Apache Iceberg: Why This Open Table Format is Taking Over Data Lakehouses


Modern data lakehouses are embracing open table formats to bring reliability and performance to data lakes, and Apache Iceberg has emerged as a frontrunner. First developed at Netflix and now an Apache project, Iceberg is widely adopted as a foundation for large-scale analytics. It addresses the longstanding pain points of Hadoop-era data lakes (like Hive tables), delivering database-like capabilities, think ACID transactions, flexible schema changes, time travel queries, and speedy metadata-based reads. All this directly on cheap object storage like S3. In this article, we'll explain why Apache Iceberg is booming in modern lakehouse architectures, focusing on its core technical strengths and real-world engineering benefits.
Iceberg's Architecture: ACID Transactions and Snapshots
Iceberg tables use a snapshot-based architecture with a multi-layer metadata tree. A catalog (Hive, Glue, etc.) maintains a pointer to the latest table metadata, which in turn references manifest lists and files that index the actual data files. Every write creates a new snapshot (metadata file) and swaps the catalog pointer atomically, enabling ACID commits and snapshot isolation.
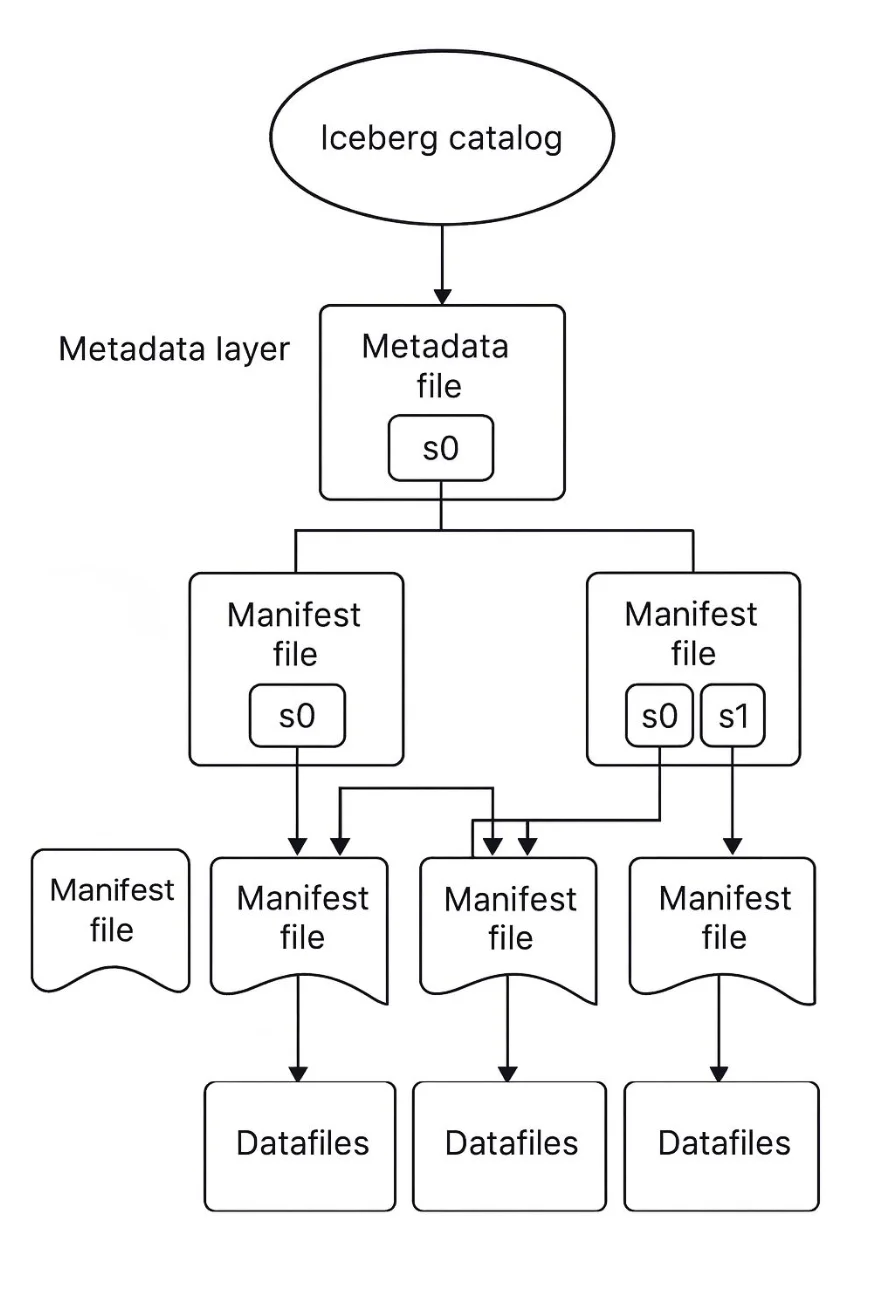
ACID transactions on a data lake, a dream in the old Hadoop world, is a reality with Iceberg. Thanks to its snapshot-based design, writes are atomic and readers always see a consistent table state. There are no partial writes or "dirty reads" even with concurrent jobs. Under the hood, committing a write in Iceberg is a single metadata swap: the catalog pointer flips from the old metadata JSON to a new one in one go. If a job fails mid-write, the old snapshot remains intact, and readers never see half-written data. Iceberg uses optimistic concurrency control (no locking); if two writers clash, one commit will fail and can be retried, preventing corrupt data races. This approach brings reliable transactional guarantees to data lakes that previously relied on fragile file replacements.
From an engineering standpoint, these ACID capabilities solve huge pain points. No more orchestration hacks to avoid readers seeing half a partition, no need to perform complex processes to get to a stable state from failed Hive jobs that left data in limbo. Iceberg's snapshot isolation means your ETL jobs and ad-hoc queries can coexist without stepping on each other. Data engineers can confidently build complex pipelines on a data lakehouse, knowing that concurrent reads/writes won't corrupt the data. In essence, Iceberg brings the reliability of a database to the openness of a data lake.
Seamless Schema Evolution and Versioning
One of Iceberg's superpowers is flexible schema evolution – the ability to change table schemas without painful rewrites or downtime. In legacy Hive tables, even adding a column often meant recreating tables or risking mismatched schemas. Iceberg was built to handle evolving data gracefully. You can add, drop, rename, or reorder columns and Iceberg will track these changes in its metadata, no rebuild required.
Each schema change generates a new snapshot version with the updated schema, while older snapshots retain the previous schema for consistency. Iceberg uses unique column IDs internally to manage fields, so even if a column is renamed, queries against old snapshots still work correctly by ID mapping. This mitigates the fragility and maintenance burden associated with strict positional schema mapping in traditional formats.
For data engineers, this means schema drift is no longer a pipeline-breaker. As your data sources evolve (new fields added, types changed), you can update the Iceberg table schema in-place. Downstream jobs can automatically pick up the new schema or even continue reading old snapshots if needed. No more week-long reprocessing of a petabyte sized table just to add a column!
Iceberg's approach maintains backward compatibility, so existing queries keep running on older schema versions while new data uses the new schema. This dramatically reduces downtime and manual work when requirements change. As a bonus, every schema change is versioned – giving you a full history of how the table's structure evolved over time.
Beyond column changes, Iceberg also supports partition evolution – you can change how the data is partitioned without rebuilding the entire table. For example, if you discover that daily partitions are too granular and want to switch to monthly partitions going forward, Iceberg allows that transition. The new partitions can use a different strategy, and the table's metadata will remember the older partitions' schema.
This kind of agility simply wasn't possible in the old Hive model (which required static partition keys and painful migrations). Iceberg's elegant handling of schema and partition evolution is a major reason experienced teams favor it for fast-changing data environments.
Time Travel: Instant Rollbacks and Historical Queries
Another killer feature of Iceberg is built-in time travel – the ability to query data as of a specific snapshot or time. Because Iceberg keeps a complete history of snapshots, you can run a query against last Friday's data or roll back the table to a previous state with ease. This is invaluable for recovering from bad writes (e.g., if a buggy job overwrote good data) and for auditing and reproducibility.
Data scientists can reproduce a report using the exact data state from a week ago, or analysts can compare current data to a snapshot from last month – all by simply specifying a snapshot ID or timestamp in their query.
Time travel in Iceberg is straightforward for the user: for example, in Spark SQL you might do SELECT * FROM table VERSION AS OF 123456 or use a timestamp.
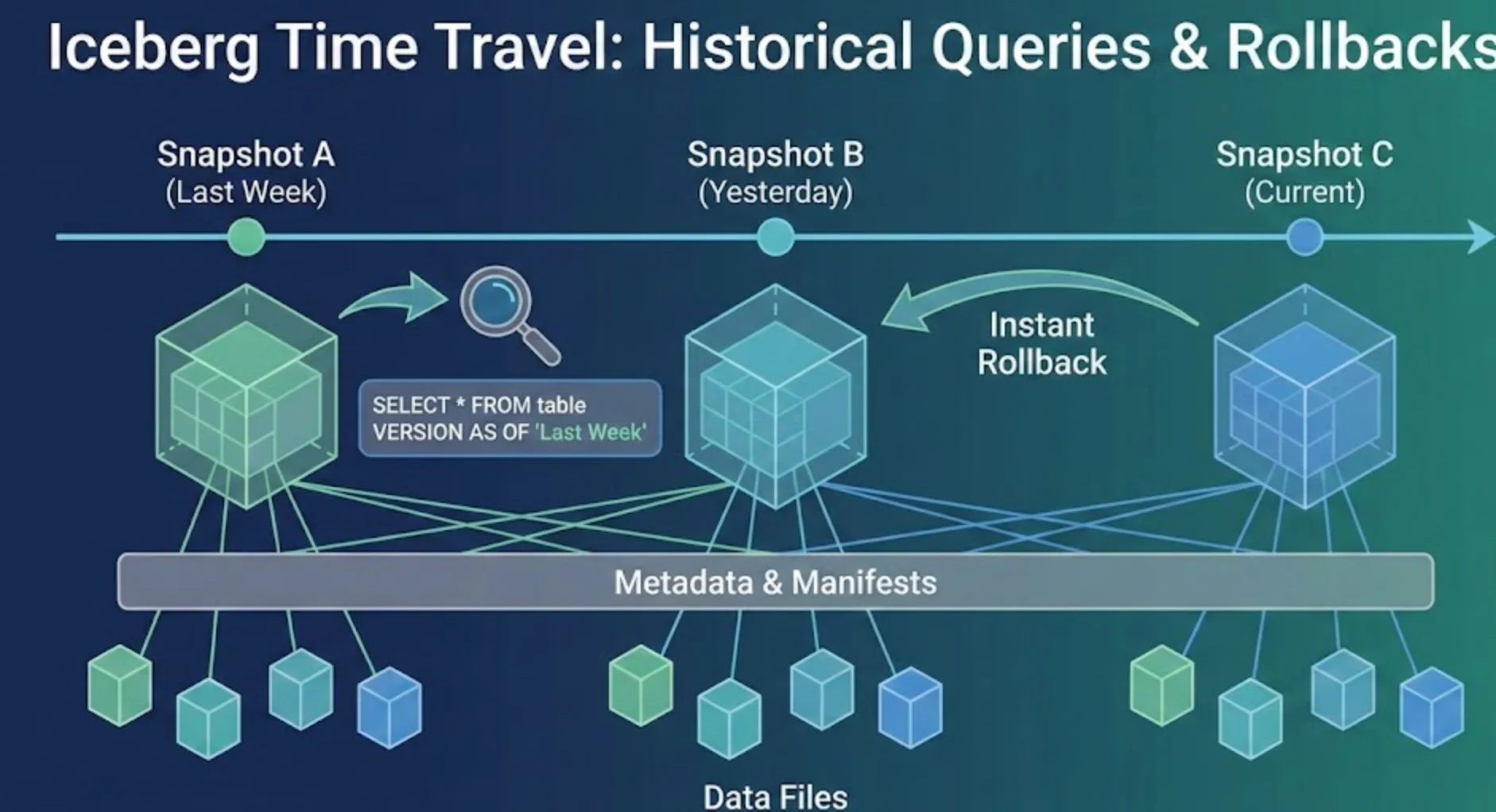
Under the hood, Iceberg's metadata makes this efficient. Each snapshot is like an immutable view of the table, referencing specific manifest files (which list the exact data files for that point in time). Query engines use the snapshot metadata to read exactly the files that were current then, skipping any newer data. There's no need to maintain separate "historical copies" of the same data – Iceberg handles it with metadata and pointers.
From an engineering perspective, this feature solves real pain points. Need to undo a bad ETL load? Just roll back the table to the previous snapshot – an atomic operation that flips the metadata pointer back. Need to debug why last week's numbers looked off? Query the old snapshot directly to investigate, no manual data restores required.
In highly regulated industries, the audit trail Iceberg provides (every data change is recorded in the snapshot log) is a huge plus for compliance. And if your enterprise has a data retention policy, Iceberg lets you expire old snapshots after a configured period to manage storage costs.
In short, time travel makes the data lakehouse both user-friendly and trustworthy, bringing Git-like version control to big data.
Hidden Partitioning and Query Performance Optimizations
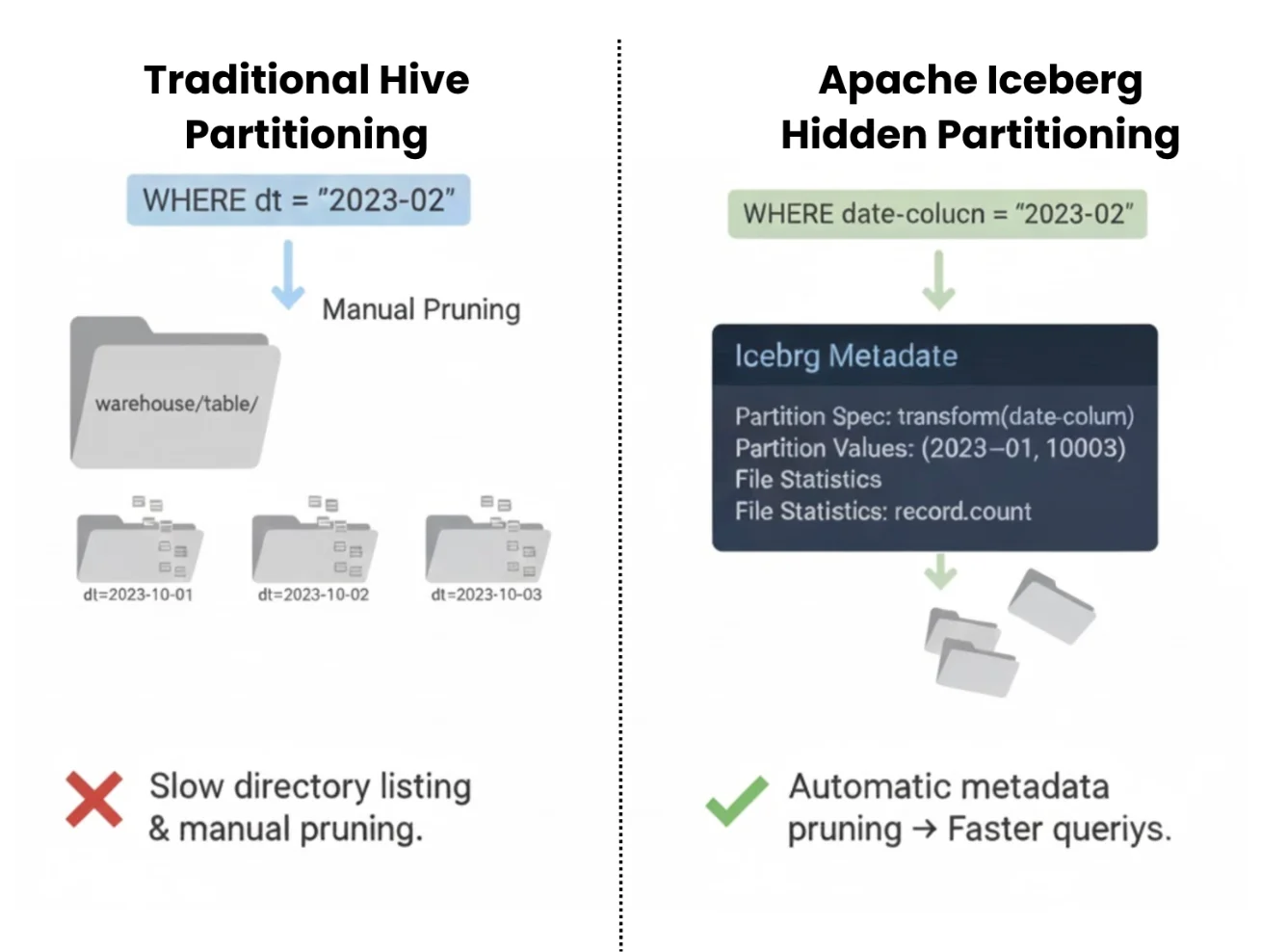
One of the most immediate benefits teams see with Iceberg is faster queries on their lakehouse data. Iceberg was designed to tackle the performance challenges of cloud object stores (like the notorious "many small files" problem and slow directory listing). It achieves this through rich metadata and hidden partitioning that enable powerful partition pruning and file skipping. Unlike Hive's folder-based partitions, Iceberg uses hidden partitioning where partition info is stored in metadata rather than in physical file paths. This diagram illustrates how Iceberg separates the logical partition schema (e.g., by date, bucket, etc.) from the actual file layout. The query engine reads partition values from Iceberg's metadata and avoids scanning irrelevant partitions or files automatically.
In traditional Hive tables, partitions were explicit folders and data pruning relied on naming conventions. This led to manual partition management and often millions of tiny files spread across directories.
Iceberg completely changes this. Partition values are computed and tracked in metadata (not hard-coded in directory/folder names), so users don't need to manually specify partitions in queries to get pruning benefits. For example, if a table is partitioned by date, a query with a date filter or or even hour or month filters will automatically skip non-matching partitions without the user having to know the partition column or path.
Iceberg essentially hides the complexity of partitions – preventing user errors and making SQL queries simpler while still reaping the performance gains. This metadata-driven approach also enables partition evolution as mentioned earlier (change partition strategy without painful reorganization, ex, if your data is coming at a much higher frequency compared to when you started, you can partition by hour rather than day for newly coming data).
Iceberg keeps track of file statistics (min/max values, record count, etc.) in manifest files, and query engines use those stats to skip entire files that don't match a filter. Instead of listing thousands of files in HDFS or S3, a query can consult Iceberg's manifest to find just the data it needs. The result is dramatically less I/O.
In practice, teams often see 2–3x faster queries after moving from legacy Hive/Parquet tables to well-partitioned Iceberg tables, mainly because engines can use Iceberg's metadata and file-level stats to skip most irrelevant files. Iceberg also provides utilities to compact small files in the background, so streaming ingestion or incremental writes won't degrade read performance over time.
From an engineering vantage, Iceberg's metadata pruning means you can keep using cheap cloud storage for analytics without suffering the usual performance penalties. It brings the query efficiency closer to that of data warehouses by eliminating expensive full-table scans and directory traversals. Combined with features like sorted merge ordering and explicit optimization commands for administrators, Iceberg gives data engineers fine-grained control to keep queries fast.
Engine-Agnostic Design for Multi-Engine Workloads
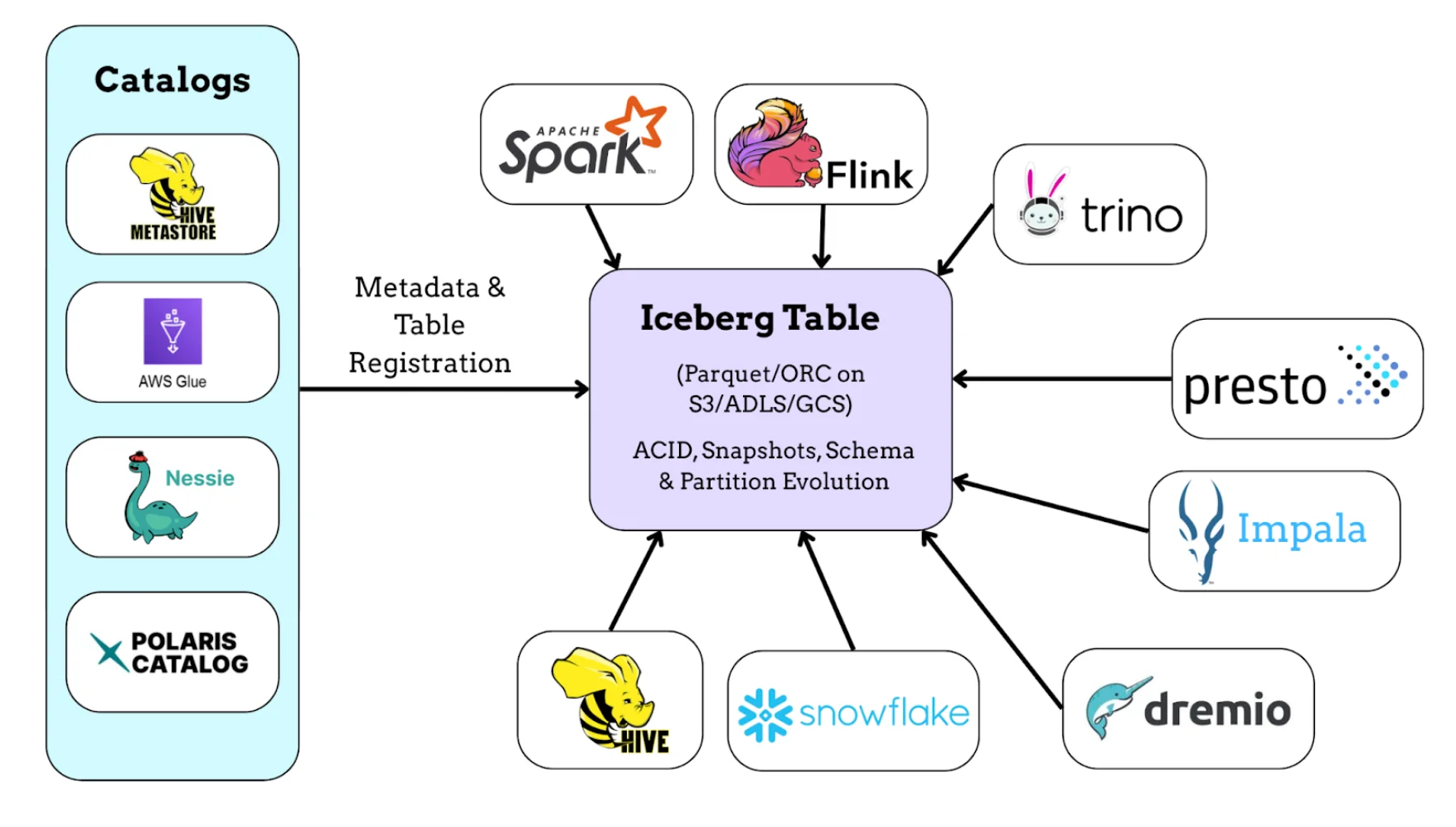
A major reason Apache Iceberg is gaining traction is its engine-agnostic design. In modern data platforms, you might have Spark for big batch jobs, Flink for streaming, Trino/Presto for interactive SQL, and so on. Iceberg's table format is not tied to any single processing engine or vendor, which means the same Iceberg table can be read and written by many tools concurrently. This interoperability is a game-changer for building flexible, future-proof data stacks.
Iceberg achieves this by providing a well-defined open specification and a variety of catalog implementations. You can register Iceberg tables in a Hive Metastore, AWS Glue Data Catalog, a JDBC database, a REST catalog like Nessie, or even Snowflake's catalog – whatever fits your infrastructure. All engines then use the Iceberg API or table spec to access the data consistently.
For example, you might ingest streaming data with Apache Flink into an Iceberg table, and simultaneously have analysts querying that same table via Trino – all without data copies. Iceberg guarantees that each engine sees a consistent view of the data and respects the ACID transactions/snapshots. This breaks down data silos that used to require complex export/import or dual pipelines for different systems.
The engine-agnostic nature of Iceberg also protects you from lock-in. Since it's an open standard on files like Parquet/ORC, you're not forced into one vendor's compute engine. Companies have adopted Iceberg as the common table layer so they can plug in new query engines as needs evolve. Want to try a new SQL engine or leverage cloud services like Athena or Snowflake on your lake data? Iceberg makes that feasible because those systems are increasingly adding Iceberg support as well.
In fact, Iceberg currently works with Spark, Flink, Trino, Presto, Hive, Impala, Dremio, and even Snowflake and BigQuery can interface with Iceberg tables. This broad ecosystem support is something earlier formats never achieved.
For experienced data engineers, this means you can build multi-engine architectures without extra complexity. A single source-of-truth dataset in Iceberg can serve real-time dashboards (via Trino), feed ML feature jobs in Spark, and ingest CDC streams in Flink – all orchestrated on the same table. It enables the coveted "write once, use anywhere" paradigm for data.
This engine flexibility also helps future-proof your platform: you can adopt new processing frameworks or migrate workloads without migrating the data. Iceberg truly decouples storage from compute, letting you choose any of the compute engines for your workloads.
Iceberg Format v3 and v4: Why the Future of Iceberg Looks So Strong
One of the reasons Apache Iceberg feels like a safe long-term bet is that the format itself is still evolving in meaningful ways. Format v3 (already part of the spec) and v4 (in progress) aren't just cosmetic tweaks – they push Iceberg from "great lake tables" toward a universal data layer that can handle messy data, heavy CDC, and real-time workloads.
Format v3: Making Iceberg Fit the Data You Actually Have
Format v3 is all about making Iceberg match the shape of modern data, not just tidy fact tables.
First, it introduces richer types like VARIANT (for semi-structured JSON/Avro/Protobuf), geospatial types (GEOMETRY / GEOGRAPHY), and nanosecond-precision timestamps. In practice, that means:
- You no longer have to shove JSON into STRING and re-parse it in every query.
- Query engines can push predicates into nested fields, keep sub-column stats, and prune files more aggressively.
- You can keep location data, events, and observability streams in the same Iceberg table instead of splitting them across side systems.
On top of that, v3 adds default column values and more expressive partition transforms. Adding a new column with a default doesn't force a giant backfill; old files implicitly use the default, and new data gets the real value. The v3 spec introduces source-ids for partition/sort fields so that a single transform can reference multiple columns (multi-argument transforms).
v3 also bakes in row lineage and table-level encryption hooks at the spec level. That's a strong signal that Iceberg is thinking beyond raw performance: it's making it easier to answer "where did this row come from?" and to plug into governance/compliance stories without every vendor inventing its own hack.
Finally, v3 introduces binary deletion vectors – compact bitmaps for row-level deletes. Instead of joining against a pile of delete files, engines can just consult a bitmap to know which rows to skip. If you're doing CDC from OLTP into Iceberg, this is what keeps row-level updates fast and predictable even as churn grows.
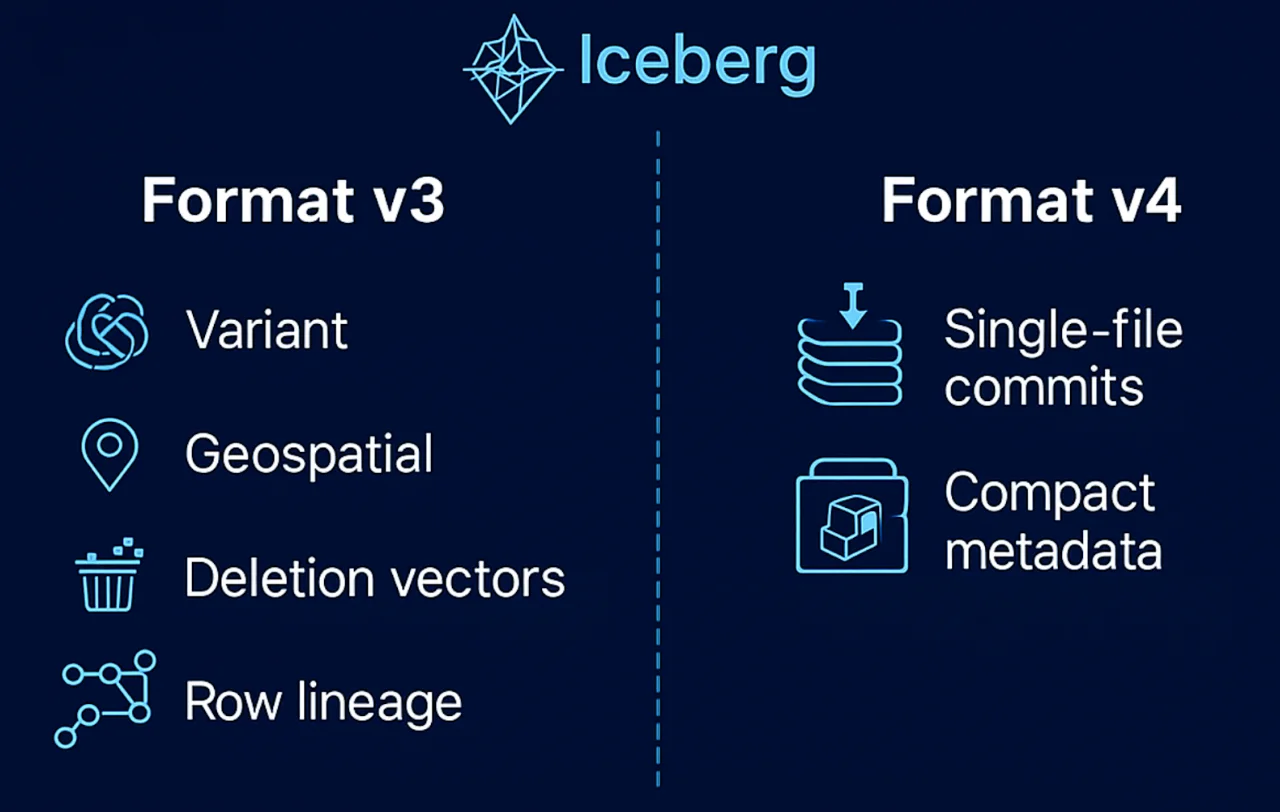
Format v4: Making Iceberg Cheaper and More Real-Time Friendly
Where v3 focuses on modeling and governance, v4 is aimed squarely at operational efficiency, especially for streaming and high-frequency workloads.
The big theme is fixing metadata write amplification. Today, even a small update can write multiple metadata artifacts (metadata.json, manifest list, manifests). v4's "single-file commit" direction is about collapsing that into one logical artifact per commit. The practical impact: lower metadata I/O, faster commits, and a much nicer experience when you're committing frequently (think Flink/Spark streams writing every few seconds or small tables with lots of updates).
There's also work around more compact, Parquet-based metadata and richer column stats, so metadata itself is smaller, faster to scan, and more informative. That helps both ends of the spectrum: petabyte-scale tables and smaller, hot tables that get hammered by queries and updates.
Overall, the v4 direction is: Iceberg shouldn't feel heavy when you treat it as the sink for a busy stream. It's not just "we support streaming" on a slide – it's about making sure lots of small commits remain cheap and responsive.
Why This Matters If You're Betting on a Format
If you zoom out, v3 and v4 together say:
- Iceberg is expanding to cover more data shapes (semi-structured, geospatial, high-frequency).
- It's getting better tools for CDC and governance (deletion vectors, lineage, encryption hooks).
- It's actively addressing real-time and operational pain points (single-file commits, compact metadata).
So if you're a data engineer choosing a table format you'll live with for the next decade, v3 and v4 are a pretty clear signal: Iceberg isn't just solid today – it's evolving in the exact directions modern data platforms need.
Real-World Use Cases and Scenarios
To ground these features in reality, let's look at some scenarios where Iceberg shines and is driving modern data lakehouse adoption.
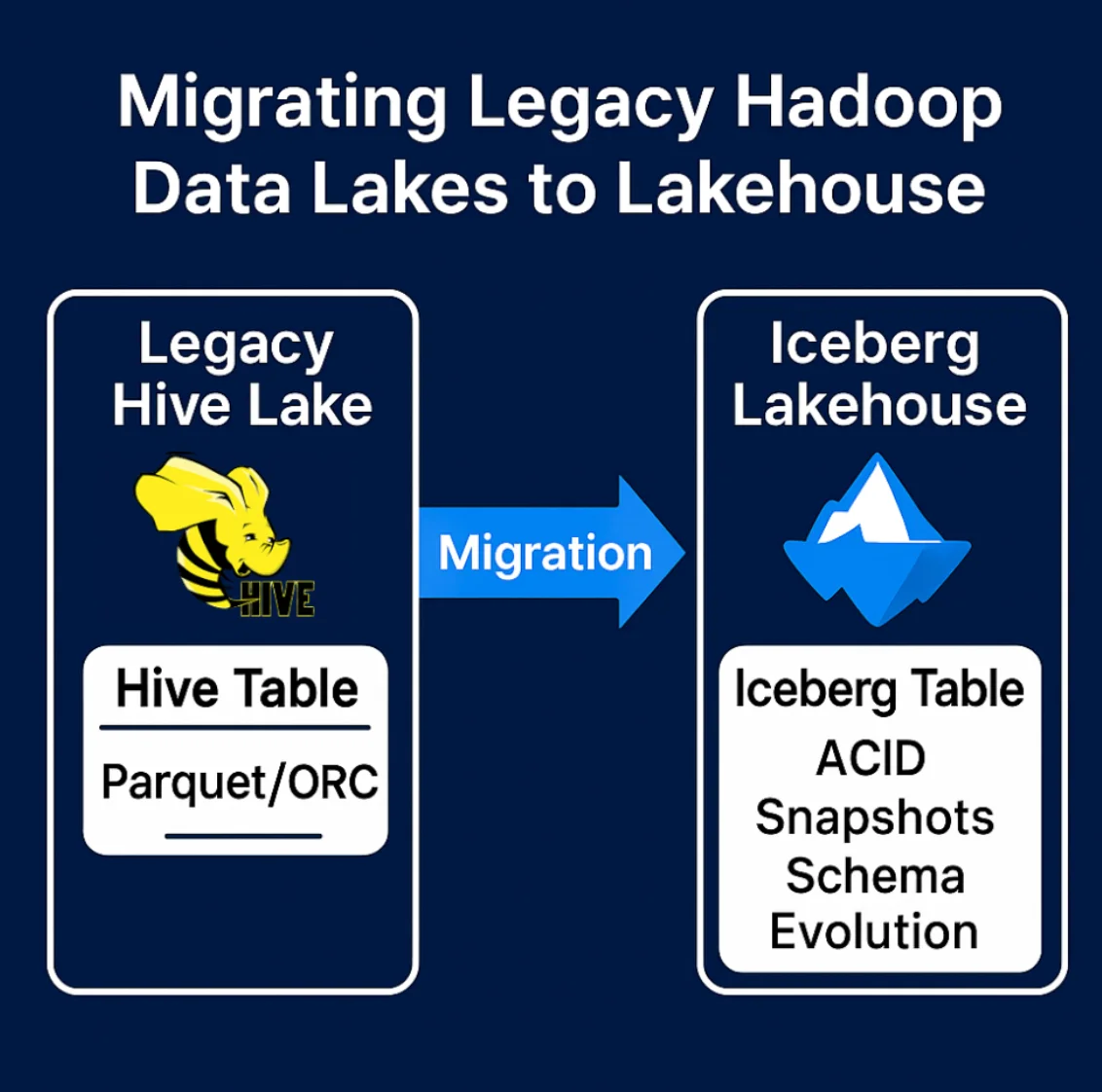
Migrating Legacy Hadoop Data Lakes to Lakehouse
Many organizations are in the midst of modernizing old Hadoop/Hive-based data lakes. Apache Hive was great in 2010 but had critical limitations: no true ACID, tons of tiny files from partitioning, costly updates/deletes, and clunky schema management.
Apache Iceberg was literally created to solve these issues. Companies moving off of Hive or other legacy table formats often choose Iceberg as the landing spot for their data in the cloud. Apache Iceberg ships with built-in migration tools (Spark procedures and Hive storage handlers) that can convert many existing Hive tables to Iceberg by layering Iceberg metadata on top of the existing Parquet/ORC/Avro files, so you avoid a full data rewrite in most cases. Full rewrites are only needed when you want to change partitioning/layout, fix incompatible schema issues, or migrate from unsupported storage formats.
The "small files problem" is reduced thanks to Iceberg's file compaction and metadata pruning (only after we fully migrate), and queries speed up because the costly Hive Metastore directory listings are replaced by fast metadata lookups. Essentially, Iceberg replaces Hive's aging storage layer with a more robust one, while still letting you use Hive's SQL if needed or, more likely, letting you transition to faster engines like Trino or Spark SQL on the same data.
Real-world example: Netflix (where Iceberg originated) moved from a monolithic Hive-based datalake to Iceberg to handle petabytes of data with better efficiency and schema flexibility. Other big players like Stripe and Pinterest have also adopted Iceberg as they outgrew Hive's limitations. If you have a large data lake on HDFS or cloud storage and are struggling with Hive table fragility, Iceberg offers a proven path to an open lakehouse with reliability comparable to a data warehouse, but on your existing storage.
Governance, Auditing, and Lineage at Enterprise Scale
As data platforms grow, governance and lineage become increasingly important – enterprises need to know where data came from, how it's changed, and to ensure adherence to policies (for compliance, privacy, etc.). Iceberg's rich metadata layer provides a strong foundation for these needs.
Every change in Iceberg is recorded as a new snapshot with timestamps, user ids (if propagated), and a full diff of added/deleted files. This means you have an audit log of data changes by default.
If someone accidentally deletes records or a buggy job writes bad data, it's straightforward to identify when it happened and revert it.
Iceberg also enables branching and tagging of data versions, akin to Git branches. This is an emerging area, but it means you can have, for example, a development branch of a table to test transformations on a snapshot of production data, and then merge it to main when validated – all without copying data. This "Git for data" approach, supported by Iceberg's metadata, is a powerful concept for governance: it allows isolation of experimental changes and safe collaboration across teams on the same dataset.
Moreover, because Iceberg is open and engine-agnostic, it integrates with enterprise data catalogs and governance tools. You can plug Iceberg metadata into your data catalog to track lineage – e.g., which dashboards or AI models are using which snapshot of data.
The time-travel feature also means you can always reproduce the exact data that was used for a report or a machine learning model training, which is crucial for auditability and compliance.
While Iceberg alone isn't a full governance solution (you'd use a metadata catalog for that), it supplies the granular metadata (snapshots, schemas, partition stats) needed to build one.
Companies aiming for strict data governance appreciate that Iceberg brings control and visibility to their data lake, whereas older file-only approaches were a black box of files.
Conclusion: Iceberg as the Future of the Data Lakehouse
Apache Iceberg has quickly become a top choice for data engineers building scalable lakehouse platforms. By combining warehouse-like features (ACID transactions, SQL support, fast queries) with the flexibility of data lakes (cheap storage, open format, multi-tool access), Iceberg offers the best of both worlds. Its technical strengths – atomic snapshots, schema evolution, time travel, hidden partitioning, and engine interoperability – directly solve the pain points of the past generation of data lakes. No surprise that we're seeing a clear trend of teams (from Netflix and Apple to adopters in finance and healthcare) migrating to Iceberg for large analytic datasets.
For experienced data engineers, Iceberg means you no longer have to choose between reliability and openness. You can build a robust data platform on cloud storage that is open, scalable, and consistent. It lowers the barrier to implement a true data lakehouse architecture: one data repository serving batch processing, reporting and model training needs together. While adopting Iceberg requires learning its APIs and thinking in terms of snapshots, the learning curve is well worth it. The sooner your tables are under Iceberg, the sooner you can stop worrying about Hive quirks, broken pipelines on schema changes, or uncontrollable file sprawl.
Apache Iceberg is widely adopted for good reason – it brings sanity to big data management. It empowers data engineers to focus on high-value logic rather than babysitting file layouts and recovery scripts. As the open table format ecosystem matures, Iceberg stands out as a future-proof choice that will likely underpin data lakehouses for years to come. If you're evaluating modern table formats, Iceberg's balance of performance, flexibility, and openness makes it a compelling option to take your data lake to the next level.
Ready to build your Data Lakehouse with Apache Iceberg? OLake provides seamless CDC replication from operational databases directly to Iceberg tables, making it easy to create a modern lakehouse architecture. Check out the GitHub repository and join the Slack community to get started.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.