Cordial's Path to an AI-Ready Lakehouse: Large scale Multi-Cluster MongoDB Ingestion with OLake


Cordial, a leading marketing automation platform, is unifying thousands of MongoDB collections into a single Apache Iceberg based lakehouse architecture to power its next generation of AI agents.
1. Introduction

Cordial is an enterprise messaging and customer engagement platform operating at massive scale, serving global brands with real-time personalization, automation, and AI-driven experiences. The platform unifies customer behavior, product catalog data, events, and user attributes, enabling marketers to build real-time, data-driven experiences. At Cordial's scale, that means handling tens of billions of events and product updates across hundreds of customers.
As the platform matured, Cordial's data architecture needed to support a new frontier: agentic AI that can reason across customer interactions, product usage, and operational signals.
This required a single, unified data layer, something that wasn't possible while key data lived across hundreds of MongoDB clusters and thousands of individual collections. To accelerate their lakehouse journey and power their next wave of AI capabilities, Cordial adopted OLake to streamline and unify their MongoDB data into a Lakehouse.
2. Company & Challenge Overview
A distributed data model shaped by scale
Cordial made an early architectural decision that still defines their system today: each enterprise customer gets their own dedicated database within Cordial's shared MongoDB clusters. This architecture with hundreds of shared MongoDB clusters with hundreds of customer-specific databases, gives clients a high level of flexibility without forcing a rigid, multi-tenant schema.
This gives customers flexibility but creates a complex engineering challenge. The Cordial team manages:
- Hundreds of separate MongoDB clusters
- Dozens to hundreds of collections per customer
- More than 100 TB of total data
- Billions of daily events
- Almost no two customers looking the same
Some retailers follow Cordial's recommended product schema, but many don't. They create custom structures, add their own metadata tables, or send deeply nested objects. Some even drop entire product catalogs into "supplements," ad-hoc tables that can hold almost any shape of data.
For marketers, it's freedom.
For engineers, it means dealing with frequent schema changes, unpredictable document shapes, and the ongoing work of ensuring everything remains consistent and usable.

The challenge became urgent when Cordial started building for agentic AI. Their models need:
- Clean, well-structured unified tables
- Consistent column types
- Fast analytical queries
- Low-latency ingestion
- Reliable schema evolution
This model where each enterprise customer receives a dedicated database within MongoDB clusters provides strong isolation and flexibility but it also means that high-value data for AI (like products, orders, and behavioral events) becomes distributed and fragmented across the system.
The challenge: AI needs unified access, not specialized replication
Cordial already operates reliable, purpose-built replication systems that support specific product workflows.

To enable agentic AI, Cordial needed:
- A single place to read customer-, event-, and catalog-level data
- A way to synchronize thousands of MongoDB collections without custom logic
- A foundation that could scale into Iceberg-backed lakehouse architecture in the future
This set the stage for OLake.
3. Why Cordial Chose OLake
A unified ingestion layer for thousands of Mongo collections
Cordial's team wasn't just looking for a faster pipeline.
They needed something that would not increase the operational overhead, handle messy MongoDB data, and land everything cleanly in Parquets or Iceberg without asking their SRE team to run another giant system.
Their old setup, custom ingestion code had become quite rigid and every new customer schema meant more custom work. The team also looked at CDC tools and Debezium-style deployments, but it became clear very quickly:
- Most "enterprise CDC stacks" would require a full-time team just to keep them running.
- Managing Kafka, connectors, offsets, schema changes, and high-cardinality MongoDB shards simply wasn't realistic for a small engineering org.
What stood out about OLake was how simple the deployment model was. No massive cluster to run. No complicated moving parts. Just a lightweight ingestion layer built for Apache Iceberg from day one.
OLake gave Cordial a consistent, declarative way to ingest and organize data across all MongoDB sources, something existing pipelines weren't designed to do at lakehouse scale.
The value, from Cordial's point of view, was obvious:
- simple deployment instead of a multi-middleware CDC platform
- Iceberg and Parquet-native writes instead of custom ETL logic
- fewer custom scripts to maintain
- low-ops ingestion for a team that didn't have extra hands to spare
OLake's model even let them plug in their own logic to orchestrate ingestion across hundreds of Mongos routers something no commercial tool supports out of the box

On top of that, Cordial built a wrapper around OLake's CLI that automatically discovers new collections, applies mappings, and starts syncs with almost no human intervention. A process that once took hours of manual work now runs automatically.
Preparing for Apache Iceberg
Today, OLake writes CDC data to Parquet, which Cordial uses as the raw ingestion layer for their lakehouse. From there, Cordial merges these Parquet CDC logs into "latest-state" Iceberg mirror tables using DuckDB and PyIceberg.
This separation of concerns has been intentional. OLake focuses on fast, reliable ingestion across thousands of MongoDB collections, while Cordial's internal lakehouse layer handles table semantics, transformations and merges for AI workloads.
The result is a setup that already delivers Iceberg-backed, query-ready tables for AI agents today, while keeping the ingestion layer simple and stable. Looking ahead, Cordial plans to use OLake's native Iceberg write support to simplify this flow further by writing directly to Iceberg tables when it makes operational sense.
This approach gives Cordial:
- A unified lakehouse interface that AI agents and ML models can query consistently
- Iceberg mirror tables built from Parquet CDC logs, without coupling ingestion to table management
- A flexible architecture that can evolve toward deeper Iceberg adoption without rewriting ingestion pipelines
4. OLake Implementation at Cordial
4.1 Multi-Cluster MongoDB Ingestion at Scale
Cordial ingests data from hundreds of shared Mongo clusters and thousands of collections. OLake allowed them to configure and automate ingestion at this scale without bespoke per-stream engineering.
4.2 Handling Diverse Document Shapes
With flexible schemas across customer databases, fields can vary in structure or presence. OLake's transformation and normalization capabilities ensured:
- Consistent schema materialization
- Stable Parquet outputs even when document shapes differ
- Rapid onboarding of new collections without code changes
4.3 Unified Data Layer for AI Agents
This was the core value driver.
OLake made it possible to unify previously siloed datasets - products, orders, events, and more into a single data layer that AI agents can operate on.
This eliminated the historical friction of searching through multiple clusters, enabling:
- Faster feature development
- Simplified AI model access
- Standardized data interfaces
4.4 Operational Efficiency and Performance
OLake reduced end-to-end sync time dramatically from 6 hours to ~1 hour enabling fresher datasets for downstream uses without operational overhead.
4.5 Solution Architecture
Cordial's OLake-powered ingestion pipeline now looks like this:
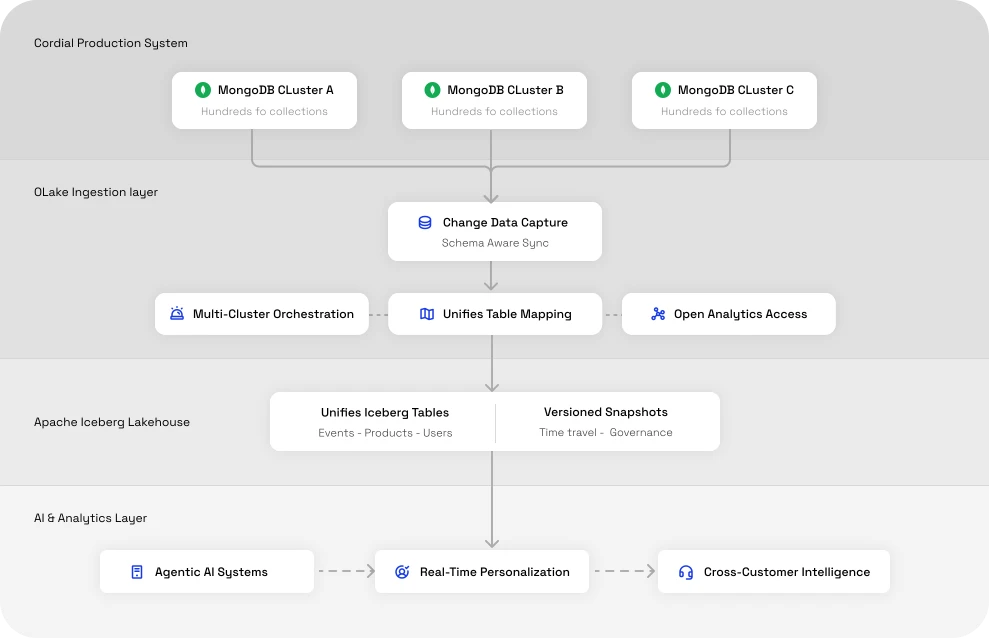
This setup enables scalable ingestion, predictable schemas, and fast queries for AI-driven personalization workflows.
5. Outcomes
✔ Unified access to thousands of Mongo collections
Cordial now has a centralized, structured data layer powering analytics and AI.
✔ A strong foundation for agentic AI
AI models and agents can now query and reason over unified datasets instead of fragmented cluster-level silos.
✔ Seamless ingestion at multi-cluster scale
OLake abstracts the complexity of onboarding new databases and collections.
✔ 6× faster end-to-end sync performance
This accelerates experiment cycles and improves data freshness for AI and ML.
✔ Near-Zero Operational Overhead
Once set up, OLake just works. There's no babysitting, repeated manual mappings, or reconfiguration when clusters change
6. What's Next
Cordial plans to continue expanding its unified data layer, unlocking new AI-driven use cases across personalization, automation, and operational intelligence. With OLake as the ingestion backbone, they're well-positioned for a shift from Parquet-based lakes to a full Iceberg lakehouse in the future.
Closing Summary
By adopting OLake, Cordial transformed a rigid ingestion process into a unified, automated, low-ops data foundation. The benefits are clear:
- 6x faster sync cycles
- Automated multi-cluster ingestion
- A smooth path to Iceberg
- Lower-compute, AI-ready architecture
As their data grows from hundreds of terabytes toward a petabyte, OLake is helping Cordial build a platform that is scalable, reliable, and ready for real-time personalization and AI workloads. Together, they are shaping the next generation of data ingestion for modern marketing.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.