Conflict-Free CDC into Apache Iceberg: Architecting Temporal Memory for Autonomous Agents

The transition from passive dashboards to autonomous Agentic AI introduces a unique architectural challenge to the modern data stack: Data agents are inherently stateless, but threat detection is inherently temporal. When building an autonomous security framework, agents rely on the Model Context Protocol (MCP) to query the network state. However, when an anomaly—such as a subtle DNS rebinding attack—is detected, querying the current state of the network graph is often insufficient. By the time an agent investigates, the attacker may already have mutated the DNS record or shifted IP addresses If your Change Data Capture (CDC) pipeline only overwrites historical state in the operational database, the agent lacks the context it needs to reconstruct the attack vector. It needs to be able to ask, "What was the exact topology of this DNS route 5 minutes ago?" Apache Iceberg’s Time Travel feature serves this purpose. However, running sub-second-latency queries on a fast-streaming Lakehouse is challenging due to metadata bloat and commit contention.
This guide looks at the mechanics of high-frequency streaming CDC. It describes an architecture that uses OLake's thread-coordinated ingestion and background compaction, OLake Fusion. This method transforms a Lakehouse into a low-latency temporal memory layer for autonomous threat detection, threat pattern prediction, correlation and monitoring.
Architectural Primitives: Iceberg Time Travel
To understand why high-velocity CDC breaks traditional ingestion, we must first establish how Apache Iceberg facilitates Time Travel. Iceberg does not manage data at the folder or directory level; it is a metadata-first architecture. Every write operation generates a linear chain of immutable temporal snapshots. Think of it as an un-erasable version history—a continuous timeline of permanent photographs capturing exactly what the network looked like at any given millisecond. The state of the table is defined through a strict metadata tree: metadata.json: The root pointer that tracks the current state and all historical snapshots. Manifest Lists (snap-.avro): A file listing the manifests included in a specific snapshot. Manifests (.avro): Files that track the exact paths, row counts, and column-level statistics (min/max bounds) of the underlying Parquet data files. When an autonomous agent runs a Time Travel query with FOR SYSTEM_TIME AS OF, the execution engine does not look through the raw data. It only opens metadata.json, finds the snapshot ID that was active at that millisecond, and uses the manifest statistics to quickly remove irrelevant files.
This metadata structure enables sub-second time-based reasoning. However, keeping this structure clean during the intense demands of real-time streaming is where traditional systems fail.
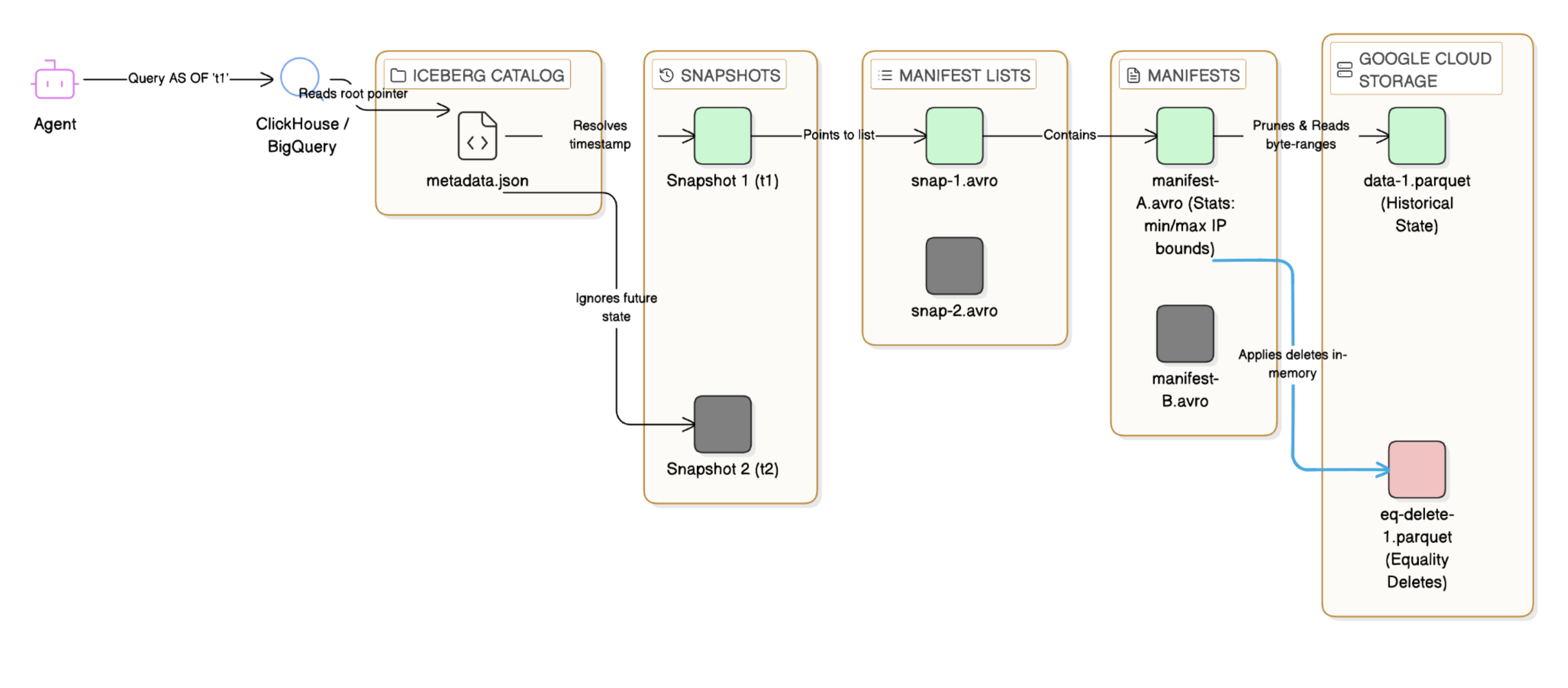
Fig.1 The Mechanics of Iceberg Time Travel. This diagram illustrates how the query engine (ClickHouse or BigQuery) executes a temporal query without scanning the entire data lake.
Defining the Streaming Bottleneck
Before detailing the solution, it is necessary to establish the data schema and understand why high-frequency streaming CDC strains traditional query engines.
1. Operational State: The Network Edge Schema
Consider a high-velocity operational database that helps users monitor live network edges. Every device/client/interface connection, disconnection, or resolution triggers an INSERT, UPDATE, or DELETE.
CREATE TABLE network_edges (
edge_id UUID PRIMARY KEY,
source_ip VARCHAR(45),
resolved_ip VARCHAR(45),
target_port INT,
connection_state VARCHAR(20), -- e.g., 'ESTABLISHED', 'DROPPED', 'MUTATED'
updated_at TIMESTAMP
)
PARTITIONED BY (days(updated_at));
As threat vectors evolve, this schema will also change. Since Apache Iceberg tracks columns by fixed IDs instead of names, OLake can easily pass upstream PostgreSQL ALTER TABLE events, such as adding a tls_cipher_suite column, directly to the Lakehouse. This process does not need pipeline downtime or rewriting old Parquet files.
2. The Direct-to-Storage Ingestion Path
To use the Agentic Firewall, data is ingested using native CDC. While massive enterprise architectures often utilise an event bus like Kafka to fan out telemetry to multiple distinct consumers, OLake’s architecture allows us to bypass this intermediary on the Lakehouse path. By removing the message bus, we strip out a layer of latency and operational overhead:
-
Data Source: PostgreSQL logical replication slot.
-
Ingestion Engine: OLake reads directly from the Postgres replication slot and writes directly to an Apache Iceberg table on Google Cloud Storage (GCS), managing the upserts and state natively.
3. Managing Read Amplification: The Physics of Merge-On-Read
In a high-throughput environment (e.g., enterprise /data center networks handling 10,000 state changes per second), we collide with the fundamental limits of object storage and columnar formats. Traditional data lake architectures default to Copy-On-Write (COW), which fails catastrophically under continuous mutation.
The Failure of Copy-On-Write (COW):
Think of COW like rewriting an entire 500-page textbook just to fix a single typo. Under the hood, a single 1KB row mutation forces the execution engine to deserialise an entire 500MB Parquet block, apply the state change in memory, re-encode the columnar structures, and execute a massive PUT request back to Google Cloud Storage. At 10,000 updates a second, this creates a catastrophic Write Amplification Factor (WAF). It saturates network bandwidth, exhausts cloud API quotas, and instantly grinds the ingestion pipeline to a halt.
The Shift to Merge-On-Read (MOR):
To survive this streaming firehose and meet strict ingestion SLAs, the Iceberg table must be configured for Merge-On-Read. Think of MOR like slapping a sticky note with a correction onto the textbook's cover. MOR shifts the compute penalty from write time to read time. During a micro-batch commit, OLake doesn't touch the massive base files. Instead, it converts random database updates into pure sequential APPEND operations—writing new data files (INSERTs) alongside small Equality Delete files (the sticky notes, e.g., "Consider any row where source_ip = '10.0.4.55' as deleted").
The Read Amplification Wall:
While appending "sticky notes" takes microseconds and saves the write path, it pushes a massive computational burden down to the query execution layer. When a vectorized engine (like BigQuery or chDB or DuckDB) queries the lake, it must broadcast all active Equality Deletes across its worker nodes and maintain them in a RAM-resident hash set. During the scan, the engine must perform a dynamic anti-join against the base data on the fly. As delete files accumulate, evaluating these row-level predicates destroys CPU cache locality and breaks SIMD vectorization efficiency. Left unmanaged, a temporal query SLA that should be 50ms spikes to 15 seconds as the engine exhausts its memory footprint, filtering obsolete rows. This creates the exact read amplification wall that OLake's architecture is engineered to bypass.
Architecting the Solution: The Mechanics of an OLake Commit
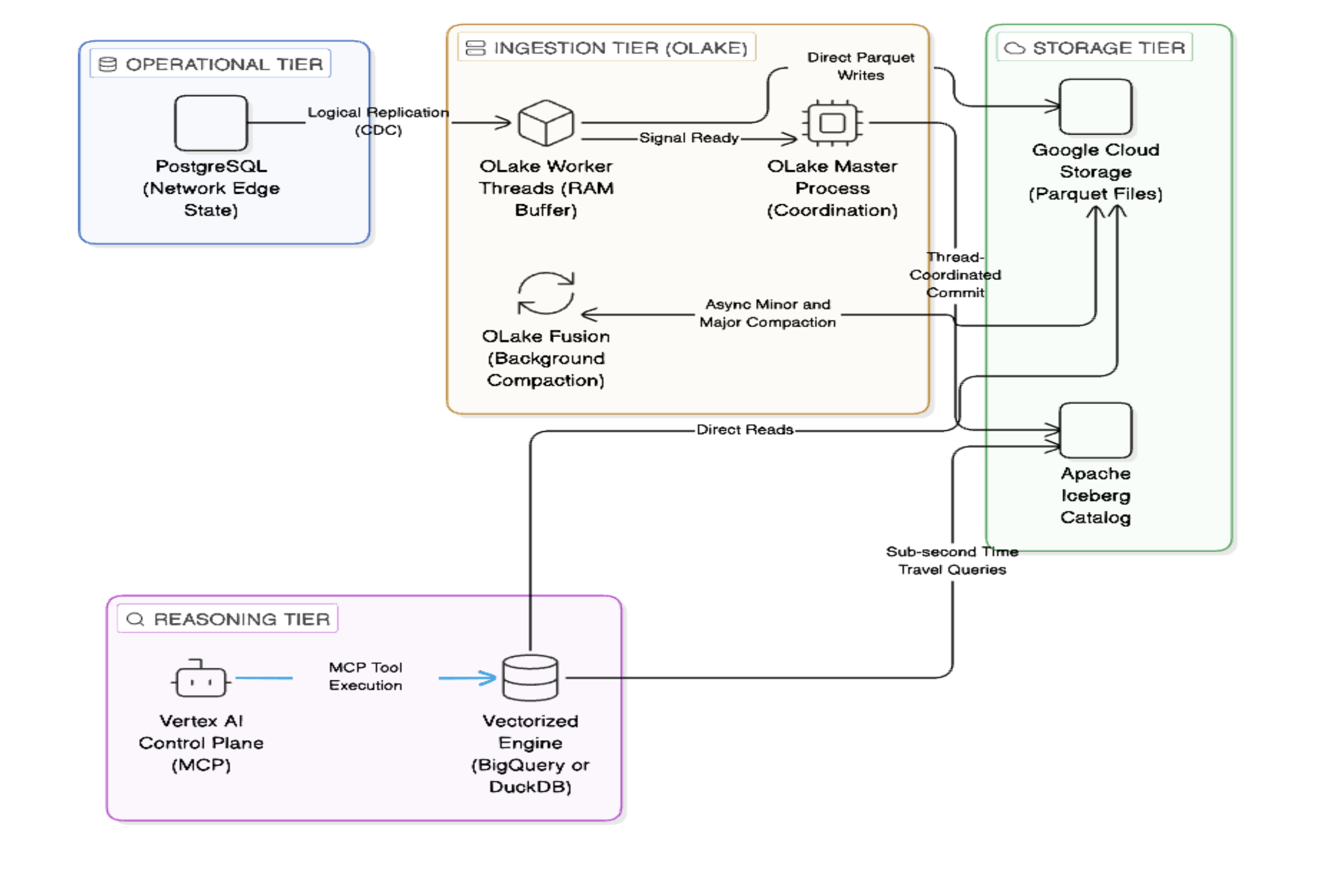
Figure 2. The end-to-end Agentic Data Architecture. Notice how the ingestion tier bypasses traditional message brokers like Kafka to minimise latency. On the left, OLake worker threads ingest CDC data directly from the PostgreSQL replication slot, using internal RAM buffers to fold noisy events before writing Parquet files directly to Google Cloud Storage. While OLake Fusion quietly compacts these files in the background, the Master Process handles the lightweight Iceberg catalog commits. On the right, this clean metadata allows the Vertex AI Control Plane to execute sub-second temporal reasoning via a vectorised execution engine.
To enable sub-second Time Travel, the ingestion layer must rigorously manage metadata hygiene. OLake achieves this through a highly concurrent, conflict-free architecture.
Phase 1: Lock-Free I/O via Logical Decoding
Before tailing the WAL for real-time deltas, OLake natively executes a lock-free historical snapshot of the Postgres table to establish the baseline state in Iceberg. Once the baseline is synced, it transitions to Logical Decoding for streaming updates. During this streaming phase, when OLake processes a batch of UPDATE events, it does not check the Iceberg Catalog to find existing data. Because the Postgres Write-Ahead Log (WAL) records not only the new state but also streams a complete change event containing the pre-update primary key (edge_id), OLake holds the exact unique identifier needed to generate the Equality Delete condition entirely in RAM. It writes the new state as data-.parquet files and simultaneously writes the eq-delete-.parquet files without ever polling the Iceberg catalog. Unlike traditional ETL, which maintains a local lookup table to find record locations, OLake uses the pre-update primary key from the WAL, allowing it to issue a "delete" command blindly. This is what makes it truly horizontally scalable. Workers do not need to coordinate or share state to know what to delete. By completely bypassing the "read-before-write" penalty (the computational tax of locating and loading existing data into memory before applying an update), OLake maintains a decentralized, lock-free I/O phase.
Phase 2: Hybrid Execution & GC Mitigation (Arrow/Java)
OLake achieves high-throughput ingestion through a pragmatic hybrid execution model, offering two modes for Iceberg writes:
-
Arrow-Based Mode: OLake generates Parquet files in Go using Apache Arrow, then submits them to iceberg-java to register them into the table. The manifest and min/max stats are generated efficiently at the Java level.
-
Java Insert Mode: OLake pulls data in Golang and submits the rows via a gRPC call to iceberg-java, which builds the Parquet files and the full ingestion, managing conflict-free schema evolution. While the Arrow-based mode already minimizes Garbage Collection (GC) overhead by delegating Parquet generation to Go, a fully Go-based structure is on the roadmap as iceberg-go matures.
Phase 3: Thread Coordination and the Master Process Lock
In standard distributed ingestion pipelines, multiple workers often attempt to commit to the catalog simultaneously, resulting in a CommitFailedException (and the "thundering herd" problem). OLake avoids this catalog contention entirely by utilizing a central Master Process. Because OLake streams directly from the Postgres replication slot, it pulls these high-velocity changes into an internal RAM buffer to form a micro-batch. No matter how many edge changes happen, OLake keeps buffering in memory till the point it reaches a significant file size, so preventing small file problems. Crucially, the heavy I/O operations—generating the Parquet files and flushing them to Google Cloud Storage or S3—are executed entirely in parallel by the worker threads without any locking. It is only after these parallel flushes succeed that the Master Process takes a lightning-fast internal lock (under 200ms) solely to perform the atomic metadata swap (snapshot) in the Iceberg catalog. This decoupled design sequences the commit cleanly while keeping the data generation path completely unblocked. By coordinating the threads internally, OLake eliminates the CommitFailedException loop and maintains maximum ingestion throughput.
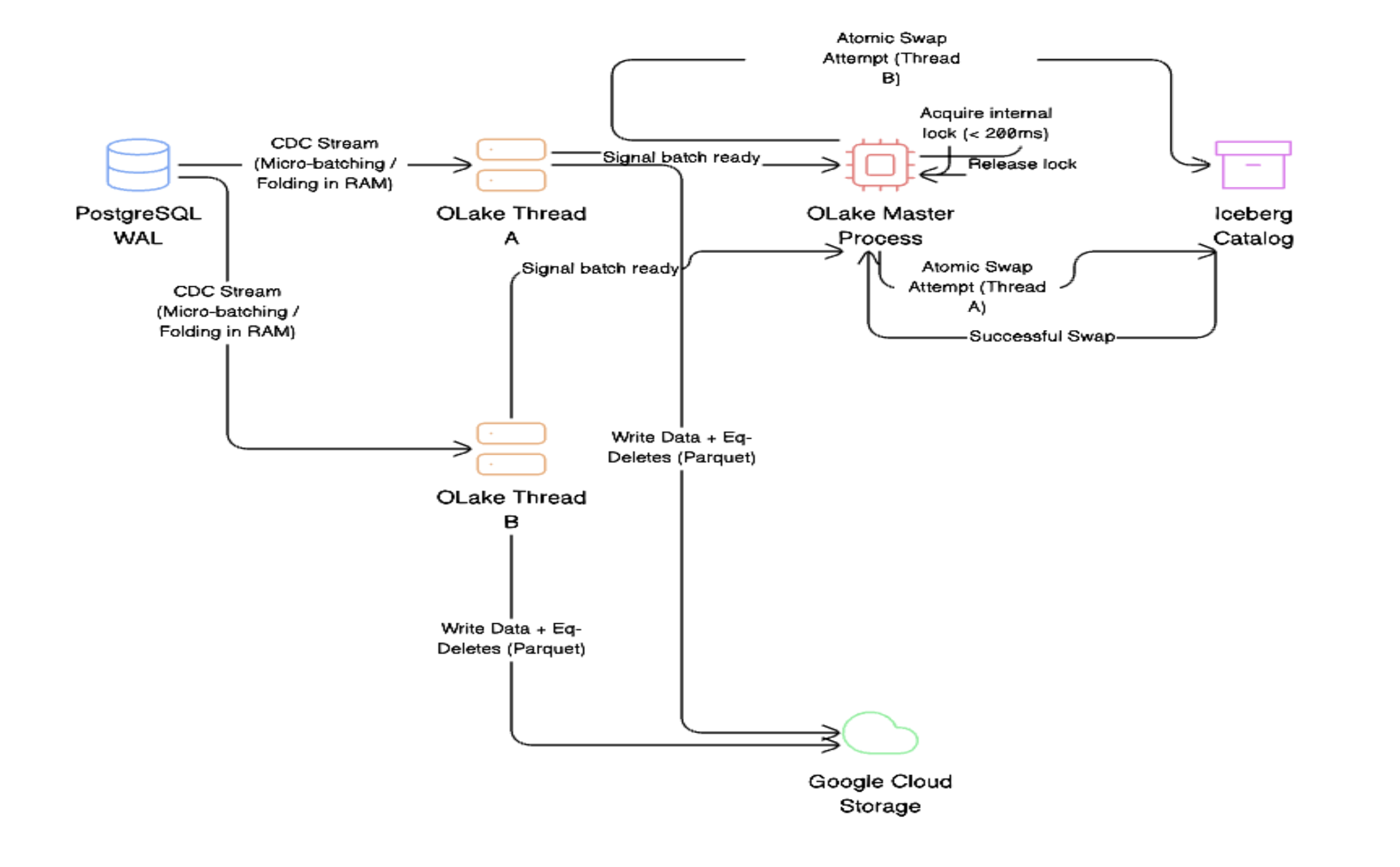
Figure 3.Resolving catalog contention through Master Process thread coordination. Instead of multiple worker threads crashing into the Iceberg catalog and causing a "thundering herd" problem, OLake centralizes the commit phase. As shown, individual worker threads process the PostgreSQL WAL stream concurrently, writing the heavy physical Parquet files directly to Cloud Storage. However, the catalog update is strictly sequenced: the Master Process acquires a lightning-fast internal lock (under 200ms) to perform the atomic swap in the Iceberg Catalog, ensuring conflict-free ingestion even under massive throughput.
Phase 4: Repaying Compaction Debt via OLake Fusion
To address the read amplification caused by Equality Deletes, OLake Fusion runs asynchronously in the background to sanitise the storage layer. It is important to note the architectural boundary here: OLake manages the compaction, ensuring the data is optimally structured for the downstream execution engines (like Trino, DuckDB, or BigQuery) that power the agentic reasoning tier.
Lite Compaction (Logical to Physical): Resolving broad Equality Deletes on the fly requires the query engine to execute expensive dynamic anti-joins in memory. Fusion converts these logical rules into specific Position Deletes, specifying the exact file paths and row offsets to skip for the query engine. Additionally, it repairs fragmentation by rolling small micro-batches into larger segments (typically close to 1/8th of the target 256MB or 512MB file size).
Medium Compaction (The Physical Purge): A separate bin-packing process reduces these segments to nearly the final target file size. It does not guarantee that after compaction data file will be of target file size.. Crucially, it physically removes the deleted rows from the Parquet blocks entirely. This restores contiguous memory layouts, allowing the query engine to scan only active data and maintain its SIMD vectorization efficiency.
Full Compaction (Global Reorganization): While Medium compaction handles localized cleanup, Full Compaction is the heavyweight background process that completely resets a partition's technical debt. Rather than relying on advanced metadata-level pruning or complex clustering, OLake focuses on raw structural efficiency. It comprehensively rewrites all base data and delete files into perfectly sized, pristine Parquet blocks. This eliminates all read-time reconciliation overhead, allowing the downstream execution engines to query pure, unfragmented data.
Architectural Warning: Merge-On-Read acts like a “computational” loan, and OLake Fusion is the repayment. If the background compaction tier lacks resources and can't keep pace with data ingestion, "delete file bloat" will accumulate. As these uncompacted files grow, the read amplification problem will resurface, leading to Time Travel queries missing their sub-second service-level agreements (SLAs). SRE teams must closely monitor the compaction queue depth to ensure the reasoning tier remains efficient.
The Reasoning Tier: Executing Temporal Queries via MCP
With perfect temporal hygiene maintained by OLake, this historical timeline can be exposed to an autonomous agent. The AI agent is equipped with an MCP tool. Upon detecting a suspicious event, it invokes the tool, passing the suspected source_ip and the exact timestamp of the anomaly.
# MCP Tool Schema
{
"name": "query_historical_network_state",
"description": "Queries the exact state of a network node at a specific millisecond in the past.",
"parameters": {
"type": "object",
"properties": {
"source_ip": { "type": "string" },
"target_timestamp": { "type": "string" }
},
"required": ["source_ip", "target_timestamp"]
}
}
Behind the MCP server, the Time Travel query runs on a vectorised engine. The type of engine used depends on the specific Agentic SLA. For embedded, serverless agents needing microsecond-level checks, a closely linked engine, such as chDB or DuckDB works best. On the other hand, for large-scale, cross-cloud incident tracing and enterprise-level reasoning, the system can easily shift to Google BigQuery as the control plane engine. It runs the same queries on the same Iceberg tables.
Vectorised engines process data in blocks of columns using CPU SIMD instructions, enabling them to scan massive datasets with sub-second latency. When the AI swarm decides to investigate, it outputs the JSON parameters. The MCP Server intercepts this request, compiles it into a parameterised SQL Time Travel query, and pushes it down to the execution engine. The Vectorized Execution Path:
-- Map the Iceberg table using native GCS integration
CREATE TABLE security_lake_edges
ENGINE = Iceberg('gcs://storage.googleapis.com/security-data-lake/network_edges', 'access_key', 'secret_key');
-- Execute the Agentic Time Travel Query
SELECT
resolved_ip,
connection_state
FROM security_lake_edges
FOR SYSTEM_TIME AS OF '2026-05-02 01:15:00.000'
WHERE source_ip = '10.0.4.55';
- Catalog Resolution: The execution engine contacts the Iceberg Catalog (e.g., Google Cloud Lakehouse) to resolve or determine the FOR SYSTEM_TIME AS OF timestamp into the correct metadata.json and active manifest.
- Direct Parquet Reads: The execution layer retrieves the specific byte ranges of the remaining Parquet files natively from GCS. Leveraging the Position Deletes generated by OLake Fusion, the engine bypasses obsolete rows with minimal compute overhead.
Architectural Tradeoffs: Tuning the Temporal Context Window
Implementing Iceberg Time Travel requires the users to balance cloud storage costs with the necessary Agentic Context Window. Aggressively expiring snapshots, such as removing history older than 2/6 hours, improves lakehouse performance. However, this also destroys the agent's temporal memory. If a security swarm needs to trace an Advanced Persistent Threat over 72 hours, an aggressive expiration policy will lead to a failed query. To support Agentic workflows, we would need to adjust the following table properties to meet the required SLA:
ALTER TABLE iceberg.security_lake.network_edges SET TBLPROPERTIES (
'history.expire.max-snapshot-age-ms'='604800000', -- Retain history for 7 days
'history.expire.min-snapshots-to-keep'='1000'
);
While retaining historical Parquet files increases storage costs, it guarantees the availability of a highly indexed, multi-day temporal memory layer.
Looking Ahead: The Decoupled Agentic Data Stack
The move toward autonomous LLM-driven agents calls for a fresh look at data engineering principles. Modern AI agents need to operate at inference speed. They cannot handle the metadata bloat or compaction lag that comes with legacy ingestion pipelines. This requirement aligns perfectly with the architectural evolution of the Google Cloud Lakehouse and the Google Cloud Next 2026 announcements. By standardising on Apache Iceberg as a zero-copy format, enterprise architecture is entirely decoupling storage from compute. In this model, Google
Cloud Storage (GCS) provides the scalable substrate, BigQuery acts as the massively parallel execution engine to crunch the historical metadata, and Vertex AI serves as the autonomous control plane reasoning over the results. However, this sophisticated cross-cloud Agentic vision is physically impossible without the right ingestion plumbing. OLake serves as critical infrastructure in this stack. By utilizing Master Process thread coordination for conflict-free snapshot generation and Fusion for asynchronous compaction, OLake shields the downstream query engines from the complexities of streaming CDC.
Stateless agents are important for heuristic blocking, whereas historical threat analysis and incident tracking require agents with stateful temporal memory. By combining OLake's accurate CDC with Apache Iceberg's built-in Time Travel, data teams will help transform object storage into a solid foundation for the next generation of autonomous enterprise defense.
Disclaimer
Opinions expressed are my own in my personal capacity and do not represent the views, policies or positions of my current and/ ex ,or their subsidiaries or affiliates