The Architect’s Guide to CDC with Apache Iceberg

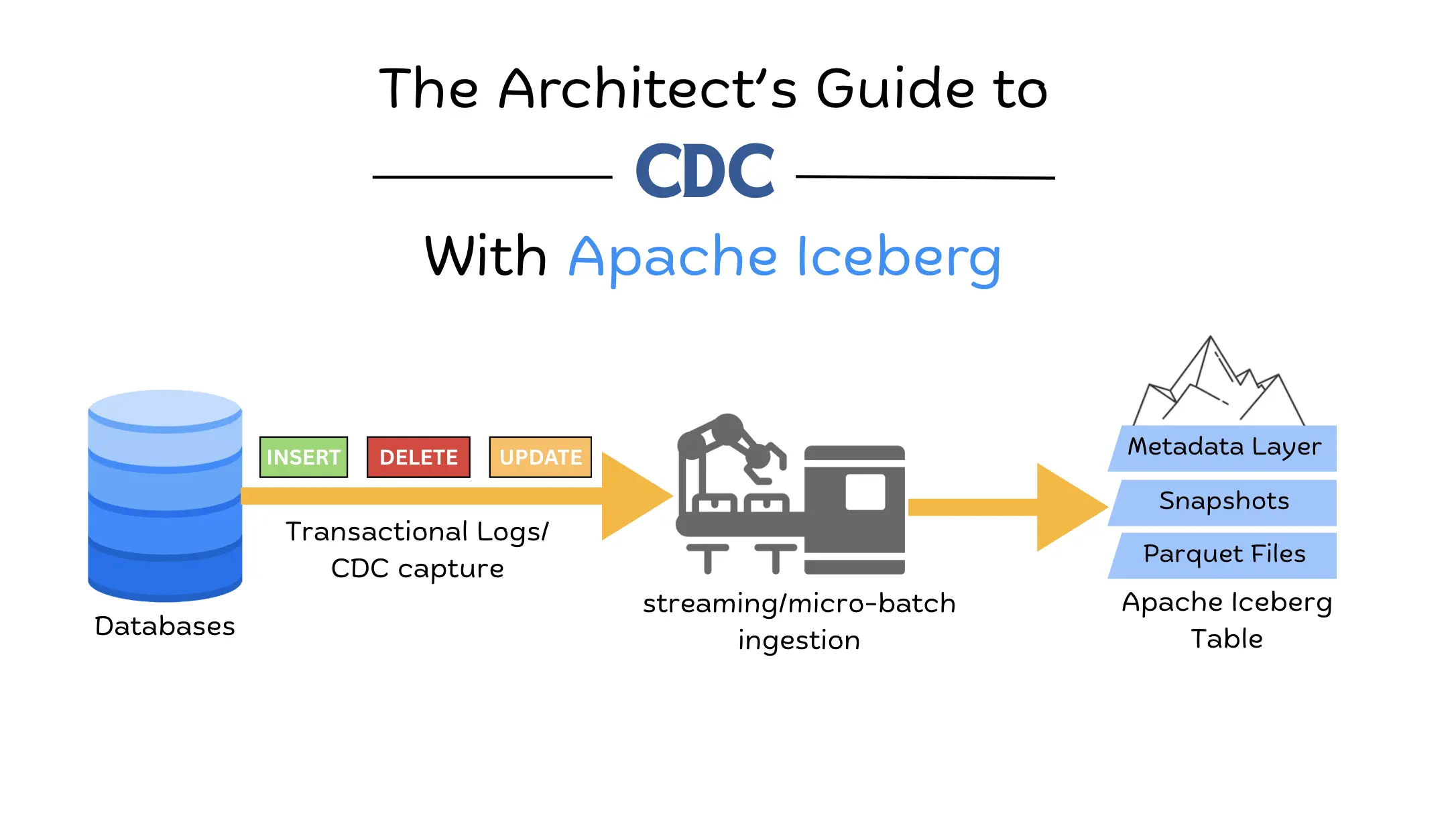
For a long time, the standard method for moving data from production databases into a data lake was Snapshot ETL. This process involved taking a full export of a database table, usually once every 24 hours, and overwriting the previous day's data in the destination. While this was technically simple to implement, it created a significant bottleneck for modern businesses. The most obvious issue was data staleness; because the sync only happened once a day, any analysis performed by the business was based on data that could be up to 24 hours old. Furthermore, these large batch jobs put immense strain on source databases, as running a massive SELECT query on a production system often led to performance degradation for end-users. This created a fragile ecosystem where a single job failure at 2:00 AM meant the entire organization spent the next business day working with outdated or missing information.
To solve the latency and performance issues of snapshot-based movement, the industry shifted toward Change Data Capture (CDC). Instead of copying the entire table, CDC monitors database transaction logs to capture every individual INSERT, UPDATE, and DELETE as it happens. This real-time visibility makes modern, data-driven applications possible, but it introduces a new technical nightmare for the storage layer: the Small File Problem. Because CDC sends changes as they occur, naive ingestion pipelines write thousands of tiny files that traditional data lakes cannot handle, causing query performance to become brittle and incredibly slow.
Apache Iceberg was built specifically to address these architectural limitations by providing a robust table format on top of standard data files like Parquet. It maintains a sophisticated metadata layer ensuring ACID compliance and tracking which files are valid and which have been replaced. This allows organizations to ingest high-velocity Change Data Capture (CDC) streams without worrying about file fragmentation or data inconsistency. By providing the reliable structure of a traditional SQL database on the scalable storage of a data lake, Iceberg transforms the chaotic stream of real-time events into a future-proof and performant data lakehouse.
The Core Challenge
Modern data lake storage is designed for massive, immutable blocks of data, which creates a fundamental architectural conflict with the row-level changes generated by CDC. To maintain a reliable and performant system, we must resolve the tension between the need for constant updates and the high cost of rewriting large data files.
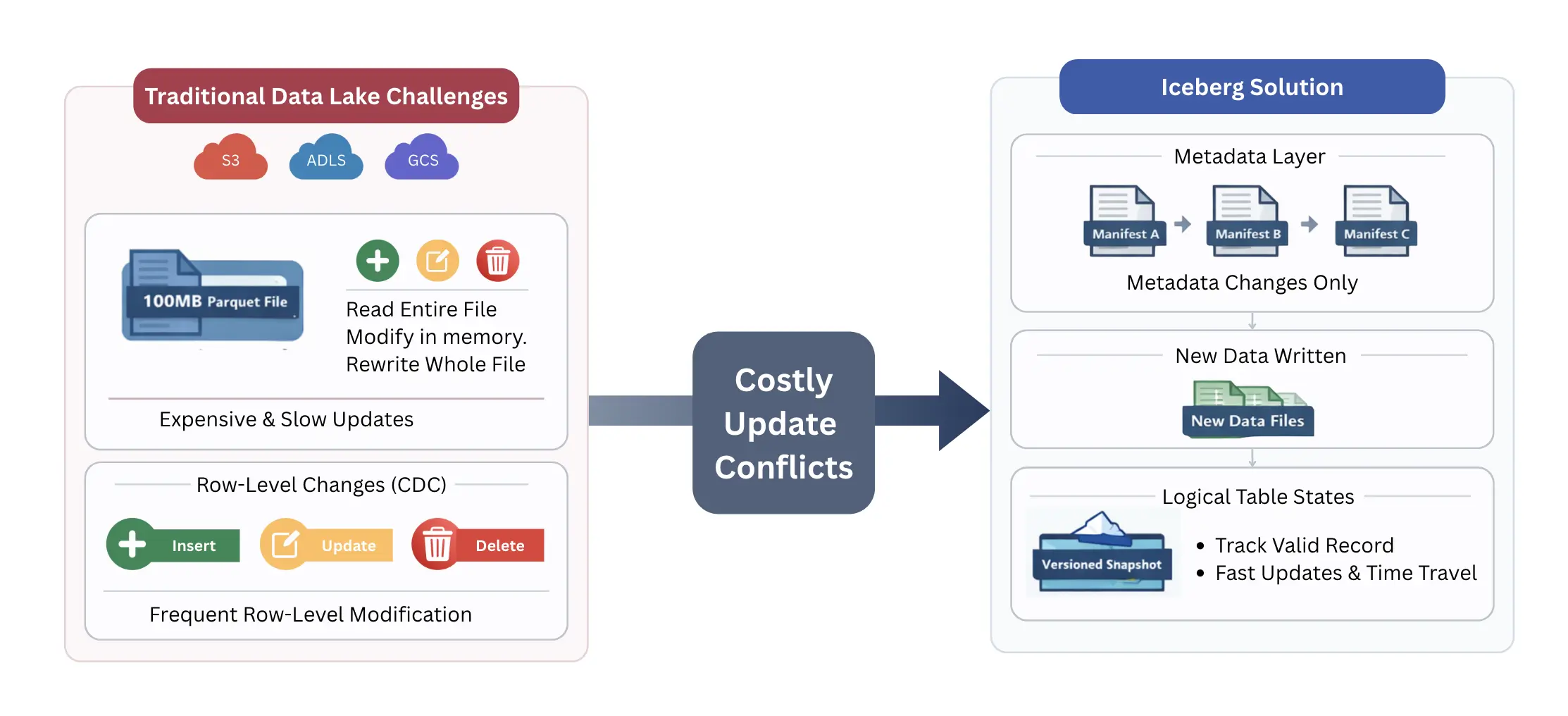
The primary technical bottleneck in modern data architecture is that cloud storage—such as S3, ADLS, or GCS—is fundamentally append-only. You cannot update a specific byte in the middle of a 100MB Parquet file; you can only delete the file or write a new one. This creates a direct conflict with the nature of CDC, where individual rows are updated or deleted constantly. In a traditional data lake, modifying a single row requires the system to read the entire file, change the value in memory, and write a completely new file back to storage. This process makes high-frequency updates a fragile and expensive operation.
Apache Iceberg addresses this by decoupling the physical data from the logical table state. Instead of forcing a rewrite of the data file every time a change occurs, Iceberg uses a robust metadata layer to track which records are valid. It treats the data lake more like a version-controlled repository. When a change happens, Iceberg can simply record the new data in a new location and update its internal map (the manifest files) to point to the most recent version of that row. This architectural shift moves the complexity away from the storage layer and into the metadata layer, providing a reliable way to handle row-level mutations without the overhead of constant file rewriting.
Strategic Architecture Patterns for CDC Ingestion
The way you structure your data flow from the source database to the Iceberg table determines your system's latency, cost, and query performance. There is no one-size-fits-all approach; instead its a trade-off between do you want faster saves at the cost of slower reads, or vice versa.
Pattern 1: Direct Materialization
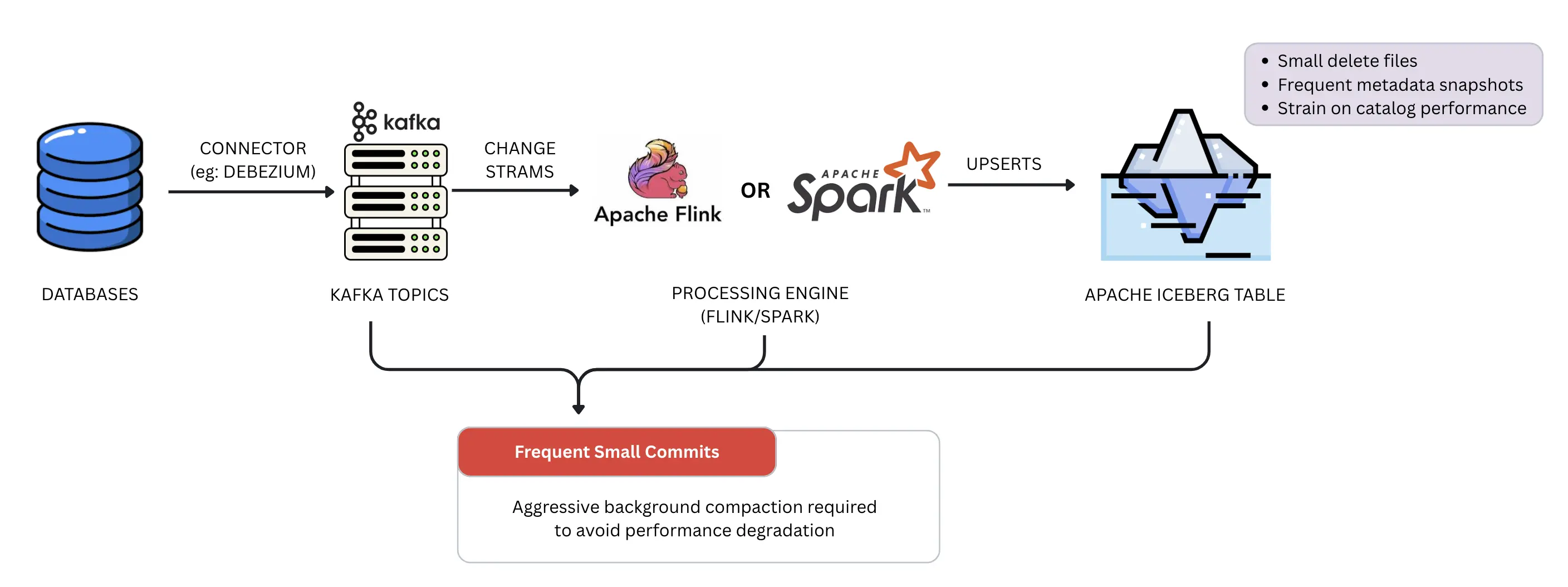
In this architecture, data flows from the database via a connector like Debezium into a Kafka topic, and then streamed through the processing engine (Flink or Spark), which performs an immediate UPSERT into the target Iceberg table. This pattern provides the lowest possible latency during write, as the data is materialized in its final state almost instantly. However, it can be a fragile approach for high-volume streams. Because every incoming change must be reconciled with the existing table state, the system often produces a high volume of small delete files and metadata snapshots. This constant stream of small commits puts immense pressure on the Iceberg catalog and can lead to significant performance degradation during table scans if not managed by aggressive background compaction.
Pattern 2: The Raw Change Log
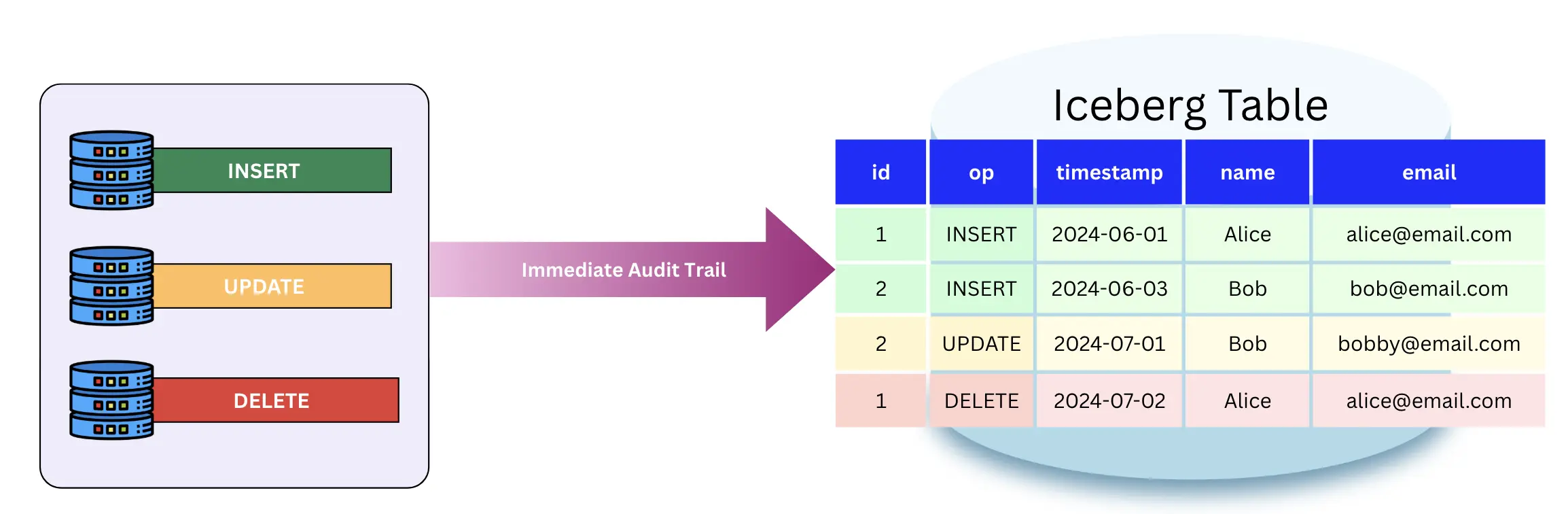
This pattern ignores immediate materialization in favor of a permanent audit trail. Every INSERT, UPDATE, and DELETE event is simply appended to an Iceberg table as a new row. This is a robust and cost-effective way to ingest data because it involves zero file rewrites—you are only ever performing appends. The trade-off is shifted entirely to the reader. To see the current state of a record, the query engine must perform a complex merge-on-read operation across the entire history of changes. While this provides a perfect audit trail and makes replaying data easy, it eventually results in a bottleneck for analytical queries as the log grows.
Pattern 3: The Hybrid Medallion Approach
The recommended Medallion approach combines the strengths of the previous two patterns. You maintain a raw change log (Bronze) for durability and then use an asynchronous process to reconcile those changes into a cleaned, materialized table (Silver or Gold). By using a MERGE INTO command in micro-batches, you can control exactly when and how the expensive compaction work happens. This decouples the ingestion speed from the query speed, ensuring that your production-facing tables remain reliable and performant without slowing down the real-time data stream.
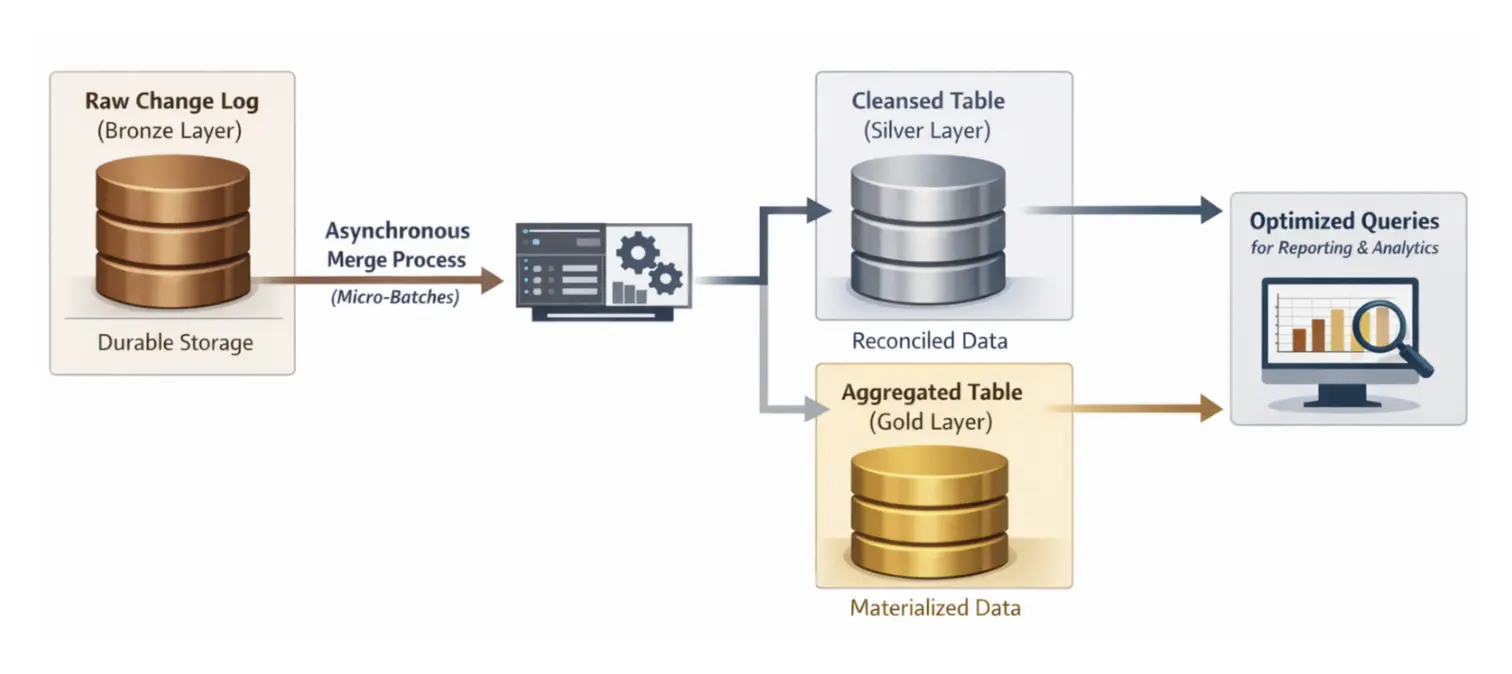
Pattern 4: Continuous Compaction
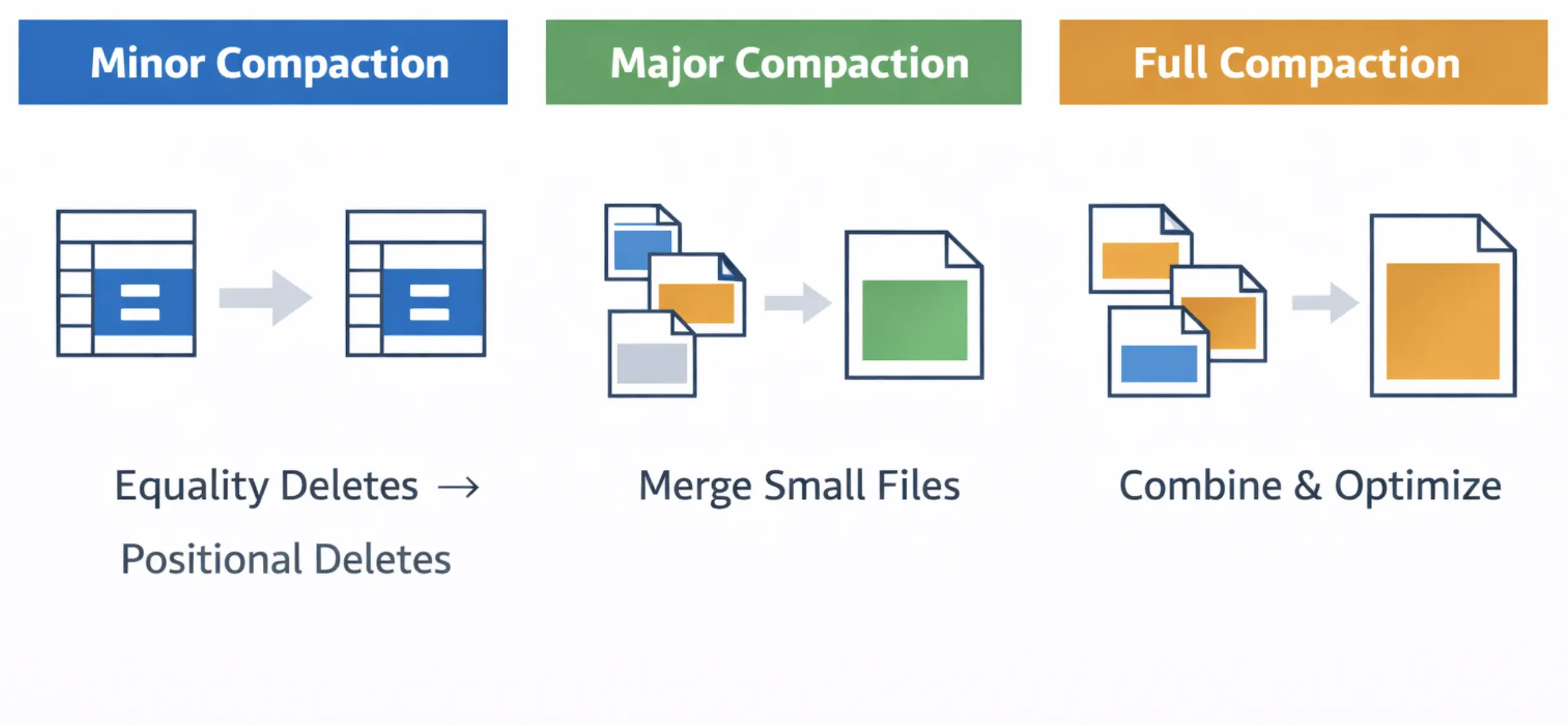
This advanced pattern, inspired by projects like Apache Amoro, reimagines how we handle deletions. Instead of waiting for a massive rewrite job, the system ingests all data in an Equality Delete format. This allows ingestion to continue at high speed without interruption. We then run a custom, tiered compaction process in the background that does not require stopping the world.
Think of this like a multi-stage sorting facility. In the Minor stage, we quickly convert expensive Equality Deletes into more efficient Positional Deletes. In the Major stage, we bundle small, fragmented files into medium-sized ones to reduce metadata overhead. Finally, in the Full stage, we optimize everything into the target file size (e.g., 512MB). This approach is future-proof because it allows for parallel ingestion and compaction, ensuring that small file overhead never accumulates to the point of system failure.
The Critical Decision: Copy-on-Write (CoW) vs. Merge-on-Read (MoR)
While both methods allow you to handle updates in Iceberg, they represent two fundamentally different philosophies of resource management. Choosing the wrong one for your specific workload can turn a flexible data lake into a bottleneck for your entire organization.
CoW: The Read-Optimized Path
Copy-on-Write (CoW) is designed for environments where data is read much more often than it is changed. In this model, any update or deletion triggers a rewrite of the entire data file containing the affected rows. This ensures that the table always consists of clean parquet files with no external dependencies. While this makes queries incredibly fast, it is a fragile strategy for high-churn CDC. If your source database has a high volume of updates, the system will spend all its time rewriting the same files over and over, leading to massive resource waste and high ingestion latency.
MoR: The Write-Optimized Path
Merge-on-Read (MoR) is the preferred path for high-velocity CDC because it avoids the immediate penalty of rewriting data files. Instead, it captures changes by writing delete files. These files come in two primary flavors: Position Deletes, which point to a specific row's location in a file, and Equality Deletes, which mark rows for deletion based on a column value (e.g., id=123). This makes the ingestion process robust and fast. However, it introduces a Read Tax, as the query engine must now reconcile the base data files with these delete files at runtime to provide a consistent view.
The Hybrid Approach
In production environments, architects rarely stick to a pure version of either strategy. The hybrid approach uses MoR for the initial ingestion to ensure the system can handle the high-velocity stream of CDC events without choking. This keeps the data fresh and the ingestion pipeline reliable.
To prevent the overwrite of increased delete files from making queries too slow, a background process asynchronously converts these MoR files into a CoW-style format through compaction. This transition moves the table from a flexible, write-heavy state to a performant, read-optimized state. By choosing the Hybrid approach, you ensure that the system remains future-proof, providing real-time data visibility today without sacrificing the speed of analytical queries tomorrow.
Implementation
You can implement CDC with Apache Iceberg from different databases like MySQL, Postgres, Oracle, MongoDB, etc using OLake. The detailed steps for implementing the CDC pipeline are mentioned here.
While the present CDC implementation into Apache Iceberg with OLake is quite efficient, we are introducing the efficient continuous compaction pattern very soon. Look out for this launch, and definitely try it out! You will be pretty amazed at the compact efficiency that you can achieve with this pattern.
Technical Deep Dive
Even with a robust table format like Iceberg, production CDC pipelines often fail due to the complexity of real-world data streams. To build a reliable system, we must address the complex parts of distributed data—ordering, schema changes, and physical layout—before they turn into architectural bottlenecks.
Ordering and Deduplication
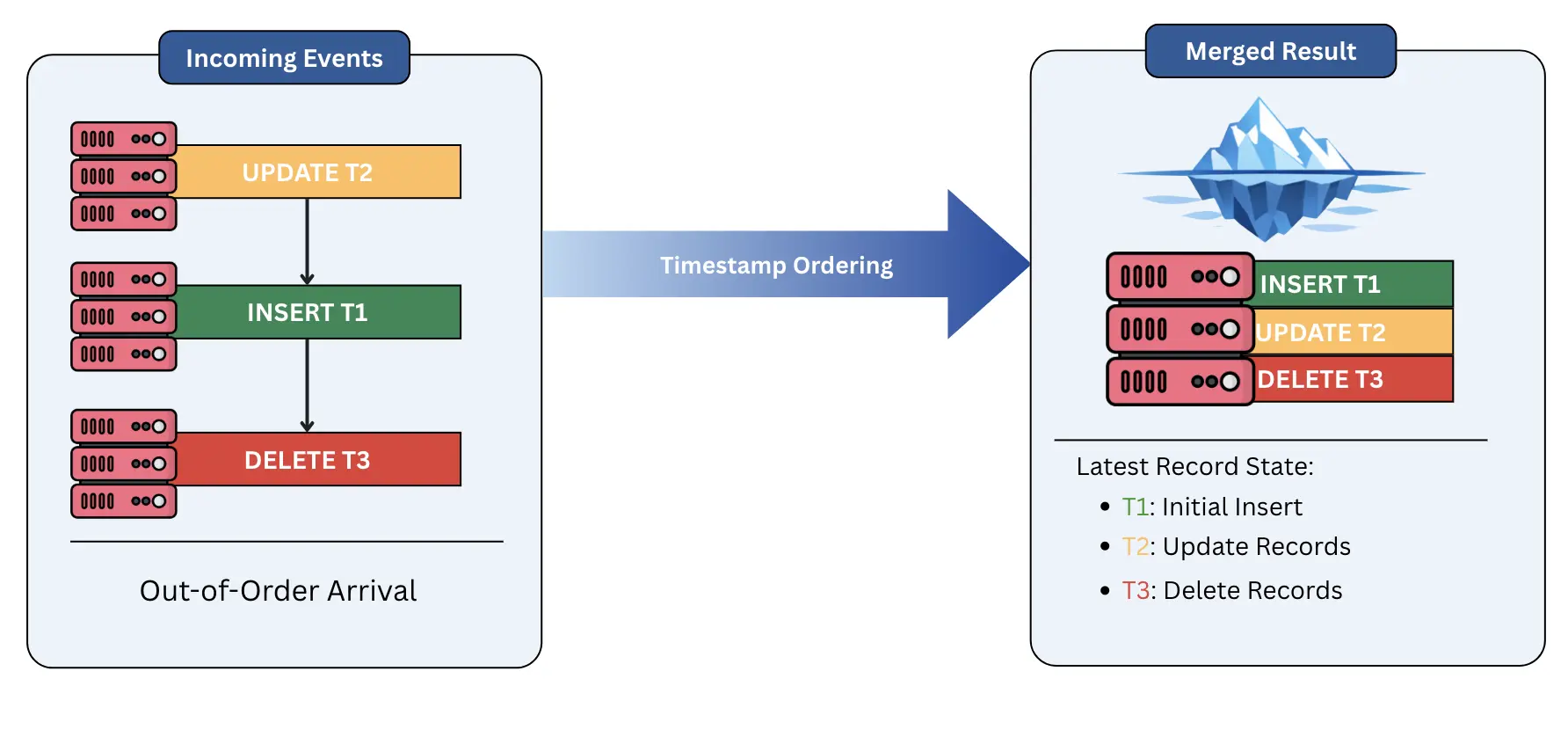
In a distributed environment, events rarely arrive in the exact order they occurred. Network latency or retries can cause an UPDATE to arrive before the initial INSERT. If handled naively, this creates a fragile state where your data lake reflects a reality that never existed. To solve this, we must rely on deterministic ordering fields from Debezium or from the source database. By using these fields during the merge process, Iceberg ensures that only the "latest" version of a record is materialized, providing a consistent and accurate view of the truth regardless of arrival order.
Schema Evolution
One of the most common nightmares in data engineering is an upstream developer adding or renaming a column in the source database, which traditionally breaks downstream pipelines. Iceberg provides a future-proof solution through its superior schema evolution capabilities. Unlike older formats that require expensive data rewrites or "schema-on-read" hacks, Iceberg assigns unique IDs to every column. This allows you to add, drop, or rename columns without ever touching the underlying data files. This architecture is flexible enough to handle rapid changes in the source system without causing a total failure of the ingestion pipeline.
Partitioning Strategies
A major pitfall in CDC design is relying on standard time-partitioning (e.g., partitioning by event_day). In a CDC context, updates to an old record (like a user profile created three years ago) would require the system to open and modify a partition from three years ago. This creates a massive performance bottleneck and leads to fragmented data.
To build a more performant system, we often move toward Bucketing or Hidden Partitioning based on a primary key or a high-cardinality ID. This ensures that updates for a specific record are always localized to the same set of files, regardless of when the record was first created. By moving away from rigid time-based structures, we create a robust physical layout that scales as the dataset grows, ensuring that row-level mutations remain efficient over the long term.
Operational Best Practices
Once the ingestion pipeline is running, the focus shifts to maintenance. To keep the lakehouse performant, you must actively manage the metadata and physical files that accumulate every hour.
Compaction
While CDC allows for near-real-time updates, the constant stream of small files and delete files eventually becomes a bottleneck for queries. Compaction is the process of merging these small files into larger, more efficient blocks.
- Bin-packing: This is the most common strategy. It takes a collection of small files and simply packs them into a larger file (e.g., 512MB). It is a robust and fast way to reduce metadata overhead and improve read speed without heavy computation.
- Sorting: For more complex workloads, sorting the data during compaction can drastically improve query performance by co-locating related data. While more resource-intensive, it ensures that "Z-ordering" or hierarchical sorting remains reliable, allowing the query engine to skip even more data during scans.
Snapshot Expiration
Every commit in Iceberg creates a new snapshot, and by default, these snapshots (and the data files they point to) are kept forever. This is a nightmare for storage costs and metadata performance. To keep the system flexible, you must implement a snapshot expiration policy. The goal is to balance the need for time travel, the ability to query historical data, against the reality of storage budgets. A future-proof strategy usually involves keeping 24 to 48 hours of snapshots for immediate recovery, while expiring anything older to reclaim space and keep the metadata tree lean.
Orphan File Cleanup
In distributed systems, things go wrong. A Spark executor might crash, or a network flap might interrupt a commit. When this happens, data files may be written to storage but never actually linked to the Iceberg table metadata. These are "Orphan Files." Over time, these files accumulate and become a hidden resource drain.
Think of this like construction debris left behind after a building is finished. The building is functional, but the site is cluttered. Running a regular remove_orphan_files procedure is a reliable way to sweep the underlying storage and delete any files that are not tracked by a valid snapshot. This ensures that your cloud storage costs reflect only the data you are actually using.
Conclusion
Building a reliable CDC pipeline with Apache Iceberg is about selecting the right architectural patterns to handle the friction between real-time data and immutable storage. We have moved from the brittle world of daily snapshots to a future-proof model where data flows continuously and remains immediately actionable. To succeed, architects must embrace a strategy that prioritizes robust ingestion while maintaining a high-performance query experience for the end user.
The foundation of this path lies in the Medallion Architecture, using a raw change log (Bronze) to ensure data durability and an asynchronous merge process (Silver/Gold) to handle the heavy lifting of materialization. By adopting Merge-on-Read (MoR) for high-velocity streams and augmenting it with a tiered, continuous compaction strategy, you eliminate the bottlenecks that typically are the major pain points for large-scale data lakes. This approach ensures that your system stays flexible, allowing you to ingest thousands of changes per second without forcing users to wait minutes for their queries to finish.
As the data lakehouse ecosystem continues to mature, the tools for managing these tables are becoming increasingly autonomous. Systems that self-optimize, such as Apache Amoro, represent the next step in this evolution. By following these architectural principles, you aren't just building a pipeline for today; you are constructing a performant and reliable foundation that will scale alongside your organization’s data needs for years to come.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.