7× Faster Iceberg Writes: How We Rebuilt OLake's Destination Pipeline


Overview
Data ingestion performance is critical when you are writing in Iceberg format to data lake. When your pipeline becomes a bottleneck, it affects everything downstream—from real-time analytics to machine learning workflows. We started with OneStack in Datazip to solve the problem of Data Analytics, but then we were bound to see the problem on Data Ingestion itself. To solve this problem for iceberg native writes we built OLake. At first we created basic Iceberg writer, but then we saw the issues with it (I will be writing about the issues in a new section). Today we have resolved all those bottlenecks.
The result? A 7× performance improvement in Apache Iceberg, without the complexity of background deduplication jobs or eventual consistency mechanisms.
In this blog I am going to explain how we achieved this, so let us start. If you are just interested in what boosted performance, read the section What We Changed. If you are interested in previous code base you can check https://github.com/datazip-inc/olake/tree/v0.1.11
Issues with Previous Iceberg Writer
If you've worked with JVM-based data processing systems, you're probably familiar with the heavy memory usage and JSON schema evolution problems. These are well-known challenges, but when you're building a production system, they become real bottlenecks.
Let me share the specific issues we encountered that were creating bottlenecks and preventing us from extending our codebase with new features. You might recognize some of these in your own systems:
-
RPC Server Format: In previous implementation we were using Debezium Formats to communicate between OLake and Java Iceberg server, which had large metadata that was mostly unused.
-
Serialization And Deserialization using JsonSchema: At multiple places serialization and deserialization were happening, resulting in less throughput, high memory and CPU consumption.
-
Inconsistent and Small File Size: In previous implementation we were flushing buffers on reaching a specific memory threshold, which was resulting in inconsistent and small file sizes after compression.
-
Heavy Processing On Java Side: Most of the processing like schema discovery, conversions, and concurrency management was happening on the Java side, so JVM overhead was again the problem, making it a bottleneck for new features like DLQ etc.
-
Partition Writer: The partition writer that was previously being used was closing files whenever a different partition record came.
-
Data Buffers: We were using two buffers to maintain batches of data, which again pushed large batches to the Java server.
Fundamentals of Iceberg Distributed Writers
After identifying these issues, the first step was understanding Iceberg's distributed writing model. You might be thinking, "Iceberg sounds complex, is this going to be hard to understand?" Don't worry—while it might seem complex at first, the core concepts are straightforward once you understand the fundamentals.
Here's what you need to know:
-
ACID properties matter: Remember learning about ACID in databases? Legacy data lakes lacked these guarantees, making concurrent writes and schema changes tricky. Iceberg brings ACID to data lakes, and atomicity is key—either all your data commits successfully, or none of it does.
-
Retrying has limits: You might have heard the Iceberg community suggest retrying failed commits, but this advice has limitations. If your data is fundamentally incompatible with the schema (like inserting a string into an integer column), retrying won't help—think of it as trying to put a square peg in a round hole.
-
Not for real-time streaming: Iceberg is not designed for real-time streaming use cases (until the small file problem is solved). Even tools like Tableflow batch data before writing to Iceberg. If you need sub-second latency, you'll need to look elsewhere—at least for now.
-
Schema changes require new writers: If you've worked with Parquet, you know that schema changes require closing the previous file and using a new one. The same applies to Iceberg writers—each writer accommodates its own schema, and you can only push data matching that schema to that particular writer.

So, here we have four things:
- Write and commit data files atomically
- Iceberg is for batch use cases
- Don't retry if you are fundamentally wrong
- Close writers based on schema changes.
Besides this, we must know something about type promotions that are possible in Iceberg. We can evolve from int to bigint and float to double. For others, you can refer to this doc: https://iceberg.apache.org/docs/latest/schemas/.
OLake New Iceberg Writer: What We Changed To Make It Fast
So, how did we achieve this 7× improvement? The refactor fundamentally changes how we handle data processing by splitting responsibilities between Go and Java components based on their respective strengths. Think of it like a restaurant: you have chefs (Go) who prepare the ingredients quickly—handling all the prep work, ingredient selection, and coordination—and waiters (Java) who serve the food. This separation of concerns allows each component to focus on what it does best while maintaining clean interfaces between them.
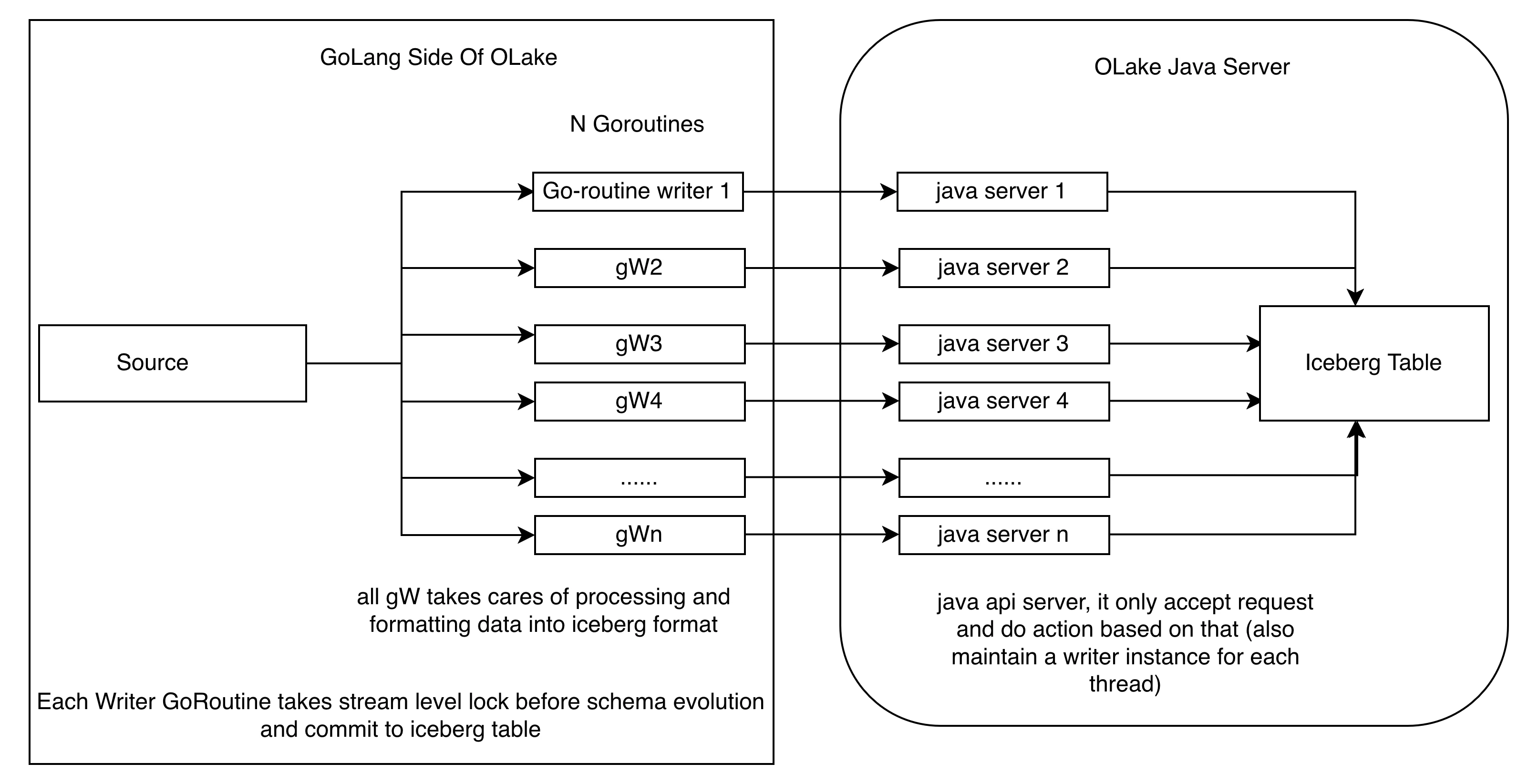
We established several design principles before proceeding with the refactoring:
- Golang for processing: Golang excels at fast data processing and concurrency management, making it ideal for our processing layer.
- Java for Iceberg I/O: The Java Iceberg library is the most mature implementation, with new features arriving in Java first.
- Minimal batching: We minimize batching overhead and write data directly to Parquet format.
- Java as API layer: The Java Iceberg server acts as a focused API layer for writing data in Iceberg format.
This refactored architecture enables each component to operate at peak efficiency while maintaining the strong consistency guarantees required for production data pipelines.
Before we dive deeper, let me clarify some terms you'll see throughout this blog. If you're already familiar with these, feel free to skip ahead:
Schema Evolution
Schema evolution refers to updating the table schema when new columns are added or when existing columns change types. Picture this: your source table adds a new email column, or a column type changes from int to bigint. The Iceberg table schema needs to evolve to accommodate these changes and it needs to do this without breaking existing queries or losing data.
Normalization
Normalization is the process of extracting columns from incoming records and transforming them to match the target table's schema. It's like unpacking a nested box and organizing the contents into a flat structure.
Here are the optimizations that we have done:
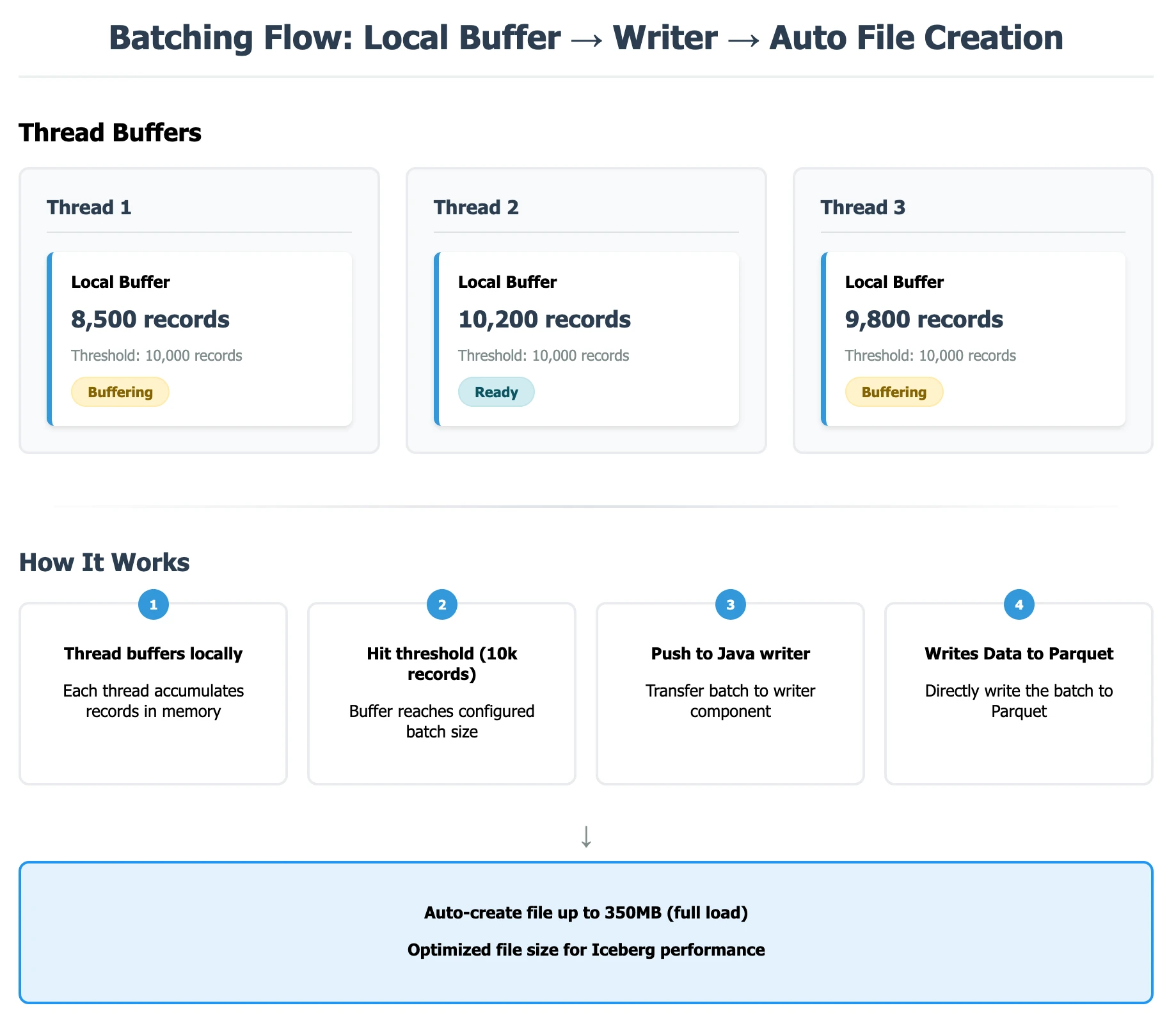
1. Removal of Large Data Buffers
Remember those two buffers I mentioned earlier? In the previous implementation, we had one buffer for each local thread that would push to a global table buffer after reaching a certain memory limit, which then pushed data to the Java Iceberg server to write to files. This double buffering approach added unnecessary overhead.
In our new writer implementation, we simplified this to just one buffer with a 10k batch size (which you can configure based on your needs). This leads to less memory footprint and higher throughput. Here's the key improvement: our writer now commits only after finishing a full chunk of 4GB (In historical snapshot), which compresses down to about 350 MB. This means fewer, larger files instead of many small ones—which is exactly what you want for query performance.
How New Batching works:
In the image below you can see how the current batching works.
-
Local thread batch: Each writer thread buffers records in-memory up to a per-thread threshold (typically 10,000 records). This local buffering allows for efficient in-memory processing and schema detection before sending data over the network.
-
Java writer: After the local batch crosses a threshold, we send a compact, typed payload (via gRpc) to the Java Iceberg writer. This payload is optimized for Iceberg operations and eliminates unnecessary json serialization/deserialization overhead. The Java writer automatically closes files and pushes them to storage once the target file size is reached.
-
Data visibility after commit: Files are created and data is written, but it only becomes visible in the Iceberg table after an explicit commit operation. This ensures atomic visibility and maintains exactly-once semantics.
2. Atomic Commits And Schema Evolution
As we discussed in the fundamentals, we require atomic data updates in Iceberg table, so here is how we are doing it in the new Iceberg writer:
1. Committing Data Files
Initially, all batches are sent to the Java server and converted into Parquet files. The Java writer internally stores these files and pushes them to the configured object store (such as S3 or Azure Blob Storage). However, these files are not yet registered in the Iceberg table, they need to be explicitly committed to become visible.
While registering them, we take a table level lock on the Go side and commit all data and delete files if any.
You might be wondering: "Why not take a lock while writing files? Won't that cause conflicts?" Great question! Here's the key insight: each writer maintains its own data file, and we create writers equal to the number of threads we've opened. So there's no write happening in the same file with two different writers, each thread has its own file, eliminating the need for file level locking during writes.
Below is the commit logic which is on the Java side:
IcebergTableOperator.java
// destination/iceberg/olake-iceberg-java-writer/src/main/java/io/debezium/server/iceberg/tableoperator/IcebergTableOperator.java
public void commitThread(String threadId, Table table) {
if (table == null) {
LOGGER.warn("No table found for thread: {}", threadId);
return;
}
try {
completeWriter(); // Collect data and delete files
int totalDataFiles = dataFiles.size();
int totalDeleteFiles = deleteFiles.size();
LOGGER.info("Committing {} data files and {} delete files for thread: {}",
totalDataFiles, totalDeleteFiles, threadId);
if (totalDataFiles == 0 && totalDeleteFiles == 0) {
LOGGER.info("No files to commit for thread: {}", threadId);
return;
}
// Refresh table before committing (critical for correctness)
table.refresh();
boolean hasDeleteFiles = totalDeleteFiles > 0;
if (hasDeleteFiles) {
// Upsert mode: use RowDelta for atomic upsert with equality deletes
RowDelta rowDelta = table.newRowDelta();
dataFiles.forEach(rowDelta::addRows);
deleteFiles.forEach(rowDelta::addDeletes);
rowDelta.commit(); // ← ATOMIC
} else {
// Append mode: pure append
AppendFiles appendFiles = table.newAppend();
dataFiles.forEach(appendFiles::appendFile);
appendFiles.commit(); // ← ATOMIC
}
LOGGER.info("Successfully committed {} data files and {} delete files for thread: {}",
totalDataFiles, totalDeleteFiles, threadId);
} catch (Exception e) {
String errorMsg = String.format("Failed to commit data for thread %s: %s", threadId, e.getMessage());
LOGGER.error(errorMsg, e);
throw new RuntimeException(errorMsg, e);
}
}
Key insight: The commit is atomic. Either the entire batch becomes visible in the Iceberg table, or nothing does, there's no partial state. This atomicity is crucial because it means readers will never see inconsistent intermediate states, even during concurrent operations. For example, if you're committing 1000 records and the commit fails halfway through, none of those records will be visible in the table.
The commit process handles two scenarios:
- Append mode: For pure inserts (like backfill operations or initial data loads), we use
AppendFileswhich simply adds new data files to the table. This is the simplest and fastest mode. - Upsert mode: For CDC operations with updates/deletes, we use
RowDelta(Equality delete MOR Iceberg) which atomically adds both data files and delete files, enabling Iceberg's native upsert semantics. For example, if a record is updated, we write the new version to a data file and mark the old version for deletion in a delete file—all in a single atomic operation.
2. Atomic Schema Evolution
Now we know how files are being committed atomically, but you might be asking: "What about schema changes? How does OLake handle type promotions and schema evolution in Iceberg tables?"
For schema evolution, we reuse the same global table atomic lock, which ensures that for any particular table, only one thread evolves the schema at a time. This prevents race conditions and ensures consistency.

But here's an interesting challenge: how do other threads know if the schema has changed? This is where our schema coordination comes in. We maintain a schema for each thread as well as a global schema on the Golang side. When any thread updates the schema, we update both the global schema and that thread's Go-side schema. Each thread periodically checks the global schema; if there's any difference, it updates both its Java-side writer and Go-side writer. This way, all Go-side threads stay aware of what schema is actually being written and what should be committed.
We implemented one optimization: if there are type promotions (for example, from int to long), we don't close or refresh the writer until a record with a greater type (e.g. long) arrives in that batch. This saves the overhead of refreshing and closing files unnecessarily.
Here's how atomic schema evolution happens:

- Thread level detection: Each thread compares its local schema with the global table schema
- Lock acquisition: Only threads detecting schema changes acquire the table level lock
- Schema evolution: The first thread to acquire the lock performs the actual schema evolution
- Writer refresh: All threads refresh their writers to use the new schema
iceberg.go
// compares with global schema and update schema in destination accordingly
func (i *Iceberg) EvolveSchema(ctx context.Context, globalSchema, recordsRawSchema any) (any, error) {
if !i.stream.NormalizationEnabled() {
return i.schema, nil
}
// cases as local thread schema has detected changes w.r.t. batch records schema
// i. iceberg table already have changes (i.e. no difference with global schema), in this case
// only refresh table in iceberg for this thread.
// ii. Schema difference is detected w.r.t. iceberg table (i.e. global schema), in this case
// we need to evolve schema in iceberg table
// NOTE: All the above cases will also complete current writer (java writer instance) as schema change in thread detected
globalSchemaMap, ok := globalSchema.(map[string]string)
if !ok {
return nil, fmt.Errorf("failed to convert globalSchema of type[%T] to map[string]string", globalSchema)
}
recordsSchema, ok := recordsRawSchema.(map[string]string)
if !ok {
return nil, fmt.Errorf("failed to convert newSchemaMap of type[%T] to map[string]string", recordsRawSchema)
}
// case handled:
// 1. returns true if promotion is possible or new column is added
// 2. in case of int(globalType) and string(threadType) it return false
// and write method will try to parse the string (write will fail if not parsable)
differentSchema := func(oldSchema, newSchema map[string]string) bool {
for fieldName, newType := range newSchema {
if oldType, exists := oldSchema[fieldName]; !exists {
return true
} else if promotionRequired(oldType, newType) {
return true
}
}
return false
}
// check for identifier fields setting
identifierField := utils.Ternary(i.config.NoIdentifierFields, "", constants.OlakeID).(string)
request := proto.IcebergPayload{
Type: proto.IcebergPayload_EVOLVE_SCHEMA,
Metadata: &proto.IcebergPayload_Metadata{
IdentifierField: &identifierField,
DestTableName: i.stream.GetDestinationTable(),
ThreadId: i.server.serverID,
},
}
var response string
var err error
// check if table schema is different from global schema
if differentSchema(globalSchemaMap, recordsSchema) {
logger.Infof("Thread[%s]: evolving schema in iceberg table", i.options.ThreadID)
for field, fieldType := range recordsSchema {
request.Metadata.Schema = append(request.Metadata.Schema, &proto.IcebergPayload_SchemaField{
Key: field,
IceType: fieldType,
})
}
response, err = i.server.sendClientRequest(ctx, &request)
if err != nil {
return false, fmt.Errorf("failed to evolve schema: %s", err)
}
} else {
logger.Debugf("Thread[%s]: refreshing table schema", i.options.ThreadID)
request.Type = proto.IcebergPayload_REFRESH_TABLE_SCHEMA
response, err = i.server.sendClientRequest(ctx, &request)
if err != nil {
return false, fmt.Errorf("failed to refresh schema: %s", err)
}
}
// only refresh table schema
schemaAfterEvolution, err := parseSchema(response)
if err != nil {
return nil, fmt.Errorf("failed to parse schema from resp[%s]: %s", response, err)
}
i.schema = copySchema(schemaAfterEvolution)
return schemaAfterEvolution, nil
}
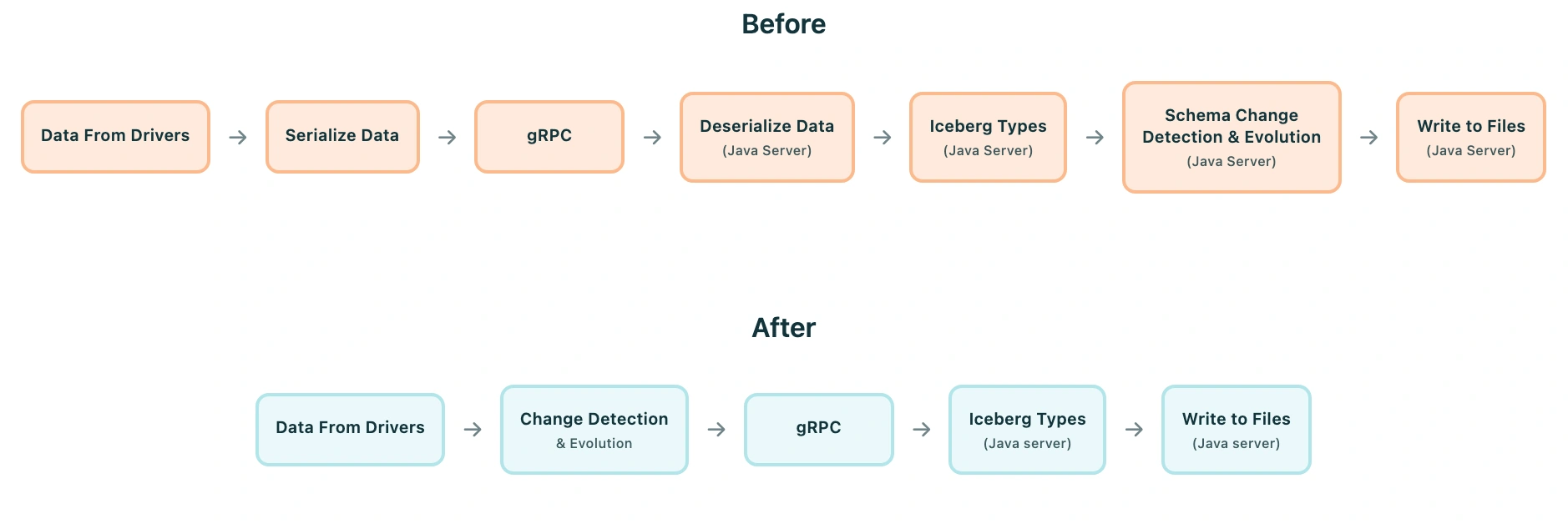
3. Removal of JSON Overhead And Type Detection
In previous implementation, Java JSON library used to load data, detect its type and then its conversion. But in new implementation we have removed the whole JSON overhead—now we are using RPC internal type definitions to pass data to Iceberg server. This makes it easier, with no conversion overhead and less RPC call metadata size.
Below is the code where we have done it:
iceberg.go
for _, field := range protoSchema {
val, exist := record.Data[field.Key]
if !exist {
protoColumnsValue = append(protoColumnsValue, nil)
continue
}
switch field.IceType {
case "boolean":
boolValue, err := typeutils.ReformatBool(val)
if err != nil {
return fmt.Errorf("failed to reformat rawValue[%v] as bool value: %s", val, err)
}
protoColumnsValue = append(protoColumnsValue, &proto.IcebergPayload_IceRecord_FieldValue{Value: &proto.IcebergPayload_IceRecord_FieldValue_BoolValue{BoolValue: boolValue}})
case "int":
intValue, err := typeutils.ReformatInt32(val)
if err != nil {
return fmt.Errorf("failed to reformat rawValue[%v] of type[%T] as int32 value: %s", val, val, err)
}
protoColumnsValue = append(protoColumnsValue, &proto.IcebergPayload_IceRecord_FieldValue{Value: &proto.IcebergPayload_IceRecord_FieldValue_IntValue{IntValue: intValue}})
case "long":
longValue, err := typeutils.ReformatInt64(val)
if err != nil {
return fmt.Errorf("failed to reformat rawValue[%v] of type[%T] as long value: %s", val, val, err)
}
protoColumnsValue = append(protoColumnsValue, &proto.IcebergPayload_IceRecord_FieldValue{Value: &proto.IcebergPayload_IceRecord_FieldValue_LongValue{LongValue: longValue}})
case "float":
floatValue, err := typeutils.ReformatFloat32(val)
if err != nil {
return fmt.Errorf("failed to reformat rawValue[%v] of type[%T] as float32 value: %s", val, val, err)
}
protoColumnsValue = append(protoColumnsValue, &proto.IcebergPayload_IceRecord_FieldValue{Value: &proto.IcebergPayload_IceRecord_FieldValue_FloatValue{FloatValue: floatValue}})
case "double":
doubleValue, err := typeutils.ReformatFloat64(val)
if err != nil {
return fmt.Errorf("failed to reformat rawValue[%v] of type[%T] as float64 value: %s", val, val, err)
}
protoColumnsValue = append(protoColumnsValue, &proto.IcebergPayload_IceRecord_FieldValue{Value: &proto.IcebergPayload_IceRecord_FieldValue_DoubleValue{DoubleValue: doubleValue}})
case "timestamptz":
timeValue, err := typeutils.ReformatDate(val)
if err != nil {
return fmt.Errorf("failed to reformat rawValue[%v] of type[%T] as time value: %s", val, val, err)
}
protoColumnsValue = append(protoColumnsValue, &proto.IcebergPayload_IceRecord_FieldValue{Value: &proto.IcebergPayload_IceRecord_FieldValue_LongValue{LongValue: timeValue.UnixMilli()}})
default:
protoColumnsValue = append(protoColumnsValue, &proto.IcebergPayload_IceRecord_FieldValue{Value: &proto.IcebergPayload_IceRecord_FieldValue_StringValue{StringValue: fmt.Sprintf("%v", val)}})
}
}
Here's the gRPC contract definition:
record_ingest.proto
// destination/iceberg/olake-iceberg-java-writer/src/main/resources/record_ingest.proto
syntax = "proto3";
package io.debezium.server.iceberg.rpc;
service RecordIngestService {
rpc SendRecords(IcebergPayload) returns (RecordIngestResponse);
}
message IcebergPayload {
enum PayloadType {
RECORDS = 0;
COMMIT = 1;
EVOLVE_SCHEMA = 2;
DROP_TABLE = 3;
GET_OR_CREATE_TABLE = 4;
REFRESH_TABLE_SCHEMA = 5;
}
PayloadType type = 1;
message Metadata {
string dest_table_name = 1;
string thread_id = 2;
optional string identifier_field = 3;
repeated SchemaField schema = 4;
}
message SchemaField {
string ice_type = 1;
string key = 2;
}
// Typed fields for efficiency (not generic Value maps)
message IceRecord {
message FieldValue {
oneof value {
string string_value = 1;
int32 int_value = 2;
int64 long_value = 3;
float float_value = 4;
double double_value = 5;
bool bool_value = 6;
bytes bytes_value = 7;
}
}
repeated FieldValue fields = 1;
string record_type = 2; // "u" (update), "c" (create), "r" (read), "d" (delete)
}
Metadata metadata = 2;
repeated IceRecord records = 3;
}
message RecordIngestResponse {
string result = 1;
bool success = 2;
}
Benefits of this protocol change:
- Typed
oneoffields: Use significantly less memory than genericgoogle.protobuf.Valuemaps, reducing both serialization overhead and memory allocations - Single RPC endpoint: Simplifies client/server logic and reduces connection management overhead
- Clear operation intent: The
PayloadTypeenum makes it explicit what operation is being performed - No Debezium envelope: The payload is purpose built for Iceberg writes, eliminating unnecessary parsing and transformation steps
- Efficient field encoding: Protobuf's binary encoding is more compact and faster to parse than JSON
- Compile time type safety: Both Go and Java get compile time validation of message structures
4. Moving Compute to Go Side
In the previous architecture, all processing, type detection, and type promotion happened on the Java side. In the new writer, the Golang side is responsible for type detection, schema updates, and data writing.
All concurrency management happens on the Go side. Iceberg Java server just acts as an API server where each API has single responsibilities. There are some optimizations that we have done:
- Concurrent processing: Managing multiple writer threads that can process different chunks or cdc simultaneouslnaging multiple writer threads that can process different partitions or tables simultaneously
- Schema coordination: Detecting table changes and coordinating evolution across threads
- Lifecycle management: Properly initializing and cleaning up writer resources
Parallel Normalization and Schema Change Detection
Normalization and schema change detection checks run in parallel at the thread level. Each thread builds a local candidate schema from its batch, compares it against the table's global schema, and only acquires the table level schema lock if a difference is detected. This approach minimizes contention and allows for efficient parallel processing.
How parallel normalization works:
- Thread local schema detection: Each writer thread analyzes its batch of records to build a candidate schema
- Parallel comparison: Threads compare their local schema against the global table schema without blocking
- Contention minimization: Only threads that detect actual schema changes acquire the table level lock
- Efficient processing: Multiple threads can process different batches simultaneously without schema conflicts
This parallel approach is crucial for maintaining high throughput while ensuring schema consistency across all writer threads.
Go Maintains Schema Copy
So to reduce RPC calls and overhead of Java server, the identical writer schema copy is being maintained on the Go side, which is responsible to check if any schema evolution is required or not. In that way, we avoid unnecessary locks for the schema checks. Also Go side verifies if schema is compatible with Iceberg format or not.
5. Partition Fanout Writer
Highly partitioned tables were another pain point we encountered. Here's what was wrong and how we fixed it:
-
Previous approach problems: When a record with a different partition arrived, the old implementation would close the current writer and open a new one. This meant sorting data in each batch before writing, which created small files. The result? Frequent writer creation/destruction overhead, many small files, and poor I/O efficiency.
-
The scale problem: Imagine processing a table with 50-100 partitions—you're constantly creating and destroying writers, which is expensive. Plus, all those small files hurt query performance because query engines need to read metadata from many files.
-
Our solution: We now maintain multiple partition writers concurrently. When memory allows, several partition writers can be active simultaneously, each handling different partitions and buffering data to target larger, more consistent file sizes.
-
The benefits: Improved throughput on highly partitioned tables, consistent file sizes for better query performance, and better resource utilization. This is crucial for tables with many partitions, where the traditional approach would create hundreds or thousands of small files, leading to poor query performance and storage inefficiency.
The Benchmarks (Success Metrics)
Now if you have seen our headline about 7x or 700% improvement, here is the proof:
| Metric | Before | After | Improvement |
|---|---|---|---|
| Throughput | ~46K records/sec | ~320K records/sec | 7× faster |
| Memory usage | 80GB+ | 40GB+ | 50% reduction |
| File size consistency | 30MB - 50MB range | 300-400MB target | Consistent sizing |
Test Environment:
- Hardware: 64-core CPU, 128GB RAM, NVMe SSD storage
- Workload: NYC taxi data with insert operations only
- Data volume: 4 billion records
- Partitions: 50-100 partitions per table
- Schema changes: 2-3 schema evolutions per test run
Key Insights:
- Consistent performance: The new architecture maintains performance even under high concurrency (10+ writer threads)
- Predictable resource usage: Memory and CPU usage are now predictable and bounded
- Better scalability: Performance scales linearly with additional threads and partitions
Conclusion
The destination refactor represents a fundamental shift in how we approach data pipeline architecture. By carefully separating concerns between Go and Java components and eliminating unnecessary complexity, we've achieved both significant performance improvements and stronger correctness guarantees.
Key Achievements
- 7× performance improvement: Result of multiple compounding optimizations including bigger batches, typed serialization, and native Iceberg I/O
- Robust schema evolution: Thread safe schema evolution with explicit writer refresh ensures consistency across concurrent operations
- Improved scalability: Better resource utilization and reduced contention enable the system to handle larger workloads
Architectural Insights
The split between Go (data plane) and Java (Iceberg I/O) provides the right abstraction boundaries:
- Go's strengths: Concurrent programming, lightweight threading, and efficient memory management make it ideal for data plane operations
- Java's strengths: Mature Iceberg ecosystem, optimized I/O libraries, and vectorized operations provide the most efficient path for file operations
- Clean interfaces: The typed gRPC contract eliminates serialization overhead while maintaining type safety
- Explicit lifecycle management: Well defined resource management prevents leaks and ensures consistency
Broader Implications
This refactor demonstrates several important principles for building high-performance data systems:
- Eliminate unnecessary complexity: Removing the Debezium envelope simplified the pipeline and improved performance
- Leverage native capabilities: Using each language's strengths rather than forcing a one-size-fits-all approach
- Design for correctness first: Strong consistency guarantees enable better performance optimizations
- Measure and optimize systematically: Each optimization was measured and validated before moving to the next
- Extendible Code: New features can be created easily on top of current architecture.
The result is a system that is not only faster but also more reliable, maintainable, and operationally friendly.
OLake is an open-source CDC and data ingestion platform for Apache Iceberg. Built for correctness, designed for speed, optimized for operations.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.