Beyond Structured Tables: Variant and Geospatial Data in Apache Iceberg v3

Introduction
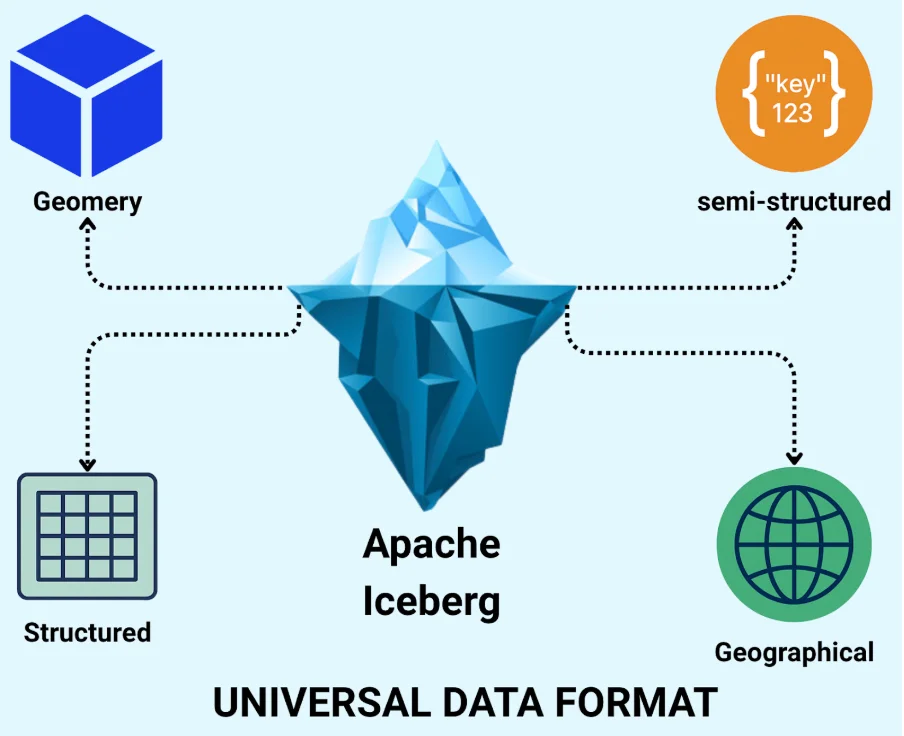
The journey of Apache Iceberg has always been about more than just "managing structured data as tables" What began as an open-table format designed for large-scale structured analytics has steadily widened its scope, and with the arrival of v3, it's making a bold leap into becoming a universal data format. In its early days, Iceberg focused on resolving the limitations of data lakes for structured data: versioning, partitioning, schema evolution, and reliable reads/writes at massive scale. Over time it added support for deletes, merges, row-level updates, and concurrent multi-engine access.
But as data engineering matured, so did the shape of data itself. Modern pipelines don't just handle neatly typed columns; they ingest semi-structured JSON logs, IoT event streams, API payloads, and geospatial datasets. Traditional table formats struggled with this variety.
That's why Iceberg v3 is so meaningful. With the addition of advanced data types such as VARIANT (for semi-structured content) and GEOMETRY/GEOGRAPHY (for spatial workloads), Iceberg is no longer just a table format; it's positioning itself as the foundational layer across structured, semi-structured, and spatial analytics.
For data engineers, this shift signals a major opportunity: you can now unify previously siloed workloads, think JSON event hubs, map-based analytics, and sensor trajectories, under a single open format with full enterprise features. In the sections that follow, we'll dive deep into those two data types, show how they work, why they matter, and how you can start leveraging them with Iceberg.
Variant Datatype
Overview:
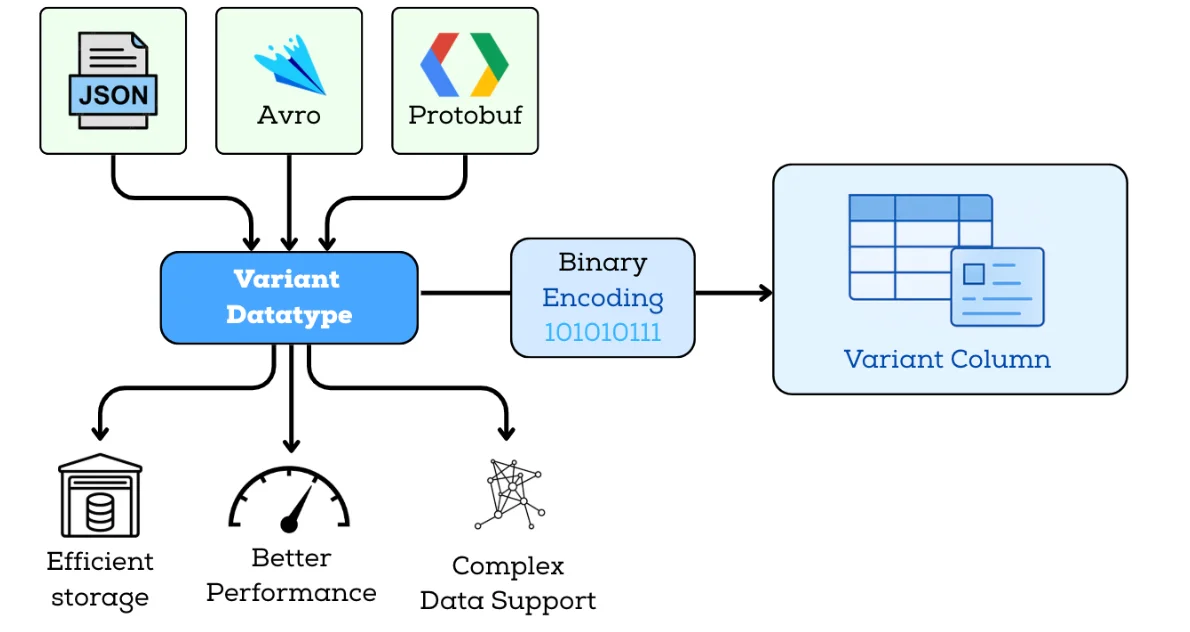
The Variant data type in Iceberg v3 allows semi-structured data—such as JSON, Avro, or API payloads to be stored natively in a compact binary format. It preserves flexible and evolving schemas while giving query engines a much more efficient representation than plain-text JSON. As more engines converge on consistent semi-structured data handling, Variant provides a common baseline across the ecosystem.
Why Variant Matters:
The Variant type brings three core advantages, each directly tied to real workloads:
Flexible Schema Handling
You can ingest complex, dynamic payloads without pre-flattening or constantly modifying table schemas. This makes it ideal for logs, event streams, IoT payloads, and API responses that change frequently.
Efficient Storage & Performance
Storing nested data in binary form drastically reduces storage footprint and avoids repeatedly parsing text-based JSON. Engines can push down filters, extract fields, and evaluate predicates much faster.
Native Support for Nested Structures
Variant cleanly handles arrays, objects, and mixed structures within a single column, enabling expressive queries on nested elements using engine-level functions.
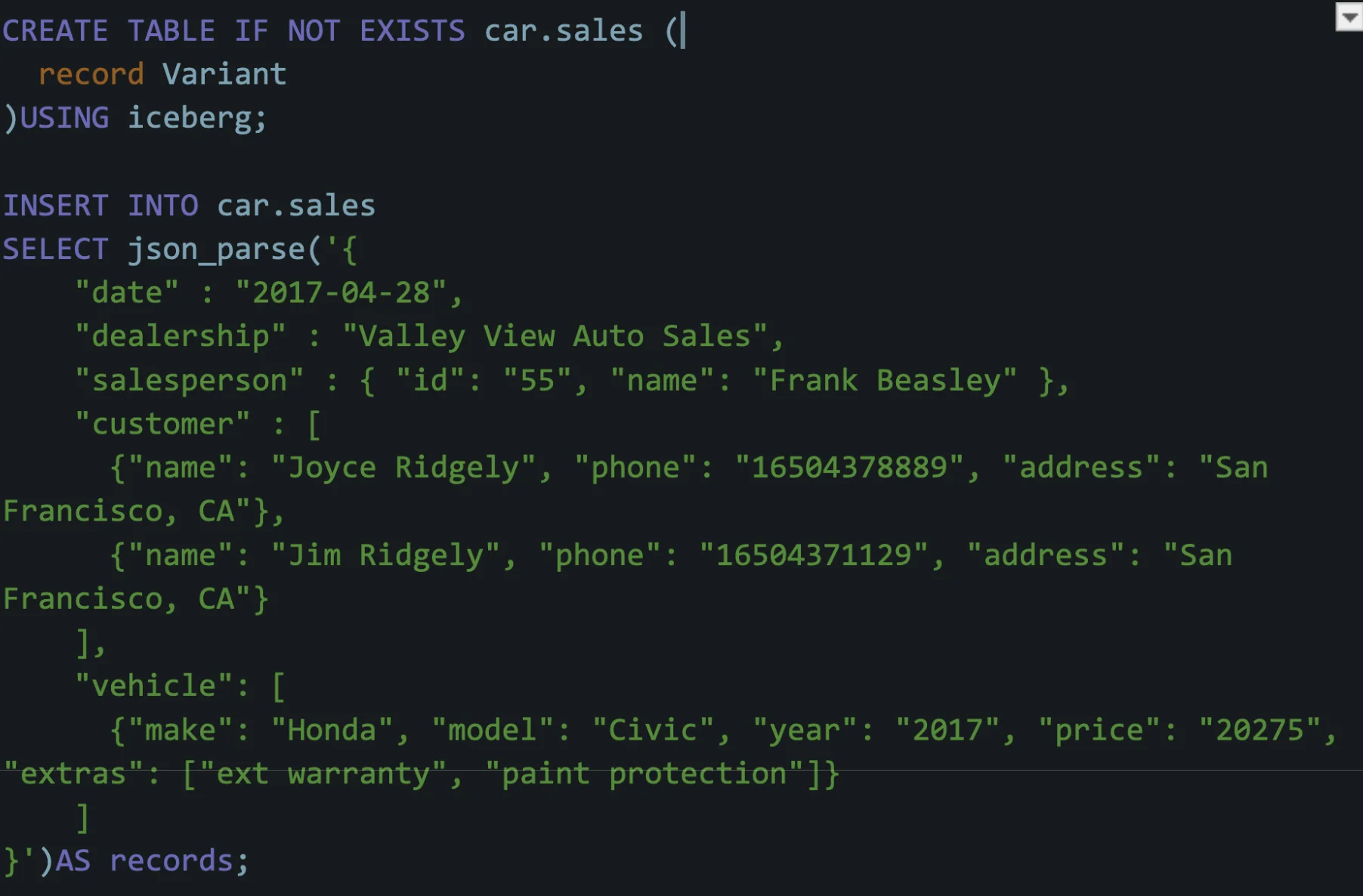
Example:
Create a table with a Variant column and insert semi-structured data using spark sql:
Query the data:
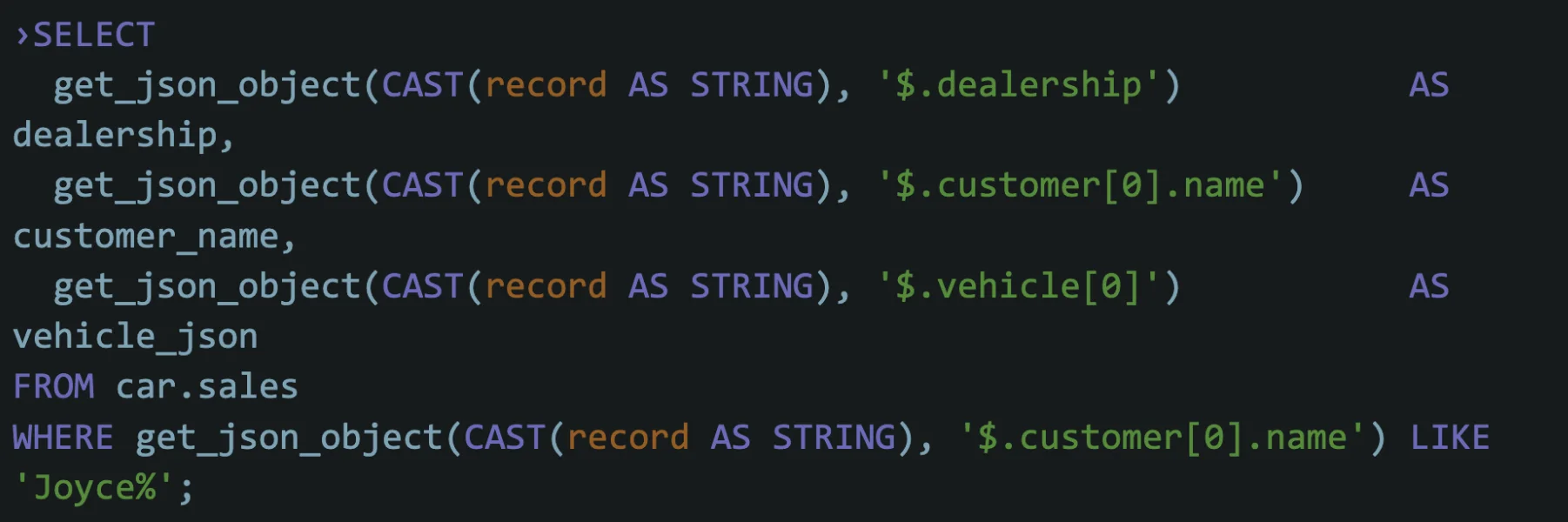
Result:
| DEALERSHIP | CUSTOMER_NAME | VEHICLE |
|---|---|---|
| Valley View Auto Sales | Joyce Ridgely | { "extras": [ "ext warranty", "paint protection" ], "make": "Honda", "model": "Civic", "price": "20275", "year": "2017" } |
Functions and Engine-Support for Variant Columns
Many query engines and platforms that integrate with Iceberg support functions to parse and manipulate semi-structured data in variant columns. The exact function names and availability depend on the engine.
Encoding Evaluation
The encoding format for the variant type is critical for balancing storage efficiency and query performance. Iceberg v3 does not mandate a specific encoding (such as BSON or any engine-specific layout); instead, engines and file formats are free to adopt binary representations optimized for nested object/array access, which typically perform much better than storing JSON as plain strings.
Storage and File Format Support
Iceberg v3 defines the Variant type, and engines map it into Parquet, Avro, or ORC according to each format's capabilities. Today, Parquet has the most mature variant encoding support, and support in Avro and ORC is evolving as the ecosystem catches up. In all cases, the low-level representation is handled by the file format and engine implementations rather than by end users.
Future Improvements
Subcolumnarization: Materializing subcolumns (nested fields within a variant column) to improve query performance. This would allow engines to track statistics on subcolumns, enabling more efficient query processing.
Native Variant Support in File Formats: Future improvements include adding native variant support in file formats like Parquet and ORC, so that complex semi-structured data can be stored and read without structure-losing transformations. This would give different engines (Spark, Trino, Flink, warehouses, etc.) a common, well-defined way to interpret variant columns, making it easier to share tables, reuse schemas, and move workloads across projects that integrate with Iceberg.
Geospatial Datatype
Introduction
Geospatial data has become a core component of modern data platforms. Historically, many big-data solutions relied on bespoke extensions and separate frameworks to handle location-based analytics—because open table formats did not natively support spatial types and functions. With Apache Iceberg v3, however, the specification now includes native support for geometry and geography types, reducing the need for work-around layers built on top of Iceberg. Although the ecosystem is actively advancing toward full spatial partitioning and clustering transforms, users should review current engine-level support when implementing spatial workflows.
Let's explore the proposal to add native geospatial support to Apache Iceberg, covering the motivation, key features, and implementation plan.
Motivation for Native Geospatial Support
While geospatial workloads are already well-established in modern data platforms, managing them on top of Iceberg has historically required ad-hoc patterns: storing geometries as strings, using custom encodings, or maintaining forks and extensions. These approaches introduce upgrade friction, ecosystem fragmentation, and inconsistent behavior across engines. Native geospatial types in Iceberg v3 are intended to eliminate that gap and provide a stable foundation for spatial analytics by addressing three key needs:
Integration with other Big Data Ecosystems: Many data processing systems (e.g., Apache Flink, Apache Spark, and Apache Hive) offers geospatial functions. Native support in Iceberg will provide seamless compatibility with these systems.
Efficient Querying: Iceberg's ability to handle large datasets and its support for partitioning and clustering will allow users to efficiently query and analyze geospatial data using spatial predicates.
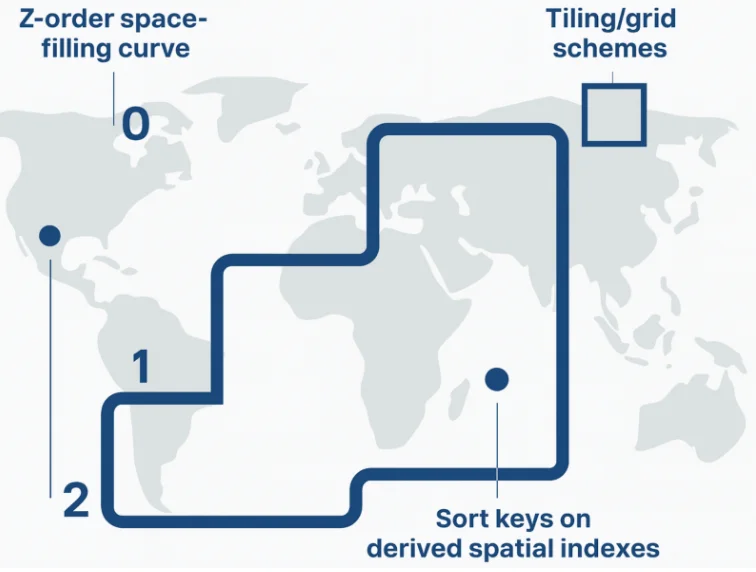
Geospatial Partitioning and Clustering: Emerging patterns in geospatial data modelling suggest that partitioning transforms such as Z-order, Hilbert curves, or other geospatial indexing may be used (or are under discussion) to optimize layout for spatial queries.
Key Features of Geospatial Support in Apache Iceberg
1. Geospatial Types
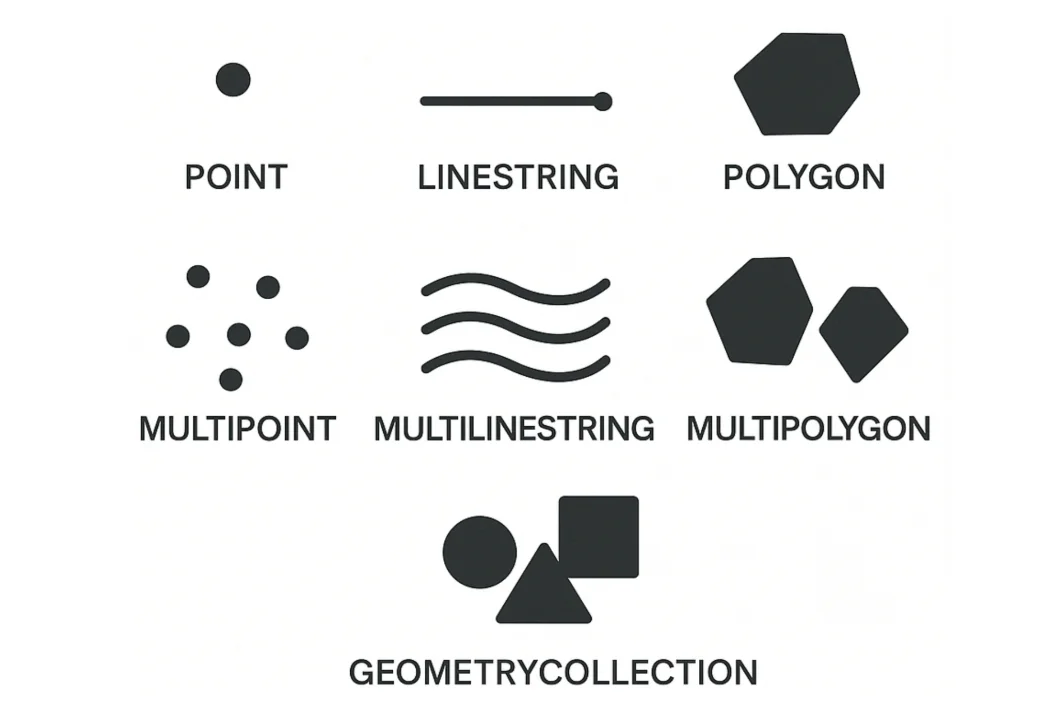
To represent geospatial data, Iceberg v3 introduces native geometry and geography types. This type will support common geometric shapes, as defined by the OGC Simple Feature Access (SFA) specification, including
- POINT
- LINESTRING
- POLYGON
- MULTIPOINT
- MULTILINESTRING
- MULTIPOLYGON
- GEOMETRY_COLLECTION
These types will be implemented using the WKB (Well-Known Binary) format, which is a widely accepted binary encoding for geometric data.
Each geometry type will consist of a POINT type with x and y coordinates (as double values in Iceberg). These will be directly mapped to Iceberg's double data type, providing efficient storage and query performance.
2. Geospatial Expressions
While Iceberg v3 defines how geospatial data is stored (e.g., GEOMETRY, GEOGRAPHY), it does not define how to query or manipulate that data.
All the "smart" geospatial operations live in the query engines (Trino, Spark, DuckDB, etc.), which typically implement OGC-style functions.
Common spatial predicates include:
ST_Covers(a, b)
Returns true if geometry 'a' completely covers geometry 'b' (every point of 'b' lies within 'a').
Useful for: "Which polygons (regions) fully contain this point or shape?"
ST_CoveredBy(a, b)
The inverse of ST_Covers: returns true if geometry 'a' is completely covered by 'b'.
Useful for: "Is this object fully inside this region?"
ST_Intersects(a, b)
Returns true if the two geometries share any point in common.
Useful for: "Which delivery zones intersect this route?" or "Which tiles overlap this bounding box?"
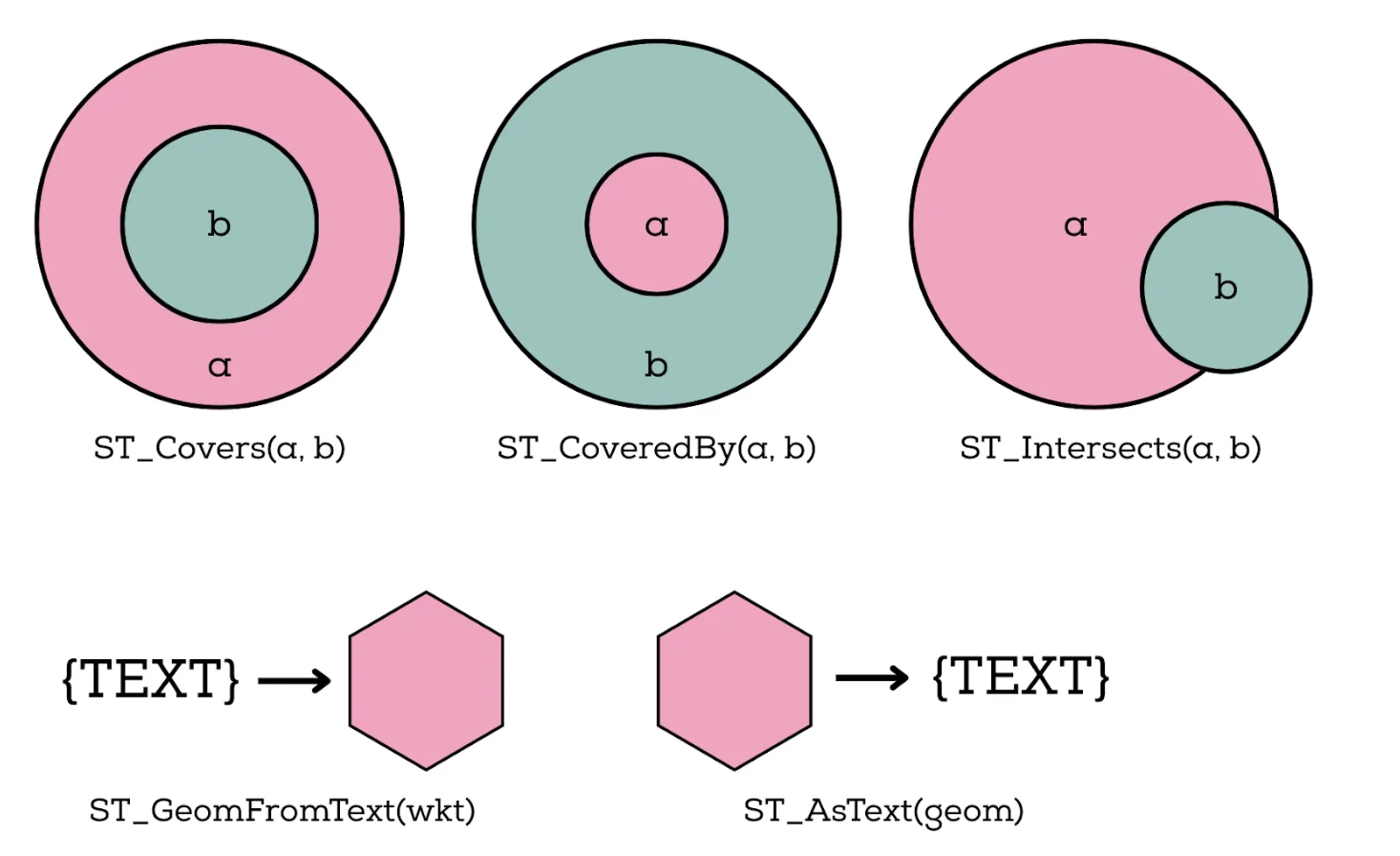
Engines also expose helper functions to convert between human-readable text and internal binary formats:
ST_GeomFromText(wkt): builds a geometry from WKT (Well-Known Text) during ingestion or querying.ST_AsText(geom): converts a stored geometry into WKT for debugging, logging, or exporting.
3. Geospatial Partition Transforms
Iceberg v3 does not yet define geospatial-specific partition transforms (like xz2) in the core table format specification. Instead, spatial optimizations today mostly live in engines and ingestion tools, which use geospatial functions to derive partition or sort keys.
In practice, teams use patterns like:
- Space-filling curves (Z-order, Hilbert, XZ2, etc.)
- Tiling/grid schemes (e.g., geohash, quadkeys, S2 cells)
- Sort keys on derived spatial indexes
These are applied at write time (in your engine or ingestion layer), while Iceberg itself just sees them as regular partition/sort columns.
Example:
CREATE TABLE iceberg.geom_table(
id int,
geom geometry
) USING ICEBERG PARTITIONED BY (xz2(geom, 7));
Here:
xz2(geom, 7)is a derived spatial index computed by your engine (e.g., via a UDF), not a built-in Iceberg transform.- Iceberg simply partitions by the resulting index column, which:
- Clusters nearby geometries together on disk
- Improves pruning and data locality for spatial filters
- Helps mitigate the boundary object problem (non-point geometries spanning multiple tiles) by using a hierarchical index that keeps related shapes close in key space.
4. Geospatial Sort Orders
In such queries, engines can combine geospatial predicates with whatever partitioning or clustering strategy you've chosen (for example, spatially aware sort keys) to prune files and row groups more effectively.
Example query:
SELECT * FROM iceberg.geom_table
WHERE ST_Covers(geom, ST_Point(0.5, 0.5));
How Variant & Geospatial Types Redefine the Iceberg Ecosystem
The introduction of Variant and Geospatial data types in Apache Iceberg v3 doesn't just expand the technical capabilities of the format; it fundamentally changes how data teams can think about designing, managing, and scaling their data systems.
1. Simplified Data Modeling and Schema Management
Data engineers no longer need to predefine rigid schemas or flatten nested structures before ingestion. With the Variant type, teams can store semi-structured data directly in Iceberg without constantly revising schemas or maintaining multiple pipelines for JSON or Avro inputs.
This means less schema churn, fewer migration headaches, and faster iteration when integrating new data sources.
2. Unified Storage for Multi-Modal Data
Previously, teams often had to maintain separate infrastructure for structured (tables), semi-structured (JSON files), and spatial (geospatial indexes) data. Iceberg v3 allows all of these to live within the same open table format, drastically reducing operational complexity.
Now, your analytics engineers, ML teams, and data scientists can all query the same Iceberg tables using Trino, Spark, or DuckDB regardless of whether the data is tabular, nested, or geospatial.
3. Improved Collaboration Across Roles
By standardizing how diverse data types are stored and queried, Iceberg v3 creates a shared foundation for multiple stakeholders:
- Data engineers can ingest data with fewer transformations.
- Analysts can query complex or nested datasets with SQL directly.
- Data scientists can work with JSON or location-based data in the same datasets used for analytics.
This unified model minimizes data silos and encourages tighter collaboration between engineering and analytics teams.
4. Reduced Operational Overhead
Supporting new data types natively within Iceberg reduces reliance on custom wrappers and external geospatial layers built on top of Iceberg or format-specific ETL jobs. Teams can now rely on a single ingestion and governance layer for all workloads, simplifying versioning, retention, and lineage tracking.
5. Future-Ready Data Platform
For teams building modern lakehouse architectures, these capabilities make Iceberg a long-term bet. As semi-structured, spatial, and even graph-like data become more common, Iceberg's extensible type system ensures your data platform evolves without re-architecting pipelines.
This gives teams confidence that investments in Iceberg today will scale with future data modalities and use cases from IoT to real-time geospatial analytics.
Why It Matters for the Ecosystem
Apache Iceberg v3's introduction of Variant and Geospatial data types marks a pivotal moment not just for individual teams, but for the broader data ecosystem built around open standards.
For years, the lack of native support for semi-structured and spatial data forced vendors and projects to build custom extensions (from proprietary JSON handling in data warehouses to community forks for geospatial analytics). With Apache Iceberg v3, these capabilities are now part of the core specification. While many query engines (such as Apache Spark, Trino and Apache Flink) are actively updating to support v3 types, users should verify the current level of support for variant and geospatial types in their engine before enabling production use.
This standardization fosters a healthier ecosystem:
- Tool builders can now innovate without reinventing data type semantics.
- Query engines can align on common encodings and predicate pushdowns, improving performance and interoperability.
- Open-source contributors have a unified path to extend Iceberg for emerging domains like IoT, mobility, or geospatial intelligence.
In short, this release strengthens Iceberg's position as the universal table format, one that unifies structured, semi-structured, and spatial data under a single open standard. It's a step toward an ecosystem where openness, interoperability, and extensibility drive progress across the entire data stack.
Conclusion
Apache Iceberg v3's integration of Variant and Geospatial data types marks a pivotal enhancement in its capabilities, positioning the format as a comprehensive solution for handling diverse data structures. By natively supporting semi-structured and spatial data, Iceberg is moving beyond traditional table formats to become a versatile foundation for modern data engineering. The Variant type enables efficient handling of dynamic, nested payloads, optimizing storage and query performance, while the introduction of native geospatial types streamlines the storage and querying of location-based data without the need for external extensions or custom encodings.
These advancements not only enhance Iceberg's ability to manage evolving data modalities but also improve performance across query engines, thanks to standardized encoding formats and predicate pushdowns. With engines like Apache Spark, Trino, and Flink actively updating to support these new types, Iceberg's role as a universal data format is solidified, providing a consistent, open standard for complex data workflows. As Iceberg v3 gains traction, it ensures that organizations can build future-proof, extensible data architectures that unify structured, semi-structured, and geospatial data under a single, scalable framework. This sets the stage for seamless interoperability across tools, optimized data pipelines, and a unified data ecosystem that can handle the demands of next-generation analytics.
Ready to leverage Apache Iceberg for your data lakehouse? OLake provides seamless CDC replication from operational databases directly to Iceberg tables, helping you build a modern lakehouse architecture with support for structured, semi-structured, and spatial data. Check out the GitHub repository and join the Slack community to get started.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.