Astrotalk's Migration to Databricks: How OLake Replaced Google Datastream for Large-Scale Database Replication


1. Introduction
![]()
Astrotalk runs one of India's largest astrology platforms, serving millions of users and handling large volumes of transactional data across PostgreSQL and MySQL. As the company began shifting from Google BigQuery to a Databricks-based lakehouse, they needed a reliable way to replicate databases to S3 which is fast, stable, and fully under their control.
Their existing tools, Google Datastream and Airbyte, weren't designed for this new "Lakehouse-ready" architecture. After experimenting with several CDC systems, the team found that most solutions were either too expensive, too complex, or too operationally heavy.
OLake changed that.
2. The Challenges Before OLake
2.1 A Move Away From BigQuery Needed a New CDC Backbone
The platform's decision to move from BigQuery to Databricks meant one thing:
They needed a CDC tool that could reliably push data into S3.
They ran multiple experiments but kept hitting the same walls - cost, complexity, and infra lock-in.
2.2 Multiple Tools, Same Problems
Before choosing OLake, the team tested:
- Confluent Kafka CDC
- Fivetran
- Estuary
- Airbyte
- AWS DMS
But each came with blockers:
- Kafka / Confluent → Too much operational overhead + complex tuning required
- Airbyte → Required heavy custom config
- Fivetran / Confluent → Event-based pricing made it extremely expensive at scale
- AWS DMS → Difficult to operate and slower for large full loads
- Datastream → Not suitable once BigQuery was no longer the destination
The team needed something simpler, open, cost-efficient, and deployable in their own environment.
3. Why Astrotalk Chose OLake
Astrotalk discovered OLake through a blog post and quickly realized it matched exactly what their migration to Databricks required.
Their evaluation came down to four pillars:
3.1 Open Source + BYOC Deployment
Running OLake directly in their own infrastructure removed lock-in and gave full control over cost and scaling.
3.2 Simpler Than Every Other Tool Tested
Compared to DMS, Confluent, and others, OLake stood out because:
- Setup was straightforward
- No heavy tuning required
- Minimal operational overhead
- Easy to understand and scale
3.3 Outstanding Engineering Support
While this wasn't a formal evaluation criterion initially, it became a major reason they stayed.

3.4 Cost Model That Actually Works at Scale
The biggest advantage:
- OLake Open source is free.
- No event pricing.
- No per-table pricing.
- No SaaS lock-ins.
For a workload syncing hundreds of tables and billions of rows, this made a dramatic difference.
4. What They Built With OLake
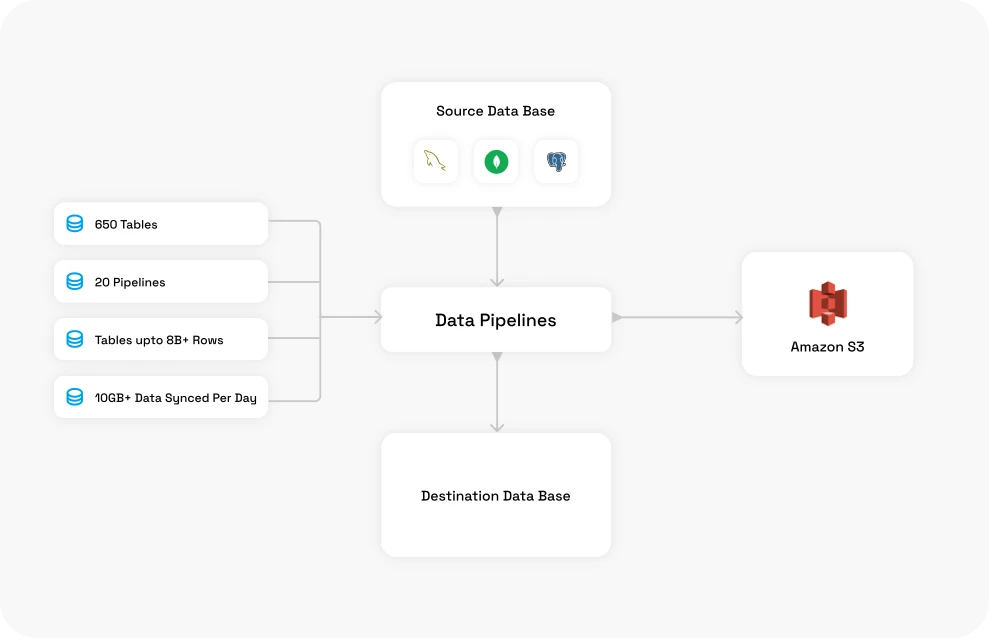
4.1 Large-Scale Postgres & MySQL Replication to S3
Today, OLake powers:
- ~650 tables replicated
- Across ~20 pipelines
- Tables up to 8B+ rows
- 10Gb+ data synced per day
Full loads and CDC both run without major issues — even on lower-spec nodes than ideal.
4.2 Foundation for Databricks Lakehouse
Once OLake started reliably delivering data to S3, Astrotalk unlocked:
- Data Lakehouse creation
- Downstream transformations
- Faster experimentation
- Better visibility into historical data
Their OLake use case is intentionally focused, but massively impactful:
Fast, reliable, lakehouse-ready database replication into S3.
5. Performance & Operational Improvements
5.1 Faster Full Loads Than AWS DMS
During testing, OLake's full loads were significantly faster than the same workloads on DMS.
(They only tested a few tables, but the difference was clear.)
5.2 Simpler Scaling Compared to Confluent & Airbyte
- Confluent required explicit performance tuning.
- Airbyte required heavy custom config.
- AWS DMS required custom table config for table mapping for particular format (parquet)
- OLake required neither.
Performance scaling was intuitive:

5.3 Replacing Google Datastream Completely
Astrotalk now relies on OLake as their primary CDC engine.
The team no longer needs Datastream at all and OLake handles workloads more efficiently inside their Databricks shift.
6. Running at Scale Without Major Issues
With hundreds of tables and multi-billion-row workloads, OLake has remained stable:
- No major failures
- No ingestion bottlenecks
- No excessive overhead
Even with lower-than-ideal compute, OLake continued to run reliably.
7. What They Want Next From OLake
Astrotalk's requests for future features include:
- Ability to full-load one table without blocking CDC on others
- More control over metadata files
- Multi-user support and audit logs
- Metrics exporter (Prometheus-compatible)
- More visibility into read counts, timing, and pipeline stats
These requests will directly shape OLake's roadmap.
8. Closing Summary
Astrotalk's migration to Databricks required a simple, reliable, cost-efficient CDC engine for S3. After testing nearly every major tool in the market, OLake became the clear winner open-source, easier to operate, and powerful enough to sync billions of rows with minimal overhead.
With OLake, Astrotalk now has:
- A fully open-source CDC layer
- ~650 tables syncing across ~20 pipelines
- Reliable full loads for tables up to 8B+ rows
- A cleaner path from databases → S3 → Databricks Lakehouse
- Lower operational cost and complexity
- A foundation for future Iceberg adoption
OLake has now fully replaced Google Datastream and is a key part of Astrotalk's modern data platform.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.