Apache Iceberg Metadata Explained: Snapshots & Manifests


Iceberg Metadata at a Glance
At its core, Apache Iceberg isn't just another file format; it's a comprehensive table format designed to bring the reliability and performance of a traditional database to the vast scale of a data lake. The secret sauce that makes this possible is its sophisticated, multi-layered metadata system. This metadata is the brain of the operation, completely decoupling the logical table structure from the physical data files stored in your lake.
This separation of the logical table structure from the physical data files is what enables game-changing features like ACID transactions, lightning-fast queries through advanced partition and file pruning, safe schema evolution, and powerful versioning capabilities like time travel—all without the common performance bottlenecks and consistency issues of legacy Hive-style tables.
Forget scanning directories or relying on fragile file naming conventions. Iceberg's metadata provides a complete, versioned definition of a table at any point in time. This self-contained description is what allows different query engines like Spark, Trino, and Flink to work on the same data concurrently and consistently. In short, the metadata is what transforms a simple collection of files in a data lake into a true, high-performance analytical table.
Here's a quick breakdown of the key metadata layers and their distinct roles:
| Metadata Layer | Role | Key Information Contained |
|---|---|---|
| Catalog | The entry point & atomic pointer | Maps a table name (e.g., db.logs) to the path of its current master metadata file. It's the source of truth. |
| Table Metadata File (.json) | The table's blueprint | Contains the current schema, partition specification, sort order, snapshot history, and other table properties. |
| Manifest List | A versioned view of the table | Lists all manifest files that constitute a specific version (snapshot) of the table. Includes partition boundary stats for fast pruning. |
| Manifest File | An index of data files | Lists individual data files (e.g., Parquet, ORC) along with detailed per-file statistics like min/max column values and null counts. |
In this blog, we will understand in detail how Apache Iceberg stores the metadata information about the actual data making it an extremely powerful open table format.
2. Introduction: Why Metadata Matters in Modern Data Lakes
The initial promise of the data lake was simple and powerful: a centralized repository to store massive volumes of structured and unstructured data at a low cost. We could pour everything—logs, event streams, database dumps—into scalable object stores like Amazon S3 or Google Cloud Storage. The storage problem was seemingly solved. But soon, a new, more formidable challenge emerged: how do we manage, query, and trust this data at scale?
This is where metadata—or rather, the lack of a robust system for it—became the primary bottleneck. Early data lake architectures, heavily influenced by the Apache Hive model, relied on a simple approach: using the filesystem's directory structure as metadata. A table was essentially a top-level directory, and partitions were subdirectories, often following a familiar pattern like dt=2025-09-29/hour=18/ or maybe more specific partition like y=2025/m=09/d=29/h=18.
While this worked for a while, it created several critical problems as data volumes and query concurrency exploded:
The "List-then-Read" Performance Issue: To find the data for a query, engines had to perform expensive and slow LIST operations on the object store. Listing tens of thousands of directories and millions of files just to plan a query is incredibly inefficient, especially in cloud environments where LIST operations are notoriously slow and can incur significant costs.
No Atomic Operations: Committing data was not an atomic action. A simple INSERT OVERWRITE operation in Hive involves deleting old files and writing new ones. If that job fails midway, the table is left in a corrupted, inconsistent state, with a mix of old and new data. There was no clean way to roll back the failed transaction.
Schema and Partition Evolution Nightmares: Changing a column's data type or evolving the partition scheme was a high-risk, all-or-nothing operation. It often required rewriting the entire table, leading to massive data duplication, extended application downtime, and potential data loss if anything went wrong.
Consistency Breakdown: Without a central, transactional mechanism, it was nearly impossible for multiple writers, or even a single writer and a reader, to operate on the same table concurrently without causing inconsistencies. Readers could see partial data from an incomplete write, leading to incorrect analytics.
These challenges made the data lake feel unreliable and slow, much like a massive library with a poorly maintained card catalog. You knew the information was there, but finding it and trusting its state was a painful, inefficient process.
This is precisely where Iceberg redefined the game by fundamentally changing the role of metadata. Instead of inferring a table's state from a directory structure, Iceberg maintains a definitive manifest of all data files that belong to the table at a specific point in time. It tracks individual files, not directories. A "commit" is no longer a series of fragile file system operations; it's a single, atomic swap of a pointer to a new metadata file.
This shift from a directory-listing model to a manifest-based file-tracking model is the core innovation. It turns slow filesystem traversals into fast metadata lookups, enables true ACID transactions, and makes schema evolution a safe, instantaneous, metadata-only change. Iceberg treats metadata not as an afterthought but as the central component for building a reliable and high-performance data lakehouse.
3. Metadata Foundations in Iceberg
To truly appreciate Iceberg, we need to understand that its metadata is not a single entity but a layered, hierarchical system built on a few core principles. This design is what gives Iceberg its power and flexibility, setting it apart from older, more brittle data lake architectures.
3.1 What Counts as Metadata in Iceberg?
Iceberg's metadata is a tree-like structure where each layer has a specific responsibility. Traversing this tree allows a query engine to quickly find the exact data files it needs to read, without ever listing directories. Below is the detailed architecture of the Iceberg metadata system:
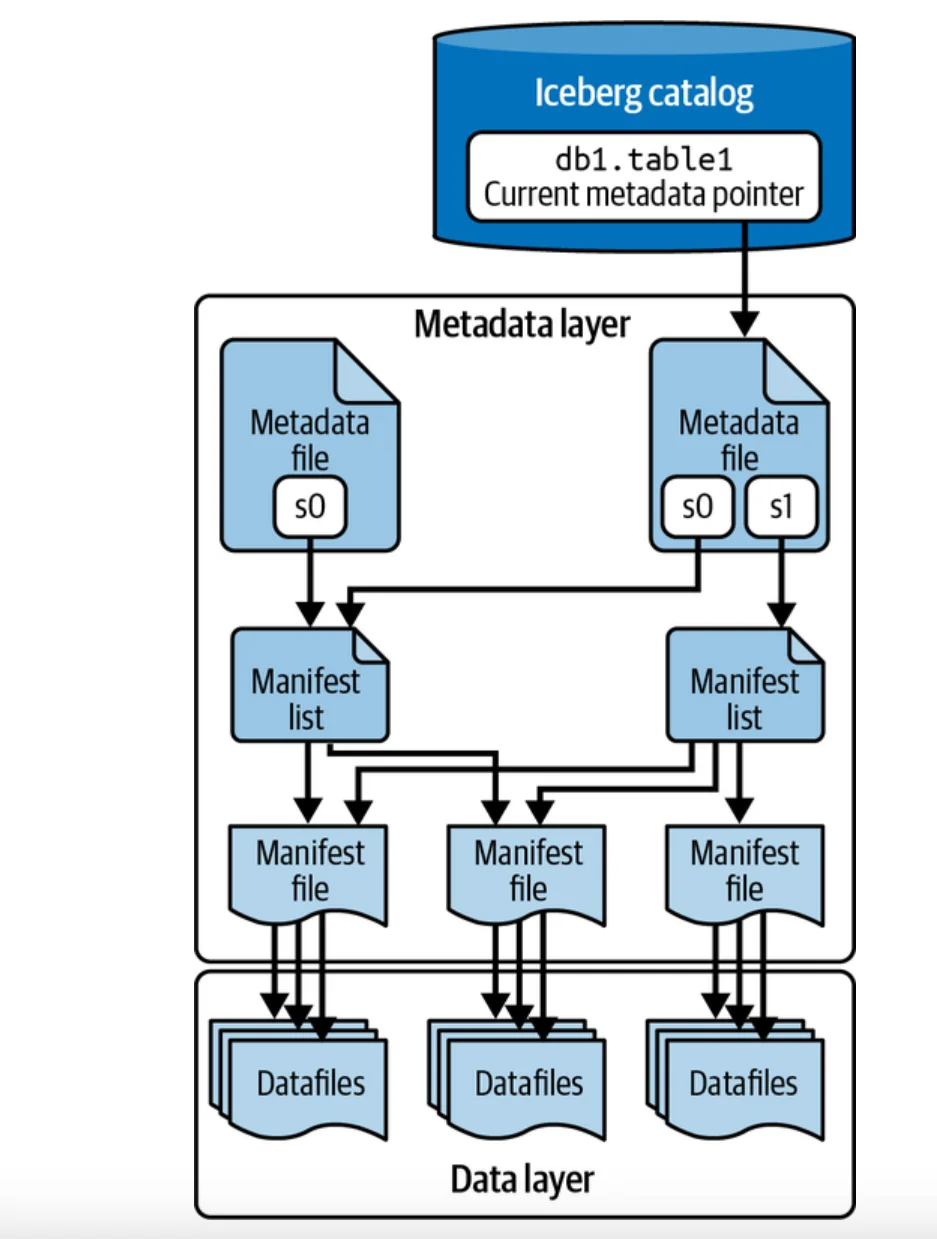
Here's a breakdown of the hierarchy, from top to bottom:
Iceberg Catalog: This is the topmost level and the primary entry point. A catalog's job is simple but crucial: it maps a human-readable table name (like prod_db.user_events) to the physical location of that table's current table metadata file. It's the "phonebook" that tells engines where to find the master blueprint for any given table.
Table Metadata File (metadata.json): This is the heart of an Iceberg table. It's a JSON file that contains everything an engine needs to know about the table's structure and history. This includes the full schema (with column IDs), the partition specification, the table's location, and a list of all historical snapshots. Each time a change is committed to the table (like an INSERT, UPDATE, or ALTER), a new, immutable metadata.json file is created.
Manifest List (or Snapshot Manifest): Each snapshot in the table's history points to a single manifest list file. This file contains a list of all the manifest files that make up that specific version of the table. Importantly, the manifest list stores statistics about the partition values covered by each manifest file, enabling engines to skip entire groups of files (a technique called partition pruning) very early in the planning phase.
Manifest Files: Finally, each manifest file contains a list of the actual data files (e.g., Parquet or ORC files) that hold the table's rows. Crucially, it stores detailed column-level statistics for each data file, such as the minimum and maximum values for each column, null counts, and total record counts. This is the information that powers fine-grained file pruning, allowing engines to skip reading files that couldn't possibly contain data relevant to a query's WHERE clause.
3.2 Core Principles: The Bedrock of Reliability
Iceberg's metadata architecture is guided by three fundamental principles that ensure consistency and interoperability:
Engine-Agnosticism: The metadata format is a well-defined, open specification. This means that any compute engine—be it Spark, Trino, Flink, or others—can read and interpret the metadata in the same way. This prevents vendor lock-in and allows different teams to use the best tool for their specific job (e.g., Spark for batch ETL, Flink for streaming ingestion) on the exact same data without conflicts.
Immutability: Every component of the metadata tree below the catalog is immutable. When data is written, Iceberg doesn't modify existing metadata or data files. Instead, it creates new files and then generates a new metadata.json file pointing to the new state. This approach provides a complete, versioned history of the table and is the foundation for features like time travel and atomic rollbacks.
Atomic Commits: All changes to an Iceberg table are committed in a single, atomic operation. This is achieved by updating the catalog's pointer from the old metadata.json file to the new one. This is a "compare-and-swap" (CAS) operation, which is guaranteed to be atomic. If the pointer swap succeeds, the commit is successful and all readers immediately see the new version of the table. If it fails (e.g., because another writer committed first), the operation fails cleanly and can be retried, ensuring the table is never left in a corrupted or intermediate state.
3.3 How is This Different from the Old Way?
The contrast with traditional Hive-style tables is stark. Hive tables couple the logical table structure directly to the physical directory layout in a distributed file system like HDFS or S3.
Hive Relies on a Central Metastore and Directory Listings: The Hive Metastore (HMS) stores the schema and a list of partition locations (directory paths). To get file-level information, the query engine must perform expensive LIST operations on those directories. This is slow, and the HMS can become a performance bottleneck.
Iceberg is Self-Contained: An Iceberg table's state is fully described by its metadata files. An engine can discover everything it needs to know—schema, partitioning, and the exact list of data files—just by reading the metadata tree, without ever listing directories.
This fundamental architectural difference is what allows Iceberg to provide ACID guarantees, superior performance, and safe, concurrent operations on the data lake. It shifts the source of truth from a fragile and slow directory structure to a robust, transactional metadata manifest.
4. Catalogs: The Entry Point to Metadata
While the metadata.json file is the heart of an Iceberg table, the Catalog is the gatekeeper. It's the essential first step in any interaction with an Iceberg table, providing the authoritative answer to a single, critical question: "For the table named db.my_table, where can I find its current, authoritative metadata file?" Without a catalog, engines would have no reliable way to locate and agree upon the true state of a table.
4.1 The Role of the Catalog
The catalog's primary responsibility is to maintain a mapping from a table identifier (like production.logs.api_events) to the path of the table's latest metadata.json file. This might seem simple, but this pointer is the lynchpin for ensuring atomicity and consistency.
When a writer commits a change to an Iceberg table, it performs the following steps:
- Creates new data files.
- Writes new manifest files listing these data files.
- Writes a new manifest list pointing to these manifest files.
- Writes a new
metadata.jsonfile that points to the new manifest list. - Finally, it asks the catalog to atomically swap the pointer from the old
metadata.jsonpath to the new one.
This final step is a compare-and-swap (CAS) operation. The catalog will only update the pointer if the current pointer still matches the one the writer started with. This prevents race conditions and ensures that commits are an all-or-nothing affair, making operations like INSERT, DELETE, and MERGE truly atomic.
Iceberg supports a variety of catalog implementations, each suited for different ecosystems:
Hive Metastore Catalog: A popular choice for users migrating from Hive. It repurposes the existing Hive Metastore (HMS) to store the pointer to the Iceberg metadata file, allowing Iceberg tables to be managed alongside legacy Hive tables.
AWS Glue Catalog: The standard choice for users in the AWS ecosystem. It leverages the AWS Glue Data Catalog as the central metastore.
REST Catalog: A standardized, open protocol for an Iceberg-native catalog service. This is a great option for building a platform-agnostic data architecture, as it decouples you from specific compute or storage vendors.
JDBC Catalog: Stores metadata pointers in a relational database like PostgreSQL, offering strong transactional guarantees.
Hadoop Catalog: A simpler, file-system-based catalog suitable for local testing or environments without a central metastore, though it lacks support for locking and is not recommended for production with multiple writers.
4.2 How Catalogs Differ from the Hive Metastore
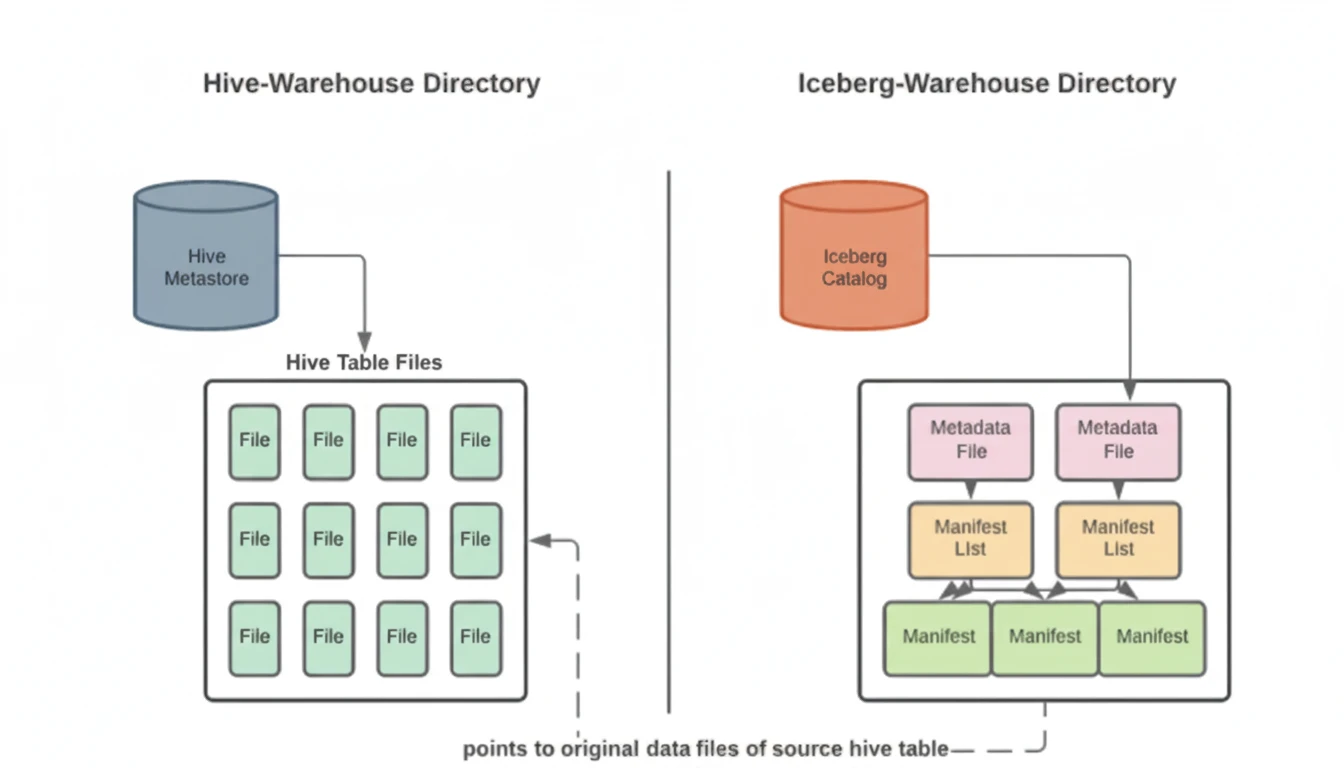
It's crucial to understand that using the Hive Metastore as an Iceberg catalog is fundamentally different from how Hive traditionally uses it.
In Traditional Hive: The HMS is deeply involved in query planning. It stores the schema, partition locations (directories), and other table properties. An engine constantly communicates with the HMS to get this information, often making it a performance and scalability bottleneck.
In Iceberg: The catalog (even if it's the HMS) is only used for one thing: to find the path to the current metadata.json file. Once the engine has that path, it reads the self-contained Iceberg metadata tree and does not need to communicate with the catalog further for planning. The catalog's role is minimal, transactional, and highly efficient.
4.3 Trade-offs and Considerations
Choosing a catalog is a key architectural decision with important trade-offs:
Performance: REST and JDBC catalogs are often highly performant as they are designed specifically for the simple CAS operation Iceberg requires. The HMS, while functional, can sometimes introduce latency as it was built for a more chatty protocol.
Governance & Features: Cloud-native catalogs like AWS Glue often integrate seamlessly with the platform's IAM for access control, auditing, and data discovery tools. The Hive catalog can leverage tools like Apache Ranger.
Ecosystem Support: The Hive Metastore is the most widely supported catalog across the open-source ecosystem (Spark, Trino, Flink, etc.). However, support for REST and Glue is rapidly maturing and becoming standard.
Operational Overhead: Running a self-hosted HMS or JDBC catalog requires maintenance and operational effort. Using a managed service like AWS Glue offloads this responsibility to the cloud provider.
Ultimately, the catalog acts as the atomic source of truth, enabling safe, concurrent operations by providing a reliable mechanism to manage the pointer to a table's complete, versioned history.
5. Table Metadata File (metadata.json)
If the catalog is the gatekeeper, the Table Metadata File (e.g., v1.metadata.json, v2.metadata.json, etc.) is the constitution of an Iceberg table. It is a single, comprehensive JSON file that contains everything a query engine needs to know to correctly read the data for a specific table version. Once an engine gets the path to this file from the catalog, the table becomes entirely self-describing. This is the authoritative blueprint.
Let's dissect its most critical components.
5.1 Structure of the Metadata File
This JSON file is meticulously structured to provide a complete and unambiguous definition of the table's state, history, and configuration.
Schema: This defines the columns of the table, including their names, data types, and documentation. Critically, every field in the schema is assigned a permanent, unique ID. When you rename a column, only its name changes in the metadata; the ID remains the same. When you drop a column and then add a new one with the same name, the new column gets a fresh ID. This ID-based tracking is what enables Iceberg's safe and reliable schema evolution, completely avoiding the dangerous ambiguity of tracking columns by name or position, which plagues older systems.
Partition Spec: This defines exactly how the table is partitioned. It specifies which source data columns are transformed to produce partition values. For example, a spec might define a partition key by applying a year() transform to a timestamp column or a truncate(10) transform to a string column. Like schema fields, each partition specification has a unique ID. This allows you to safely change how a table is partitioned over time without rewriting existing data. Old data remains organized under the old partition spec, while new data is written using the new one.
Snapshots & Snapshot Log: This is a list of every available snapshot in the table's history. Each entry in this log contains a snapshot ID, the timestamp it was created, and a summary of the operation that created it (e.g., append, overwrite). The metadata file also contains a current-snapshot-id field that points to the snapshot representing the table's active state. This log is the foundation of Iceberg's powerful time-travel capabilities.
Properties: A simple key-value map for storing table-level configuration. This can include settings like the default file format (e.g., write.format.default=parquet), compression codecs, and other custom properties that govern write behavior or are needed by various tools.
Here is a sample Iceberg metadata file (JSON):
{
"format-version": 2,
"table-uuid": "f7m3-a812-4a5c-96b6-8a3a",
"location": "s3://warehouse/db/events",
"last-updated-ms": 1664472000000,
"last-column-id": 3,
"schemas": [
{
"schema-id": 0,
"type": "struct",
"fields": [
{ "id": 1, "name": "event_ts", "required": true, "type": "timestamp" },
{ "id": 2, "name": "level", "required": true, "type": "string" },
{ "id": 3, "name": "message", "required": false, "type": "string" }
]
}
],
"current-schema-id": 0,
"partition-specs": [
{
"spec-id": 0,
"fields": [ { "name": "event_ts_day", "transform": "day", "source-id": 1 } ]
}
],
"current-partition-spec-id": 0,
"snapshots": [
{
"snapshot-id": 3051729675574644887,
"timestamp-ms": 1664471000000,
"summary": { "operation": "append", ... },
"manifest-list": "s3://.../snap-3051729.avro"
},
{
"snapshot-id": 8235603094578364387,
"parent-snapshot-id": 3051729675574644887,
"timestamp-ms": 1664472000000,
"summary": { "operation": "append", ... },
"manifest-list": "s3://.../snap-8235603.avro"
}
],
"current-snapshot-id": 8235603094578364387
}
5.2 Schema and Partition Evolution Tracking
The use of unique IDs for both schema fields and partition specs is a cornerstone of Iceberg's design, making evolution a safe, metadata-only operation. In legacy systems, renaming a column could break downstream queries, or adding a column in the "wrong" position could lead to data corruption.
Iceberg avoids this entirely. Because engines track data via field IDs, you can safely perform operations like:
- Add: A new column is added with a new unique ID.
- Drop: A column is removed from the current schema, but its historical data and ID are preserved for older snapshots.
- Rename: The column's name is changed in the metadata, but the underlying ID remains the same, so queries referencing it don't break.
- Reorder: The position of columns can be changed without any effect on correctness.
Similarly, when you change a table's partition scheme (e.g., from daily to hourly), a new partition spec with a new ID is created and registered in the metadata. Iceberg is smart enough to use the correct spec for the corresponding data files, allowing for seamless evolution as your access patterns change—all without rewriting old data.
5.3 Versioning Through Immutability
Every time a transaction is committed to the table, Iceberg creates a new, completely independent metadata.json file. This file is given a monotonically increasing version number in its filename (e.g., 00000-....metadata.json, 00001-....metadata.json, etc.). The atomic commit in the catalog simply updates the pointer from the previous metadata file to this new one.
This versioning strategy provides several key benefits:
- Auditability: You have a linear, auditable history of the table's state.
- Trivial Rollbacks: A rollback is nothing more than an atomic commit that changes the catalog pointer back to an older version of the metadata file.
- Snapshot Isolation: Long-running read jobs are not affected by concurrent writes, as they will continue to read against the specific, immutable table version they started with, guaranteeing a consistent view of the data.
6. Snapshots: Versioned Views of a Table
Every change to an Iceberg table, whether it's adding data, deleting rows, or altering the schema, creates a new snapshot. A snapshot is an immutable, complete view of the state of a table at a specific point in time. It's not a copy of the data itself, but rather a definitive list of all the data files that constitute the table at the moment the transaction was committed.
6.1 What a Snapshot Represents
Think of a snapshot as a version commit in a Git repository. Each commit produces a new snapshot, which is identified by a unique Snapshot ID and a timestamp. The metadata.json file we just discussed maintains a log of these snapshots, allowing Iceberg to track the table's complete lineage. This history is the foundation for some of Iceberg's most celebrated features.
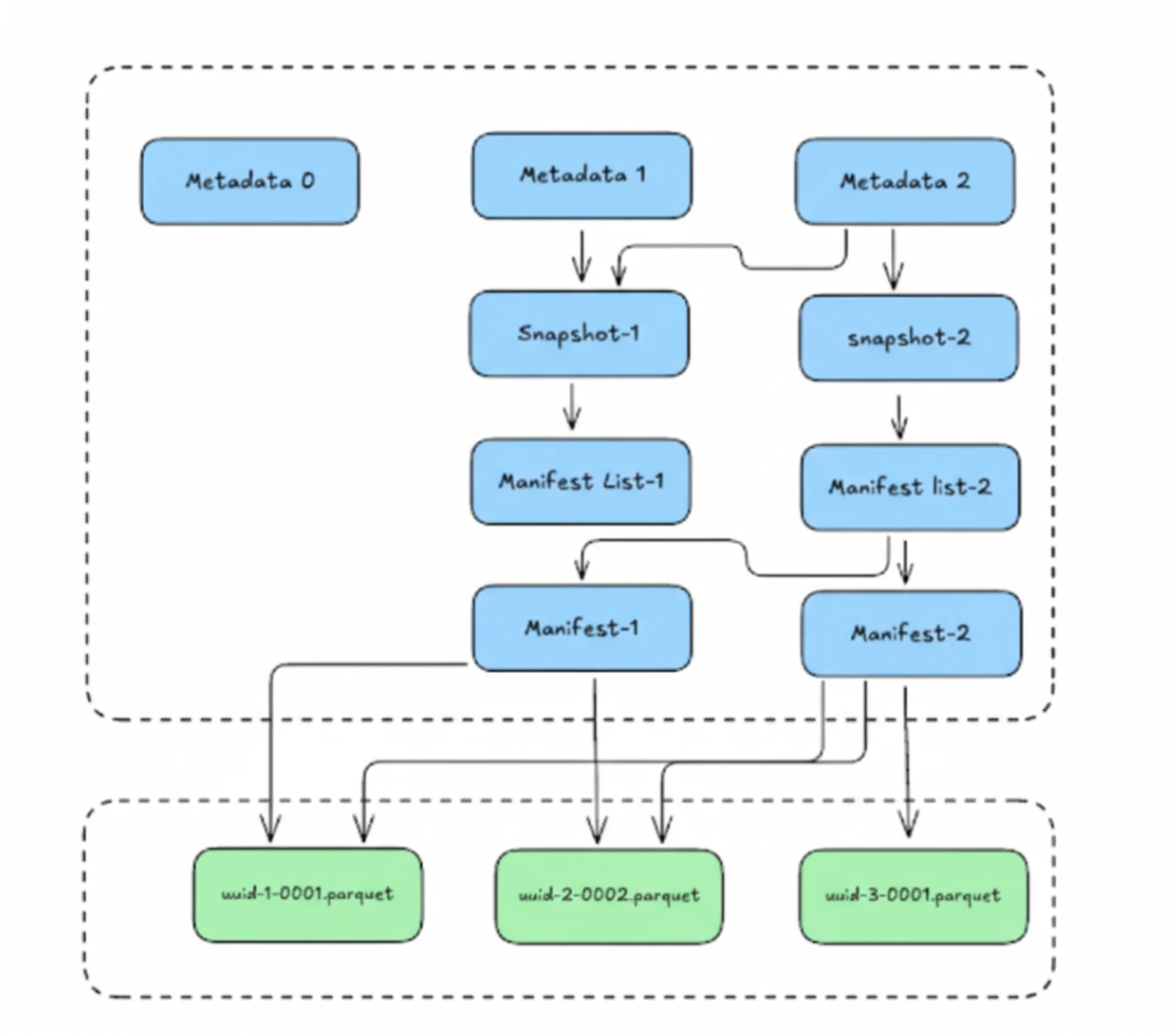
Each snapshot points to a single manifest list file, which in turn points to the manifest files that track the actual data files. This clean separation ensures that every version of the table is fully self-contained and reproducible.
6.2 Snapshot Lineage and Metadata
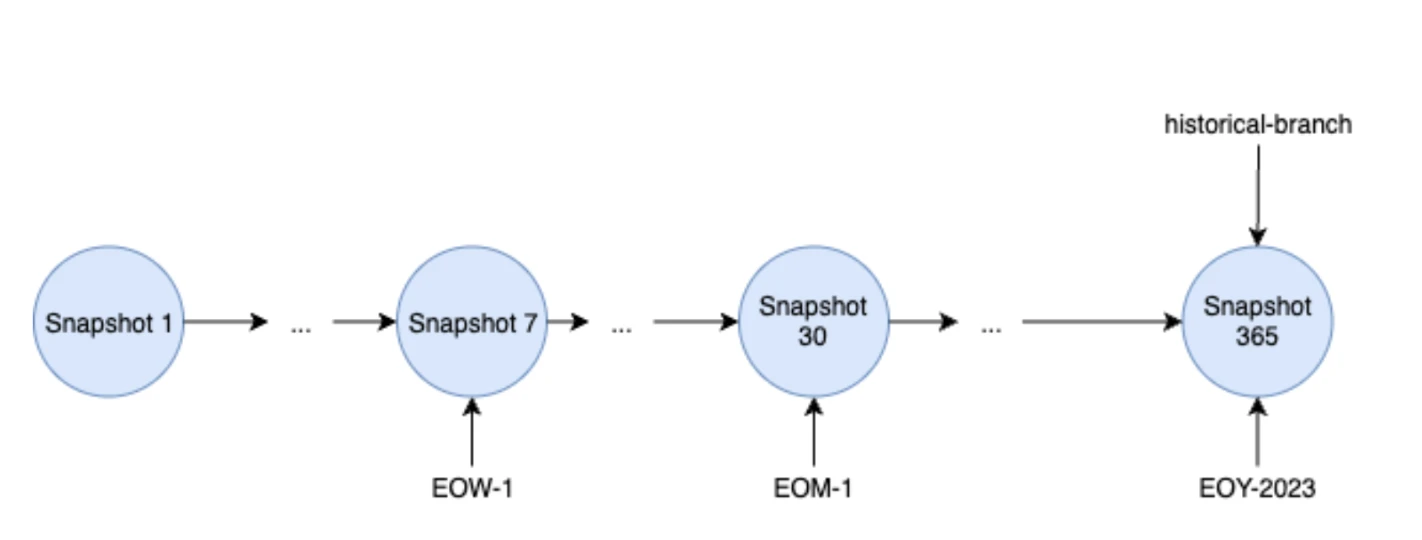
Beyond the unique ID and timestamp, each snapshot (except the very first one) also contains a parent-snapshot-id. This pointer creates a clear, sequential chain of events, allowing you to trace exactly how the table evolved from one state to the next. This lineage is crucial for auditing, debugging, and understanding data provenance.
6.3 Time Travel, Rollback, and Branching
The versioned history created by snapshots enables a suite of powerful data management capabilities that are difficult, if not impossible, to achieve in traditional data lakes.
Time Travel: This allows you to query the table as it existed at a previous point in time. Because each snapshot is a complete and immutable representation, you can run a SELECT query against a specific snapshot ID or a timestamp. This is incredibly useful for reproducing machine learning experiments, rerunning reports, or debugging issues by comparing the state of the table before and after a change. It provides perfect snapshot isolation for readers.
Rollback: If a data pipeline introduces bad data, recovery is instantaneous and safe. A rollback is simply a metadata operation that changes the table's current-snapshot-id pointer back to a previous, known-good snapshot. No data is physically moved or deleted during the rollback itself. The operation is atomic and completes in seconds, dramatically reducing the mean time to recovery (MTTR) for data quality incidents.
Branching and Tagging: More advanced workflows, similar to Git, are also possible. You can create branches (named references to snapshots) for development or experimentation, and tags to give permanent, human-readable names to important snapshots, like an end-of-quarter report.
6.4 Practical Example: Recovering from a Bad Pipeline Run
Let's make this concrete. Imagine a daily ETL job that appends new user activity data to your main events table.
- Monday, 9 AM: The pipeline runs successfully, creating snapshot S1. The table is in a good state.
- Tuesday, 9 AM: A bug is introduced into the pipeline's transformation logic. It runs and appends malformed data, creating a new snapshot, S2.
- Tuesday, 10 AM: Downstream dashboards start showing incorrect metrics. A data quality check fails, and you're alerted to the problem.
The Old Way (Hive): You'd be in for a painful, multi-hour process of identifying the bad partitions, manually deleting files, and carefully re-running the job, all while the table is in a corrupted state.
The Iceberg Way: You identify the last known-good snapshot (S1). You execute a single command to roll back the table's current state to S1. The change is atomic and immediate. All new queries now see the clean data from Monday. The corrupted data files from S2 are now "orphaned" (no longer referenced by the current snapshot) and will be safely garbage collected by a later maintenance job. Your data is fixed in seconds.
This ability to instantly and safely correct errors transforms data engineering from a high-risk practice into a more agile and resilient discipline.
7. Manifest Lists & Manifest Files
Diving deeper than the snapshot level, we find the core indexing system of an Iceberg table: the manifest lists and manifest files. These metadata layers work together to provide query engines with a fast and efficient way to locate the exact data files they need, enabling massive performance gains by avoiding unnecessary data reads.
7.1 How manifest lists point to manifest files
Each snapshot in the table's history points to a single manifest list file. This file acts as a top-level index for that specific version of the table. Its primary content is a list of paths to one or more manifest files.
Critically, the manifest list doesn't just store file paths. For each manifest file it points to, it also stores aggregated statistics, specifically the range of partition values contained within that manifest. This crucial detail allows a query engine to perform high-level pruning, immediately discarding entire manifest files (and by extension, all the data files they track) that could not possibly contain data relevant to a query's filter conditions.
7.2 Manifest file contents
Each manifest file is a more granular index that contains an inventory of individual data files. For every data file (e.g., a specific Parquet or ORC file), the manifest stores a wealth of information:
- The status of the file (whether it was added, is existing, or has been deleted in this snapshot).
- The full path to the data file in object storage.
- Detailed information about the file's partition membership.
- Most importantly, rich column-level statistics, including the minimum and maximum values for each column within that file, a count of null values, and the total record count.
This detailed, file-specific metadata is the foundation for fine-grained query optimization.
7.3 Metadata pruning: skipping entire files via statistics
This multi-level index is what allows Iceberg to surgically select files instead of relying on slow directory listings. Consider this query:
SELECT * FROM logs WHERE event_date = '2025-09-28' AND log_level = 'ERROR';
The query engine uses the manifests to prune data in two steps:
-
Partition Pruning (using the Manifest List): The engine reads the manifest list and examines the partition stats for event_date. It immediately ignores any manifest file whose partition range does not include '2025-09-28'.
-
File Pruning (using the Manifest Files): For the remaining manifests, the engine reads them and inspects the column-level stats for log_level for each data file. If a data file's stats indicate its log_level values only range from 'INFO' to 'WARN', the engine skips that file completely, knowing it cannot satisfy the log_level = 'ERROR' predicate.
This process ensures that the engine only reads the minimal set of files required, dramatically reducing I/O and accelerating query execution.
7.4 Handling small files and compaction
The small file problem, common in streaming workloads, can degrade query performance. Iceberg's manifests provide a perfect solution. Because the manifests contain a complete list of all data files, a maintenance process can easily identify tables with too many small files.
A compaction job can then read a group of these small files, write their contents into a new, larger file, and commit a new snapshot. This commit atomically replaces the manifest entries for the old small files with a single entry for the new compacted file. The process is transactional and invisible to readers, who seamlessly begin using the more efficient file once the commit is complete.
8. Concurrency & Atomicity Through Metadata
One of the biggest challenges in data lakes has always been managing concurrent reads and writes safely. Traditional Hive tables offered little to no protection, often leading to inconsistent results or corrupted tables when multiple jobs tried to write at the same time. Iceberg solves this by using its metadata to provide full ACID transaction guarantees through a clever and efficient concurrency control model.
8.1 Atomic Commits with Optimistic Concurrency
Iceberg ensures data integrity using atomic commits built on a foundation of optimistic concurrency. Let's break that down.
Atomicity is guaranteed by the final step of any write operation: a compare-and-swap (CAS) call to the catalog. As we've discussed, a commit is only successful if the catalog's pointer to the table's metadata file can be atomically updated. If this single operation succeeds, the new version of the table is instantly visible to all new queries. If it fails for any reason, the table's state is completely unchanged, as if the operation never happened. This prevents partial writes and data corruption.
Optimistic Concurrency is the strategy Iceberg uses to handle multiple writers. Instead of using traditional database "locks" (which are slow and complex to manage in a distributed file system), Iceberg writers operate "optimistically." They assume that no other writer will interfere with their work. A writer reads the table's current state, prepares its changes, and only at the very last moment does it check if the table has changed since it started. If the table is still in the same state, the commit succeeds. If not, the commit is rejected, and the writer must retry.
This model is perfectly suited for analytics workloads, where write conflicts are relatively infrequent but throughput is critical.
8.2 What Happens During Concurrent Writes
Let's walk through a typical concurrent write scenario:
- Start: Two writers, Job A and Job B, both start an operation on a table. They both read the current metadata and see that the table is at version V1.
- Job A Finishes First: Job A completes its work, creates new data files, and writes a new metadata file for version V2. It then goes to the catalog and says, "Please update the table pointer from V1 to V2." The CAS operation succeeds. The table is now officially at V2.
- Job B Attempts to Commit: A few moments later, Job B finishes its work, which was also based on V1. As V1 is no longer the current version, the Job B crashes.

With Iceberg, the catalog rejects Job B's request because the current pointer is no longer V1—it's V2. This is a commit conflict. The Iceberg client library catches this failure and automatically retries:
- It discards its failed attempt and reads the new current state of the table (V2).
- It checks if the changes made by Job A conflict with its own changes.
- If there's no conflict (e.g., they modified different partitions), Job B reapplies its changes on top of V2 and attempts a new commit.
- If the changes do conflict (e.g., both jobs tried to update the same row), the retry fails, and the application receives an error (like a CommitFailedException) that must be handled.
8.3 Comparison with Hive's Delta/Base File Strategy
This optimistic concurrency model stands in stark contrast to Hive's approach to ACID transactions, which relies on a more complex system of delta and base files.
In Hive, updates and deletes are written to small "delta" files. A reader must query the main "base" data files and merge the changes from all relevant delta files on the fly. This merge-on-read process can become very slow as the number of deltas grows. To maintain performance, a background process must periodically run a "major compaction" to merge the deltas back into the base files.
Iceberg's copy-on-write (for appends/overwrites) and merge-on-read (for row-level deletes) mechanisms are fundamentally different. A commit always produces a new, clean snapshot of the table. There is no lingering state of delta files that every reader has to resolve. This simplifies the reader's job, provides more predictable query performance, and makes the state of the table much easier to reason about.
9. Metadata Performance Considerations
Iceberg's metadata architecture is designed for massive scale, but like any high-performance system, it benefits from proper tuning and maintenance. As tables grow to billions of rows and millions of files, understanding how to manage the metadata itself becomes crucial for maintaining fast queries and controlling costs, especially in the cloud.
9.1 Scaling Metadata for Large Tables
A common concern is whether the metadata itself can become a bottleneck. What happens when a table has millions of data files? Reading a single, gigantic manifest file listing all of them would be slow.
Iceberg avoids this by design. A snapshot's manifest list can point to multiple manifest files. As a table grows, write operations will intelligently split metadata across many smaller, more manageable manifest files, often aligning them with the table's partitions. This enables query engines to prune entire manifest files using the manifest list's partition stats, and read and process the remaining manifest files in parallel across multiple workers.
This ability to split and parallelize metadata processing allows Iceberg's query planning to scale horizontally, preventing the metadata from becoming a centralized bottleneck.
9.2 Metadata Caching Strategies
Repeatedly fetching and parsing metadata files from object storage for every query would be inefficient. To solve this, query engines like Spark and Trino implement aggressive metadata caching.
When a query is first planned for an Iceberg table, the engine reads the necessary metadata files (metadata.json, manifest lists, manifests) from storage and caches them in memory. Subsequent queries, even from different users, can then reuse this cached information, skipping the expensive network calls and parsing steps. This can reduce query planning times from seconds to milliseconds, which is especially impactful for interactive BI and analytics workloads where many similar queries are run against the same tables.
9.3 Tuning Compaction and Snapshot Expiration
Like a database, an Iceberg table requires routine maintenance for optimal performance. Two key procedures are essential:
Snapshot Expiration: Keeping a perpetual history of every snapshot can cause the primary metadata.json file to grow, and it prevents the cleanup of old data files. You should regularly run snapshot expiration procedures to remove old snapshots that are no longer needed for time travel or rollbacks. This keeps the metadata lean and, more importantly, allows the garbage collection process to safely identify and delete orphaned data files, saving on storage costs.
Data Compaction: To combat the "small file problem," you should run compaction jobs to combine small data files into larger, more optimal ones. This is a read-time performance optimization. Fewer files mean less metadata to track and fewer file open operations for the query engine. A well-tuned compaction strategy is a trade-off between the compute cost of running the compaction job and the query performance gains it delivers.
9.4 Cost Implications of Metadata Scans in Cloud Object Stores
While Iceberg brilliantly avoids expensive LIST operations in cloud storage, it still needs to read its own metadata files, which incurs GET request costs. For a very large, frequently queried table, the number of GET requests to read manifests can become a noticeable line item on your cloud bill.
This is where all the previous points converge to help you manage costs:
- Effective Caching: This is your first and most important defense, as it dramatically reduces the number of GET requests for repeated queries.
- Smart Partitioning: A good partitioning scheme ensures that partition pruning is highly effective, minimizing the number of manifest files that need to be read in the first place.
- Regular Compaction: Fewer data files result in fewer entries in manifests, which can lead to a smaller number of manifest files overall, reducing GET operations during planning.
By actively managing your metadata, you can ensure your data lakehouse is not only performant but also cost-effective.
10. Advanced Metadata Features
Beyond the fundamentals of reliable transactions and time travel, Iceberg's metadata specification enables a suite of advanced features that bring true data warehousing capabilities directly to the data lake. These features are powered by further enriching the information stored in the metadata files.
10.1 Sort/Order Specs for Query Efficiency
Partitioning is excellent for eliminating files based on low-cardinality columns, but what if you frequently filter on a high-cardinality column like user_id or session_id? Partitioning by such a column would create an explosion of small files.
Iceberg solves this with sort orders, which are defined in the metadata. By declaring a table's sort order, you instruct writers to sort data within each file by the specified columns. While this doesn't change which files are read, it dramatically improves performance during the file scan. When the query engine reads a sorted Parquet or ORC file, it can use the internal row group statistics to skip huge chunks of rows within the file that don't match the query's filter. This provides a powerful, secondary layer of data skipping, especially for highly selective queries.
10.2 Row-level Deletes via Delete Files
Historically, deleting a single row from a data lake table required finding the file containing that row and rewriting it entirely—an expensive and slow process. Iceberg v2 introduced delete files to handle row-level operations efficiently.
Instead of rewriting data, Iceberg can perform a "merge-on-read" by associating data files with delete files. There are two types:
- Position Deletes: These files are highly efficient and record the exact location of a deleted row (e.g., "in file data_1.parquet, row number 1,234 is deleted"). They are the result of targeted DELETE or MERGE operations where the exact rows to be removed are known.
- Equality Deletes: These files specify that any row across multiple data files that matches a certain condition should be considered deleted (e.g., "delete all rows where user_id = 'xyz-789'"). This is extremely useful for privacy compliance and GDPR "right to be forgotten" requests, where you need to purge all data for a specific entity.
The table's manifests are updated to track these delete files alongside the data files, ensuring that any query engine reading the table knows precisely which deletes to apply.
10.3 Branching and Tagging for CI/CD-Style Data Workflows
Iceberg brings version control concepts directly to your data, closely mirroring Git workflows. This is managed through named references in the metadata.
Branching: A branch is simply a named pointer to a snapshot. You can create a dev branch from your main production branch, allowing data engineers to experiment with complex, multi-stage ETL jobs in complete isolation. Once the results are validated on the dev branch, the changes can be "merged" back to main as a single, atomic, fast-forward operation. This provides a safe sandbox for data development and testing.
Tagging: A tag is a permanent, human-readable, and immutable name for a specific snapshot. This is perfect for marking production releases or important historical moments, such as end_of_q3_2025_report or v1.0_ml_model_training_data. Tags make it trivial to time-travel back to these critical, named versions of your table.
10.4 Metadata in Iceberg Format v3
Building on the robust foundation of v2, the newly introduced Iceberg format version 3 (v3) focuses on advanced query acceleration and broader cross-engine collaboration. The metadata enhancements in v3 are designed to support even more sophisticated data warehousing workloads.
Key innovations in the v3 metadata include:
- Support for the Puffin File Format: V3 introduces a formal specification for Puffin, a sidecar file format designed to hold large statistics and indexes. This allows for storing things like Bloom filters or other complex index structures alongside your data, enabling highly efficient data skipping for selective queries without bloating the core manifest files.
- Standardized View Specification: A major leap forward in v3 is the formalization of Iceberg Views. The metadata can now store a view's definition, including its SQL logic and schema. This means a view created in one engine (like Spark) is instantly available and understood by another (like Trino), bringing Iceberg's "single source of truth" principle to logical views, not just physical tables.
In essence, format v3 enriches the metadata to further optimize query performance and enhance interoperability, solidifying Iceberg's role as the definitive standard for the lakehouse.
11. Metadata in Practice: Real-World Workflows
The true power of Iceberg's metadata isn't just in its elegant design, but in how it solves practical, complex data engineering challenges and enables workflows that were previously unreliable or impossible in a data lake.
11.1 Data Ingestion Pipelines
Whether you're dealing with high-velocity streams or large batches, metadata ensures reliability.
Streaming CDC Merges: Maintaining an up-to-date replica of an operational database in the lake is a classic challenge. With Iceberg's support for row-level changes (thanks to delete files), a streaming application using Flink or Spark can consume a Change Data Capture (CDC) feed from a source like Debezium. It can then perform MERGE INTO operations in near real-time. The metadata's atomic commit process guarantees that each micro-batch of changes is applied transactionally, providing a consistently fresh and accurate view of the source data for analytics.
Append-Only Feeds: For immutable event streams or logs, Iceberg provides crucial reliability. Atomic commits ensure that batches of data are either fully visible or not at all. If an ingestion job fails midway, there is zero risk of a downstream consumer reading a partial, corrupted dataset. The snapshot created by a successful commit provides a clean, instantaneous point-in-time for downstream jobs to consume.
11.2 BI Workloads with Partition Pruning
Imagine a business analyst using Tableau to build a dashboard on a multi-terabyte sales table partitioned by month.
- The analyst applies a filter for "last quarter."
- Tableau sends a query to Trino with a WHERE clause on the date column.
- Trino doesn't scan the whole table. It first reads the Iceberg table's manifest list.
- Using the partition stats in the metadata, Trino immediately identifies that 95% of the manifest files (representing older data) are irrelevant and skips them entirely.
- It then reads only the few manifests corresponding to the last quarter and, using their column stats, further prunes individual data files.
The result? A query that would have taken hours on a traditional Hive table returns in seconds. This metadata-driven pruning is what makes interactive BI on massive datasets in the lakehouse possible.
11.3 Machine Learning Feature Stores
Reproducibility is non-negotiable in machine learning. If the training data changes, you can't reliably compare model results.
Snapshot Isolation for Training: ML engineers can "pin" their feature generation process to a specific Iceberg snapshot ID or a permanent tag. The metadata guarantees that no matter how much new data is ingested into the table by other teams, their training job will always read the exact same, consistent version of the data. This ensures that experiments are reproducible and model performance can be compared accurately.
Time Travel for Debugging: If a model's performance degrades in production, an engineer can use time travel to pull the exact data the model was trained on months ago to debug the issue, providing a perfect historical snapshot for analysis.
11.4 Governance and Auditing using Metadata Lineage
Data governance teams need to answer critical questions: "Who changed this data?", "What did this table look like at the end of last quarter?", and "What was the last operation run by the nightly ETL job?" The snapshot log within each metadata.json file serves as a perfect, immutable audit trail. Each snapshot entry records:
- The operation that created it (append, overwrite, delete).
- The timestamp of the commit.
- The application or user that performed the write.
This metadata lineage can be parsed to provide a complete history of the table's evolution, simplifying compliance checks, SOX audits, and data provenance tracking without needing to piece together clues from filesystem timestamps or external logs.
12. Decision Guide: How to Leverage Metadata Effectively
Understanding Iceberg's metadata is the first step, but translating that knowledge into a robust, performant, and cost-effective table design requires a thoughtful approach. The decisions made at the design stage will have a lasting impact on the table's entire lifecycle. It's about moving beyond the defaults and architecting a solution that fits your specific access patterns.
12.1 Designing for Performance: Schema, Partitioning, and Sorting
The foundation of any good table is a well-designed schema. While Iceberg makes evolution safe with fast, metadata-only operations, starting with clear column names and appropriate data types prevents future complexity. From there, the most critical design choice is the table's physical layout, which is primarily controlled by partitioning. The cardinal rule of partitioning is to choose columns with low cardinality that are frequently used in query filters. The goal is always to maximize data pruning. Common choices include dates, regions, or categories. Using Iceberg's built-in transforms like day(ts) or month(ts) is crucial for temporal columns to prevent an explosion of partitions.
A common pitfall is partitioning by a high-cardinality column like user_id, which creates an unmanageable number of small files and harms performance. For these high-cardinality columns, the correct strategy is data sorting. By defining a sort order in the table's metadata, you instruct writers to physically order data within each file. This allows query engines to skip large blocks of rows inside the files, providing a powerful secondary layer of data skipping that works in harmony with partition pruning.
12.2 Maintaining Table Health: Compaction and Snapshot Management
A well-designed table must also be well-maintained. For any production table, two ongoing processes are non-negotiable: data compaction and snapshot management. Over time, frequent writes will lead to the accumulation of small, inefficient files. Regular compaction is the essential remedy, a process where these small files are merged into larger, optimized ones (typically 512MB - 1GB). This reduces metadata overhead and significantly improves read speeds.
Equally important is managing the table's history. While time travel is a powerful feature, an infinite history leads to bloated metadata and prevents the cleanup of old data. You must implement a sensible snapshot expiration policy to define a retention window (e.g., 3-7 days). This not only keeps the table's history manageable but, more importantly, it enables garbage collection. Once old snapshots are expired, the maintenance process can safely identify and delete old data files that are no longer referenced by any valid snapshot, which is critical for controlling storage costs.
13. Migration Notes: Moving to Metadata-Centric Design
Migrating from a traditional Hive-style data lake to Apache Iceberg is more than a technical file conversion; it's a fundamental shift in thinking. The most common challenges arise not from the tools, but from carrying over old habits rooted in a filesystem-centric world. Embracing Iceberg's metadata-centric design from the start is key to a successful transition.
13.1 Common Pitfalls When Migrating from Hive
Many legacy Hive tables are not optimally structured, and simply migrating them "as-is" will prevent you from realizing the full benefits of Iceberg.
A primary pitfall is importing an overly aggressive partitioning scheme. In the Hive world, it was common practice to partition by high-cardinality columns. This was often done not for query performance, but as a crude way to organize files on the filesystem. Bringing a table with tens of thousands or even millions of partitions directly into Iceberg creates a massive metadata footprint. While still better than directory listing, query planning can slow down, and it almost always results in a severe small file problem. The migration process is the perfect opportunity to re-evaluate and simplify your partitioning. Your new scheme should be based on actual query patterns, using low-cardinality columns and partition transforms. High-cardinality access patterns should be addressed with data sorting, not partitioning.
Another common issue is directly migrating a table that already suffers from the small file problem. Simply converting thousands of small ORC or Parquet files into an Iceberg table just moves the issue into a new format. To start on the right foot, the migration job itself should include a compaction or data rewrite step. Iceberg's migration tools in Spark allow you to re-sort and coalesce data into optimally-sized files as part of the conversion process. This ensures the new Iceberg table is born in a healthy, performant state from day one.
13.2 Leveraging Metadata to Simplify Governance and Compliance
The shift to a metadata-centric model fundamentally enhances data governance, moving from a world of guesswork to one of verifiable guarantees.
In a Hive-style lake, auditing is a reactive and difficult process, often requiring a complex analysis of query logs and filesystem timestamps to piece together a table's history. With Iceberg, the snapshot log within the metadata serves as a built-in, immutable audit trail. Every single change to the table is recorded, answering who, what, and when for every transaction. This rich lineage can be easily parsed and fed into governance platforms for automated monitoring and reporting.
Furthermore, compliance requirements that were once a nightmare are now straightforward. For financial audits requiring perfect reproducibility, you can use time travel to query a table's exact state from a specific snapshot ID, providing a cryptographically certain view of the data at that time. For privacy regulations like GDPR or CCPA, which require the "right to be forgotten," Iceberg's row-level delete capabilities provide a surgical solution. Instead of a massive, risky job to rewrite entire partitions, you can issue a simple DELETE statement. This creates a new snapshot that clearly and auditably reflects the removal of specific data, simplifying compliance workflows immensely.
14. Summary: The Metadata is the Architecture
Throughout this deep dive, one principle stands above all others: in Apache Iceberg, the metadata is the architecture. It's far more than simple bookkeeping or a secondary index; it is the intelligent, self-contained backbone that elevates a collection of files into a true, high-performance database table on the data lake.
We've seen how this multi-layered system of catalogs, versioned metadata files, and manifests works in concert to deliver capabilities once thought impossible in the object store world. It's the metadata that frees us from the brittle and slow paradigm of directory listings, enabling surgical data pruning for fast queries. It's the atomic pointer swap in the catalog that provides the ACID guarantees necessary for reliable, concurrent data pipelines. And it's the immutable, versioned history of snapshots that unlocks powerful features like instantaneous rollbacks, safe schema evolution, and perfectly reproducible machine learning experiments.
By decoupling the logical table from the physical data layout, Iceberg's metadata provides a definitive source of truth. This allows diverse engines like Spark, Trino, and Flink to interact with the same data simultaneously and consistently, delivering on the promise of a truly interoperable data lakehouse.
Ultimately, Apache Iceberg represents a fundamental shift in how we manage data at scale. It treats metadata not as a necessary evil, but as the primary key to unlocking performance, reliability, and modern data engineering workflows. For any organization looking to build a robust and future-proof data platform, understanding and leveraging this powerful metadata system is no longer just an option—it is the path forward.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.