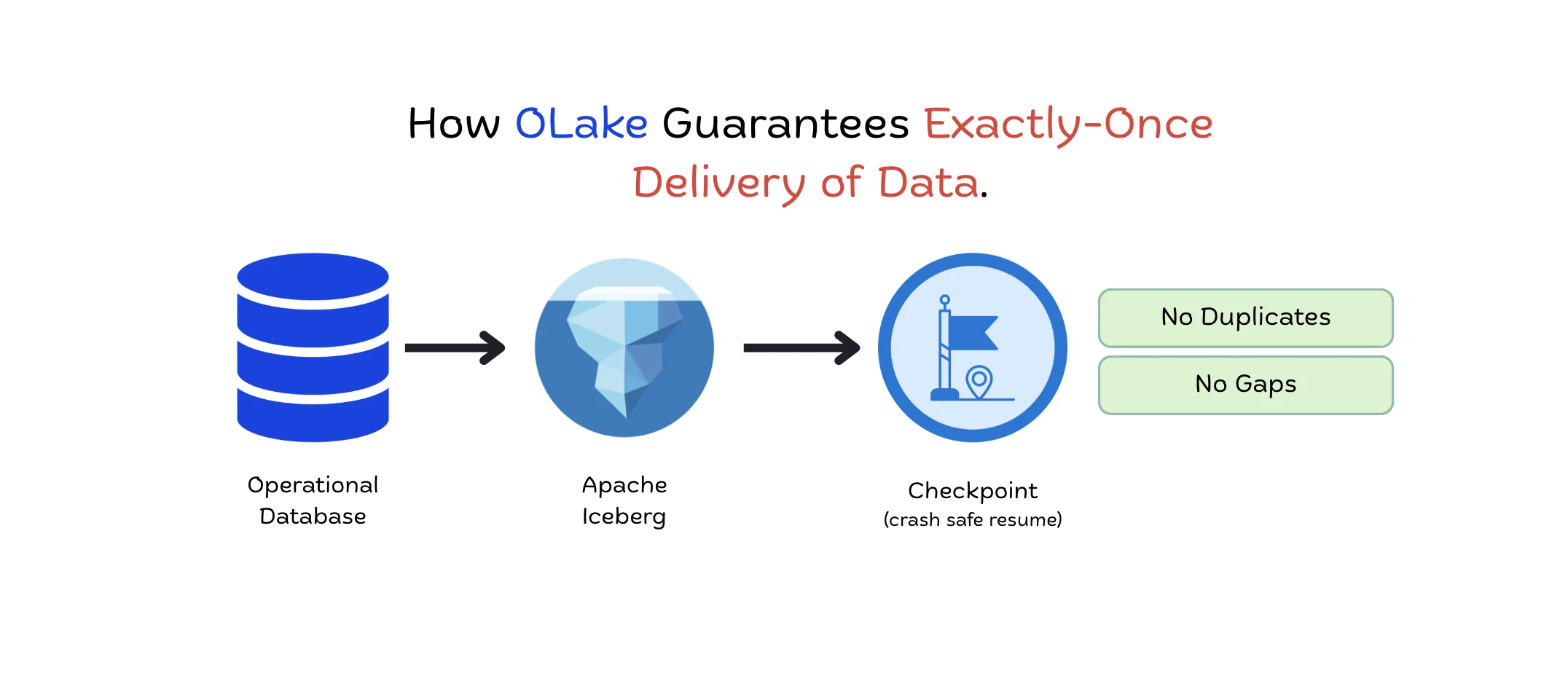
How OLake Guarantees Exactly-Once Delivery to Apache Iceberg
How OLake guarantees exactly-once delivery into Apache Iceberg across Full Refresh, Incremental, and CDC syncs using atomic commits and checkpoint recovery. No duplicates, no data loss, no external coordinator.

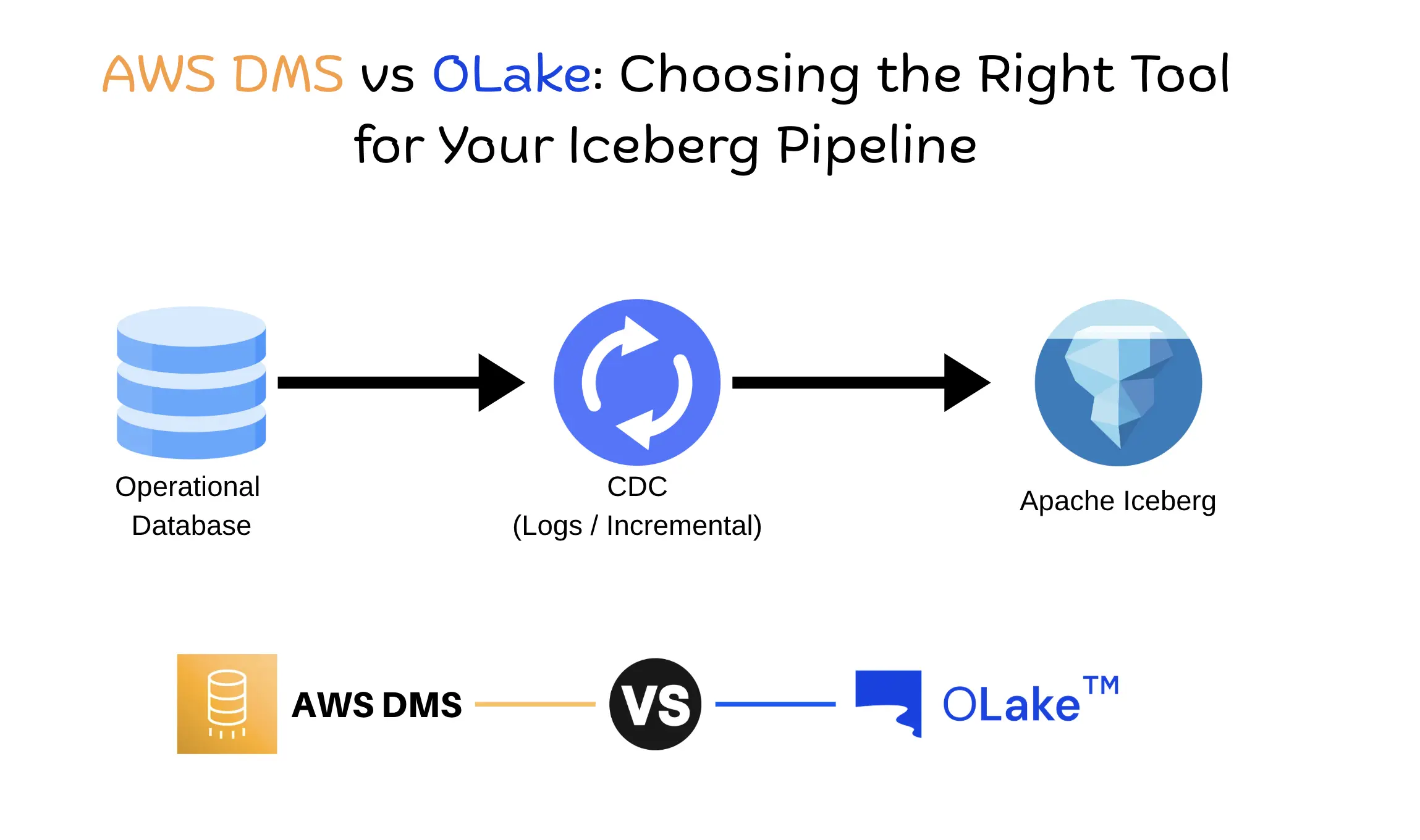
AWS DMS vs OLake: Choosing the Right Tool for Your Iceberg Pipeline
Compare AWS DMS and OLake for database-to-Iceberg pipelines: setup, CDC, schema evolution, scaling, and cost, with benchmark numbers on over 4 billion rows.

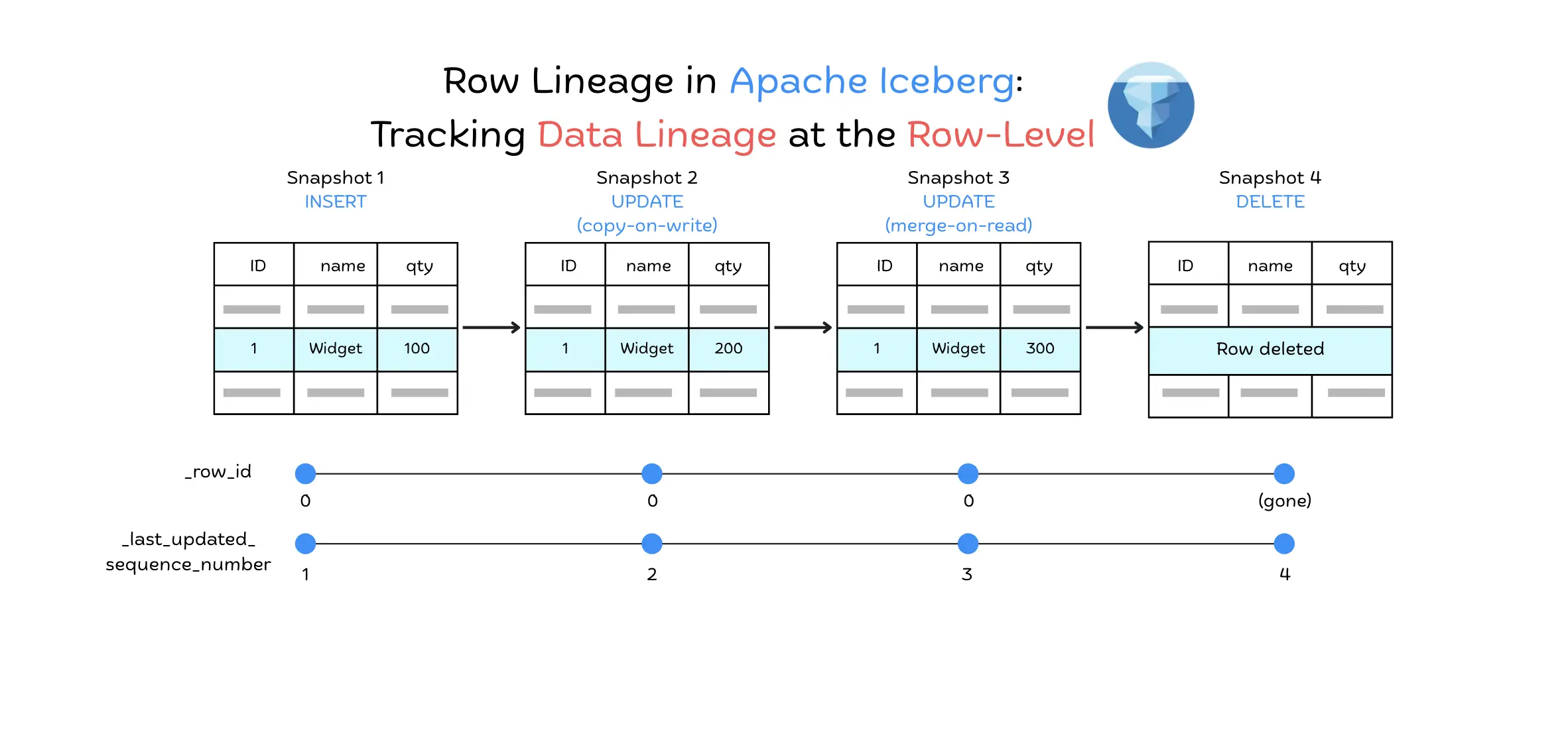
Apache Iceberg Row Lineage: Tracking Data Lineage at the Row-Level
How Apache Iceberg v3 row lineage tracks row-level changes for CDC, with a tested look at _row_id preservation across Spark 3.5 and Iceberg 1.9 vs 1.10.
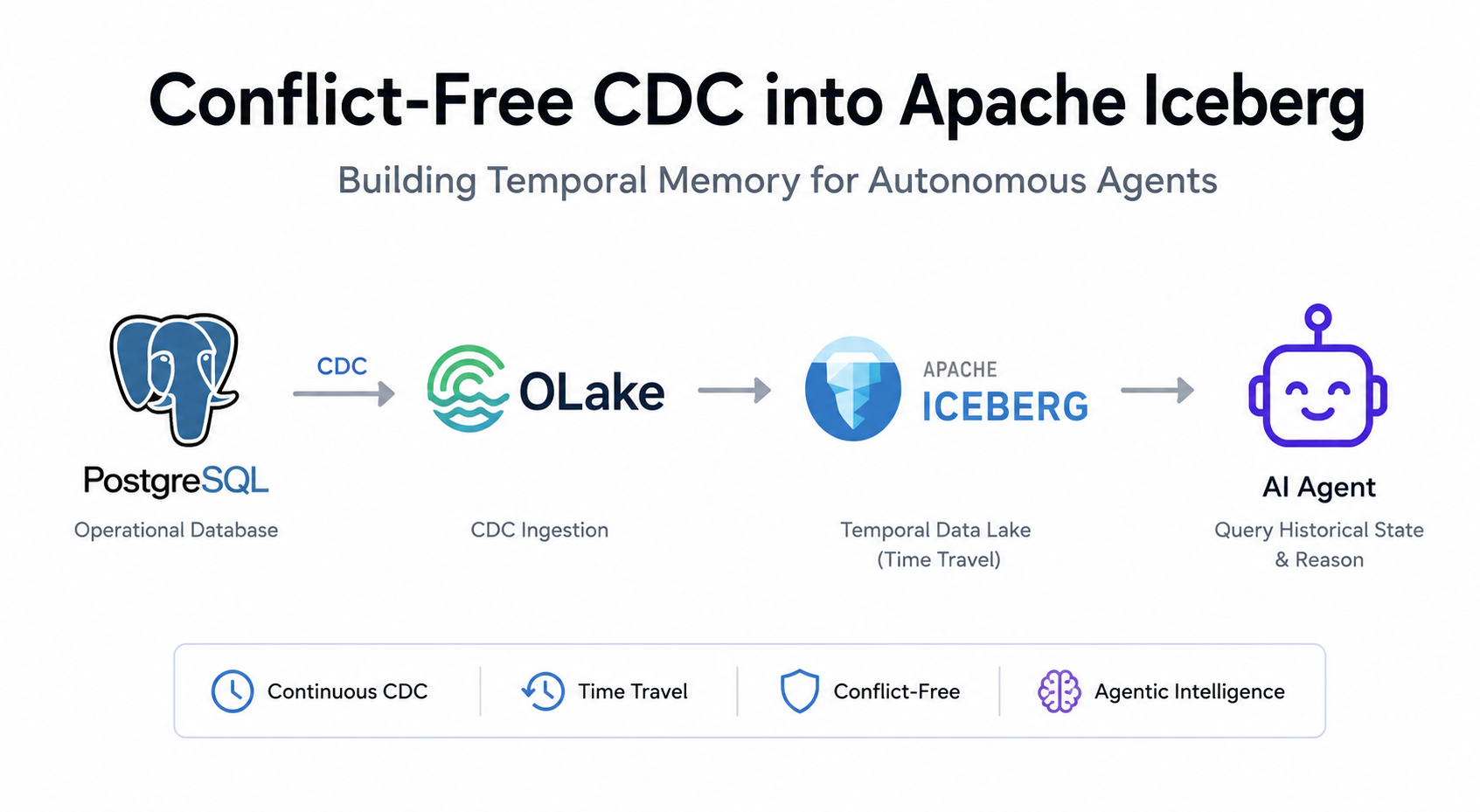
Conflict-Free CDC into Apache Iceberg: Architecting Temporal Memory for Autonomous Agents
Learn how to build 'Temporal Memory' for Agentic AI. Bypassing the Iceberg Read Amplification Wall using OLake CDC and ClickHouse for sub-second network analytics.


Apache Iceberg Table Maintenance Made Easier with OLake Fusion
OLake Fusion is an Apache Iceberg table maintenance solution for CDC tables, helping manage small files and delete files with tiered scheduling, metrics, and lower Spark costs.


50% Cheaper (2x Faster) Iceberg Compaction: OLake Fusion (Open Source) Beats Spark
We benchmark Spark rewrite_data_files against OLake Fusion compaction on Apache Iceberg by running a full TPCH lineitem load from Postgres to GCP, applying 200k-record CDC batches every 2 minutes, and tracking TPC-H Query 6 performance, runtime, resource usage, and infrastructure cost.
