Apache Iceberg Table Maintenance Made Easier with OLake Fusion


Apache Iceberg is the right choice for most modern lakehouses (read more). It gives you ACID guarantees, schema evolution, time travel, and genuinely fast analytical queries — without locking you into any single vendor or engine. The adoption numbers back it up: Iceberg has quietly become the default open table format for teams building serious data infrastructure.
But here's what nobody tells you when you're getting started: picking the right table format is only half the job. The other half is keeping those tables healthy. And that part? It's a lot harder than it looks.
This blog is about that second half — specifically, why Iceberg table maintenance tends to become a full-time headache, what teams are doing today to cope with it, and what we built at OLake to actually solve it.
The Apache Iceberg Small Files Problem
The Apache Iceberg small files problem shows up when streaming ingestion, CDC syncs, or frequent micro-batches create thousands of small Parquet files instead of fewer well-sized data files. It builds quietly until query performance is already degraded.
Every time a CDC pipeline writes data to Iceberg, it creates new files in object storage. That's how the format works. The trouble is that modern CDC pipelines write constantly. Row-level changes streaming in every few seconds, each batch producing a tiny new file. What should've been 50 well-sized Parquet files has turned into 50,000 tiny ones spread across your table.
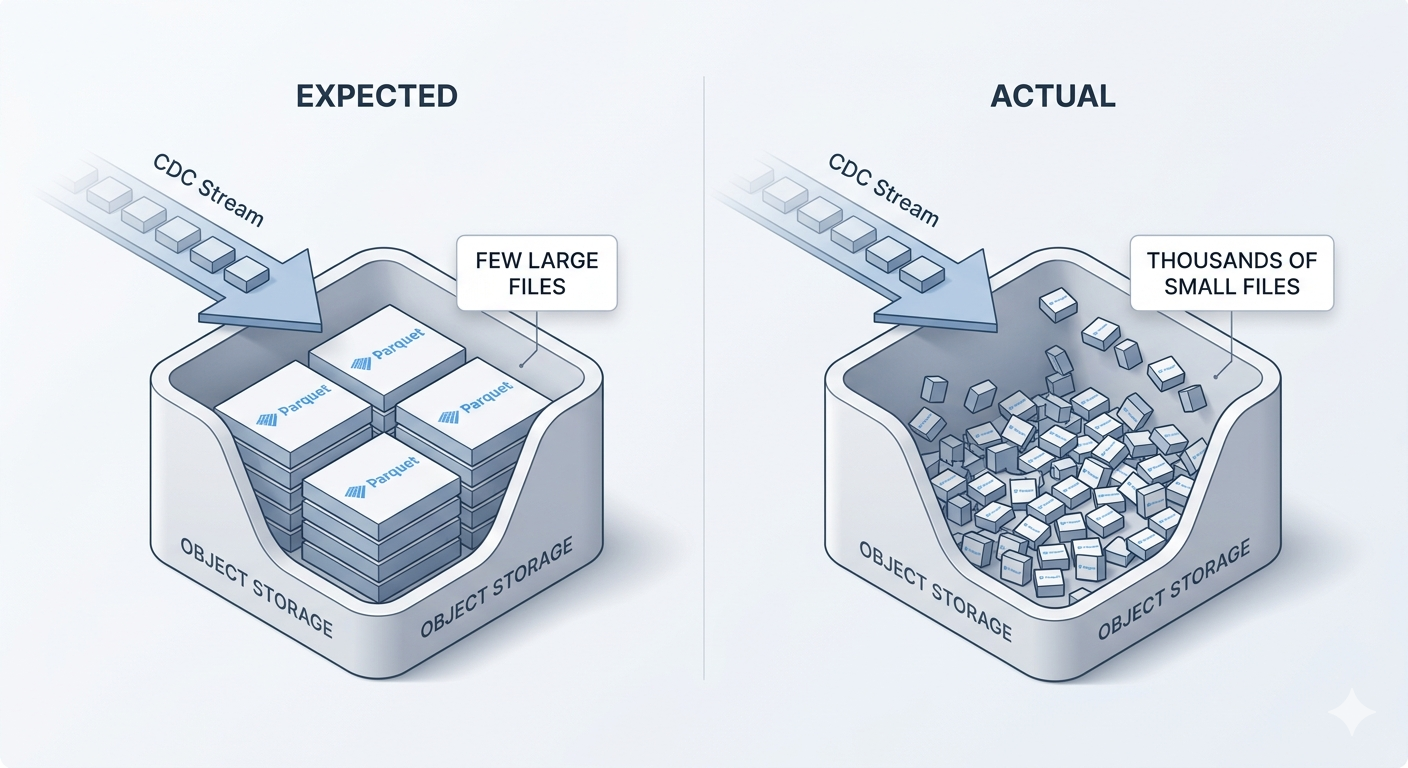
This is the small files problem, and it triggers a cascade of issues.
Query engines have to work much harder. Engines like Spark, Trino, or Athena don't read a table as a single unit. They read individual files. With 50,000 small files, every query involves thousands of extra file listings, metadata reads, and I/O round trips. The total data size hasn't changed, but the work has grown by orders of magnitude.
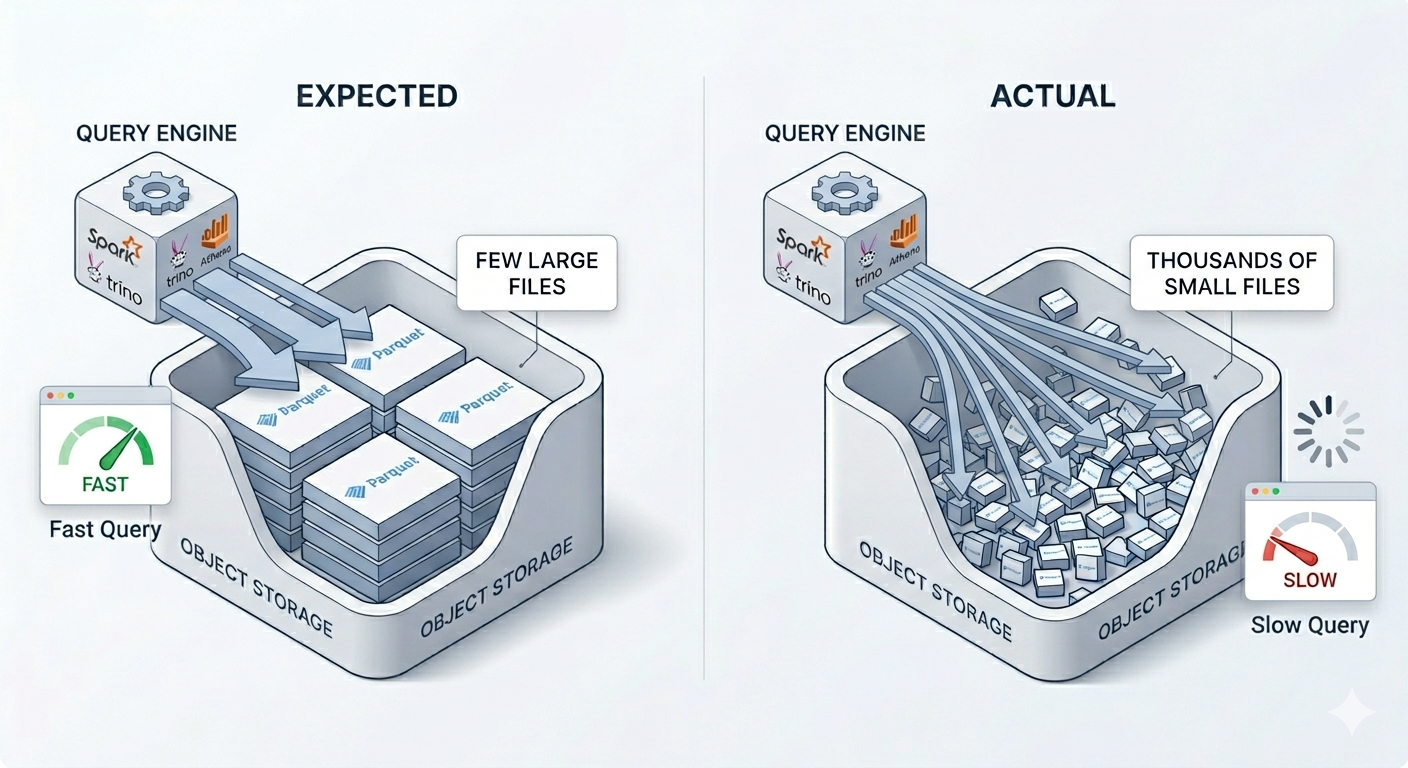
Metadata becomes a bottleneck on its own. Iceberg lists every data file in manifests. The more files you have, the heavier those lists get. Planning a query or committing a write then takes longer, because the engine has to scan a much larger inventory before it can do real work.
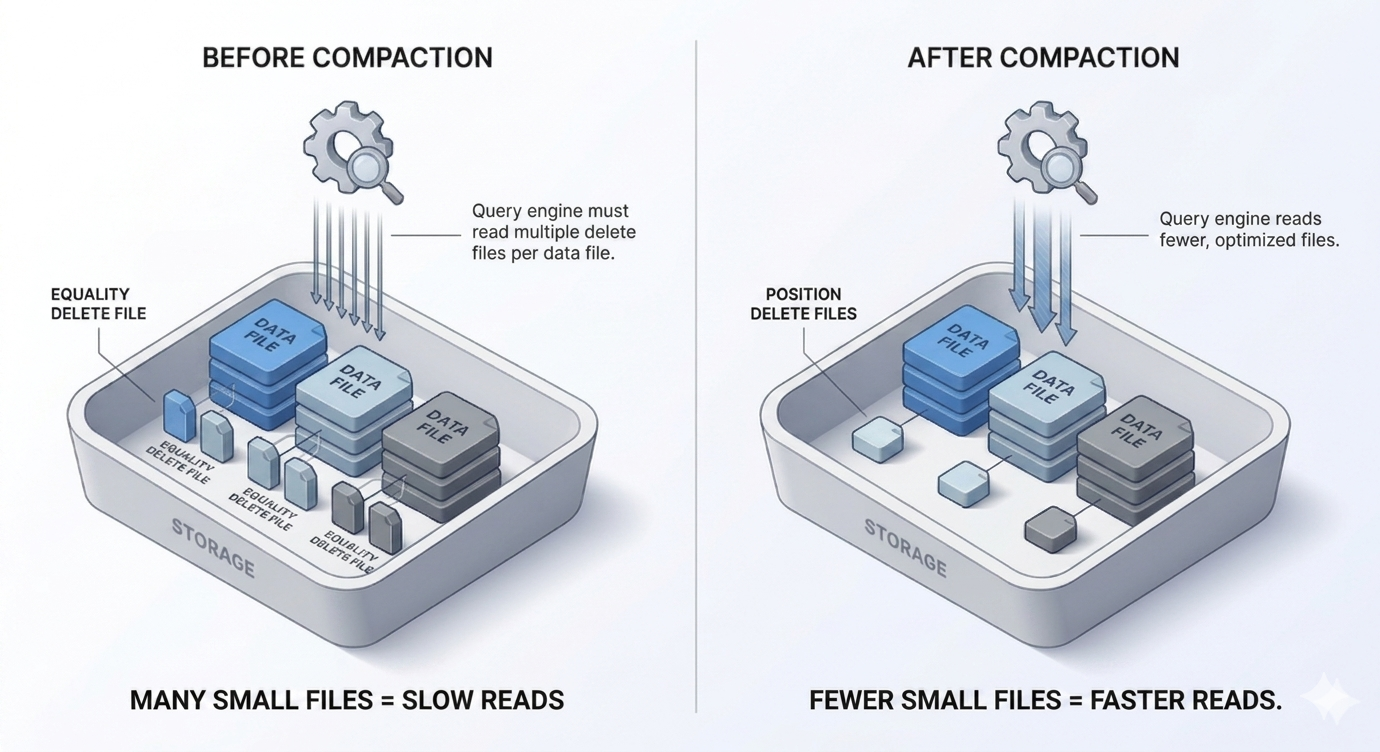
Delete file accumulation makes this even worse. In CDC-heavy pipelines, every sync doesn't just create new data files. It also creates delete files that track which rows were updated or deleted. These delete files are how Iceberg handles upserts without rewriting entire data files on every change. But delete files have a cost: every query has to apply them at read time to get the correct view of the data. As they pile up, the overhead of applying deletes during reads becomes significant. A table with thousands of delete files will be noticeably slower than the same table after they've been resolved.
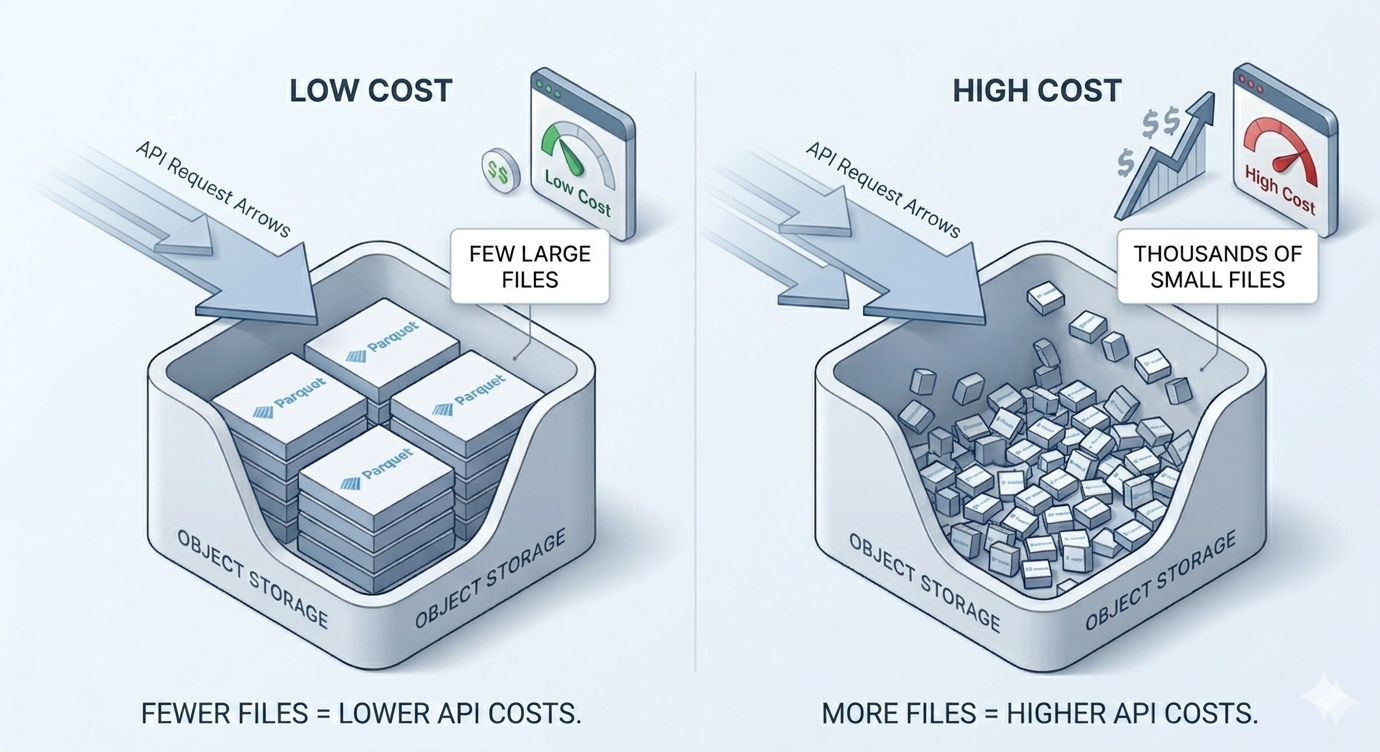
Object storage costs creep up silently. Cloud storage doesn't just charge for how much data you store. It also charges per API request. More files means more reads, more listings, more API calls on every operation. You won't notice it until the bill shows up, and by then you've been overpaying for weeks.
None of this happens suddenly. It builds up quietly, which is exactly why it catches teams off guard. By the time performance is obviously degraded, the tables are already in rough shape.
Why Vanilla Spark compaction is hard to operate
The standard fix for small files and delete accumulation is compaction: periodically rewriting fragmented small files into larger, well-organized ones and resolving accumulated deletes into the data. Iceberg's ecosystem supports this, and Apache Spark has become the de facto tool for it via rewrite_data_files.
So most teams end up doing something like this:
They write a Python script that calls rewrite_data_files(...) with the right parameters. They figure out executor counts, memory settings, file size bounds, and parallelism through trial and error. They wire it up to a job scheduler or a cron job to run every 20 or 30 minutes. A few weeks later, their ingestion rate changes, and the parameters they tuned are no longer appropriate for the table's current state.
This works. Teams do make it work. But look at what they're actually doing:
Writing custom spark scripts to maintain Iceberg tables. The compaction script itself becomes a thing that needs documentation, version control, incident response, and occasional debugging at 2am when a job fails and nobody knows why. That's before you account for the fact that most teams have more than one Iceberg table.
Running one compaction setup for situations that need different treatment. Some tables need frequent, aggressive compaction, while others only need lighter compaction on a slower schedule. Spark's rewrite_data_files doesn't differentiate. It processes whatever files fall within your size bounds, regardless of whether that's the right level of intervention for the current table state.
Figuring out what happened by digging through scattered logs. Most setups save something like: scheduler run history, Spark driver logs, or files on disk. The hard part is connecting that output back to the table itself: whether file layout improved, deletes were absorbed, and whether the job really helped. When a run fails, or shows success while queries stay slow, why is often still unclear. Errors and exit codes alone rarely say what went wrong; you hunt through executor logs and put the picture together by hand.
Introducing OLake Fusion: Simplified Apache Iceberg Table Maintenance
OLake Fusion is a dedicated Iceberg maintenance service built for CDC-heavy Apache Iceberg tables. It handles compaction on a per-table cron schedule you configure, with tiered compaction levels, built-in metrics, and enough observability to actually understand what's happening to your tables.
No custom Spark scripts. No wondering if last night's compaction job did anything useful.
Tiered Iceberg Compaction: Lite, Medium, and Full
The most important thing about OLake Fusion's approach is that it doesn't treat all compaction as the same operation. It offers three compaction tiers that you can schedule independently, each designed for a different kind of table maintenance need.
Lite: Designed for small, frequent cleanup tasks. It keeps tables from slowly sliding into bad shape without using much compute, so you can run it often.
Medium: Designed for regular cleanup when small files and deletes are starting to slow reads. It does more work than Lite, but avoids the cost of rewriting the whole table.
Full: Designed for deep cleanup tasks where the whole table needs to be laid out fresh. It uses the most compute, so it makes sense for occasional resets, not frequent runs.
One important detail: if multiple tiers are scheduled to run at the same time, Fusion automatically runs only the highest one. Medium overrides Lite. Full overrides both. You don't end up doing redundant work when schedules overlap.
For the exact details of what each tier does, see the Types of Compaction.
This tiered approach matters because it lets you optimize for cost and efficiency at the same time. Running Full compaction every few minutes on a CDC table is wasteful. You're rewriting data that doesn't need rewriting. Running only Lite is insufficient if delete files are building up and impacting read performance. The right answer is run Lite frequently, Medium regularly, Full occasionally. Fusion makes it easy to express exactly that.
OLake Fusion vs Vanilla Spark Compaction: Faster, Cheaper Iceberg Maintenance
On comparable infrastructure, Fusion costs about 50% less than Apache Spark’s rewrite_data_files for the same compaction workload without giving up table layout quality. Run-by-run timings, query checks, methodology, and cost breakdown are covered in OLake Fusion vs Spark compaction benchmark
Apache Spark rewrite_data_files | OLake Fusion | |
|---|---|---|
| Setup | Custom script per table | Per-table config in UI |
| Scheduling | Manual | Built-in cron per tier |
| Compaction tiers | Single operation | Lite / Medium / Full |
| Observability | Manual log digging | Built-in metrics per run |
| Cost vs Spark | Baseline | ~50% lower |
| Speed vs Spark | Baseline | ~2x faster |
Iceberg Maintenance Observability and Table Health Metrics
Here's a problem that doesn't get talked about enough: with custom Spark compaction scripts, visibility is usually something you have to build and maintain yourself.
You can query Iceberg metadata tables before and after a Spark job to calculate file counts and delete counts. But in practice, teams still have to wire that into the job, store the results, connect them to run history, and make them easy to inspect when something feels slow. Fusion makes that visibility part of the product instead of another extra script.
Fusion comes with observability built in, at two levels.
Per-run logs and metrics. Fusion keeps logs and metrics for each compaction run, so you can see what happened and dig in without starting from unrelated job noise. More in Runs and logs.
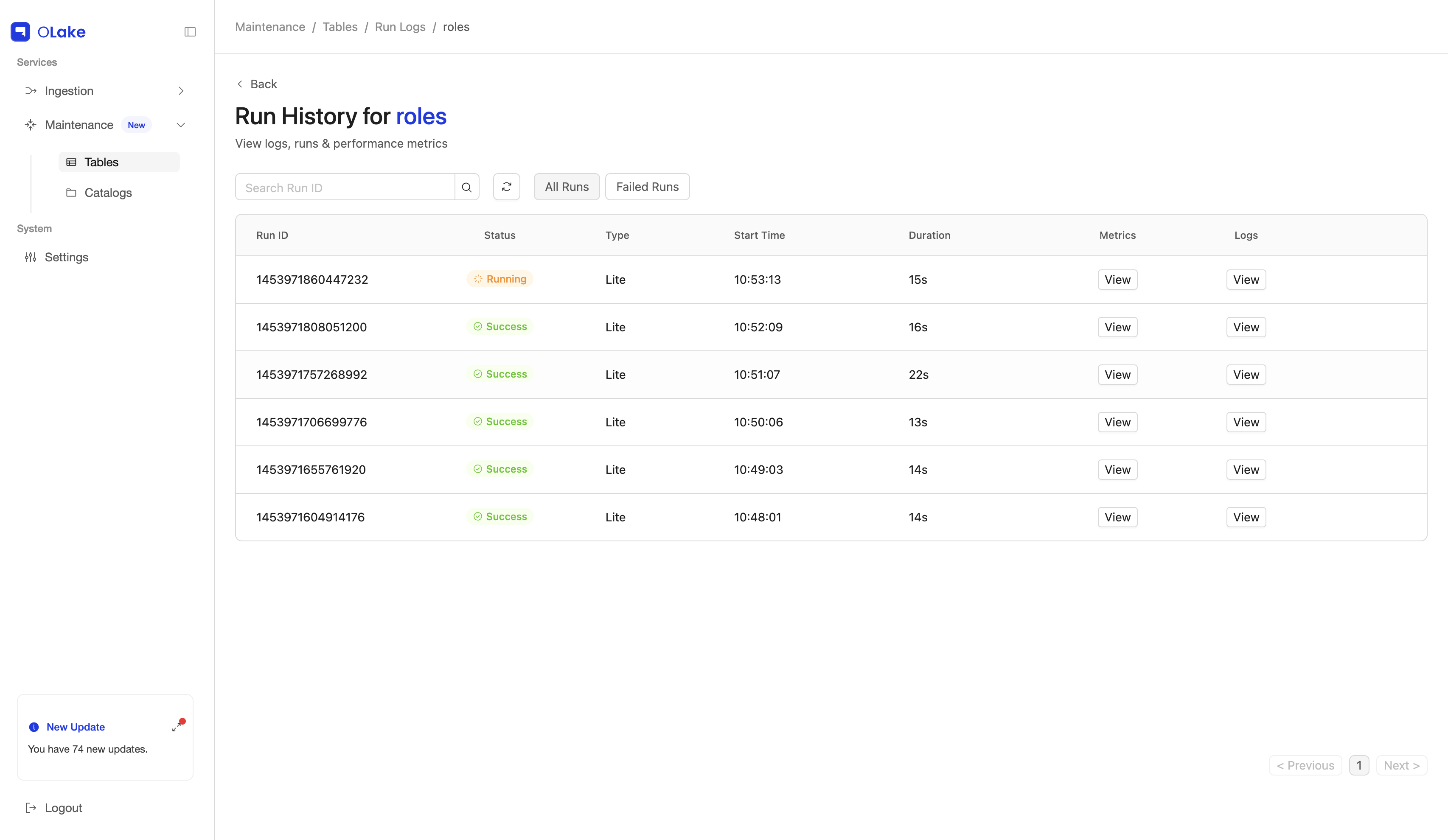
Input vs output for each run. After each compaction run, Fusion shows metrics for inputs and outputs: counts and sizes for data files and deletes, recorded before versus after each run. You read them straight from the UI instead of reconstructing totals only from unstructured logs.
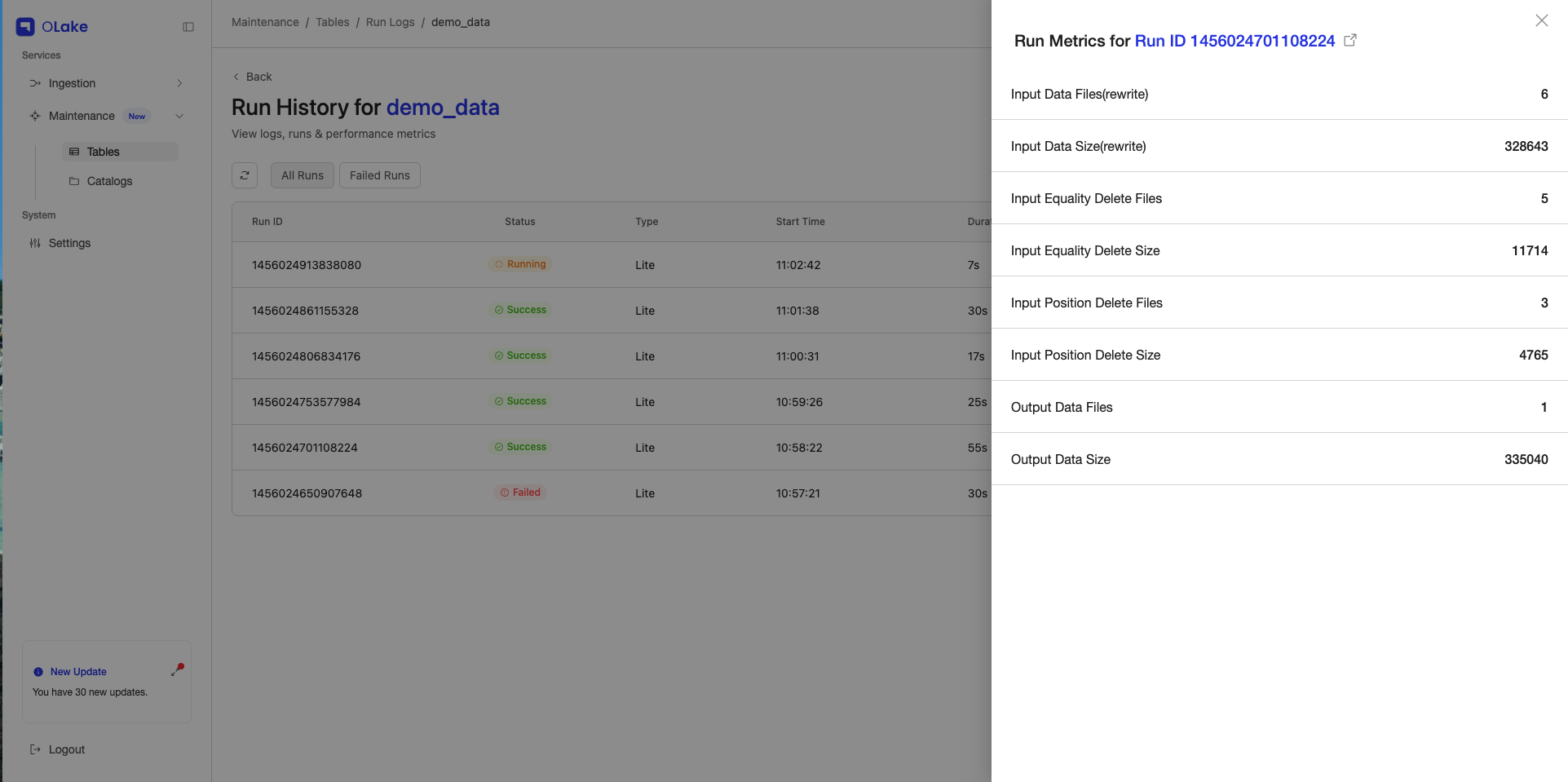
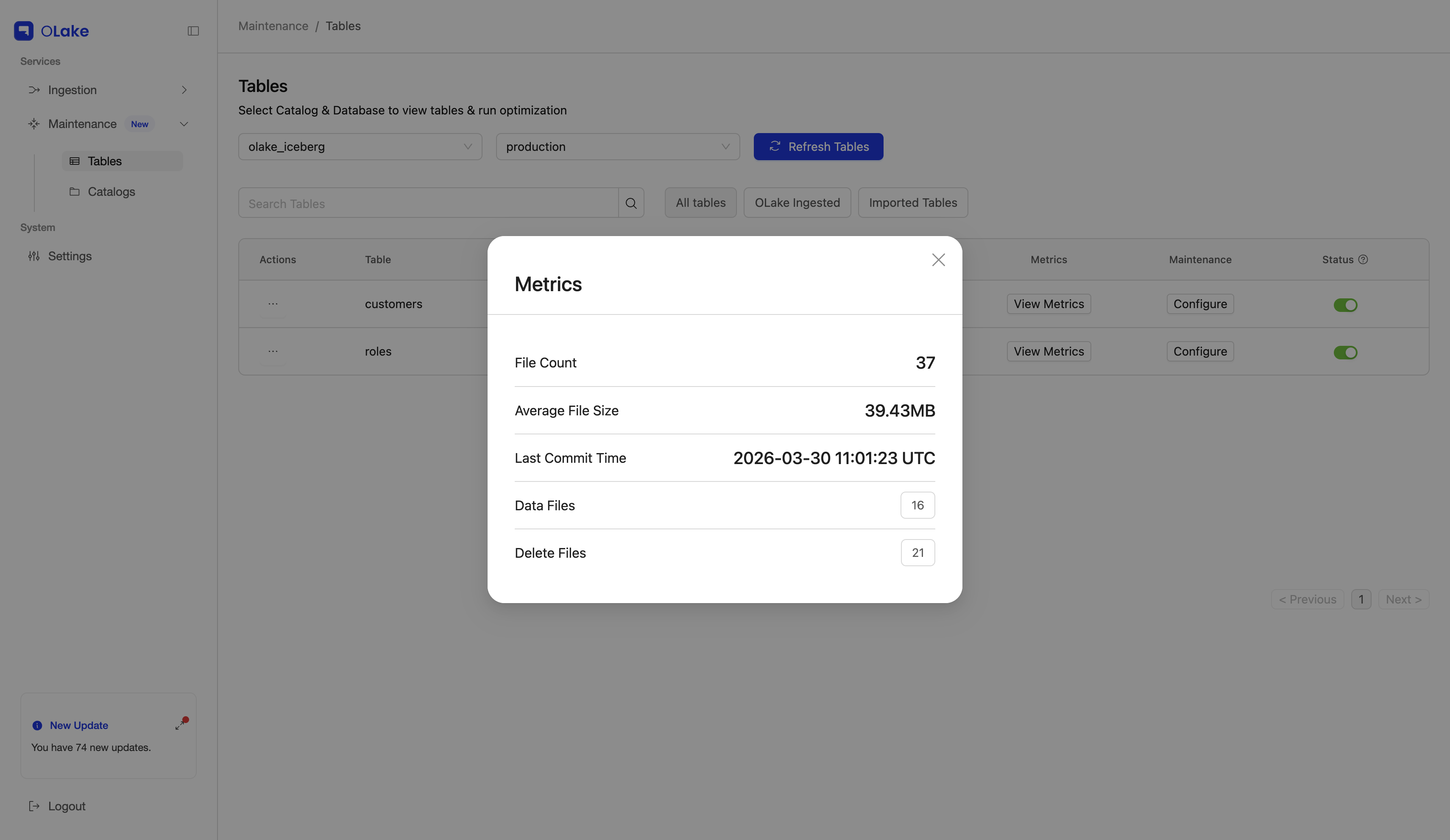
Table-level Metrics: Fusion shows metrics for each table's current state so you can understand and decide whether it needs compaction.
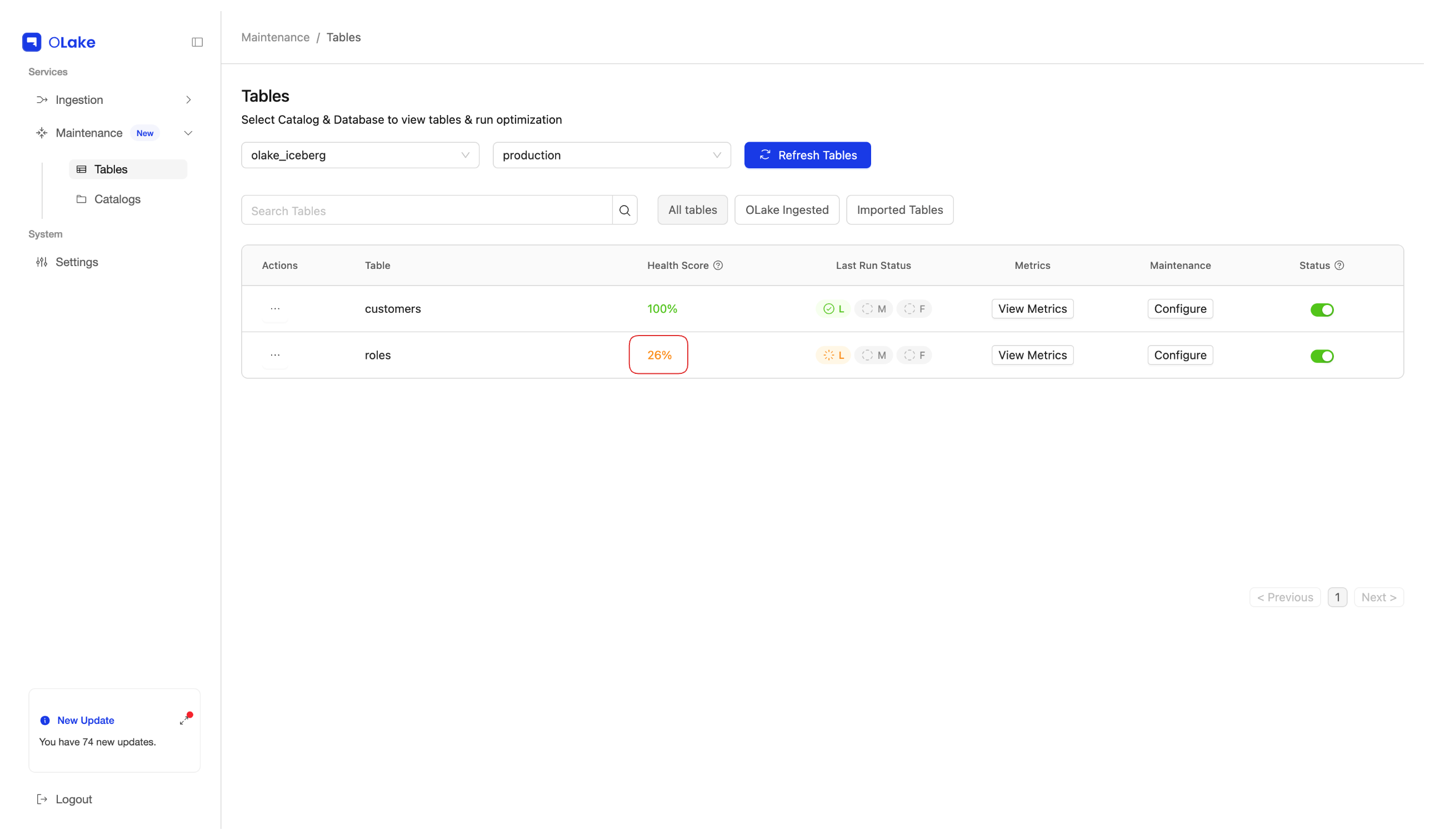
The Tables page shows an overall health score for each table, so you get a first-pass view of whether compaction looks necessary before you dive into detailed metrics.
This is the kind of visibility that makes the difference between proactively maintaining your tables and reactively debugging performance issues after users are already complaining.
To know more about metrics, refer here.
Configure Once, Maintain Continuously
Fusion connects to your Iceberg catalog. For each table, you configure the compaction schedule — which tiers to enable, and how often each one should run. You can think of it like cron: you define the cadence, Fusion executes it.
A typical setup depends on your CDC ingestion frequency. For example, if ingestion runs every 2 minutes, you might schedule Lite every 30 minutes, Medium every 6 hours, and Full every 2 days. Fusion handles the execution, the logging, and the metrics. If a run fails, you see it immediately in the runs view without having to dig through your job scheduler's logs or SSH into a Spark driver node.
If you're already using OLake for CDC ingestion, Fusion integrates naturally — same catalog, same UI. But it also works as a standalone service if you're using a different ingestion tool.
Refer here for a walkthrough guide: Getting Started with Fusion
Summary: Apache Iceberg Table Maintenance with OLake Fusion
If you're running Iceberg with CDC pipelines, table maintenance isn't optional, it's the difference between a lakehouse that stays fast and one that gradually becomes unusable. The small files problem and delete file accumulation are real, they compound over time, and they're hard to notice until performance is already degraded.
Spark-based compaction works, but only if you build and run those jobs yourself. They are often slow and expensive, and it can be hard to tell if each run really helped.
OLake Fusion is built specifically for this. Tiered compaction that matches the level of work to what the table actually needs. 2x faster than Spark. About half the cost. And enough observability to actually understand what's happening to your tables, before your users start asking why queries are slow.
Frequently Asked Questions
Q1. What is table maintenance in Apache Iceberg?
Table maintenance in Apache Iceberg is the set of routine operations that keep analytical queries fast and tables storage-efficient as data is written, updated, and deleted. Because every write creates new files and a new snapshot, tables accumulate small files, stale snapshots, orphan files, and bloated metadata over time.
A typical maintenance workflow includes compaction (rewrite_data_files) to merge small files and resolve deletes, snapshot expiration (expire_snapshots) to drop old snapshots, orphan file removal (remove_orphan_files) to clean up unreferenced files, and manifest rewriting (rewrite_manifests) to speed up query planning.
Q2. What is Apache Iceberg compaction?
Apache Iceberg compaction rewrites small, fragmented data files into larger optimized Parquet files and resolves accumulated delete files, reducing query planning overhead, merge-on-read costs, and object storage API charges on Iceberg tables.
Q3. Why do CDC pipelines create small files in Iceberg?
CDC pipelines write data continuously — often every few seconds or minutes. Each write typically creates a new set of data files and delete files. Because writes are frequent and small, the result over time is thousands of tiny files instead of a smaller number of optimally sized ones. Iceberg's merge-on-read model means query engines must scan all of these files at read time, which compounds the performance penalty.
Q4. What is Spark rewrite_data_files and what does it do?
rewrite_data_files is an Apache Iceberg table maintenance procedure, typically run
via Apache Spark, that reads existing data files and rewrites them into larger,
better-organized Parquet files. It can also resolve equality delete files into the
data, removing them from the read path. Teams use it to undo the effects of small
file accumulation — but it requires a running Spark cluster, manual configuration,
and custom scheduling.
Q5. What is the difference between equality delete files and position delete files?
Equality delete files record deleted rows by column value (e.g., "delete all rows
where id = 42"). They require the query engine to scan most of the data files to apply
the delete — expensive at scale. Position delete files are more efficient: they
record the exact file path and row offset of deleted rows. Fusion converts equality deletes into position deletes as an intermediate step before fully resolving them into the data files.
Q6. What is binpack compaction in Apache Iceberg?
Binpack compaction is a strategy that packs existing small files into target-size bins (e.g., 512MB) without reordering data. It minimizes the number of files while keeping write amplification low. It's the right choice for frequent, lightweight compaction runs where you want to reduce file count without the cost of a full sort.
Q7. What is sort compaction in Apache Iceberg?
Sort compaction rewrites data files while also sorting rows by one or more columns (e.g., a partition key or frequently filtered column). Sorted files allow query engines to skip entire files using min/max statistics, dramatically reducing I/O for selective queries. Sort compaction is more expensive than binpack and is best reserved for periodic deep-maintenance runs.
Q8. How often should Iceberg tables be compacted?
Compaction frequency depends on your ingestion rate. A typical setup for a CDC-heavy table absolutely depends on how frequently your CDC ingetions are scheduled. Given a case, where your CDC ingestion are scheduled every 2 mins, you may schedules your Lite compaction every 30 minutes, Medium every 6 hours and Full every 2 days.
Q9. Does Iceberg compaction remove delete files?
Yes. When compaction rewrites data files, it applies any pending delete files and incorporates their changes into the rewritten data. After compaction, those delete files are no longer part of the table's live snapshot and are removed from the read path. This is one of the primary performance benefits of compaction for CDC workloads.
Q10. How does OLake Fusion differ from running Vanilla Spark's rewrite_data_files?
OLake Fusion offers three compaction tiers (Lite, Medium, Full) that you schedule independently per table via cron expressions. It runs approximately 2x faster than Spark's rewrite_data_files on comparable infrastructure and at about 50% of the cost. It also includes built-in metrics, file counts and sizes before and after each run. So you can verify that compaction actually improved your table's state.
OLake Fusion
Open-source lakehouse maintenance for Apache Iceberg tables. 50% cheaper (2x faster) compaction than Vanilla Spark.