Parquet vs. Iceberg: From File Format to Data Lakehouse King

Before we dissect the architecture, let's establish the fundamental distinction. Apache Parquet is a highly-efficient columnar file format, engineered to store data compactly and enable rapid analytical queries. Think of it as the optimally manufactured bricks and steel beams for constructing a massive warehouse. Apache Iceberg, in contrast, is an open table format; it is the architectural blueprint and inventory management system for that warehouse. It doesn't store the data itself—it meticulously tracks the collection of Parquet files that constitute a table.
Iceberg provides the database-like reliability and features that raw collections of Parquet files inherently lack, transforming a brittle data swamp into a robust data lakehouse. The choice is not Parquet versus Iceberg. It is about using Iceberg with Parquet to build something reliable, manageable, and future-proof.
You don't choose between the foundation and the blueprint; you need both to build a sound structure.
| Feature | Raw Parquet | Apache Iceberg (on top of Parquet) |
|---|---|---|
| Type | Columnar File Format | Open Table Format |
| Atomicity | None. File operations are not atomic and can lead to partial writes. | ACID Transactions delivered through atomic metadata swaps. |
| Schema Evolution | Risky and costly, often requiring full data rewrites. | Safe and Fast via metadata-only changes that require no rewrites. |
| Partitioning | Physical, directory-based partitioning that is brittle and difficult to change. | Logical and hidden partitioning that can be evolved without touching data. |
| Time Travel | Not supported. | Native support for querying historical snapshots by ID or timestamp. |
| Concurrency | Prone to data corruption from write conflicts. | Optimistic Concurrency Control to safely manage simultaneous writes. |
| Performance | Fast data scans, but bottlenecked by slow file listing operations. | Fast scans plus fast query planning via indexed manifest files. |
Introduction
The initial promise of the data lake was revolutionary. In the early days of big data, organizations were promised a single, scalable, and cost-effective repository for all of their data—structured and unstructured. Using commodity cloud storage like Amazon S3 or Azure Data Lake Storage, you could store exabytes of data in open formats like Parquet, freeing yourself from the expensive, proprietary constraints of traditional data warehouses. The promise was a unified reservoir of all enterprise data, ready for any analytical workload. The reality, for many, was a data swamp.
A data lake built on a simple collection of files and directories is fundamentally brittle. The metadata—the information about the data—was often managed by a Hive-style catalog, which did little more than map a table name to a directory path. This design was rife with failure modes. A Spark job that failed halfway through writing to a partition left the data in a corrupted, inconsistent state. Trying to change a table's schema was an operational nightmare, often requiring a complete and costly rewrite of every file. Concurrent writes from different processes would silently overwrite each other, leading to lost data. Without the transactional guarantees of a database, data reliability was not a given; it was a constant, fragile effort.
This created a severe business problem. As organizations sought to run mission-critical analytics and BI directly on the lake, they demanded the same reliability they had in their data warehouses: ACID compliance, predictable performance, and trustworthy data. The economics of the cloud met the reliability requirements of the enterprise, and the traditional data lake architecture buckled under the pressure.
This is precisely why the discussion of Parquet and Iceberg is so critical today. The industry is rapidly converging on the Data Lakehouse architecture—a new model that delivers data warehouse capabilities directly on the open, low-cost foundation of a data lake. Table formats like Iceberg are the enabling technology for this shift. They provide the missing layer of management and reliability that transforms a fragile collection of files into a robust, governable, and performant data asset.
Iceberg doesn't just improve the data lake; it makes it dependable.
Background & Evolution
To grasp the relationship between Parquet and Iceberg, we must understand their distinct roles and the evolutionary path that connected them. One is a raw material optimized for storage; the other is the sophisticated logistics system required to manage that material at scale.
What is Apache Parquet?
Before Parquet, analytical queries on data lakes were often slow and expensive. Row-based formats like CSV or Avro were the norm, and they created a significant I/O bottleneck. If you wanted to calculate the average of a single column from a table with 100 columns, the query engine had no choice but to load all 100 columns from disk into memory. This was wildly inefficient.
Apache Parquet was engineered to solve this problem directly through columnar storage.
Let's make this concrete with an analogy. Imagine a massive retail inventory spreadsheet.
-
A row-based format is like reading this spreadsheet one product (row) at a time, from left to right: Product ID, Name, Category, Price, Stock Quantity. To find the average price of all products, you must read every piece of information for every single product.
-
A columnar format like Parquet organizes the data by column. All Product IDs are stored together, all Names are stored together, and all Prices are stored together. To find the average price, the engine reads only the price data, completely ignoring the other columns.
This approach has two profound benefits:
-
Drastic I/O Reduction: Queries only read the columns they need, which is the foundation of high performance in analytical systems.
-
Superior Compression: When similar data types are stored together (e.g., a block of integers or a block of text), they can be compressed far more effectively than a row of mixed data types.
Combined with features like predicate pushdown, which allows engines to skip entire blocks of data that don't match query filters, Parquet became the de-facto standard for storing analytical data-at-rest. It is the perfect, highly optimized storage container for big data.
Row-based storage

Column-based storage
What is Apache Iceberg?
While Parquet optimized the files, a critical problem remained: how do you manage a table made of millions, or even billions, of individual Parquet files? The standard solution, the Hive Metastore, was little more than a pointer to a top-level directory. It offered no transactional integrity and no mechanism for tracking the state of a table over time. A collection of Parquet files in a directory is not a reliable table; it is a brittle collection of assets.
Apache Iceberg is the solution to this management crisis. It is an open table format specification, not a storage engine or a file format. It does not replace Parquet. Instead, it creates a structured metadata layer on top of it.
Think of it this way: if Parquet files are individual books in a library, the old Hive system was just a sign pointing to the "Fiction" section. Iceberg, by contrast, is the master librarian's ledger. This ledger doesn't contain the books themselves, but it meticulously tracks the exact state of the library at any given moment: which specific books (files) make up the current collection, where they are located, and a complete history of every book ever added or removed.
Iceberg provides the source of truth for what data constitutes the table at any point in time.
The Paradigm Shift
The central innovation Iceberg introduces is the decoupling of the logical table from the physical data files. This is the key to providing mutability without sacrificing reliability.
-
The Old Way (Hive-style): The table was the directory. The physical layout of the files and folders (e.g.,
/year=2024/month=10/) defined the table's structure. This tight coupling was fragile. AnUPDATEoperation meant dangerously modifying files in place (or creating a combination of delete and insert files which need to be processed on query), and changing the partition scheme required a complete, expensive rewrite of the entire table. -
The New Way (Iceberg): The logical table is defined by a master metadata file that points to a specific list of underlying data files. The physical location of these Parquet files is irrelevant. When you perform an
UPDATE,DELETE, orMERGEoperation, Iceberg does not change the existing data files. Instead, it creates new Parquet files with the updated data and then commits a new version of the metadata. This commit atomically swaps the table's pointer from the old metadata file to the new one.
This architecture provides the best of both worlds: the underlying data files are treated as immutable, preventing corruption, while the table itself is logically mutable, allowing for DML operations. It's like using a domain name for a website instead of a hardcoded IP address. Yet another analogy could be this: the domain name (the logical table) is constant and easy to work with, while the underlying server IP (the physical file locations) can change seamlessly without disrupting the user.
This decoupling is the architectural key that unlocks database-like features on the data lake. It is the foundation for ACID transactions, safe schema evolution, and time travel.
Architectural Foundations
The relationship between Iceberg and Parquet is a perfect example of a layered architectural design, where each component has a distinct and well-defined responsibility. Parquet handles the physical storage of data with maximum efficiency, while Iceberg provides the logical management and transactional control. This separation of concerns is what makes the entire system so robust and performant.
Apache Iceberg Architecture
Let's dissect this architecture layer by layer.
Parquet's Role: The Data Layer
At the very bottom of the stack, we have the Parquet files. This is the physical data layer. Iceberg is not a file format; it wisely delegates the complex task of data storage to the proven industry standard. When you write data to an Iceberg table, you are creating Parquet files that benefit from all its native features: columnar storage, efficient compression, and predicate pushdown filtering.
Think of Parquet as the shipping containers in a global logistics network. They are standardized, secure, and optimized for efficiently holding the actual goods (the data). Iceberg is the logistics system that tracks where every single container is, what it contains, and which containers constitute the current shipment.
Iceberg's Role: The Metadata & Transaction Layer
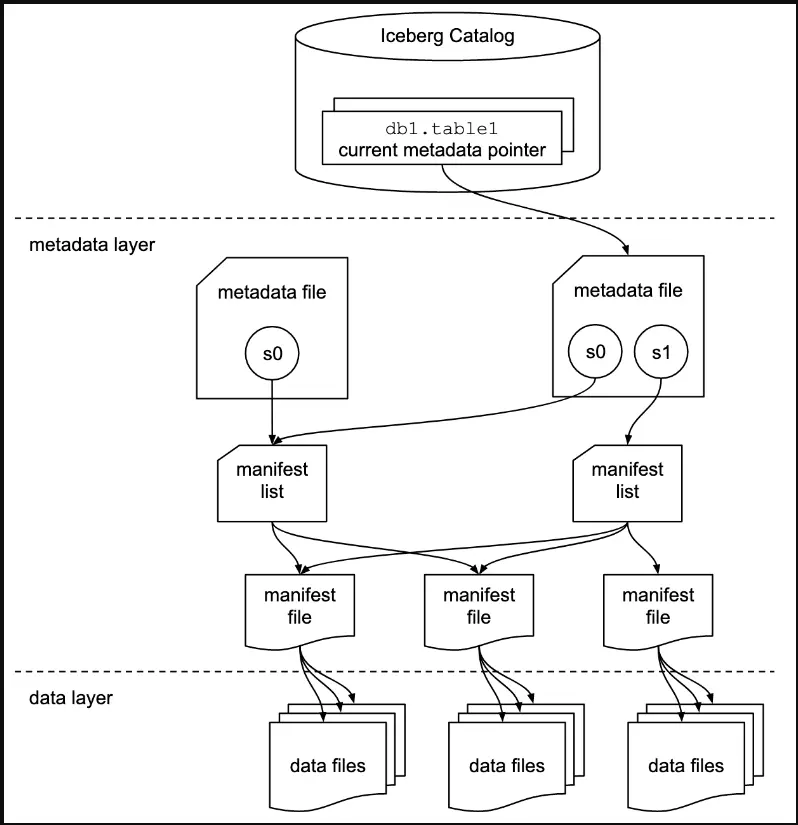
Iceberg's contribution is a sophisticated, multi-level hierarchy of metadata that imposes order on the chaos of raw data files. This hierarchy is not accidental; it is a masterclass in distributed systems design, engineered to provide performance and transactional guarantees. It consists of three primary components.
The Catalog
A query engine's first question is always, "Where is the current, authoritative state of this table?" The Catalog is the answer. It is the single source of truth that stores a reference, or pointer, to a table's current master metadata file.
The catalog is the front desk of a secure archive. You don't wander the halls looking for a document; you go to the front desk and ask for the "Q4-2025 Financial Report." The receptionist looks up its current location in a central registry and gives you a precise pointer to file_v3.json. This central registry is the catalog.
The catalog provides the atomic mechanism for commits. When a write operation completes, the transaction is finalized by atomically swapping the pointer in the catalog from the old metadata file to the new one. This ensures that readers always see a complete and consistent version of the table. Common implementations include the Hive Metastore, AWS Glue Catalog, or Project Nessie.
The catalog provides the atomic guarantee for all table operations.
Metadata Files
The pointer from the catalog leads to a single, top-level metadata file. This is a JSON file that acts as the table's historical ledger. It contains critical information such as:
- The table's current schema.
- The partition specification (how the data is logically organized).
- A list of all historical snapshots of the table.
Each snapshot represents a version of the table at a specific point in time and points to a manifest list that defines its state.
Continuing the analogy, if the catalog points you to the main binder for the "Financial Reports", the metadata file is the table of contents for that entire binder. It shows you the schema (the column headers used) and a history of revisions: "Version 1 (Oct 10), Version 2 (Oct 11), Version 3 (Oct 12)."
This file is the anchor for time travel and schema evolution.
Manifest Lists & Manifest Files
This is the secret to Iceberg's performance at scale. Recursively listing millions of Parquet files in cloud storage is a notorious performance bottleneck. Iceberg solves this by creating its own index.
-
A Manifest List is a file that contains a list of all Manifest Files that make up a snapshot. Each entry includes metadata about the manifest file, such as the data partition it tracks and statistics about its contents.
-
A Manifest File contains the list of the actual Parquet data files. Crucially, it stores column-level statistics for each Parquet file, such as the minimum and maximum values for each column within that file.
Continuing the analogy, the manifest list is like the chapter index in our report binder ("Chapter 1: North America, Chapter 2: Europe"). The manifest file is the detailed index for a specific chapter. The index for "Chapter 1: North America" doesn't just list the page numbers (the Parquet files); it includes a summary for each page, like "contains sales data where country=USA and revenue is between $100 and $5,000."
During query planning, the engine uses the statistics in these manifest files to perform aggressive data pruning. If you query for revenue > $10,000, the engine can read the manifest's summary and know, without ever touching the actual data file, that it can be completely skipped.
Manifests transform a slow file-listing problem into a fast, indexed metadata lookup.
Key Feature Showdown
The architectural layers we've dissected are not just theoretical constructs; they are the foundation for capabilities that solve the most painful and expensive problems of the traditional data lake. Moving from a raw collection of Parquet files to an Iceberg-managed table is the difference between building a fragile prototype and engineering a robust, production-ready system.
Let's make this concrete by walking through the most critical features that Iceberg unlocks.
Schema Evolution
This is arguably one of the most significant operational pain points in legacy data lakes. Business requirements change, and your table schemas must evolve with them.
-
The Old Way (Hive-style): A schema evolution nightmare. The approach was akin to a simple spreadsheet where data is identified by its position. If column C is 'Price' and you insert a new column at B, everything shifts—column C now contains 'Product Category,' silently corrupting every query. The only "safe" way to perform these changes was to launch a massive, expensive backfill job to rewrite the entire table—terabytes or even petabytes of data.
-
The New Way (Iceberg): Iceberg, in contrast, operates like a true database. It assigns a permanent, internal ID to each column. The name 'Price' is merely a human-friendly alias for that ID. You can rename it to 'Unit_Cost,' reorder it, or add new columns, and the system still fetches the correct data because it follows the immutable ID, not the fragile position or name. This makes schema changes fast, metadata-only operations. No data is touched.
Iceberg future-proofs your data model against changing requirements.
Transactional Guarantees
Data integrity is the bedrock of trust in any analytical system. Without transactional guarantees, that trust is broken.
-
The Old Way (Hive-style): The process was as risky as moving money between bank accounts by first withdrawing cash from Account A, and only then walking over to deposit it into Account B. If the job failed halfway through writing its output files, the money simply vanished, leaving the data in a corrupted, partial state and leading to incorrect reports.
-
The New Way (Iceberg): Iceberg provides full ACID compliance by treating every operation as a single, atomic bank transaction. It writes all the necessary data files first, and only after they are successfully persisted does it attempt the final commit. This commit is an atomic swap of a single pointer in the catalog. The debit and credit are committed as one unit; the operation either completes successfully or it fails entirely, leaving the original state untouched.
This transforms the lake from a best-effort system into a reliable one.
Advanced Partitioning & Pruning
Query performance at petabyte scale depends on one thing: reading as little data as possible. Iceberg introduces two revolutionary improvements here.
1. Hidden Partitioning & Partition Evolution:
-
The Old Way (Hive-style): Partitioning was physical and brittle. A directory structure like
/dt=2025-10-13/was permanently baked into your data's physical layout. If you chose to partition by day but later realized you needed hour, your only option was a full, catastrophic table rewrite. -
The New Way (Iceberg): Iceberg introduces hidden partitioning, decoupling the logical partition values from the physical file path. You can define a partition on a timestamp column using a transform like
hours(event_ts). Even better, Iceberg supports partition evolution. You can change a table's partitioning scheme at any time. New data will use the new scheme, while old data remains perfectly readable using its original scheme.
2. Data Pruning via Manifests:
-
The Old Way (Hive-style): Engines could only prune data at the partition level. If you queried for
user_id = 123but your table was partitioned by date, the engine still had to list and read every single file within the relevant date partitions. -
The New Way (Iceberg): As we saw in the architecture, manifest files contain column-level statistics for every Parquet file. When you query for
user_id = 123, the query planner reads the manifest metadata and can see that one Parquet file contains IDs from 100-200, while another contains 201-300. It knows instantly that it only needs to read the first file, dramatically reducing the amount of data scanned.
Iceberg doesn't just read less data; it plans queries smarter.
Time Travel and Version Rollback
Mistakes happen. A bug in an ETL script can write corrupted data. With traditional data lakes, recovery was a manual and stressful fire drill.
- The New Way (Iceberg): This capability effectively provides Git for your data. Every commit to an Iceberg table creates a new snapshot, which is equivalent to a
git commithash. Time travel becomes as simple asgit checkout \<snapshot_id\>, allowing you to query the table's state from last week or last year. If a bad write occurs, a full rollback is a one-linerevertcommand that instantly resets the table to the last known good state.
This is not just a feature; it is a safety net for your entire data platform.
Concurrency Control
As data platforms grow, multiple jobs will inevitably need to write to the same table simultaneously.
-
The Old Way (Hive-style): This was a recipe for silent data loss due to the "last-write-wins" problem. If two jobs tried to rewrite the same partition, the second job to finish would simply overwrite the files from the first. No error would be thrown; data would just vanish.
-
The New Way (Iceberg): Iceberg implements Optimistic Concurrency Control. When a writer is ready to commit, it tells the catalog, "I started with version V1, and here is my new version V2". The catalog will only allow the commit if the current version is still V1. If another writer has already committed (making the current version V2), the second writer's commit will fail with an exception.
Iceberg ensures data integrity by preferring a failed job over corrupted data.
Real-World Workflows
The features we've discussed are not just incremental improvements; they are enablers for entirely new ways of operating a data lake. They transform what was once a fragile, batch-oriented data repository into a dynamic, reliable, and multi-purpose data platform.
Let's examine the three most impactful workflows unlocked by the Iceberg and Parquet combination.
The Reliable Data Lakehouse
This is the quintessential use case that drives the adoption of the data lakehouse architecture. The core challenge has always been supporting mixed workloads without conflict.
The Scenario: A team of business analysts is running complex queries against a critical sales table to populate a company-wide BI dashboard. These queries need a stable, consistent view of the data to produce accurate reports. Simultaneously, a series of ETL jobs are running every 15 minutes to append new sales data and update the status of existing orders.
The Old Way (The Conflict): This scenario was a bottleneck and a source of constant failure. The BI query could start, and midway through, the ETL job would start modifying partitions. This would either cause the BI query to fail with an error or, worse, cause it to read a mix of old and new data, producing a silently incorrect report. The only solutions were rigid, brittle scheduling ("ETL jobs can only run between 2 AM and 4 AM") or complex locking mechanisms that often failed.
The New Way (The Solution): Iceberg's snapshot isolation completely resolves this conflict. When the BI query begins, the engine locks onto the current table snapshot (e.g., Snapshot A). It will see a perfectly consistent version of the table from that moment in time for the entire duration of the query. In the meantime, the ETL jobs can commit multiple new snapshots (Snapshot B, C, and D). These commits happen independently and do not affect the BI query's view of the world. Once the BI query is finished, the next one will automatically see the latest version, Snapshot D.
This provides true read/write isolation, a cornerstone of any serious database, directly on the low-cost object storage of the data lake.
The Compliant Data Lake
Data privacy regulations like GDPR and CCPA introduced the "right to be forgotten", a requirement that was operationally impossible for traditional data lakes to handle efficiently.
The Scenario: A long-time customer submits a request to have all of their personal data deleted. This customer has placed hundreds of orders over the past five years. Their records are scattered across dozens of partitions (e.g., partitioned by order_month) and hundreds of large Parquet files within a petabyte-scale orders table.
The Old Way (The Nightmare): To fulfill this single request, you would have to launch a massive and destructive rewrite job. For every single partition this customer has ever placed an order in, you would need to read all the data for all customers, filter out the specific order records for the requesting customer, and then rewrite the entire partition. This meant rewriting terabytes of data just to delete a few kilobytes, a process that was brutally expensive, took hours or days, and carried a high risk of failure.
The New Way (The Surgical Deletion): Iceberg supports row-level deletes. A single command (DELETE FROM orders WHERE customer_id = 'abc-123') initiates an efficient, metadata-driven process. Iceberg uses its manifest files to quickly identify only the Parquet files that contain records for this customer. It then creates small, lightweight delete files that essentially act as markers, instructing the query engine to ignore those specific rows in those data files. The original data files are not touched. The physical removal of the marked rows is handled later by a rewrite_data_files (compaction) procedure during a scheduled, low-cost maintenance window.
Iceberg transforms a compliance mandate from a costly, disruptive project into a manageable and efficient background operation.
The Streaming-Ready Lake
Getting fresh, real-time data into the lake has always been at odds with maintaining good query performance.
The Scenario: You want to ingest data from a real-time source like Apache Kafka directly into a data lake table to reduce data latency for analytics from hours to seconds. This requires committing new data every few seconds or minutes.
The Old Way (The Small File Problem): This pattern is poison for a traditional data lake. Committing every few seconds would create millions of tiny Parquet files. When an analyst queries this data, the query engine spends more time opening and closing these millions of files than it does actually reading data, leading to extremely poor performance.
The New Way (Decoupled Ingestion and Optimization): Iceberg is engineered to handle frequent, small commits with grace. Each micro-batch is committed as a new, atomic snapshot, making the data available for query within seconds. While this still creates small files, Iceberg provides the tools to solve the problem asynchronously. A separate, scheduled compaction job can run in the background. This job will efficiently scan for small files within a partition, combine them into larger, optimally-sized Parquet files, and commit the result as a new, clean snapshot that replaces the smaller files.
Iceberg decouples the act of ingestion from the act of optimization. This allows you to achieve low-latency data availability without sacrificing the high-throughput query performance that large files provide.
Decision Matrix
Adopting a table format is a deliberate architectural choice. While powerful, it introduces a layer of metadata management that is only justified if it solves a clear and present set of problems. Use the following matrix to map your project's requirements to the appropriate technology. The more your needs align with the right-hand column, the stronger the case for adopting Iceberg.
| Criteria | Raw Parquet Architecture | Iceberg Table Format Architecture | |--||--| | Schema Volatility | Best for static schemas that rarely or never change. | Designed for agile environments where schemas evolve frequently (adding, renaming, or reordering columns). | | Concurrency | Suited for simple, single-writer batch ETL workflows. | Essential for complex workloads with multiple concurrent writers, streaming ingest, and user-driven updates. | | Data Reliability | Acceptable if occasional inconsistencies from failed jobs can be tolerated or handled downstream. | Required when ACID guarantees are non-negotiable for mission-critical reporting and BI. | | Audit & Compliance | Sufficient when there is no business need to query historical data versions. | Required for use cases demanding time travel for audits, debugging, or instant rollbacks to a previous state. | | Performance at Scale | Performant for small-to-medium datasets where partition-level scans are fast enough. | Crucial for petabyte-scale tables where aggressive, file-level data pruning is necessary for query performance. | | Workload Type | Optimized for append-only batch data ingestion. | Built to handle a mix of batch, streaming, and DML operations like UPDATE, DELETE, and MERGE. |
This matrix serves as a pragmatic guide. If your project's characteristics fall predominantly in the right-hand column, a table format like Iceberg is no longer a "nice-to-have"; it is a foundational requirement for a robust and future-proof data platform.
Migration Playbook
Once you have determined that an Iceberg table format is necessary, the next phase is execution. The goal is to perform this transition with minimal disruption and maximum benefit, transforming your existing data assets into a more reliable and performant foundation.
Pre-Migration Audit & Catalog Selection
Before moving a single byte of data, you must perform two foundational steps.
1. Analyze Existing Assets: Audit your current Hive/Parquet tables. Understand their partitioning schemes, the average file sizes, and the data layouts. This analysis is critical because it will inform which migration strategy is most appropriate. A table with a clean partition scheme and well-sized files is a better candidate for an in-place migration than a table riddled with small files.
2. Choose Your Catalog: The Iceberg catalog is the central nervous system of your new architecture. It stores the pointer to the current state of each table. This choice is pivotal. Common options include the AWS Glue Catalog, the existing Hive Metastore, or a transactional catalog like Project Nessie. Your selection will depend on your cloud provider, existing infrastructure, and need for advanced features like multi-table transactions. Choose your catalog wisely; it is the new foundation.
Migration Strategies: In-Place vs. Shadow
There are two primary strategies for migrating a Hive/Parquet table to Iceberg. The choice is a trade-off between speed and optimization.
The In-Place Migration
This strategy involves creating an Iceberg table definition and then registering your existing Parquet files into the Iceberg metadata without rewriting them.
-
The Concept: This is the faster, lower-cost approach. It's like an archivist discovering a vast collection of historical documents and creating a modern, digital card catalog for them. The documents themselves don't move or change, but they are now officially tracked and managed by a new, more robust system. You use Iceberg procedures like
add_filesormigrateto scan the existing directory structure and create the initial manifest files. -
When to Use It: Ideal for large tables where a full rewrite would be prohibitively expensive and the existing data layout is "good enough".
-
Pros: Extremely fast and requires minimal compute resources.
-
Cons: The new Iceberg table inherits the existing physical layout, including any pre-existing small file problems or suboptimal partitioning.
In-place migration is about bringing modern management to your existing data.
The Shadow Migration
This strategy involves creating a new, empty Iceberg table and populating it by reading all the data from the old Hive table using a CREATE TABLE ... AS SELECT ... (CTAS) statement.
-
The Concept: This is the slower but cleaner approach. It is akin to building a brand-new, state-of-the-art library next to the old one. You then move every book over, but in the process, you organize them perfectly, repair any damaged ones, and place them on shelves designed for optimal access. The CTAS operation reads all your old data and writes it into a new, perfectly optimized Iceberg table with ideal file sizes and a clean partition scheme.
-
When to Use It: Best for critical tables where performance is paramount, or when the original table is poorly structured and a clean slate is desired.
-
Pros: Results in a perfectly optimized table from day one.
-
Cons: The migration process can be slow and compute-intensive, as it requires a full scan and rewrite of the entire source table.
Shadow migration is about rebuilding your data for optimal future performance.
Common Pitfalls to Avoid
A successful migration requires avoiding these common operational mistakes.
1. Forgetting Post-Migration Optimization: Especially after an in-place migration, you have inherited the old file layout. It is critical to immediately schedule regular compaction jobs (e.g., rewrite_data_files). These jobs will run in the background, combining small files into larger, more optimal ones, gradually erasing the technical debt of your old table structure.
2. Misconfiguring the Catalog Connection: The connection between your query engine (like Spark or Trino) and your chosen Iceberg catalog is the most critical configuration. A misconfigured or incorrect catalog pointer is the most common source of errors. This connection must be rigorously tested and validated, as it is the single entry point to all of your tables.
A migration is a one-time cost that pays dividends in reliability and performance for years to come.
Performance & Cost Tuning
Simply migrating to Iceberg provides immediate reliability. However, achieving peak query performance and cost-efficiency requires active governance of your data's physical layout. Operations like streaming ingestion and frequent updates, while enabled by Iceberg, naturally lead to a suboptimal file structure over time. Tuning is the disciplined process of refining this structure.
Let's tune the engine.
Optimizing File Layouts
The physical arrangement of your data files has the single biggest impact on query speed. An unmanaged table will accumulate small files and an inefficient data layout, leading to slow scans and wasted compute.
Compaction (Bin-Packing): Streaming and DML operations often create a large number of small files. This is a notorious performance bottleneck for any file-based system, as the overhead of opening and reading metadata for each file outweighs the time spent reading data. Compaction is the process of intelligently rewriting these small files into larger, optimally-sized ones (typically aiming for 512MB - 1GB). This is the equivalent of a librarian taking dozens of loose-leaf pamphlets and binding them into a single, durable book. It is a routine maintenance task, essential for table health.
Sorting (Z-order): Standard compaction organizes data by size, but sorting organizes it by content. By sorting the data within files based on frequently filtered columns, you co-locate related records. Advanced techniques like Z-order sorting do this across multiple columns simultaneously. This dramatically enhances the effectiveness of data pruning. If your data is sorted by user_id and event_timestamp, a query filtering on a specific user and time range can skip massive numbers of files because the query engine knows, from the manifest metadata, that the relevant data is clustered together in just a few files.
File Sizing: The goal of compaction is to produce files of an optimal size. The ideal size is a trade-off: large enough to minimize the overhead of file-open operations and maximize read throughput from cloud storage, but not so large that predicate pushdown becomes ineffective. For most analytical workloads, targeting a file size between 512MB and 1GB is the industry-standard best practice.
Effective file layout is the foundation of a performant lakehouse.
Fine-Tuning Parquet Settings
Iceberg manages the table, but Parquet controls the internal structure of the data files themselves. Tuning these internal settings provides another layer of optimization.
Row Group Size: A Parquet file is composed of multiple row groups. This is the unit at which data can be skipped. Think of a Parquet file as a large shipping container, and row groups are the smaller, individually labeled boxes inside. A larger row group size (e.g., 256MB or 512MB) is excellent for scan-heavy workloads as it allows for large, sequential reads. A smaller size may be better if your queries are highly selective, as it allows the engine to skip data with more granularity.
Compression Codecs: The choice of compression impacts both storage footprint and CPU usage. Snappy is the default for a reason: it is extremely fast to decompress and offers good compression ratios. ZSTD, on the other hand, provides a much higher compression ratio but requires more CPU to decompress. The choice is a direct trade-off: use Snappy when query speed is paramount (CPU-bound workloads), and consider ZSTD when minimizing storage costs or network I/O is the primary concern (I/O-bound workloads).
Tuning Parquet is about optimizing the efficiency of every I/O operation.
Analyzing Table Metadata
You cannot optimize what you cannot measure. One of Iceberg's most powerful and underutilized features is its set of metadata tables. These are special, readable tables (e.g., my_table.files, my_table.manifests, my_table.partitions) that provide a direct view into the internal state of your main table.
This is the equivalent of the librarian using their own ledger to run analytics on the library itself. You can write standard SQL queries against these metadata tables to diagnose performance problems.
-
Need to find partitions with too many small files?
SELECT partition, COUNT(1), AVG(file_size_in_bytes) FROM my_table.files GROUP BY partition; -
Want to see how your data is distributed across files?
SELECT file_path, record_count FROM my_table.files;
These tables are the primary tool for an architect to validate that compaction and sorting strategies are working as intended. They provide the visibility required for true data governance.
Of course. We are approaching the conclusion of our architectural blueprint. Before the final summary, it is essential to address the common, practical questions that arise during implementation. This section serves as a direct, authoritative reference to clarify key distinctions and operational realities.
FAQ: People Also Ask
Is Iceberg a replacement for Parquet?
No. This is the most fundamental misconception. Iceberg does not replace Parquet; it organizes it. They operate at two different architectural layers to solve two completely different problems.
Let's make this concrete. Think of your data lake as a massive digital music library.
-
Parquet files are the individual MP3 files. Each one is a perfectly encoded, high-fidelity container for the actual music—your data. It is the raw asset.
-
Iceberg is the playlist. The playlist file itself contains no music. It is a simple metadata file that points to the specific MP3s that constitute your "Workout Mix". It provides the logical grouping, the name, and the order.
You can add or remove a song from the playlist (a transaction) or see what the playlist looked like last week (time travel) without ever altering the underlying MP3 files. Iceberg is the management layer; Parquet is the storage layer.
Can you use Iceberg with other file formats like ORC or Avro?
Yes, absolutely. The Iceberg specification is file-format-agnostic. While it is most commonly used with Apache Parquet for analytical workloads due to Parquet's columnar performance benefits, it is fully capable of managing tables composed of Apache ORC or Apache Avro files. This flexibility is a core design principle, ensuring that the table format does not lock you into a single storage format.
What are the main differences between Iceberg, Delta Lake, and Hudi?
All three are open table formats designed to solve similar problems (ACID transactions, schema evolution, time travel). The primary differences lie in their design philosophy and underlying implementation.
-
Apache Iceberg: Prioritizes a universal, open specification with zero engine dependencies. Its greatest strengths are fast query planning at massive scale (via its manifest file indexes) and guaranteed interoperability. It is architected to avoid the "list-then-filter" problem that can plague other formats on petabyte-scale tables, making it a robust choice for multi-engine, large-scale data lakehouses.
-
Delta Lake: Originated at Databricks and is deeply integrated with the Apache Spark ecosystem. It uses a chronological JSON transaction log (
_delta_log) to track table state. It is often considered the most straightforward to adopt if your organization is already standardized on Databricks and Spark. -
Apache Hudi: Originated at Uber with a strong focus on low-latency streaming ingest and incremental processing. It offers more granular control over the trade-off between write performance and read performance through its explicit Copy-on-Write and Merge-on-Read storage types.
The choice is one of architectural trade-offs. Iceberg is built for interoperability and scale, Delta for deep integration with Spark, and Hudi for fine-grained control over streaming workloads.
Does using Iceberg add significant performance overhead?
On the contrary, for any non-trivial table, Iceberg provides a significant performance improvement.
The perceived "overhead" is the storage of a few extra kilobytes of metadata files. The problem it solves is the primary performance bottleneck in cloud data lakes: recursively listing the millions of files that make up a large table. This LIST operation is notoriously slow and expensive.
Iceberg avoids this entirely by using its manifest files as a pre-built index of the table's data files. The query engine reads this small index to find the exact files it needs to scan, transforming a slow file-system operation into a fast metadata lookup. It trades a negligible amount of storage for a massive gain in query planning speed.
How does Iceberg handle row-level deletes on Parquet files?
It's critical to remember that Parquet files are immutable. Iceberg never changes an existing Parquet file. Instead, it handles deletes using a metadata-driven, merge-on-read approach.
When a DELETE command is issued, Iceberg creates lightweight delete files. These files store the path to a data file and the specific row positions within that file that are marked for deletion. At query time, the engine reads both the original Parquet data file and its associated delete file, merging them on the fly to present a view of the data where the deleted rows are filtered out.
Think of it as an errata slip published for a book. The original book text is not altered, but the slip tells the reader to ignore a specific sentence on a specific page. The process of making this deletion permanent by rewriting the data files is handled by a separate, asynchronous compaction job.
Conclusion
We began this discussion by dissecting the broken promise of the first-generation data lake—a system that offered immense scale but was fundamentally brittle, unreliable, and operationally expensive to manage. The root of this fragility was its architecture: a simple collection of files in a directory is not a database. It lacks the transactional integrity, the metadata intelligence, and the structural flexibility required for mission-critical work.
Apache Parquet solved the first part of the problem. It gave us the perfect storage container—a highly-compressed, columnar file format optimized for fast analytical scans. It is the ideal physical layer. But a pile of perfect bricks does not make a robust building; it requires a blueprint.
That blueprint is Apache Iceberg.
Iceberg provides the missing management layer. It is the architectural specification that transforms a static collection of Parquet files into a dynamic, reliable, and governable table. By decoupling the logical table from the physical data, Iceberg introduces the database-like guarantees that were once the exclusive domain of traditional data warehouses: ACID transactions, safe schema evolution, time travel, and efficient DML. It makes the data lakehouse not just a concept, but a production-ready reality.
Therefore, the architectural conclusion is clear. The question is not Parquet versus Iceberg. It is, and has always been, Parquet with Iceberg.
For any serious data lake initiative that demands reliability, performance, and agility, the choice is no longer if you should adopt a modern table format. The only question is how you will leverage a format like Iceberg to unlock the true potential of your data. To build a future-proof data platform, you need both the optimal storage container and the master blueprint, i.e. Parquet with Iceberg!
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.