Deploy OLake on Kubernetes Helm - Fast, Scalable Data Pipelines


It is often said that setting up a robust data replication pipeline can be a headache. Custom deployment scripts are often wrestled with, disparate components must be managed, and concerns arise about what happens when failures inevitably occur. Data teams are kept waiting while time is spent on plumbing instead of enabling.
What if a complete, production-ready data replication platform could be deployed on Kubernetes with a single command? What if it was built from the ground up to be scalable, observable, and secure?
That’s exactly why the new official Helm chart for OLake was built. It is more than just an installer; it is a fast track to a powerful data pipeline, where data is moved from database sources to a data lakehouse in Apache Iceberg or Parquet.
This is not just a guide. It is a journey. A process to achieve a fully operational pipeline will now be demonstrated.
The OLake Helm Chart Architecture
To ensure every data pipeline runs like a well-oiled machine, a complete and observable replication stack is deployed by the Helm chart. The architecture was designed around the core principles of resilience and a clean separation of duties. By this modular design, a stable foundation is provided, where each part knows its job and does it well.
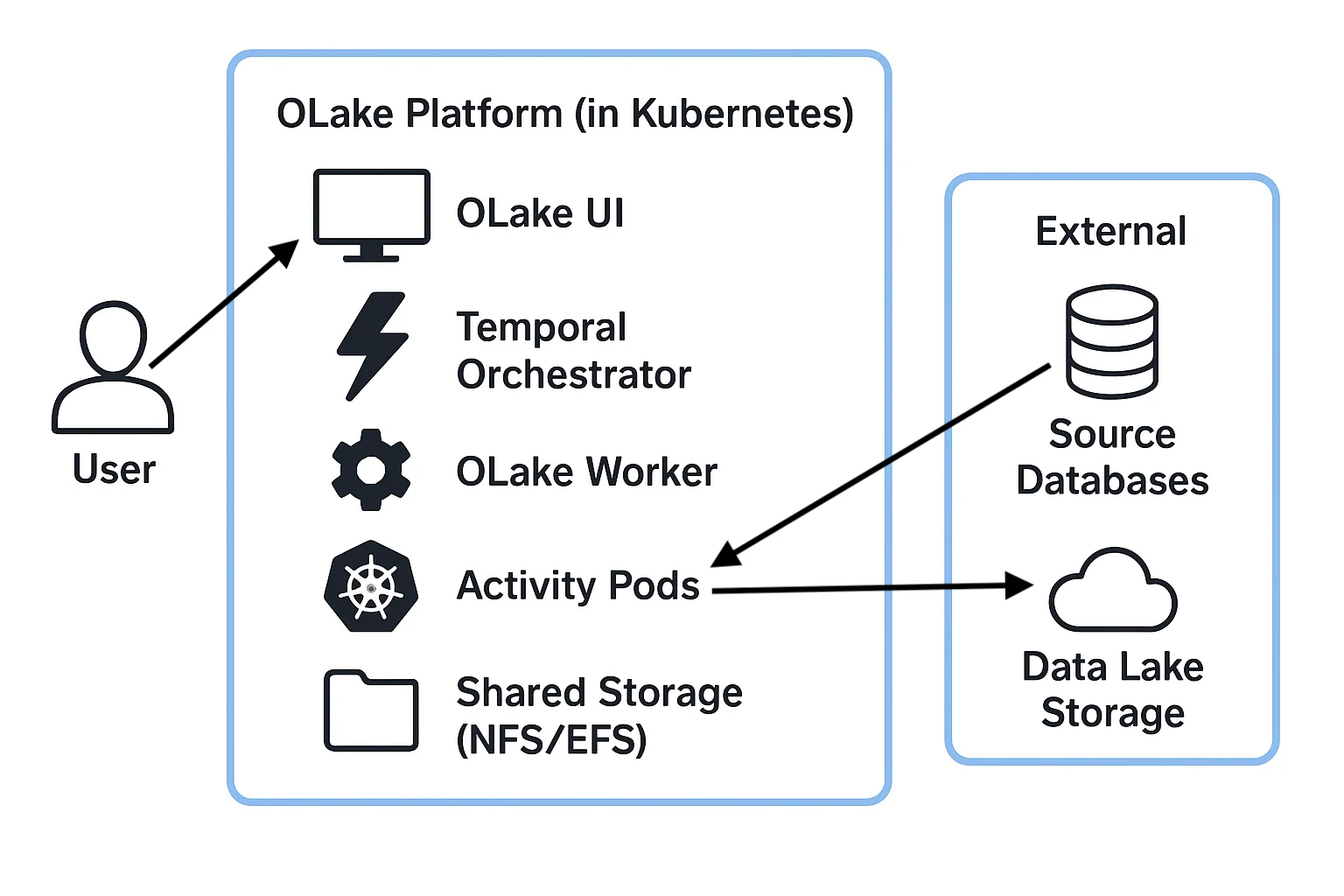
What You Get with the Helm Chart
Six key services are deployed by the chart, which work in concert:
- OLake UI: The central command center. It's the web interface and backend API for setting up connectors, managing data pipelines, and monitoring sync progress.
- OLake Worker: The engine of the platform. This Kubernetes-native worker listens for tasks from the orchestrator and dynamically creates Kubernetes pods to execute data synchronization, schema discovery, and connection testing.
- Temporal: The heart of the operation. Temporal is a powerful workflow orchestrator that manages the entire data pipeline lifecycle, guaranteeing reliable execution with built-in retries and state management.
- PostgreSQL: The persistence layer. It stores all OLake application data (sync state, job configurations, etc.) and the state of Temporal workflows, ensuring no data is lost.
- Elasticsearch: The visibility layer. It's integrated with Temporal to provide advanced search and observability into workflow executions, making it easy to debug and monitor your jobs.
- Shared Storage: A persistent volume is required for coordination between the UI and the dynamic worker pods. For a quickstart, a development-grade NFS server can be deployed by the chart. For production, a custom ReadWriteMany storage solution can be easily integrated.
The Mission: A Live Pipeline in 5 Minutes
First, the power of OLake can be demonstrated with a quick development setup. The goal is for the entire platform to be running in the cluster in the next few minutes.
Prerequisites
- Kubernetes 1.19+ & Helm 3.2.0+
kubectlconfigured to the cluster- A default
StorageClassdefined in the cluster
Step 1: Add the OLake Helm Repo
The Helm client must be informed of where the chart can be found:
helm repo add datazip https://datazip-inc.github.io/olake
helm repo update
Step 2: Deploy OLake Helm Chart!
Now for the magic, this one command should be run:
helm install olake olake/olake
With this command, the entire OLake stack is deployed: the UI, the Temporal orchestrator, the OLake workers, and the necessary PostgreSQL and Elasticsearch databases. For this quick start, even a simple NFS server for shared storage is provisioned.
The components can be watched as they come to life:
kubectl get pods
NAME READY STATUS RESTARTS AGE
elasticsearch-efgh 1/1 Running 0 2m
olake-nfs-server-mnop 1/1 Running 0 2m
postgresql-pqrst 1/1 Running 0 2m
temporal-7b7c8f9f68-abcde 1/1 Running 0 2m
olake-ui-5f5d6b7b89-fghij 1/1 Running 0 2m
olake-worker-6c6b7d8d90-klmno 1/1 Running 0 2m
Step 3: Log Into the System
The platform is now running. To access the OLake UI, the port can be forwarded from the service to a local machine or accessed via domain in case setup using Ingress:
kubectl port-forward svc/olake-ui 8080:8080 8000:8000
A browser can be opened to http://localhost:8000, and login with admin / password to create a job. In just a few minutes, a complete data replication platform has been deployed.
Under the Hood: The Design Philosophy by Which OLake is Powered
Now that the platform has been seen in action, some of the key design decisions that make OLake both easy to use and powerful enough for production will be explored.
More Than Just Storage: The Role of the Shared Volume in Pipeline Coordination
When OLake was first deployed, an NFS server was automatically provisioned. This is not just about storage—it's the coordination backbone by which the entire pipeline is made to work seamlessly.
It can be thought of in this way: job configurations need to be handed off from the OLake UI to workers, discovered schemas must be passed from workers to sync processes, and state needs to be coordinated by everyone. Without shared storage, these components would be like orchestra musicians attempting to play together while situated in different buildings.
The deployed NFS volume acts as this coordination layer. When a new data source is configured in the UI, that configuration is written to the shared volume. When a worker pod is spun up to discover the database schema, that same location is read from, and what is found is written back. It is a simple but powerful pattern by which everything is kept in sync.
For a quick start, this has been made invisible—the built-in NFS server just works. But a key point must be understood: while the self-managed NFS is perfect for development and testing, production workloads deserve better.
In production, the cloud provider's managed storage services should be leveraged. The durability, performance, and availability guarantees that are depended on by data pipelines are provided by these services. AWS EFS, Azure Files, and Google Cloud Filestore are all battle-tested, managed solutions that scale with needs and come with built-in redundancy.
The way OLake would be configured to use AWS EFS in production is shown here:
# values.yaml
nfsServer:
enabled: false # Disable our built-in NFS server
# Use your existing EFS persistent volume claim instead
external:
name: "my-efs-pvc"
The same pattern works for Azure Files or Google Cloud Filestore—the managed storage is pointed to, and the rest is handled by OLake. Enterprise-grade storage reliability is thus provided to the pipelines while the same simple operational model is kept.
This shared storage design doesn't just solve coordination—powerful operational capabilities are also enabled. If a failed pipeline needs to be debugged, the logs and state files are located right there in the shared volume. If a migration of the OLake deployment to a new cluster is desired, the entire pipeline state is moved with the storage. It is resilience through simplicity.
Escaping the 'Noisy Neighbor' Problem in Your Data Pipelines
This scenario has been lived through by every data engineer: multiple heavy data sync operations are run simultaneously, and all are found on the same Kubernetes node, where CPU, memory, and I/O are fought for. The result is slower performance across the board and unpredictable completion times.
This is known as the "noisy neighbor" problem, where resource-intensive workloads are impacted by each other when forced to share the same infrastructure. In traditional data pipeline setups, performance bottlenecks and unreliable sync times are the result, especially when large datasets are being processed.
This problem is solved intelligently by OLake for the operations that matter most: heavy data sync workloads.
When pods are created by OLake for sync operations, podAntiAffinity rules are automatically applied, by which these resource-intensive tasks are spread across different nodes in the cluster. It can be thought of as an intelligent traffic controller by which the heaviest data processing jobs are ensured not to interfere with each other.
What this means in practice:
- Consistent Sync Performance: Dedicated node resources are given to large table syncs, so completion is achieved in predictable timeframes without competition for CPU and memory with other sync operations.
- Improved Reliability: A single node is prevented from becoming a bottleneck, so the risk of memory pressure or CPU saturation that could cause sync operations to fail or timeout is reduced.
For lightweight operations like discovery and testing, a different approach is taken by OLake—these quick, low-resource operations can be run anywhere without the need for special scheduling constraints. The system is thus kept efficient while the sophisticated scheduling logic is focused where the most value is provided.
The result is a data pipeline architecture by which performance is automatically optimized, ensuring the most critical sync operations are given the resources needed to succeed.
Precision Scheduling: A Guide to JobID-Based Node Mapping
Now that the handling of resource isolation by OLake is understood, the topic of precision can be addressed. Not all data operations are created equal—some require massive memory for processing large datasets, others benefit from high-CPU nodes for complex normalizations, and some can be run perfectly fine on cost-effective general-purpose instances.
In traditional Kubernetes scheduling, all pods are treated in the same way, being spread randomly across available nodes. But what if a strategic approach could be taken regarding where different types of data work are actually run?
That is exactly what is delivered by OLake's JobID-based node mapping: the power for specific sync operations to be routed to the exact infrastructure that is needed for them to perform at their best.
How It Works
The concept is elegantly simple. A JobID is given to every data job in OLake—it can be thought of as a unique fingerprint for that particular operation. Through the Helm configuration, a mapping is created that tells OLake: "When JobID X is seen, it should be scheduled on nodes with these specific labels."
# values-production.yaml
global:
jobMapping:
# Heavy PostgreSQL sync is routed to memory-optimized nodes
123:
olake.io/workload-type: "memory-optimized"
456:
olake.io/workload-type: "general-purpose"
# Default scheduling behaviour
789: {}
Real-World Impact
A typical enterprise scenario can be considered: a massive customer transactions table (JobID 123) that needs 32GB of memory to be processed efficiently is being synced, while another lightweight sync is simultaneously being run across dozens of smaller tables (JobID 456).
Without node mapping, both operations might be scheduled on the same node by Kubernetes, causing memory contention. Or worse, the memory-hungry sync job might be put on a small node where an out-of-memory error would cause it to fail.
With JobID-based mapping, the heavy sync is necessarily landed on a node with label olake.io/workload-type: "memory-optimized" where completion is achieved in 30 minutes instead of timing out. The other sync job are run happily on smaller, cheaper nodes, finishing without waste.
The Progressive Advantage
What makes this approach brilliant is that it is completely optional and grows with needs. A simple start can be made—everything can be run anywhere using default Kubernetes scheduling. As data volumes grow and performance patterns are identified, mappings can be added only for the jobs that benefit.
For new systems, no mappings are required. For growing enterprises with complex workloads, the heaviest jobs can be mapped to dedicated node pools.
Configuration That Just Works
The beauty lies in the simplicity. A few lines are added to the Helm values, a redeployment is done, and jobs are automatically started to be routed by OLake according to the rules. No code changes, no complex rewrites, no architectural overhauls are needed. The intelligence is built into the platform.
This is precision scheduling in action: the right job, on the right infrastructure, at the right time.
The Engine of Scale: Reliably Orchestrating Dozens of Concurrent Data Pipelines
It is Monday morning, and 20 different sync jobs have been scheduled to be run simultaneously. Customer data from PostgreSQL, product catalogs from MongoDB, transaction logs from MySQL—all are flowing into the data lake at the same time. In a traditional setup, this would be a recipe for chaos. Jobs would interfere with each other, failed workflows would disappear into the void, and everything would be restarted manually while coffee gets cold.
This complexity is handled by OLake through two powerful components working in perfect harmony: Temporal for rock-solid orchestration and OLake Workers for intelligent concurrency management.
Temporal: The Reliability Safety Net
When a data sync is kicked off in OLake, it is not just "run" by Temporal—a durable, recoverable workflow is created that persists through failure. If a sync crashes, it is remembered by Temporal where each job was, and a resumption from that exact point is performed on the next schedule of the job.
But what makes Temporal truly powerful for data pipelines is that complete visibility is provided into what is happening. Every step, every retry, every decision point is tracked. If it is needed to know why a sync job failed three days ago, the full execution history is right there on the OLake UI.
The Magic of Dynamic Pod Creation
The architecture is made particularly smart at this point. When a data operation needs to be executed by a workflow—say, for schema discovery from a PostgreSQL database—that operation is not run within the OLake Worker itself. Instead, a dedicated Kubernetes pod is created specifically for that task.
This means dozens of operations can be coordinated simultaneously by the worker while each actual data processing task is run in its own isolated environment with dedicated resources. It is like a smart dispatcher managing a fleet of specialized vehicles, with each one being optimized for its specific job.
Data, Handled Your Way, Without Excuses
The OLake Helm chart is more than a tool; it's a statement. It is believed that enterprise-grade data replication should be accessible to everyone. It should be easy to deploy, secure by default, and powerful enough for growth. By handling the deployment complexity, focus can be placed on what truly matters: the data.
Happy replicating!
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.