

50% Cheaper (2x Faster) Iceberg Compaction: OLake Fusion (Open Source) Beats Spark
We benchmark Spark rewrite_data_files against OLake Fusion compaction on Apache Iceberg by running a full TPCH lineitem load from Postgres to GCP, applying 200k-record CDC batches every 2 minutes, and tracking TPC-H Query 6 performance, runtime, resource usage, and infrastructure cost.
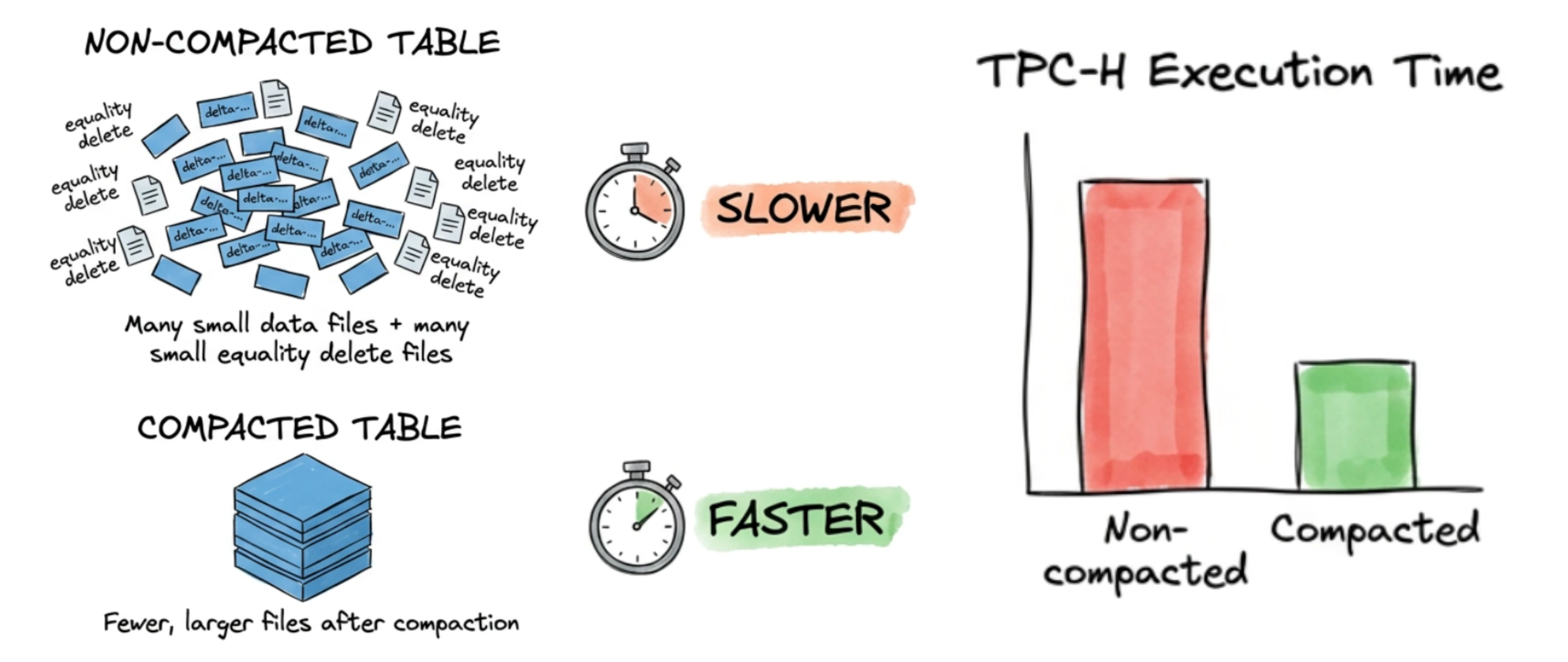
Iceberg Compaction: How Much Faster Are TPC-H Queries?
We ran TPC-H queries on Iceberg tables with many small files, then compacted them and ran the same queries again. Here's how much faster compaction made them.
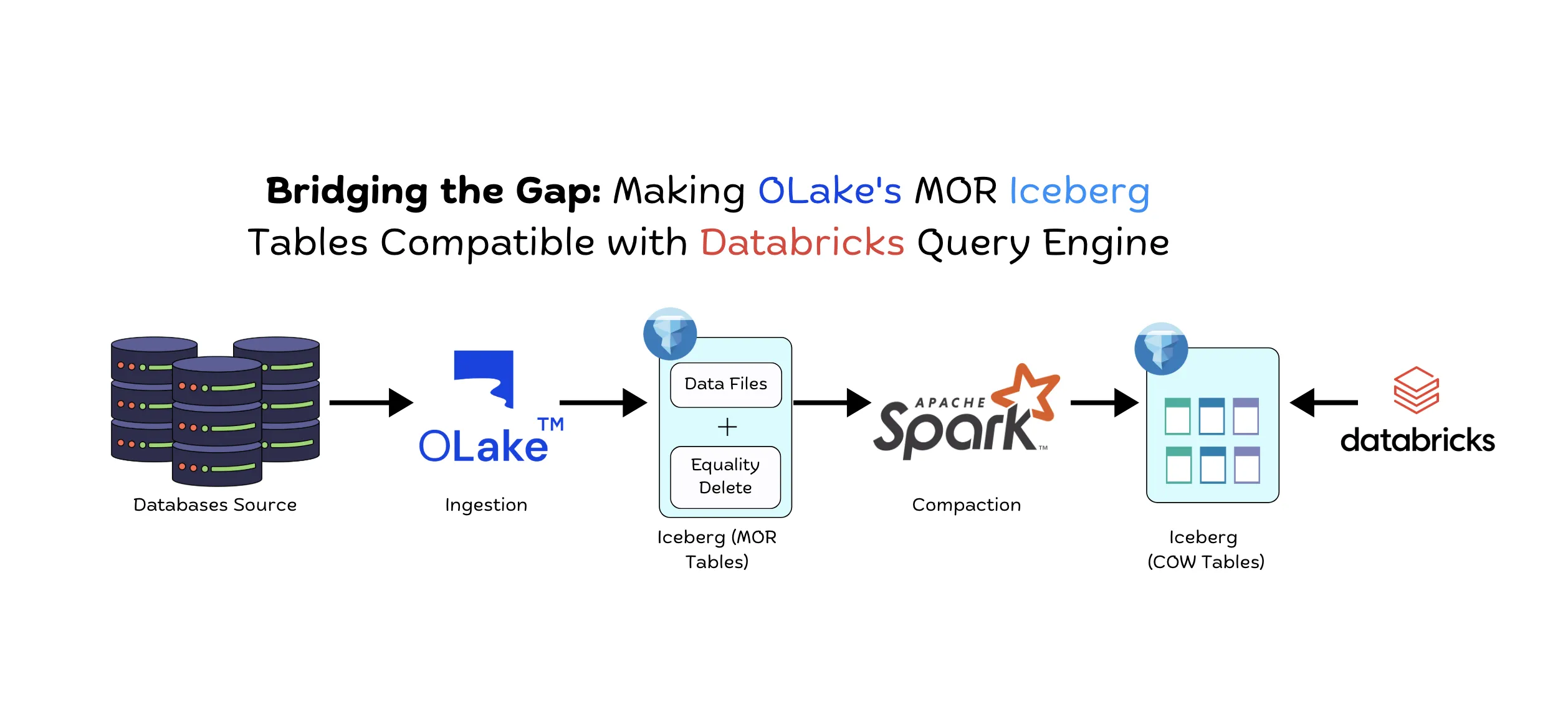
Bridging the Gap: Making OLake's MOR Iceberg Tables Compatible with Databrick's Query Engine
Learn how to make OLake's Merge-on-Read (MOR) Iceberg tables compatible with Databricks using an automated MOR to COW write script that transforms MOR tables into Copy-on-Write (COW) format for accurate analytics queries.

Building a Serverless Iceberg Lakehouse: OLake's Speed + Bauplan's Git Workflows
Learn how OLake and Bauplan work together to create a powerful, version-controlled data lakehouse on Apache Iceberg.