Apache Iceberg vs Hive: Data Lakehouse Comparison Guide


Apache Hive and Apache Iceberg represent two different generations of the data lake ecosystem. Hive was born in the Hadoop era as a SQL abstraction over HDFS, excelling in batch ETL workloads and still valuable for organizations with large Hadoop/ORC footprints. Iceberg, by contrast, emerged in the cloud-native era as an open table format designed for multi-engine interoperability, schema evolution, and features like time travel. If you are running a legacy Hadoop stack with minimal need for engine diversity, Hive remains a practical choice. If you want a flexible, future-proof data lakehouse that supports diverse engines, reliable transactions, and governance at scale, Iceberg is the more strategic investment.
Hive vs Iceberg — Feature Comparison at a Glance
| Feature | Apache Hive | Apache Iceberg |
|---|---|---|
| Origin | Introduced by Facebook (2008) as a SQL-on-Hadoop layer | Introduced by Netflix (2017) as an open table format |
| Storage Abstraction | Works over HDFS, ORC, Parquet (engine tightly coupled to Hadoop) | Engine-agnostic table format, works with Parquet, ORC, Avro |
| Metadata & Catalog | Hive Metastore (centralized, single-point bottleneck) | Multiple catalogs: Hive Metastore, AWS Glue, REST Catalog; supports multi-engine |
| Schema Evolution | Limited: add columns easy, renames/drops tricky, often requires table rewrite | Robust: add/drop/rename/change types without rewriting data |
| Partitioning | Manual/static partitions; dynamic partition insert; buckets | Hidden partitioning, partition evolution; optimized pruning |
| Transactions (ACID) | ACID via delta/base ORC files, requires compaction; limited concurrency | Snapshot isolation, atomic commits, concurrent writers supported |
| Time Travel / Rollback | Basic options via file versions or manual backups | Native snapshots, rollback to any previous version, audit-friendly |
| Performance | Dependent on Hive engine + Hadoop cluster tuning; metadata queries slow at scale | Fast metadata ops via manifests, pruning, snapshot metadata |
| Engine Support | Primarily Hive, limited support in Spark/Presto with connectors | Wide support: Spark, Flink, Trino, Presto, Athena, Snowflake, Dremio, etc. |
| Best For | Legacy Hadoop workloads, existing ORC + Hive ACID users, batch ETL | Multi-engine analytics, governance, schema/partition evolution, cloud-native lakes |
| Operational Overhead | High: compaction, partition management, tuning needed | Lower: auto metadata management, simpler operations |
Introduction: From Big Data to the Lakehouse
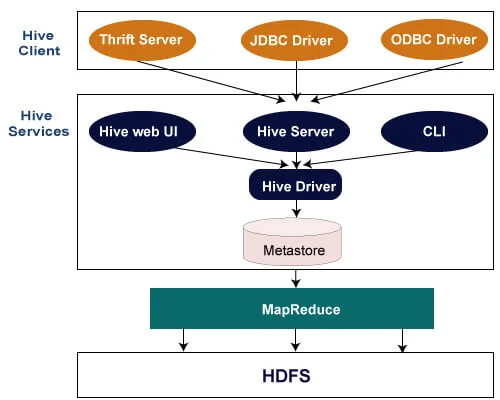
The story of Hive and Iceberg cannot be told without revisiting the rise of big data itself. In the late 2000s, enterprises were drowning in information: logs, clickstreams, transactions, and sensor readings were being generated at a scale traditional relational databases could no longer manage. Hadoop emerged as the first serious answer to this challenge. By distributing storage across clusters of inexpensive commodity hardware, Hadoop's distributed file system (HDFS) made it possible to store petabytes of data reliably and cost-effectively. On top of this, MapReduce enabled parallelized computation, which was powerful but hardly user-friendly. To extract value from Hadoop, developers had to write verbose code for even the simplest queries.
Apache Hive, created at Facebook in 2008, bridged this usability gap. By offering a familiar SQL-like interface, Hive allowed analysts to query massive datasets using a language they already knew. Behind the scenes, Hive translated these queries into MapReduce jobs, hiding the complexity of distributed computation. It became the default way organizations interacted with their Hadoop clusters, unlocking large-scale batch analytics for companies that otherwise would have struggled to harness their growing data estates.
But while Hive opened new possibilities, its design was firmly rooted in the assumptions of the Hadoop era, and those assumptions soon became limitations. Query latency was measured in minutes or hours, an acceptable compromise in the early days of batch-oriented reporting but increasingly frustrating as expectations shifted toward interactive exploration. Metadata management through the Hive Metastore proved to be a bottleneck at scale, and once a partitioning strategy was chosen, it was notoriously difficult to adapt as business needs changed. Later enhancements, such as ACID transactions built on ORC files, improved reliability but at the cost of additional operational overhead, including constant compaction jobs. Most importantly, Hive tables were tightly coupled to the Hive execution engine, making it difficult to bring in newer engines like Spark or Presto without friction.
By the mid-2010s, the world had begun to move on. Cloud object stores such as Amazon S3 and Azure Blob Storage changed the economics of data management. Unlike HDFS, these stores were virtually limitless, required no cluster maintenance, and decoupled storage from compute. Crucially, they could be accessed by many different processing engines at once. This shift made it clear that the future of analytics would not be tied to a single execution engine or a monolithic Hadoop cluster. Instead, what was needed was a way to treat data in these lakes as structured, governed tables—accessible in a consistent manner regardless of the engine performing the computation.
It was this need that gave rise to open table formats such as Apache Iceberg. First developed at Netflix and later donated to the Apache Software Foundation, Iceberg redefined the role of metadata in a data lake. Instead of relying on a centralized metastore designed around static partitions, Iceberg introduced a more sophisticated metadata layer capable of handling schema evolution, partition evolution, atomic transactions, and even time travel. These capabilities unlocked new patterns: tables could evolve as business requirements changed, concurrent writers could safely operate on the same dataset, and analysts could roll back to a consistent snapshot for reproducibility or audit.
The convergence of these innovations led to what is now commonly referred to as the lakehouse. A lakehouse combines the flexibility and scale of a data lake with the reliability and governance traditionally associated with a warehouse. Data is stored in open formats such as Parquet or ORC, governed through table formats like Iceberg, and made available to multiple engines—be it Spark for data engineering, Trino for ad hoc queries, Flink for streaming, or BI tools for dashboards. In this model, storage and compute are decoupled, but governance ensures consistency across workloads.
Hive, in many ways, represents the first wave of democratizing big data, while Iceberg is emblematic of the second wave: the recognition that data must remain open, interoperable, and evolvable if it is to serve the diverse needs of modern analytics. Hive made Hadoop usable. Iceberg makes the data lakehouse governable.
Background & Evolution
What is Apache Hive?
When Apache Hive emerged in 2008, it was nothing short of revolutionary for the Hadoop ecosystem. At its core, Hive was designed as a SQL abstraction layer over Hadoop's distributed storage and processing. Its promise was simple but powerful: analysts could query petabytes of data using a language that looked and felt like SQL, without needing to understand the intricacies of MapReduce or distributed systems. This accessibility dramatically expanded the audience for big data analytics, opening the door to business analysts and data scientists who would have otherwise been excluded by Hadoop's complexity.
The architecture of Hive revolved around a few key components. The most important was the Hive Metastore, which tracked metadata about tables, schemas, partitions, and file locations. It allowed Hive to translate SQL queries into jobs that could locate the right files across HDFS and process them in parallel. For storage, Hive typically relied on columnar formats such as ORC or Parquet, which were optimized for analytics and compression. Over time, Hive also introduced support for ACID transactions, particularly through ORC-backed tables. These features made Hive more reliable but also more complex, as transactions required background compaction and strict maintenance to avoid data bloat and query slowdowns.
Despite its limitations, Hive became the cornerstone of the Hadoop era. For years, it powered batch ETL pipelines, reporting systems, and early data warehouses at internet-scale companies. Its dominance was not simply because it was perfect, but because it was the first widely adopted solution that made big data usable at all.
What is Apache Iceberg?

Almost a decade later, Netflix faced a different challenge. Hadoop and Hive had made big data accessible, but the company's data lake had grown unwieldy. As multiple teams worked on the same datasets, schema changes became disruptive, partitioning strategies locked tables into rigid designs, and ensuring consistency across engines proved increasingly difficult. What was needed was a new foundation: one that separated the definition of a table from the execution engine, and one that treated metadata as a first-class citizen rather than a sidecar.
Apache Iceberg, born out of these needs in 2017, redefined how data in a lake could be managed. Unlike Hive, Iceberg is not an execution engine. Instead, it is a table format—a specification for how to structure metadata, schema, and partitions in a way that is both engine-agnostic and highly flexible. Its design enables features that were difficult or impossible in Hive. For example, schema evolution in Iceberg allows columns to be added, dropped, or renamed without rewriting terabytes of underlying data. Partitioning strategies can evolve over time, with Iceberg handling the translation so queries still work seamlessly. Transactions are handled through snapshot isolation and atomic commits, eliminating the need for constant compaction and reducing operational pain.
Perhaps Iceberg's most striking feature is its support for time travel. Each table operation—whether an insert, update, or schema change—creates a new snapshot. Analysts and engineers can query data "as of" a given snapshot, enabling reproducibility, rollback, and auditability in ways that Hive never fully supported. Combined with its compatibility across a growing ecosystem of engines—Spark, Flink, Trino, Presto, Athena, Snowflake, and more—Iceberg quickly became the flagship of the open table format movement.
Why Table Formats Changed the Lake Game
The introduction of table formats like Iceberg represented a paradigm shift in how organizations thought about data lakes. In the Hadoop world, the lake was simply a collection of files, and governance was layered on top in somewhat ad hoc ways. Hive's metastore provided a centralized catalog, but it was tightly bound to Hive itself and limited in what it could express. The assumption was always that one engine—Hive—would be in control.
Table formats broke this assumption by decoupling the metadata layer from any single execution engine. Instead of forcing data to conform to one processing framework, Iceberg and its peers created a standard way of describing tables that any compliant engine could understand. This separation of storage and compute, underpinned by a robust metadata system, is what makes the lakehouse possible.
In this sense, Hive and Iceberg embody two different eras of data management. Hive was built to tame Hadoop, bringing SQL to a distributed file system. Iceberg was built to tame the chaos of modern data lakes, where multiple engines, schemas, and workloads collide on the same storage. Hive democratized big data for the first time. Iceberg is democratizing it again, but in a way that is open, interoperable, and future-proof.
Architectural Foundations: Hive vs Iceberg
When comparing Hive and Iceberg, the most important distinctions are not cosmetic but structural. The way each system manages metadata, organizes files, and enforces consistency determines how they behave under real workloads. These architectural choices explain why Hive thrived in the Hadoop era and why Iceberg has become a cornerstone of the lakehouse movement today.
Metadata and Catalogs
At the heart of Hive lies the Hive Metastore, a centralized relational database that records information about tables, schemas, partitions, and file locations. Every Hive query depends on the Metastore to resolve where data lives and how it is structured. While this worked well for smaller deployments, it became a bottleneck at scale. As the number of tables and partitions grew, Metastore lookups slowed down, and the service itself became a single point of failure. Hive's catalog was designed for Hive's engine first, and though Spark, Presto, and others later added connectors, the experience was rarely seamless.
Iceberg reimagines metadata from the ground up. Instead of a single relational metastore, it uses a layered metadata system that lives with the data. A table in Iceberg is defined not by directories and partitions in the file system, but by metadata files that capture its schema, partitioning rules, snapshots, and versions. On top of this, Iceberg can plug into multiple catalog systems: it can still use the Hive Metastore for backward compatibility, rely on cloud-native services such as AWS Glue, or leverage its own REST-based catalog for distributed governance. This modularity makes Iceberg far more adaptable in cloud and hybrid environments.
Table Layout and File Organization
Hive's approach to organizing data was grounded in the realities of Hadoop. Data was typically stored in partitions—directories on HDFS—often defined by high-cardinality fields such as date or region. Queries filtered on these partitions would scan fewer files, improving performance. However, this model was brittle. If the partitioning scheme no longer fit the query workload, tables had to be rewritten. Bucketing added another layer of optimization, distributing rows into fixed groups, but it too was rigid and required forethought. These limitations meant that design decisions made at the time a table was created could have long-lasting consequences.
Iceberg replaces this rigidity with a dynamic and self-describing structure. Instead of directories, it uses metadata and manifests that track the files belonging to a table, along with rich statistics about their contents. Partitioning is defined declaratively in the metadata, not in the physical directory layout, and it can evolve over time. For example, a table originally partitioned by day can later be redefined to use monthly partitions, and Iceberg ensures queries remain consistent across both generations. This abstraction not only reduces operational headaches but also enables engines to perform aggressive pruning based on metadata without scanning unnecessary files.
Concurrency and Transactions
One of the most significant architectural differences between Hive and Iceberg lies in how they handle concurrent writes and transactional guarantees. Hive introduced ACID tables to bring transactional reliability to the data lake, but the implementation leaned heavily on ORC files and a system of delta and base files. Every write created delta files, which had to be merged into base files during compaction. Without regular compaction, query performance degraded quickly. While functional for low- to moderate-concurrency workloads, Hive ACID was never designed for the level of parallelism demanded by modern CDC and streaming pipelines.
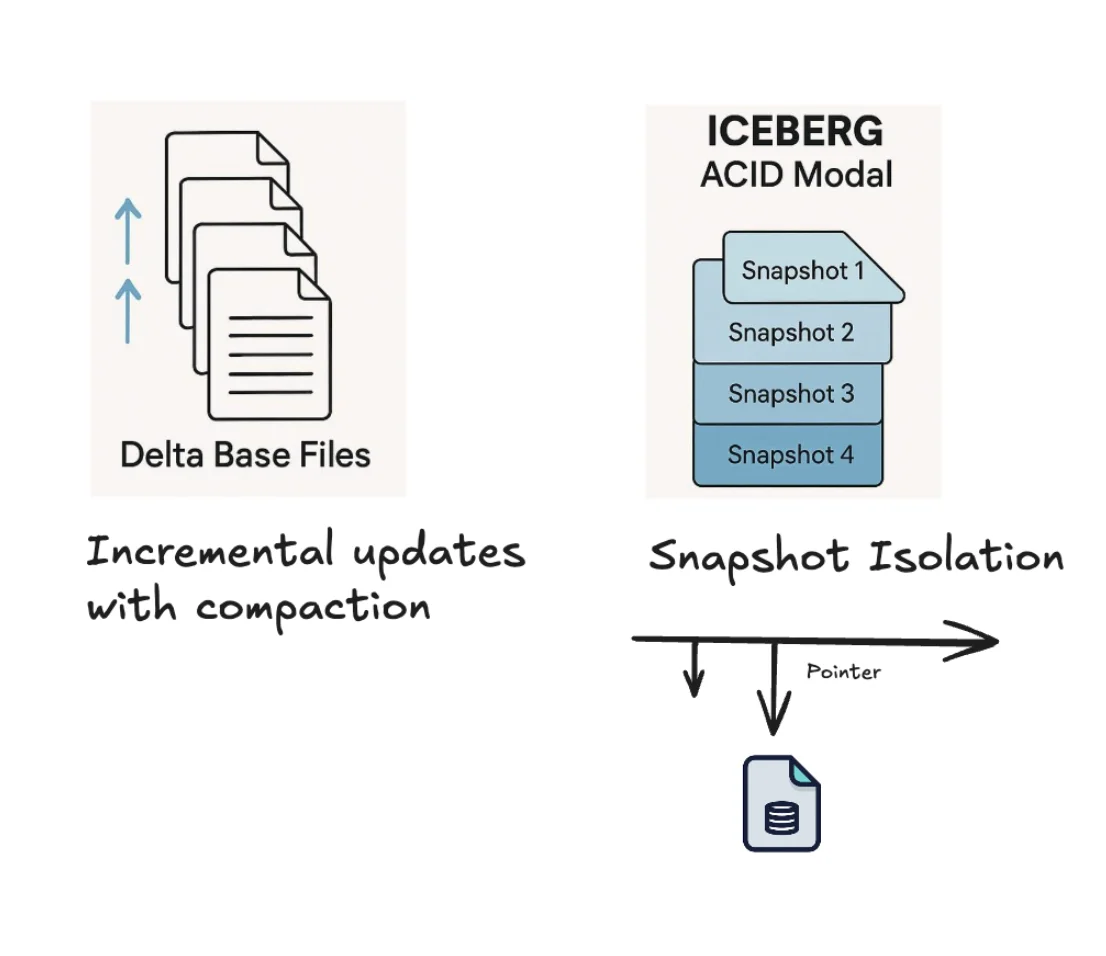
Iceberg, in contrast, treats transactions as a first-class concern. Its design is based on snapshot isolation and atomic commits. Every operation—whether it is an insert, update, or schema change—creates a new snapshot of the table. Writers operate against the latest snapshot, and when they commit, the catalog atomically advances the table pointer to the new version. This eliminates the need for compaction jobs and allows multiple writers to work in parallel without corrupting the table state. The snapshot model also underpins Iceberg's time travel features, giving it a strong advantage in governance and reproducibility.
In essence, Hive's architecture reflects the constraints and goals of its time: a centralized metastore, rigid partitioning, and transactional features bolted on to an HDFS-first system. Iceberg, designed a decade later, embodies the lessons learned: metadata must be distributed and evolvable, file layouts should be abstracted, and transactions must be lightweight but reliable. These architectural foundations explain not only why Iceberg is more flexible but also why it integrates more naturally into today's diverse, cloud-native data stacks.
Key Feature Comparison (Deep Dive)
The architectural foundations of Hive and Iceberg reveal their contrasting philosophies, but it is in their day-to-day features that the differences become most tangible. These are the capabilities practitioners interact with constantly, and they often determine whether a system feels enabling or constraining.
Schema Evolution
Hive's support for schema evolution has always been partial and somewhat fragile. Adding a new column is straightforward enough, but operations such as renaming or dropping columns are problematic. In practice, dropping a column might leave behind residual data that future queries need to navigate carefully, while renaming often results in mismatched metadata between the Metastore and the underlying files. More complex changes, such as altering column types, typically require a full table rewrite, which can be prohibitive at scale.
Iceberg was built with schema evolution in mind. It tracks columns by unique IDs rather than by name or position, which means columns can be safely renamed without breaking queries or requiring file rewrites. Dropping or adding columns is similarly lightweight, and even type changes can often be accommodated without rewriting underlying data. This design makes schema evolution a routine part of table management rather than a disruptive event, which is particularly valuable in environments where data models must adapt quickly to business needs.
Partitioning
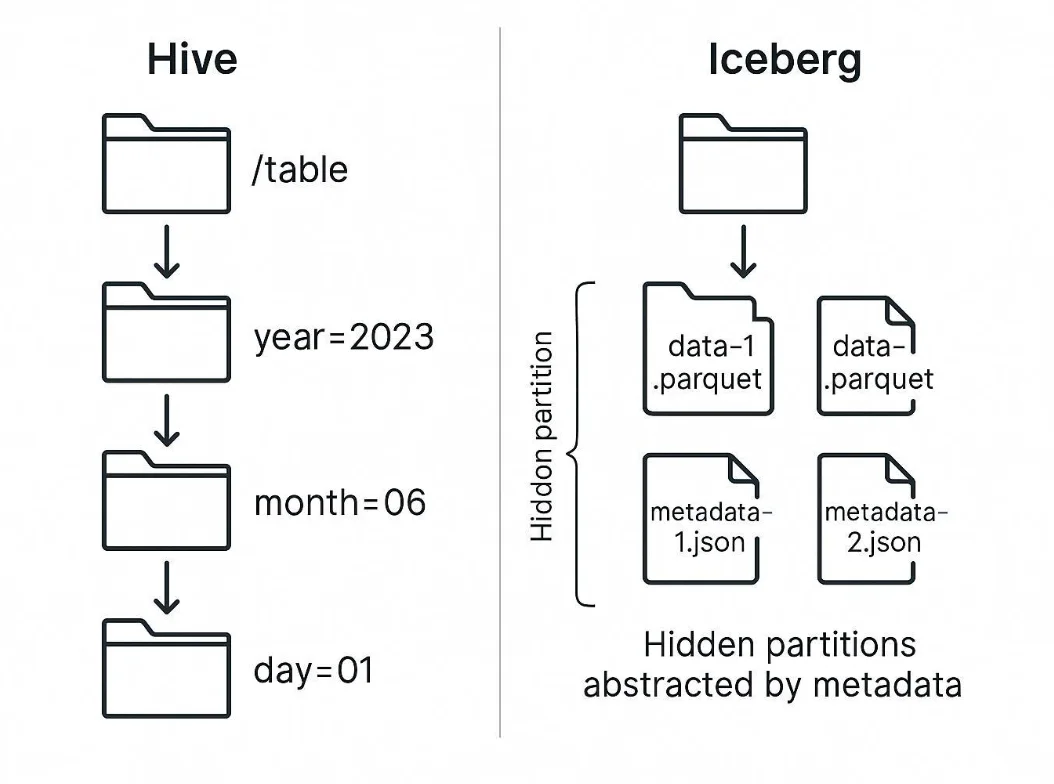
Partitioning is another area where Hive shows its Hadoop heritage. Data in Hive is partitioned by creating directories for each partition value, such as year=2023/month=01/day=15. While this can improve query performance when filters align with the partition structure, it puts enormous pressure on design decisions made at table creation time. A poorly chosen partitioning strategy can create millions of tiny directories and files, degrading performance and requiring painful rewrites to fix.
Iceberg abstracts partitioning away from directory structures. It introduces the concept of hidden partitioning, where queries can filter by high-level expressions (such as a date column), and Iceberg automatically resolves them against the underlying partitioning scheme. Better still, Iceberg allows partitioning to evolve: a table that began with daily partitions can later switch to monthly ones without rewriting historical data. This flexibility prevents the "frozen design" problem of Hive and ensures that partitioning adapts as workloads change.
ACID Compliance and Reliability
Hive's journey toward ACID compliance was incremental. Originally designed for append-only batch processing, Hive later introduced transactional tables built on ORC files. These rely on delta and base files that must be periodically compacted to maintain query efficiency. While functional, the model is operationally heavy and struggles under high concurrency. The need for compaction creates windows of inconsistency and requires constant tuning, which makes Hive ACID better suited for low-velocity workloads than for modern streaming or CDC pipelines.
Iceberg implements transactions through snapshot isolation. Each commit—whether an insert, update, or delete—creates a new snapshot of the table, and the catalog atomically advances the table pointer to reflect the latest state. This model avoids compaction entirely and makes concurrent writers far less risky. The result is a system that supports both batch and streaming ingestion with minimal operational burden. In terms of reliability, Iceberg's transactional design is simply more aligned with the demands of today's multi-writer, high-concurrency environments.
Performance Considerations
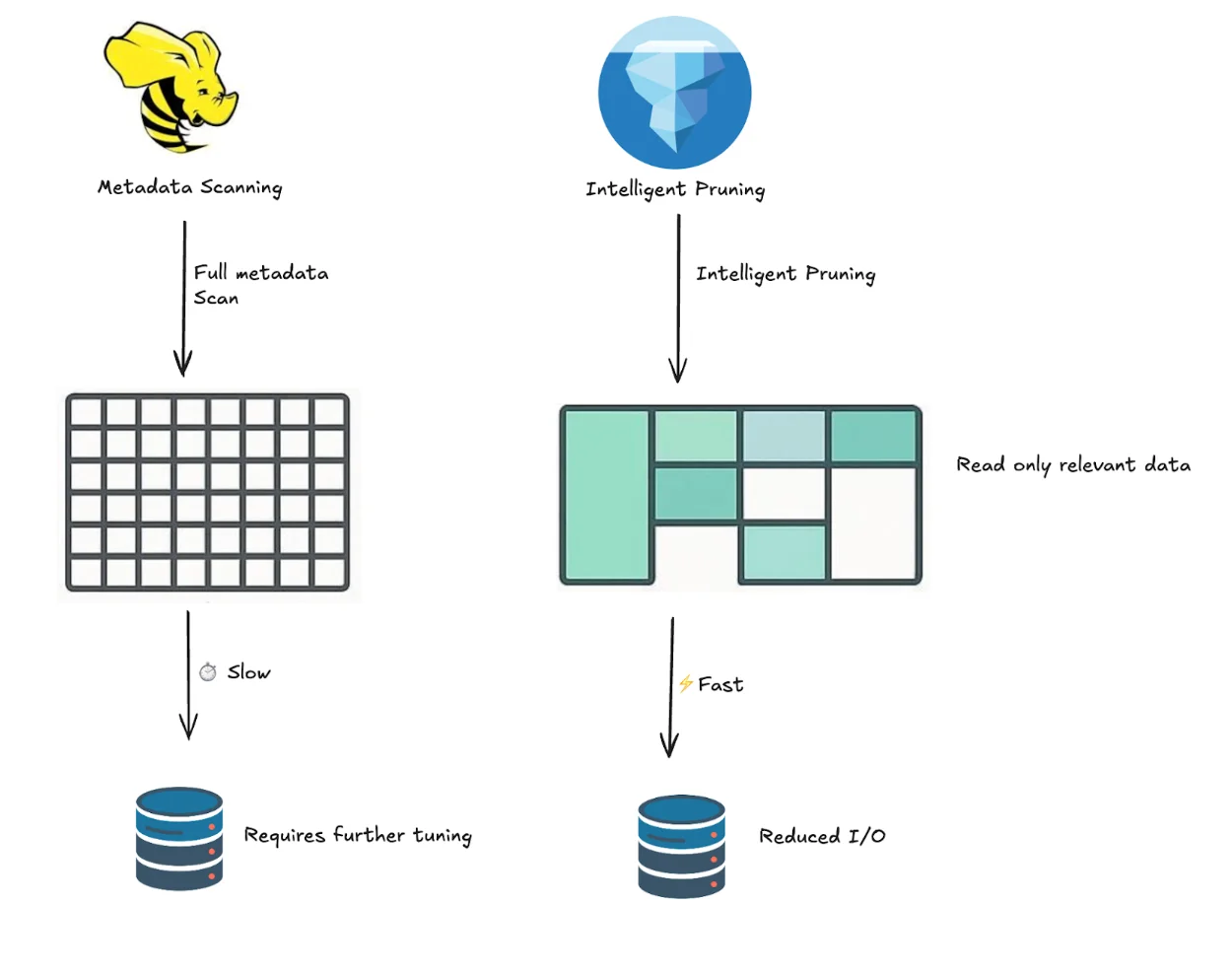
Performance in Hive has always been tied closely to the execution engine and the health of its partitions. If partitions are too granular, the system can drown in metadata operations. If compaction jobs fall behind, query performance suffers. Even simple count operations often require scanning large portions of the dataset because Hive lacks fine-grained metadata pruning. Performance tuning is possible, but it is a game of constant vigilance: right-sizing files, managing partition health, and keeping the Metastore responsive.
Iceberg improves performance by embedding statistics directly into its metadata tree. Manifest files record min/max values for columns, row counts, and other metrics, allowing query engines to prune aggressively before scanning files. Because partitioning is abstracted, queries do not rely on rigid directory structures but on metadata-driven filtering. In practice, this means Iceberg queries can skip vast amounts of irrelevant data, delivering much faster performance without the same operational overhead.
Time Travel and Versioning
Time travel is one of the most visible differentiators between the two systems. In Hive, there is no native notion of versioned tables. At best, teams simulate time travel by copying data into timestamped partitions or relying on backup versions in HDFS. While workable, these approaches are manual, error-prone, and lack the transactional guarantees needed for governance and reproducibility.
Iceberg, by contrast, bakes time travel into its core. Every change creates a new snapshot, and these snapshots are retained for configurable periods. Analysts can query a table "as of" a given snapshot ID or timestamp, enabling historical analysis, debugging, and rollback. For organizations concerned with compliance and auditability, this feature is not just convenient but transformative, as it provides a reliable way to reproduce past results or investigate anomalies.
Ecosystem and Engine Support
Perhaps the most practical difference for modern data teams lies in ecosystem support. Hive was designed for a world where the Hive engine dominated. While connectors exist for Spark, Presto, and others, these are often constrained by the limitations of the Hive Metastore and the rigidity of Hive's file layouts. In practice, Hive tables work best when queried by Hive itself, making it less attractive in multi-engine environments.
Iceberg, on the other hand, was explicitly designed to be engine-agnostic. Its open specification and flexible metadata layer have attracted widespread support: Spark, Flink, Trino, Presto, Athena, Snowflake, and Dremio all integrate with Iceberg. This interoperability means data stored in Iceberg tables can be shared across diverse workloads without creating silos. A machine learning team can train models in Spark, while business analysts query the same tables in Trino, all without duplicating or reshaping data.
Taken together, these feature comparisons make clear why Hive and Iceberg occupy such different places in the analytics landscape. Hive's limitations are not failings so much as reflections of the era in which it was built. Iceberg, by contrast, embodies the lessons learned from a decade of operating large-scale data lakes, providing flexibility, reliability, and interoperability that align with modern expectations.
Real-World Workflows: Where Each Shines
When teams evaluate Hive and Iceberg, the decision is rarely made in a vacuum. Most organizations already have an existing data landscape, with established pipelines, workloads, and operational practices. The value of either technology depends heavily on the context in which it is deployed. By examining typical workflows, we can see why Hive continues to persist in some environments while Iceberg is rapidly gaining traction in others.
Hive shines in ecosystems that remain tightly coupled with Hadoop. Enterprises that invested heavily in on-premise Hadoop clusters over the last decade often built thousands of tables in Hive, many of them backed by ORC files optimized for batch-style ETL. These organizations may run nightly or weekly batch jobs to prepare data for reporting, where latency is measured in hours rather than seconds. In such cases, the overhead of Hive's compaction or the rigidity of its partitions is less of a concern. The existing investment in tooling, skills, and integrations makes Hive a stable choice, especially when the workload is predictable and the cost of migration would outweigh the benefits.
Consider, for instance, a financial services company with compliance-driven reporting processes. Their nightly jobs transform raw transactional logs into ORC-backed Hive ACID tables, which auditors then query using familiar HiveQL. The governance controls and procedural checks are built entirely around Hive, and shifting to Iceberg would require not only reworking the data itself but also retraining teams and revisiting regulatory approvals. In such a scenario, sticking with Hive is often the most pragmatic decision.
Iceberg, on the other hand, is purpose-built for modern, multi-engine data lakehouses. Workflows that demand agility, concurrency, and interoperability benefit enormously from Iceberg's design. Imagine a retail company running streaming ingestion pipelines from Kafka into Iceberg tables via Apache Flink. At the same time, data scientists explore historical patterns using Spark, while analysts run ad hoc queries in Trino or Athena. Iceberg's snapshot isolation ensures that each group sees a consistent view of the data, while hidden partitioning and metadata pruning keep queries performant. Such workflows simply cannot be sustained efficiently on Hive.
Another compelling use case for Iceberg emerges in cost-conscious cloud environments. Because Iceberg tables can be queried by multiple engines without copying or reshaping data, teams avoid the expense of maintaining duplicate pipelines or materialized views. Time travel also allows organizations to validate changes and roll back mistakes without reprocessing entire datasets, reducing both infrastructure costs and operational risk. For example, a healthcare analytics platform may store patient telemetry data in Iceberg and enable different departments to query the same dataset for clinical research, operational dashboards, and billing audits—all without duplicating the underlying files.
It is also worth noting that Iceberg's flexibility makes it well-suited for emerging workloads like machine learning feature stores. These require frequent schema evolution, low-latency ingestion, and reliable versioning to ensure reproducibility. Hive's static partitioning and limited schema evolution capabilities make it an awkward fit for this kind of dynamic environment.
In short, Hive remains a strong choice when the priority is stability, legacy integration, and minimal disruption. It works best in Hadoop-native stacks where workloads are primarily batch-oriented and schema changes are infrequent. Iceberg, by contrast, thrives in cloud-first, multi-engine, high-concurrency scenarios, where adaptability, governance, and performance optimization are non-negotiable. For organizations building or modernizing data lakehouses, Iceberg offers not just incremental improvements but a fundamentally more flexible foundation.
Decision Matrix: Apache Hive vs Apache Iceberg
Choosing between Hive and Iceberg is rarely as simple as "old versus new". Most organizations face a complex blend of legacy investments, evolving workloads, and future ambitions. A decision matrix provides a practical way to evaluate the trade-offs systematically, weighing different factors such as workload type, team expertise, governance requirements, and cost considerations.
One way to think about this is through workload archetypes. For batch ETL, Hive remains a dependable, if somewhat heavy, option. Its mature ecosystem and compatibility with ORC make it attractive when transformations are predictable and schema changes are rare. But when workloads shift toward more dynamic workloads, Iceberg's snapshot-based transactions and support for high-concurrency pipelines give it a decisive edge. Similarly, in ad hoc BI queries where latency matters, Iceberg's metadata pruning consistently outperforms Hive's directory-based partition scans. For machine learning use cases, the decision becomes even clearer: Iceberg's schema evolution, time travel, and cross-engine interoperability align naturally with the iterative, experimental nature of ML feature engineering.
Team skills and operational comfort also play a major role. Organizations with a deep bench of Hive practitioners may prefer to extend the life of their Hive deployments, especially if training budgets are constrained or data governance processes are tightly bound to Hive's constructs. On the other hand, teams already working with Spark, Flink, or Trino will find Iceberg a smoother fit, since it integrates natively with these engines and supports more modern development patterns.
Governance is another dimension where the two systems diverge. Hive's governance relies heavily on the Hive Metastore, which has long been a bottleneck in terms of scalability and flexibility. Iceberg's catalog abstraction, by contrast, allows organizations to choose between the Hive Metastore, AWS Glue, or a REST catalog, enabling governance strategies that match broader organizational needs. This flexibility becomes critical in multi-cloud or hybrid-cloud contexts, where a single centralized catalog may not suffice.
Cost considerations tie all of these threads together. Hive often incurs hidden costs through compaction jobs, oversized partitions, and inefficiencies in query execution. These costs may be tolerable on-premise, but they can quickly escalate in cloud environments where compute and storage bills scale with usage. Iceberg's fine-grained pruning, compact metadata files, and cross-engine operability allow organizations to reduce redundant storage and lower query costs, making it more attractive for teams under pressure to optimize budgets.
Decision Matrix: Hive vs Iceberg
| Dimension | Hive Strengths | Iceberg Strengths |
|---|---|---|
| Batch ETL | Mature, proven in Hadoop environments | Equally strong, with added flexibility |
| Streaming / CDC | Limited, compaction overhead | Native snapshot isolation, high concurrency |
| BI / Ad-hoc Queries | Slower, partition pruning only | Faster, metadata-driven pruning |
| Machine Learning | Rigid, limited schema evolution | Flexible schema changes, reproducible snapshots |
| Governance | Stable but tied to Hive Metastore | Flexible catalogs (Hive, Glue, REST) |
| Cost Efficiency | Operational overhead and compaction costs | Lower storage & compute via pruning and reuse |
| Team Skills | Strong for Hadoop-native teams | Strong for multi-engine, modern teams |
This table is not meant as a definitive scorecard but rather as a conversation starter. Every organization will weigh these dimensions differently. For some, minimizing disruption and leveraging existing Hive expertise will outweigh the benefits of Iceberg's flexibility. For others, especially those building greenfield platforms or modernizing toward the lakehouse model, Iceberg's advantages will be too compelling to ignore.
In the end, the decision is less about declaring one system "better" than the other, and more about aligning the tool with the organization's strategic priorities. Hive continues to serve as a workhorse for stable, batch-oriented, Hadoop-native environments. Iceberg, meanwhile, has emerged as the table format of choice for interoperable, cloud-ready lakehouses where agility, governance, and cost efficiency are paramount.
Migration Considerations & Playbook
Choosing between Hive and Iceberg is rarely as simple as "old versus new." Most organizations face a mix of legacy investments, evolving workloads, and future ambitions. A structured decision framework helps clarify the trade-offs, weighing factors like workload type, team expertise, governance needs, and cost.
Workload patterns often shape the choice. For batch ETL, Hive is still a reliable, if somewhat heavy option. Its mature ecosystem and tight integration with ORC make sense when pipelines are predictable and schema changes are rare. But as workloads shift toward more dynamic, high-concurrency environments, Iceberg's snapshot-based transactions and modern table mechanics shine. In ad hoc BI queries, where latency is key, Iceberg's metadata pruning consistently outpaces Hive's directory-driven scans. And for machine learning, Iceberg is the natural fit: schema evolution, time travel, and engine interoperability align with the iterative nature of feature engineering and experimentation.
Team expertise also matters. Organizations with long-standing Hive skills may prefer to extend Hive's life, especially when training budgets are tight or governance practices are deeply tied to Hive's conventions. But for teams already invested in Spark, Flink, or Trino, Iceberg tends to feel like a smoother fit, integrating natively with modern engines and development practices.
Governance creates another point of divergence. Hive depends on the Hive Metastore, which can become a bottleneck as environments scale. Iceberg's catalog abstraction, however, allows teams to choose Hive Metastore, AWS Glue, or a REST-based catalog, adapting governance strategies to fit multi-cloud and hybrid-cloud realities where a single centralized approach isn't enough.
Finally, cost pulls these considerations together. Hive often incurs hidden expenses from compaction jobs, oversized partitions, and inefficient scans. These may be tolerable on-prem, but in the cloud they quickly translate into rising compute and storage bills. Iceberg, with its fine-grained pruning, compact metadata, and multi-engine reusability, offers a more efficient cost profile—an advantage for teams under pressure to optimize budgets.
Performance & Cost Tuning Tips (Both Sides)
Performance and cost efficiency highlight the biggest contrasts between Hive and Iceberg. While Hive often requires constant tuning just to stay stable, Iceberg offers built-in optimizations that make it easier to control performance and costs in the long run.
In Hive, challenges stem largely from its ACID design. Frequent inserts and updates create base and delta files that demand costly compaction jobs, and query performance suffers if these fall behind. File sizing and partitioning require continuous adjustment—too many small files or overly fine-grained partitions can overwhelm the system, driving up compute costs and slowing queries. This balancing act makes Hive dependable for batch workloads but less suited to dynamic or real-time environments.
Iceberg addresses many of these issues with richer metadata. By embedding statistics directly in its metadata tree, it enables engines to prune irrelevant data without scanning files, reducing the need for manual partition management. File size and compaction still matter, but they focus on optimizing layout rather than cleaning up delta files. Features like sort and order specs in format v2 further improve pruning and cut scan costs, which is especially valuable in cloud-native engines where billing is tied to data scanned.
Cost models also differ sharply. Hive's reliance on compaction and complex partitions leads to unpredictable compute overheads. Iceberg, by contrast, provides clearer levers: snapshot retention, compaction scheduling, and smart partitioning or clustering strategies that align with query patterns. This results in lower, more predictable costs across engines.
In short, tuning Hive is about firefighting compaction and partition sprawl to keep systems running. Tuning Iceberg is about unlocking efficiency—using metadata and layout strategies to deliver better performance and lower costs in cloud-first environments.
FAQ: People-Also-Ask
Is Apache Iceberg better than Hive for analytics?
Iceberg generally offers stronger advantages for analytics workloads, especially those involving ad hoc queries, BI dashboards, or interactive exploration. Its metadata-driven pruning and hidden partitioning allow query engines to skip irrelevant files, dramatically reducing scan times. Hive, by contrast, relies on directory-based partitioning, which is slower and less flexible. That said, Hive remains perfectly adequate for batch-oriented ETL jobs in legacy Hadoop environments where performance is less critical.
Can I use Hive Metastore with Iceberg?
Yes. In fact, many organizations start their Iceberg journey this way. Iceberg supports multiple catalogs, including Hive Metastore, AWS Glue, and REST catalogs. Using the Hive Metastore allows incremental adoption—teams can register Iceberg tables alongside Hive tables and gradually migrate workloads. The limitation is that Hive Metastore itself was not designed for high-scale metadata operations, so as adoption grows, some organizations eventually move to more scalable options like Glue or REST-based catalogs.
How does Iceberg handle schema changes compared to Hive?
Schema evolution is one of Iceberg's standout features. It tracks columns by IDs rather than by name or position, which means you can rename, add, or drop columns without rewriting underlying data. Type changes are also supported in many cases. Hive, on the other hand, handles schema changes less gracefully. Renaming or dropping columns can cause inconsistencies, and type changes often require rewriting the table. For teams working in fast-moving domains, Iceberg's approach provides far more agility.
Do I need ORC for Hive ACID?
Yes, typically. Hive's ACID compliance relies on ORC files for transactional tables. These tables maintain base and delta files that must be periodically compacted. While Hive also supports other formats like Parquet or Avro for non-transactional tables, ORC remains the default and most reliable choice for ACID operations. This reliance on ORC is one reason why Hive feels more constrained compared to Iceberg, which supports multiple formats more flexibly.
Is Iceberg only for the cloud?
Not at all. While Iceberg is popular in cloud-native lakehouse architectures, it can also be deployed on-premise. What makes it cloud-friendly is its separation of storage and compute, plus support for object stores like S3, ADLS, and GCS. On-prem deployments often use Iceberg with distributed file systems like HDFS, though the benefits of time travel, schema evolution, and multi-engine compatibility are equally valuable regardless of environment.
Can Hive and Iceberg coexist in the same environment?
Yes—and in many cases, they do. Organizations often run Hive and Iceberg side by side during migration. Some workloads remain on Hive where stability and legacy integration matter, while new workloads adopt Iceberg for flexibility and performance. Over time, the balance often shifts toward Iceberg, but coexistence provides a practical path to transition without disrupting critical pipelines.
Summary / Conclusion
The story of Hive and Iceberg is, in many ways, the story of the data ecosystem itself. Hive emerged in the Hadoop era to bring SQL-like querying to massive datasets stored across distributed systems. For more than a decade, it powered reporting, compliance, and batch ETL in countless enterprises. Its rigid partitioning, complex ACID model, and reliance on the Hive Metastore weren't design flaws so much as reflections of the constraints of its time. Hive thrived because it solved the problems that mattered most in the early days of big data.
Iceberg, by contrast, belongs to the lakehouse generation. It was designed with lessons from Hive and the needs of cloud-native architectures in mind. By decoupling metadata from storage, supporting schema and partition evolution, and enabling time travel, Iceberg provides a more flexible foundation for modern workloads. Its engine-agnostic approach fits a world where Spark handles machine learning, Trino powers analytics, and Flink manages streaming all against the same consistent data.
The choice between Hive and Iceberg comes down to context. For organizations with heavy Hadoop investments and steady, batch-oriented pipelines, Hive remains a dependable workhorse. But for teams building new platforms, aiming for flexibility, or looking to cut cloud costs, Iceberg offers clear advantages. Its adaptability makes it more than just an incremental step forward; it's a key enabler of the lakehouse model.
Looking ahead, Hive will continue to support legacy systems where stability is valued, while Iceberg is poised to become the default open table format for modern data platforms. The real decision isn't about which technology is "better," but which future you want to build. If that future depends on multi-engine analytics, cost efficiency, and architectures that can evolve with the business, Iceberg is the format built to carry you there.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.