Comparing Delete Methods in Apache Iceberg & Delta Lake

In recent years, terms such as deletion vectors, position deletes, and other related concepts have become increasingly common in discussions around modern data lakehouse technologies. However, the nuances of these deletion mechanisms are not always well understood, despite their growing importance.
This article explores how leading open table formats manage data deletions, why these approaches matter, and the practical implications for organizations building data lakehouse platforms.
The Evolution from Traditional Data Lakes to Smart Data Lakehouses
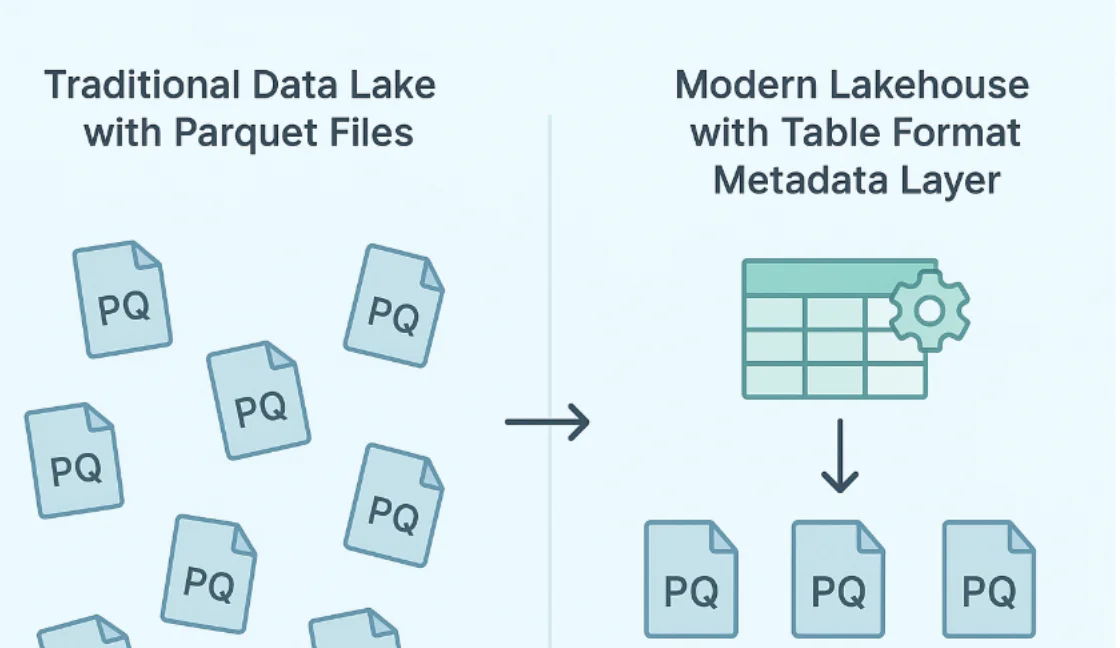
Consider a simple scenario: attempting to delete a single row from a large Parquet file. While possible, the process is highly inefficient and computationally expensive, as it typically requires rewriting the file rather than removing just the targeted record.
Traditional data lakes were built on immutable file formats like Parquet, which are fantastic for storage efficiency and query performance. However, they have one major limitation: you can't easily update or delete individual records. When you need to delete even a single row from a file containing millions of records, the entire file must be rewritten. Imagine having to reprint an entire newspaper just to correct one typo, that's essentially what we were dealing with.
This is where table formats like Apache Iceberg and Delta Lake come to the rescue. These aren't just file formats; they're intelligent abstraction layers that sit on top of your storage, providing database-like capabilities including ACID transactions, schema evolution, and most importantly for our discussion – efficient row-level operations.
Apache Iceberg: The Netflix Innovation That Changed Everything
Understanding Iceberg's Architecture
Apache Iceberg was born out of necessity at Netflix when they were dealing with massive Hive-partitioned datasets on S3 that were becoming unmanageable. The company needed a way to handle petabyte-scale data with better performance and reliability where we got a table format that separates metadata management from data storage, enabling incredible flexibility and performance.
Instead of relying on directory structures like traditional Hive tables, Iceberg maintains a sophisticated metadata layer.
This metadata layer consists of:
- Metadata files that contain table schema and configuration information
- Manifest lists that point to manifest files for different snapshots
- Manifest files that contain information about data files and their statistics
- Data files where your actual data lives in formats like Parquet or Avro
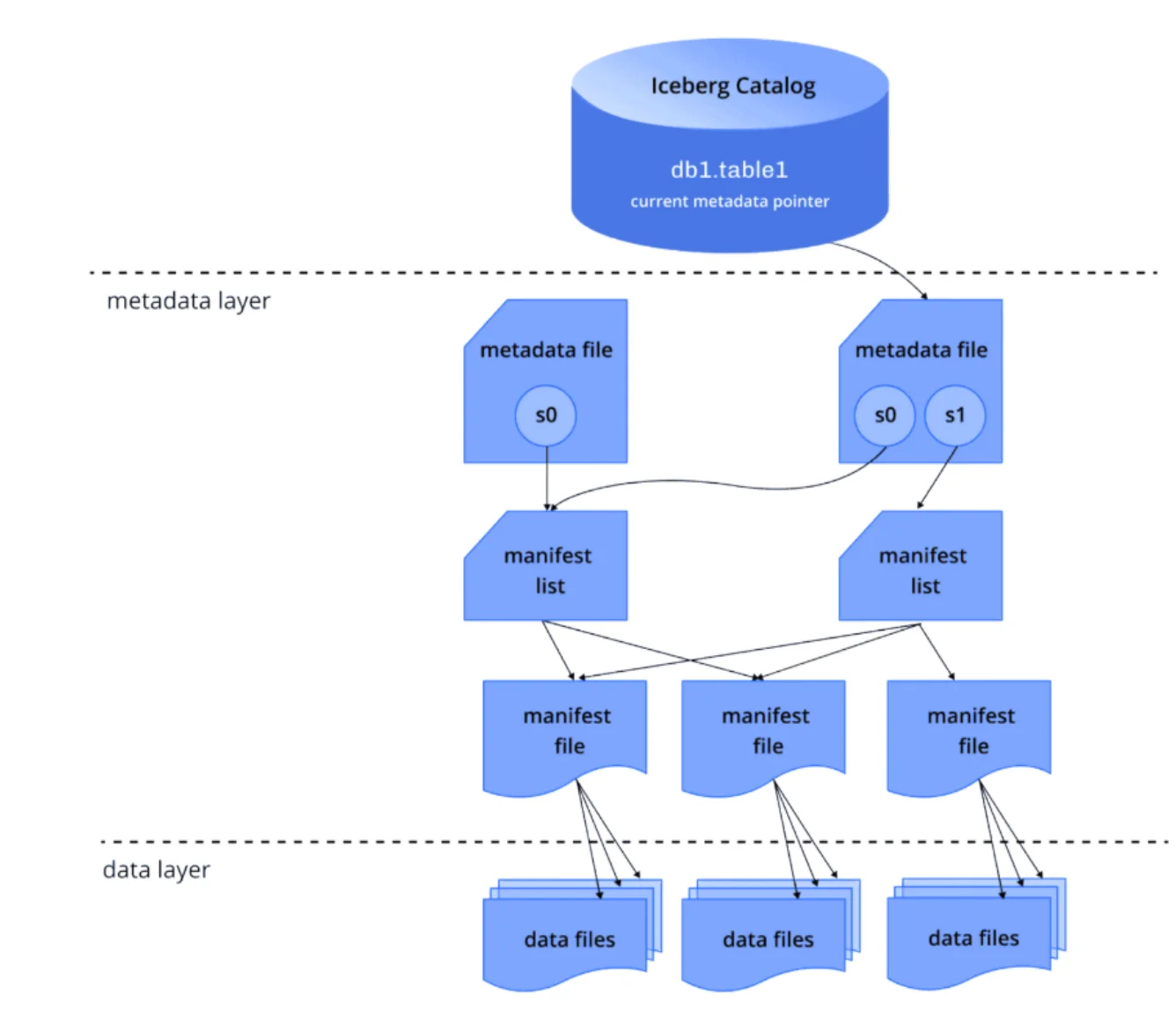
This layered architecture is what makes Iceberg so powerful. When you want to query your data, the engine doesn't need to scan directories or enumerate files; it simply reads the metadata to understand exactly which data files contain the information you need.
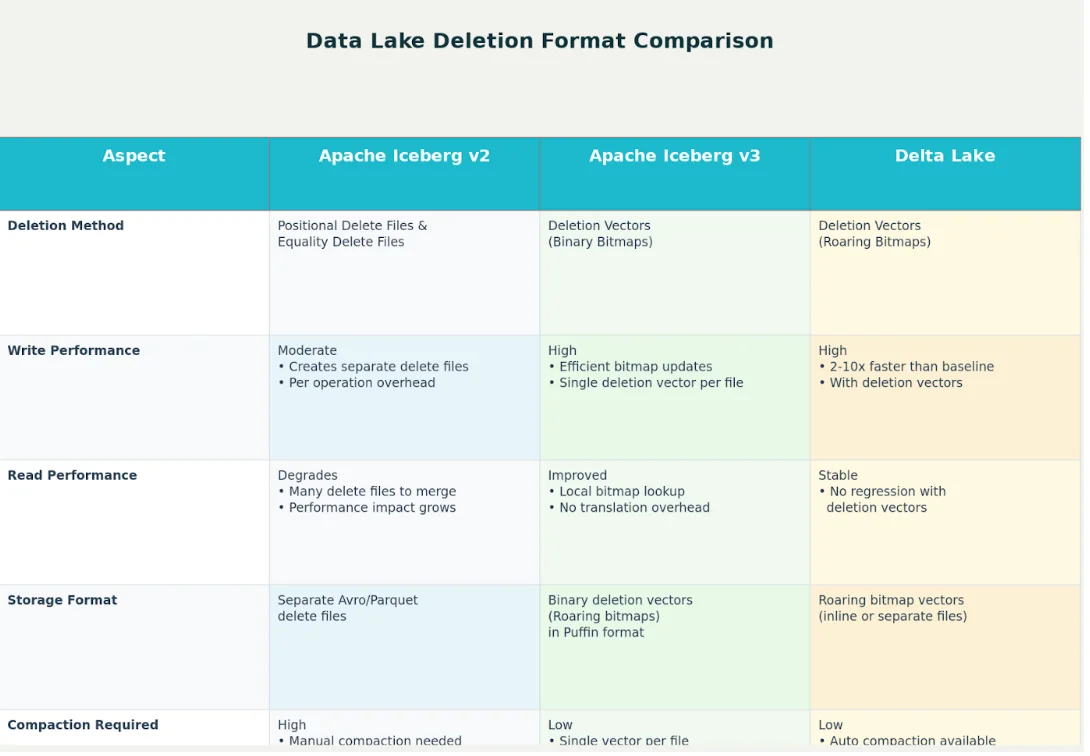
The Deletion Challenge in Iceberg v2
In Iceberg format version 2 (v2), the system introduced two clever approaches to handle deletions without rewriting entire files:
-
Position Deletes: These are like having a detailed index that says "ignore row number 42 in file ABC and row number 1,337 in file XYZ." The delete file stores the exact file path and row position of deleted records. While this works well, it requires the query engine to read through potentially many small delete files and apply them during query time.
-
Equality Deletes: These work differently by storing the actual column values that should be considered deleted. For example, instead of saying "delete row 42," it says "delete all rows where customer_id = 12345." This is faster to write but can be more expensive to process during reads since the engine must compare every row against the deletion criteria.
Both approaches follow what's called a Merge-on-Read (MoR) strategy. The beauty of MoR is that writing becomes much faster because you're not rewriting large files. However, there's a trade-off: reads become slightly more expensive because the query engine must merge the delete information with the base data files on-the-fly.
No More Centralized Delete Logs
In Iceberg versions earlier than v3, deletions were handled through positional delete files. Each of these files contained references to data file paths along with the exact row positions that should be ignored. While functional, this approach introduced two big challenges:
-
Disparate Delete Files – Every batch of deletes could generate new small delete files scattered across storage. Over time, tables accumulated hundreds or thousands of these, creating the classic "small file problem" and making metadata management more complex.
-
Query-Time Merging – When reading data, the engine had to scan not only the base data files but also locate and merge all relevant delete files. This added significant overhead, especially for queries touching many partitions.
Iceberg v3 solves this by attaching a deletion vector (DV) directly to each data file, stored in a compact Puffin sidecar. Instead of chasing down multiple delete files scattered across the table, the query engine can simply read the file and its paired DV together. This removes the need for centralized logs and fragmented delete files, drastically simplifying read paths and improving performance.
How Deletion Vectors Work in Iceberg v3
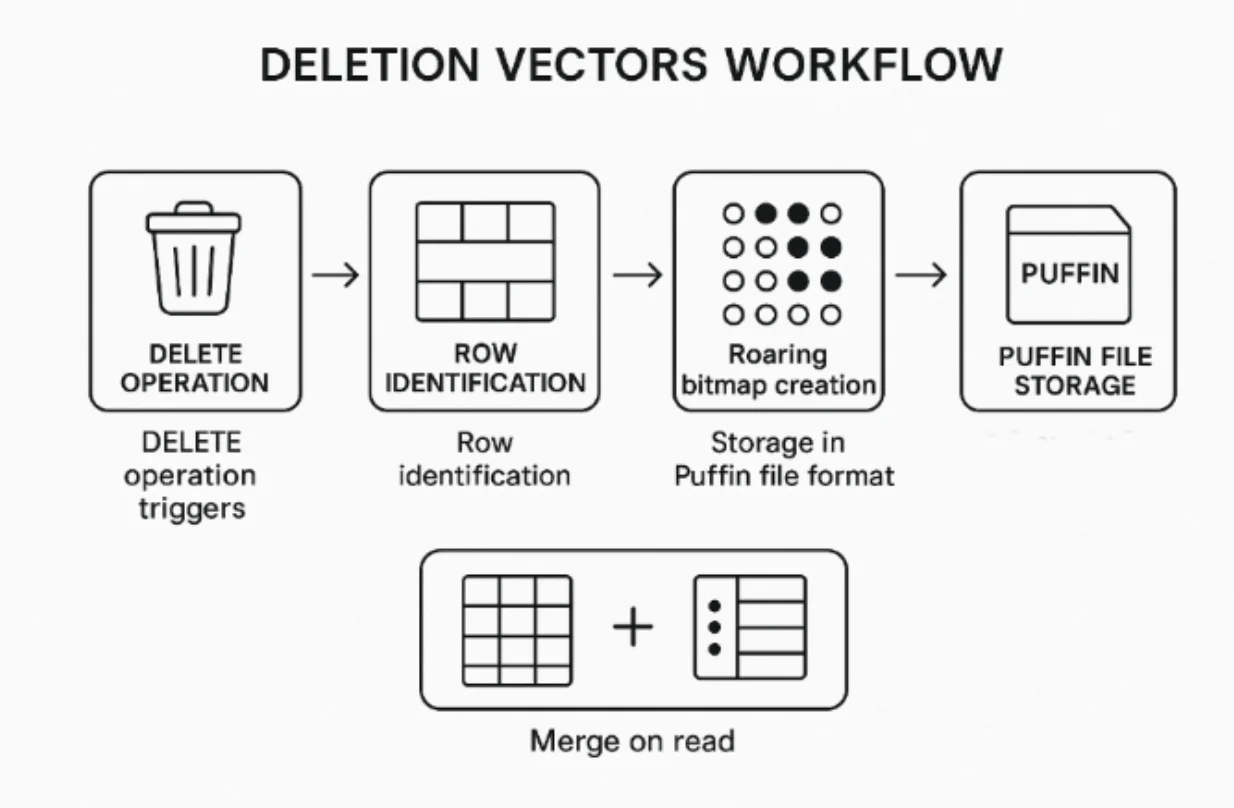
Iceberg v3 fundamentally improves the process of managing deletes by pairing each data file with its own compact deletion vector, stored as a Roaring Bitmap in a Puffin file. As queries scan a data file, they can efficiently read its associated deletion vector to mask out deleted rows with minimal overhead. This design means deletions are applied at read time but are highly performant due to the compressed, in-memory nature of Roaring Bitmaps.
-
No More Centralized Delete Logs: Previously, deletes required referencing a centralized log such as a deletes.avro file that mapped files and row positions. Iceberg v3's model attaches the delete information directly alongside each data file, simplifying read paths and reducing query-time complexity.
-
Puffin Files: Deletion vectors are stored in a special, efficient format called Puffin, which is tailored to store various metadata "blobs" (not just DVs, but potentially future features like sketches and indexes). Puffin uses a consistent, binary format with built-in checksums, compression flags, and support for both backward and future compatibility.
-
Improved Performance & Compaction: Performance is further improved thanks to required maintenance of a single DV per file eliminating the proliferation of many tiny delete files and streamlining data file statistics and state comparison across snapshots.
-
Compatibility and Unification: By using Roaring Bitmaps and aligning file encoding with Delta Lake's established approaches, Iceberg v3 further enables compatibility and easier migration/interoperability between leading data lakehouse engines. This unification benefits organizations seeking flexibility as their data architectures evolve.
Detailed Format and Features
-
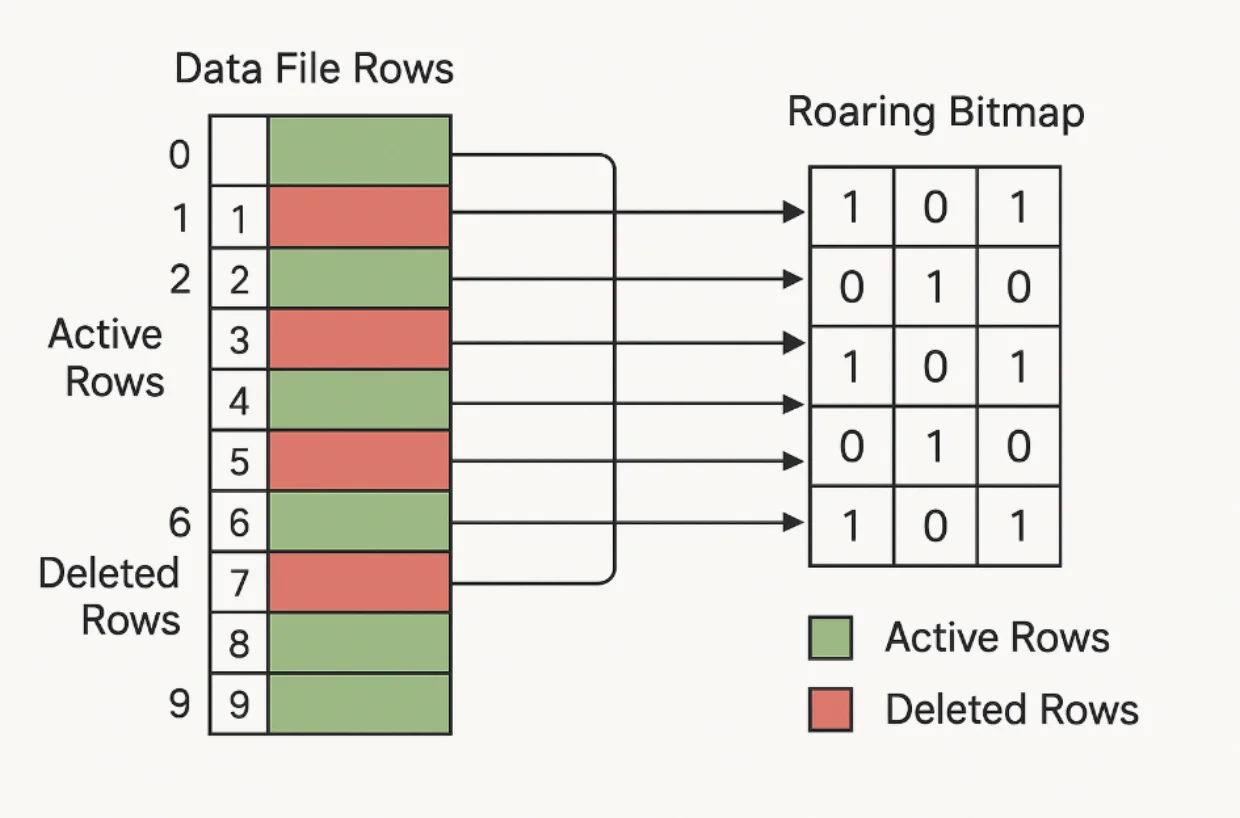
Roaring Bitmap Storage: Each deletion vector represents row positions as bits in a bitmap—if a bit is set, that row is considered deleted. Roaring Bitmaps provide exceptional compression and efficient search/access even for sparse deletions across large files.
-
Sidecar Model for Deletes: Every data file now has a paired .puffin sidecar storing its DV, which reduces I/O, isolates delete logic, and enables more granular, localized compaction.
-
Binary Format – On-Disk Parity With In-Memory Deletion State: Previously, deletion vectors existed in-memory only; v3 persists them on disk with strong format guarantees, removing conversion overhead thus query engines no longer need to rebuild bitmaps from raw logs on every scan; they can load them directly into memory as-is, enabling increased performance.
-
Maintenance and Enforcement: The spec and most engines now require compaction at write time to ensure only a single DV exists per file, thereby keeping tables tidy and performant with minimal operational burden.
Why This Matters
-
Scalability: Deletion vectors make row-level deletes viable for tables with massive scale, where previous approaches would degrade rapidly.
-
Minimal Read Overhead: By localizing and compressing deletes, reads are significantly faster even as deletions accumulate, since there's no need to merge many files or reconstruct metadata from logs.
-
Powerful CDC: This architecture is especially powerful for Change Data Capture (CDC), regulatory compliance, streaming ingestion, and other scenarios where deletions are frequent and need to happen without disrupting write throughput.
New Practical Considerations
-
No More Positional Delete Files: From v3 onward, position delete files are deprecated; users must migrate to DVs for all new tables, and older tables should consider upgrading for performance and simplicity.
-
Intelligent Blob Metadata: Puffin blobs (containing DVs) carry explicit metadata, including the referenced data file location and cardinality (number of deleted rows). This enhances both management and logical audits of deletes at scale.
-
Easier Downstream Change Processing: The enforced one-DV-per-file rule and improved metadata allow for simpler, more accurate streaming and incremental processing, as previous and current DV states can be easily compared.
Delta Lake: Databricks' Answer to Lakehouse Challenges
The Delta Lake Approach
While Netflix was developing Iceberg, Databricks was tackling similar challenges with their own approach: Delta Lake. Delta Lake wraps around Parquet files and maintains a transaction log that tracks all changes to the table. This transaction log is what enables ACID properties and time travel capabilities.
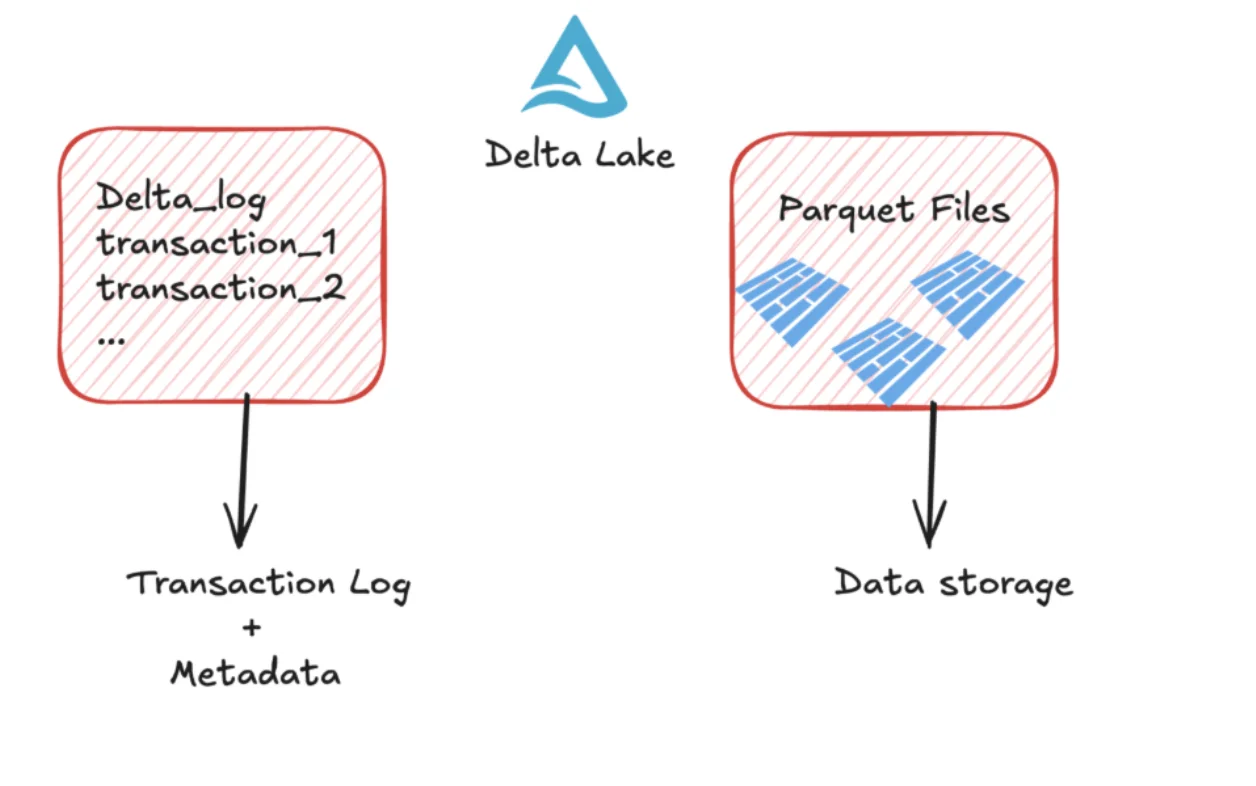
Delta Lake's approach to deletions has been evolving. Initially, the system used a Copy-on-Write (CoW) approach where any change to a file required rewriting the entire file. While this ensures optimal read performance, it can be expensive for write operations, especially when you're dealing with frequent small updates.
Delta Lake Embraces Deletion Vectors
Recognizing the benefits of the merge-on-read approach, Delta Lake introduced its own version of deletion vectors. Like Iceberg v3, Delta Lake's deletion vectors use Roaring Bitmaps to efficiently track deleted rows without rewriting data files. The key insight is that deletion vectors spread the cost of deletions over time; you pay a small price during reads but save significantly during writes.
But here's the interesting part: reads can become slower with deletion vectors, especially if you have many deletions and don't run maintenance operations. This is where the OPTIMIZE command becomes crucial it compacts the data files and incorporates the deletions, eliminating the merge-on-read overhead for future queries.
Copy-on-Write vs. Merge-on-Read: Choosing Your Strategy
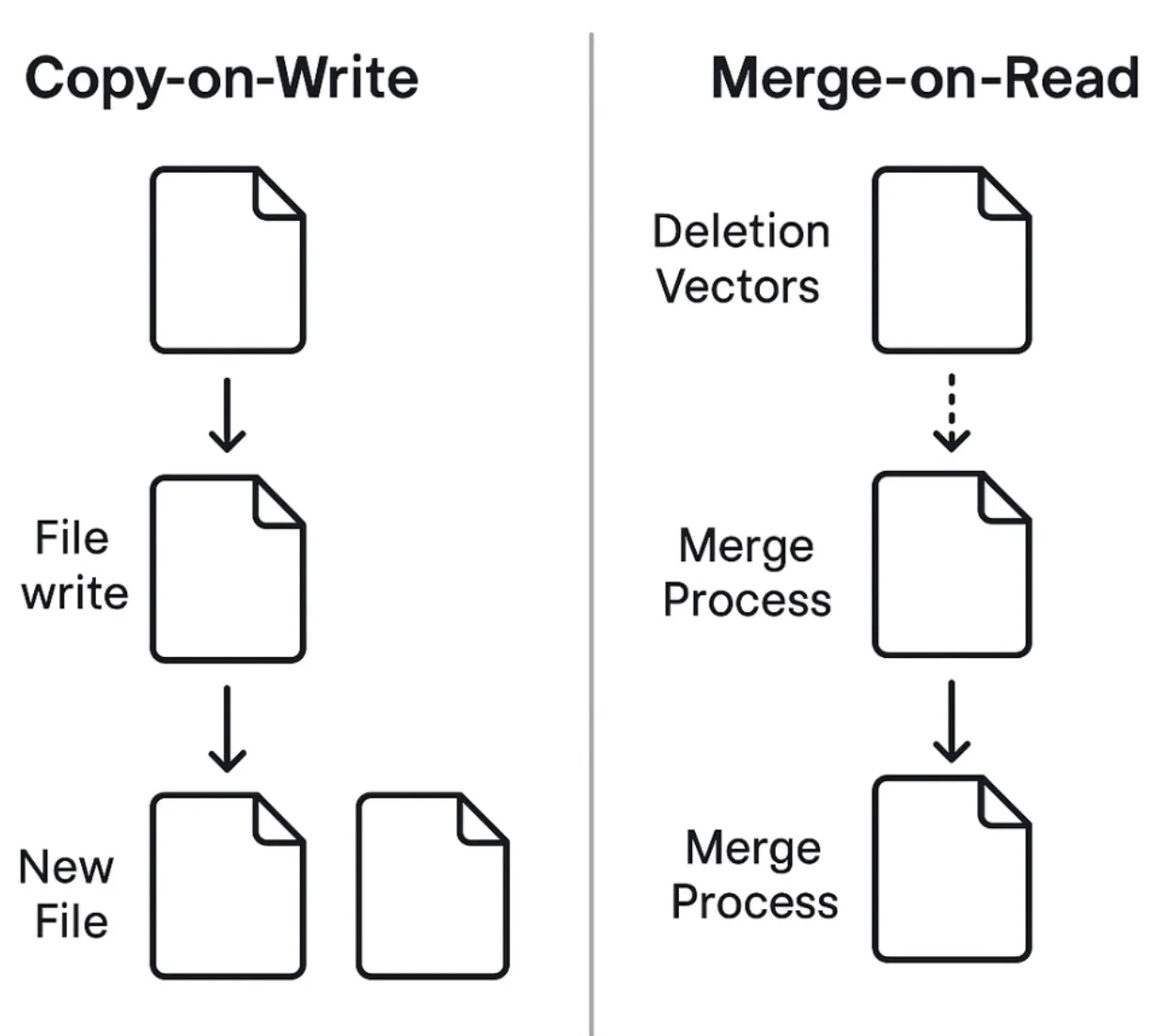
Want to dive deeper into MOR vs COW strategies? Check out our comprehensive guide on Understanding Equality Deletes in Apache Iceberg for detailed performance comparisons and real-world testing results.
Let me help you understand when to choose each approach because this decision can significantly impact your system's performance.
Copy-on-Write (CoW): When Reads Rule
CoW is perfect when you have:
- Infrequent updates and deletions but lots of queries
- Large batch operations where rewriting files makes sense
- Read-heavy workloads where query performance is paramount
- Simple operational requirements without complex maintenance schedules
Think of a data warehouse scenario where you load data once daily and run hundreds of analytical queries. Here, the upfront cost of rewriting files pays off through faster query performance.
Merge-on-Read (MoR): When Speed Matters
MoR shines when you have:
- Frequent small updates that would make CoW expensive
- Real-time streaming data where write latency is critical
- Change Data Capture (CDC) scenarios with high update frequencies
- Regulatory compliance requirements needing frequent deletions
Consider a scenario where you're ingesting streaming data from multiple sources with occasional corrections and deletions. MoR allows you to handle these changes efficiently without disrupting your ingestion pipeline.
How Companies Are Using These Technologies
Netflix: Maestro and Incremental Processing
Netflix uses Apache Iceberg with their Maestro platform to handle incremental data processing at massive scale. By leveraging Iceberg's snapshot isolation and incremental processing capabilities, they've eliminated the need for expensive full data reprocessing while maintaining data accuracy and freshness. This is particularly crucial for their content recommendation systems that need up-to-date user interaction data.
Airbnb: From HDFS Bottlenecks to S3 Efficiency
Airbnb migrated their data warehouse from HDFS to Apache Iceberg on S3, achieving remarkable results. They experienced a 50% reduction in compute resources and a 40% decrease in job elapsed time for their data ingestion framework. The key breakthrough was eliminating the Hive Metastore bottleneck that was causing performance issues with their millions of partitions.
Apple: Enterprise-Scale Compliance
Apple has implemented Iceberg as the foundation for their lakehouse architecture across all divisions, managing tables ranging from megabytes to petabytes. Their primary challenge was regulatory compliance (GDPR, DMA) requiring efficient row-level operations rather than expensive partition-level updates. With Iceberg's row-level capabilities, maintenance operations that previously took "something like two hours" now complete in "several minutes."
Practical Considerations using Apache Iceberg
Implementing Apache Iceberg isn't just about better features, it's about balancing performance, storage efficiency, and operational complexity. Here are the challenges people face while doing the implementation.
The Small File Problem
One challenge both systems address is the "small file problem". When you have frequent updates using traditional approaches, you can end up with thousands of tiny files that are inefficient to process. Deletion vectors help by consolidating deletion information into compact, efficiently stored formats rather than creating numerous small delete files.
Maintenance and Optimization
Here's something crucial that many teams learn the hard way: maintenance operations are not optional. Whether you're using Iceberg or Delta Lake with merge-on-read approaches, you need regular compaction operations to maintain optimal performance. Think of it like defragmenting your hard drive – it's maintenance that pays dividends in performance.
For Delta Lake, this means running OPTIMIZE commands regularly. For Iceberg, you'll want to schedule compaction jobs to merge delete files and rewrite data files periodically. The good news is that many cloud platforms now offer automated maintenance services to handle this for you.
Making the Right Choice for Your Organization
So, how do you decide between Apache Iceberg and Delta Lake, and when should you enable deletion vectors? Let me give you a framework for thinking about this.
Choose Apache Iceberg When:
- You need multi-engine compatibility across different analytics tools
- Your primary challenge is metadata management at massive scale (10K+ partitions)
- You want to avoid vendor lock-in and need maximum flexibility
- You're building on cloud-native infrastructure with diverse compute engines
Choose Delta Lake When:
- You're primarily a Spark shop with relatively low write throughput
- You're already using Databricks and want tight ecosystem integration
- You need the easiest operational experience with excellent tooling
- You want portability without catalog dependencies for development work
Enable Deletion Vectors When:
- You have high write frequency or need low write latency
- Your workload involves frequent small updates spread across many files
- You're implementing CDC pipelines or real-time data correction
- Write performance is more critical than absolute read performance
Wrapping Up: The Practical Takeaways
Let's bring this full circle with the key points you should remember:
-
Understanding the Trade-offs: Deletion vectors represent a fundamental shift from eager to lazy deletion processing. You're trading some read performance for significantly better write performance and operational flexibility. This trade-off makes sense for most modern data workloads where real-time updates are increasingly important.
-
Maintenance Matters: Whether you choose Iceberg or Delta Lake, success with merge-on-read approaches requires good operational practices. Regular compaction isn't optional – it's essential for maintaining performance over time.
-
The Ecosystem is Converging: The collaboration between format communities means you're less likely to make a "wrong" choice. Both formats are evolving to address similar challenges with similar solutions, reducing the risk of technological lock-in.
-
Start Simple, Scale Smart: Begin with the default approaches (copy-on-write for batch workloads, deletion vectors for high-update scenarios) and optimize based on your actual performance characteristics and operational requirements.
The world of data lake deletion formats might seem complex, but it's really about solving a fundamental problem: how do you efficiently manage changing data at scale? Apache Iceberg and Delta Lake have both arrived at elegant solutions that make this possible, each with their own strengths and ideal use cases.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.