Building Modern Lakehouse with Iceberg, OLake, Lakekeeper & Trino


Quick on that here : Iceberg is the storage "brain", OLake is the real-time "pipeline", and Trino is the fast "question-answering" engine.
Together they turn raw object-storage files into a governed, low-latency analytics platform. Data engineering nowadays has swung toward the lakehouse paradigm where we are mixing data lake scale with warehouse reliability and this blog walks through a hands-on stack of open-source tools that make a Lakehouse work.
We'll see how Apache Iceberg (an open table format), OLake (fast DB→lake loader), Lakekeeper (Iceberg's REST catalog), and Trino (distributed SQL engine) fit together. Think of it as a friendly tour of each component (what it is, why it matters and most importantly how it all connects)
What Is Apache Iceberg?
Well to understand it a bit simpler you can picture a giant library where every book (data file) sits on random floors with no catalog. Finding the Harry Potter series would be a chaos. Iceberg acts as the modern Dewey Decimal system: it tags every file with rich metadata, tracks versions, and lets you time-travel to yesterday's shelves all without moving the books themselves . Thus, now you can read books and data engineers can query data better .
Well what's the value of it ?
Firstly , you get database-style "all-or-nothing" writes on cheap object storage, e.g. S3, GCS, Azure blobs or Minio. You can add, rename, or drop columns and partitions without rewriting terabytes.
Query your data "as of" last Tuesday for audits or bug fixes.
Hidden Partitioning — Iceberg tracks which files hold which dates, so queries auto-skip irrelevant chunks, no brittle dt='2025-07-21' filters required.
Most importantly it is engine-agnostic you might have heard this term a lot and here it gets a meaning iceberg supports Spark, Trino, Flink, DuckDB, Dremio, and Snowflake all speak to the tables natively
Before Iceberg, data lakes were basically digital junkyards. You'd dump data files into cloud storage (like Amazon S3), and finding anything useful was like looking for a specific needle in a haystack .
Understanding Iceberg Catalogs: The Foundation Layer
Think of the catalog as the librarian of your data lakehouse it keeps track of which tables exist, where they are, and which version is current.
The Catalog Challenge in Iceberg
Every time you make changes to an Iceberg table whether adding rows, updating schemas, or modifying partitions Iceberg creates a new metadata.json file (like v1.metadata.json, v2.metadata.json). Over time, you accumulate hundreds of these files.
The critical question becomes: how do query engines like Trino, Spark, or DuckDB know which metadata file represents the "current" state of the table?
This is where the catalog becomes essential. The catalog serves two fundamental purposes:
-
Maintains a registry of existing Iceberg tables like a phone book for your data assets
-
Tracks pointers to the current metadata.json file ensuring everyone sees the same version of truth
There are different type of data catalogs file based and service based and today, we're taking a closer look at Lakekeeper a type of data catalog that resolves these challenges so we will cover what it is, how it stands out, and exactly what category of catalog it belongs to for Apache Iceberg.
What is Lakekeeper?
(Empowering Object Storage with Iceberg and Enterprise-Grade Governance)
Lakekeeper turns ordinary object storage (like S3) into a fully governed Apache Iceberg lakehouse. Out of the box, S3 is just a bunch of files with basic access controls. Lakekeeper manages all the Iceberg metadata (schemas, snapshots, pointers) so your storage now supports transactions, time travel(going back at a particular commit ) and consistent views across all engines (Trino, Spark, DuckDB, you name it).
What really makes Lakekeeper stand out is how it hooks into your organization's identity, access control, and policy tools (like OPA and OpenFGA). This means you get table, column, even row-level permissions and governance applied no matter who's querying or how they access the data.
In short: By combining open table formats (Iceberg) and centralized, policy-driven control, Lakekeeper upgrades your object store from "just a bucket" to a secure, compliant, analytics-ready platform. That's the key to making S3 truly enterprise and audit—friendly.
Why Lakekeeper Isn't Just Another Catalog
It fully implements the Apache Iceberg REST Catalog API, making it compatible with any query engine that supports the Iceberg standard REST interface.
Written in Rust, it's lightning-fast and extremely lightweight; just one binary to deploy, but strong enough for enterprise-grade operations
How it suits modern pipelines?
What really sets Lakekeeper apart is how it bridges the gap between raw object storage and truly managed, governed Iceberg tables. Most basic catalogs just keep a list of where the data is, but Lakekeeper acts as a smart, active coordinator that actually turns cloud buckets into a secure, production-ready analytical layer.
Instead of relying on the old approach where you had to manage clunky file-based pointers or deal with slow, legacy services, Lakekeeper brings the agility, real-time response, and open standards you'd expect from a modern data stack.
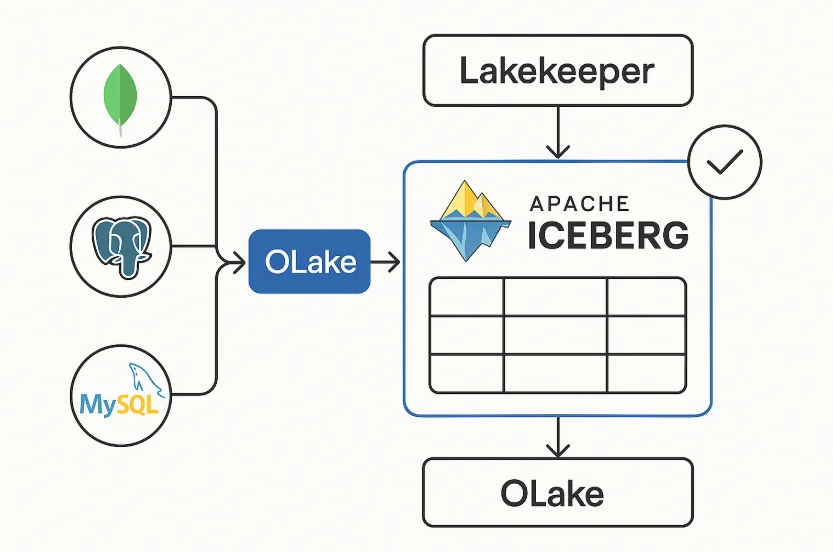
What is OLake?
Now that you understand how Apache Iceberg organizes your data lake into a well-structured, reliable system, you're probably wondering: "That's great, but how do I actually get my operational data INTO Iceberg format?"
This is where the rubber meets the road in building a modern lakehouse.
Traditional approaches involve complex setups with tools like Debezium + Kafka, or using generic ETL platforms that weren't designed for the specific demands of lakehouse architectures. These solutions often struggle with scale, reliability, and the unique requirements of Apache Iceberg. That's exactly the gap that OLake was built to fill it's like having a specialized highway that moves data from your operational databases directly into the Iceberg ecosystem, fast and reliably.
Still confused ? Think of it this way: if your operational database is like a busy restaurant kitchen constantly taking orders and making food, OLake is like having a super-efficient catering service that continuously packages up perfect copies of those meals and delivers them to your analytics "dining hall" (the data lakehouse) without disrupting the kitchen operations.
How Lakekeeper and OLake Work Together for Ingestion
(And Why It's a Game-Changer for Real-Time, Production-Grade Data Stacks)
So you've set up your data lakehouse and you want fresh, reliable data to land there fast, secure, and always discoverable by everyone who needs it. That's where the tag team of OLake (for high-speed database replication) and Lakekeeper (as the brains of your Iceberg metadata) steps in. Let's break down exactly how these two connect, and what happens under the hood when new data is ingested.
The Big Picture Flow
OLake handles pulling change data from your databases (like MongoDB, PostgreSQL, MySQL), breaks it into efficient chunks, and writes it directly into Apache Iceberg tables. But it needs to coordinate all metadata table versions, schema, file locations to make sure what it writes is instantly queryable, consistent, and secure.
Lakekeeper is the REST catalog that acts as the "metadata authority" where OLake checks what tables exist it is the place OLake registers new data and schema changes while also acting as the guardrail for access, audit, and governance
In short: OLake does the heavy lifting, but Lakekeeper makes sure every lift is recorded, governed, and easy to discover in real-time by analytical engines like Trino.
What is trino? : Distributed SQL on Everything
![]()
With storage (Iceberg) and metadata (Lakekeeper) in place, we need a query engine. Trino fits the bill for that . It's an open-source distributed SQL engine designed for interactive analytics on big data lakes.
It lets you ask questions in standard SQL across data sitting anywhere, from object-storage "data lakes" to traditional databases, without copying or moving that data. Think of it as a super-fast interpreter that speaks SQL, fans work out to many servers in parallel, and hands you results in seconds, even at petabyte scale.
Quick Definition
Trino is a "query engine," not a database.
It stores no data itself. Instead, it connects to many systems, splits your SQL into small tasks, runs them in parallel on worker nodes, and merges the answers back to you
Core Concept
-
It stores no data itself and basically purely acts as compute layer while also being able to connect to multiple systems (S3, MySQL, Kafka, etc.) and make them look like SQL tables.
-
It also supports massive parallelism where it breaks queries into small tasks, runs them across worker nodes, and merges results. Thus, making things more efficient as compared to traditional approach
Why Trino Exists?
-
Speed over Hive & MapReduce: Facebook's data analysts needed sub-minute answers on multi-petabyte Hadoop clusters; Hive's MapReduce jobs took hours. The first Presto prototype (Trino's original name) appeared in 2012 to fix that.
-
SQL for Everything: Teams hated learning four different APIs. Trino made any data source look like an ANSI-SQL table.
-
Data Stays Put: Copying data is slow, risky, and costly. Trino federates live sources so analytics teams can join S3 logs with MySQL customer tables in one query.
-
Open Governance: After leaving Facebook, the creators forked PrestoSQL and rebranded it as Trino in 2020 to keep development community-driven.
So if you are wondering why would you even consider trino let me get you in on some benefits on using that
Key Benefits — Why it's so powerful?
-
Trino is like that powerhouse for the organizations that want to save time on analysis here we get answers in seconds on terabyte datasets vs. hours with traditional tools like presto .
-
Same familiar SQL syntax across all data sources so you don't have to learn multiple ways of querying that data
-
If you are organization scaling is the NEED of the hour well it goes ahead and supports elastic scaling where you can add workers to cut runtime nearly linearly
-
Most importantly it doesn't make you dependent on one vendor, might have heard of vendor lock in right? Yup, sorts it out aswell .
Putting It All Together with Docker Compose 🐋
Here's a minimal Docker Compose snippet that wires up these services. It uses MinIO as S3 storage, Lakekeeper as the catalog, OLake as an ingestion service, and Trino as the query engine. (In practice you'd supply actual config files or env vars as needed.)
For those wondering what even is MinIO is it's a simple, S3-compatible object storage service that runs locally, making it incredibly useful for experimenting with what you're learning before moving to a full cloud setup.
Click to expand Docker Compose YAML
version: '3.8'
services:
minio:
image: quay.io/minio/minio:latest
container_name: minio
volumes:
- minio-data:/data
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
command: server /data --console-address ":9001"
ports:
- "9000:9000" # API port
- "9001:9001" # Console port
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
lakekeeper:
image: ${LAKEKEEPER__SERVER_IMAGE:-quay.io/lakekeeper/catalog:v0.11.1}
pull_policy: always
environment:
- LAKEKEEPER__PG_ENCRYPTION_KEY=This-is-NOT-Secure!
- LAKEKEEPER__PG_DATABASE_URL_READ=postgresql://postgres:postgres@db:5432/postgres
- LAKEKEEPER__PG_DATABASE_URL_WRITE=postgresql://postgres:postgres@db:5432/postgres
- LAKEKEEPER__AUTHZ_BACKEND=allowall
# Externally taken from environment variables if set
- LAKEKEEPER__OPENID_PROVIDER_URI
- LAKEKEEPER__OPENID_AUDIENCE
- LAKEKEEPER__OPENID_ADDITIONAL_ISSUERS
- LAKEKEEPER__UI__OPENID_CLIENT_ID
- LAKEKEEPER__UI__OPENID_SCOPE
command: [ "serve" ]
healthcheck:
test: [ "CMD", "/home/nonroot/lakekeeper", "healthcheck" ]
interval: 1s
timeout: 10s
retries: 3
start_period: 3s
depends_on:
migrate:
condition: service_completed_successfully
ports:
- "8181:8181"
restart: unless-stopped
migrate:
image: ${LAKEKEEPER__SERVER_IMAGE:-quay.io/lakekeeper/catalog:v0.11.1}
pull_policy: always
environment:
- LAKEKEEPER__PG_ENCRYPTION_KEY=This-is-NOT-Secure!
- LAKEKEEPER__PG_DATABASE_URL_READ=postgresql://postgres:postgres@db:5432/postgres
- LAKEKEEPER__PG_DATABASE_URL_WRITE=postgresql://postgres:postgres@db:5432/postgres
- LAKEKEEPER__AUTHZ_BACKEND=allowall
# Externally taken from environment variables if set
- LAKEKEEPER__OPENID_PROVIDER_URI
- LAKEKEEPER__OPENID_AUDIENCE
- LAKEKEEPER__OPENID_ADDITIONAL_ISSUERS
- LAKEKEEPER__UI__OPENID_CLIENT_ID
- LAKEKEEPER__UI__OPENID_SCOPE
restart: "no"
command: [ "migrate" ]
depends_on:
db:
condition: service_healthy
db:
image: bitnami/postgresql:16.6.0
container_name: db
environment:
- POSTGRESQL_USERNAME=postgres
- POSTGRESQL_PASSWORD=postgres
- POSTGRESQL_DATABASE=postgres
healthcheck:
test: [ "CMD-SHELL", "pg_isready -U postgres -p 5432 -d postgres" ]
interval: 2s
timeout: 10s
retries: 2
start_period: 10s
volumes:
- volume-lakekeeper:/bitnami/postgresql
trino:
image: trinodb/trino:latest
container_name: trino
ports:
- "8082:8080"
depends_on:
- lakekeeper
- minio
volumes:
- ./trino/etc:/etc/trino:ro
environment:
# Optional: Add any Trino-specific environment variables
TRINO_ENVIRONMENT: development
restart: unless-stopped
# Note: Ensure ./trino/etc contains proper catalog configuration:
# File: ./trino/etc/catalog/iceberg.properties
# connector.name=iceberg
# iceberg.catalog.type=rest
# iceberg.rest-catalog.uri=http://lakekeeper:8181
# iceberg.rest-catalog.warehouse=warehouse
# fs.s3.aws-access-key=minio
# fs.s3.aws-secret-key=minio123
# fs.s3.endpoint=http://minio:9000
# fs.s3.path-style-access=true
# OLake service - commented out as the image may not be publicly available
# olake:
# image: datazipinc/olake:latest
# container_name: olake
# depends_on:
# - minio
# - lakekeeper
# environment:
# # Add required OLake configuration
# OLAKE_S3_ENDPOINT: http://minio:9000
# OLAKE_S3_ACCESS_KEY: minio
# OLAKE_S3_SECRET_KEY: minio123
# OLAKE_CATALOG_URI: http://lakekeeper:8181
# restart: unless-stopped
# # Add ports if OLake exposes a web interface
# # ports:
# # - "8082:8082"
volumes:
minio-data:
driver: local
volume-lakekeeper:
networks:
default:
name: lakehouse-network
With that up (docker compose up), you'd have MinIO as object storage, Lakekeeper listening on port 8181, and Trino on 8080.
In Trino's catalog config (shown above as comments), we create an Iceberg catalog of type rest pointing to Lakekeeper. This tells Trino to use Lakekeeper as the metadata store. and OLake would be running too, ready to sync data from your databases into Iceberg tables on MinIO.
Note: The exact configs (region, bucket, etc.) depend on your setup. You'll also need to create a warehouse in Lakekeeper (via its UI or API) and tell Trino which warehouse to use. Check Lakekeeper docs and Trino's Iceberg connector docs for full details
Example Trino Query
Once everything is running, you can query your Iceberg tables with Trino like any SQL database. Here's a simple example of a business query joining two tables:
SELECT c.country, SUM(o.amount) AS total_sales
FROM customers AS c
JOIN orders AS o
ON c.customer_id = o.customer_id
WHERE o.order_date >= DATE '2025-01-01'
GROUP BY c.country
ORDER BY total_sales DESC;
In this query, customers and orders are Iceberg tables managed by Lakekeeper. Trino will translate the SQL into distributed file scans: reading Parquet files in S3/MinIO, filtering, grouping, etc because Iceberg tracks partitions and snapshots, Trino can push down predicates (e.g. on order_date) and only read relevant files.
Even updates or deletes you made via Iceberg's MERGE/DELETE commands will be handled correctly under the hood (Iceberg's metadata ensures consistency).
This simple example shows the power of the stack: you define your tables in Iceberg, OLake or other pipelines load them, Lakekeeper keeps metadata, and Trino lets you run normal SQL against the data. You could swap in DuckDB for ad-hoc local queries on the same data, or add Spark to the mix for large ETL jobs the data format remains the same.
Trino x Lakekeeper
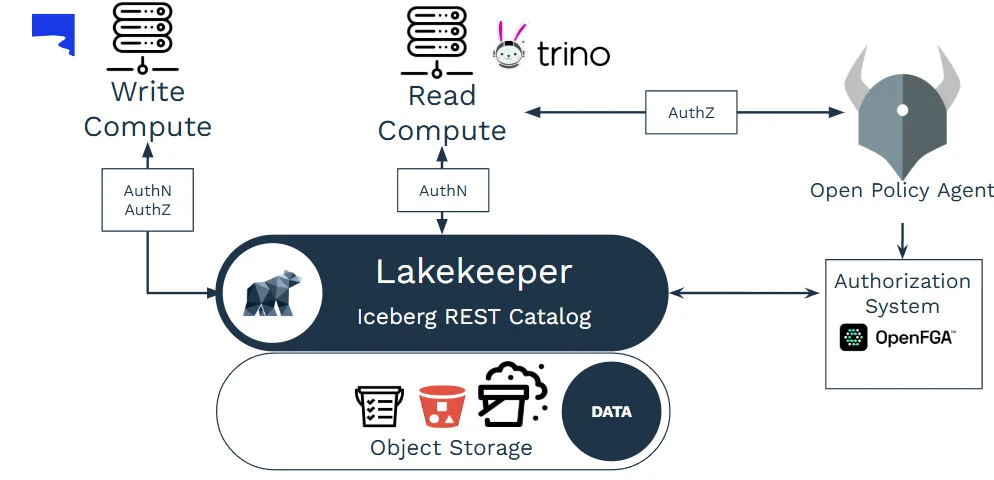
Now that Trino is ready to run your queries, Lakekeeper steps in as its metadata guardian ensuring every Iceberg table is tracked, secured, and instantly discoverable.
Lakekeeper is a service-based Apache Iceberg REST catalog written in Rust. Point Trino's Iceberg connector to Lakekeeper:
connector.name=iceberg
iceberg.catalog.type=rest
iceberg.rest-catalog.uri=http://lakekeeper:8181/catalog
From there you can get Consistent Snapshots: All engines (Trino, Spark, DuckDB) see the same table version no stale or conflicting metadata.
Security stays one of the important concerns but lakekeeper enforces OIDC authentication plus OpenFGA/OPA policies for table, column, and row-level access automatically on every Trino query if you want to read more about them you can do so here
In short, Lakekeeper transforms raw object storage into a governed, high-performance Iceberg layer that makes Trino queries reliable, secure, and effortlessly current.
How Iceberg, OLake,Lakekeeper and Trino Mesh
End-to-End Flow
- Ingest – OLake ingests CDC streams and commits Iceberg snapshots via Lakekeeper API.
- Discover – Trino's Iceberg connector points to Lakekeeper, instantly seeing new tables and versions.
- Secure & Govern – Lakekeeper checks OpenFGA policies for each Trino user before handing back metadata.
- Query – Trino executes federated SQL joins across fresh Iceberg data, legacy MySQL tables, and even Kafka streams—all through one engine.
What You Gain
| Benefit | Iceberg | OLake | Trino |
|---|---|---|---|
| Low-cost object storage | ✓ | - | - |
| Transactional writes | ✓ | ✓ (via Iceberg commits) | - |
| Real-time ingestion | - | ✓ | - |
| Snapshot time travel | ✓ | - | ✓ (select snapshot) |
| Interactive SQL | - | - | ✓ |
| Federated joins | - | - | ✓ |
| Centralized auth | - | - | ✓ (via Lakekeeper/OPA) |
| Engine-agnostic metadata | ✓ | ✓ | ✓ |
Conclusion
We've covered a modern open-source lakehouse setup: Iceberg for storage, OLake for loading data, Lakekeeper for metadata, and Trino for querying.
Each piece is designed for scale and flexibility. For example, Iceberg's features mean you can evolve schemas without downtime and "time travel" in your data. Lakekeeper adds security and standardization for those Iceberg tables. OLake takes care of the heavy lifting of moving data into the lake. And Trino glues it together by giving you a familiar SQL interface.
All of these tools play nicely with Docker (as shown) or Kubernetes, so you can spin them up for testing or production. If you're already familiar with Docker, you should have no trouble experimenting: try loading some sample data and running queries. The best way to learn is to dive in!
Happy building and welcome to the lakehouse club!
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.