MongoDB CDC with Debezium & Kafka | Real-Time Data Streaming

If you're into the world of data replication or streaming and wondering how to move your MongoDB data into a data warehouse or lakehouse, this article might shed some light into in’s and out’s of considering Debezium.
Let's look out over Debezium and Apache Kafka, and see how they can be helpful for Change Data Capture (CDC). Grab your favorite beverage, and let’s break this down in a way that makes total sense.
Understanding Change Data Capture (CDC)
What is CDC?
Alright, let’s start with the basics. Change Data Capture (CDC) is like having an attentive assistant that watches your database for any changes—whether it's adding new records, updating existing ones, or deleting stuff.
Instead of periodically checking (which can be inefficient and slow), CDC captures these changes in real-time and makes them available for other systems to use. Think of it as a live news feed of your database’s activity.
Why Should You Care About CDC?
Imagine you're running an online store. Every time someone makes a purchase, you want that data to instantly reflect in your analytics dashboard, inventory system, and maybe even trigger some marketing emails.
Without CDC, you’d have to batch process these changes, leading to delays and potential inconsistencies. CDC makes sure that every change is captured and propagated immediately, keeping everything in sync. One of the main challenges without CDC is you need to have a proper bookmark column using which you can track new incremental records and also there is no way to track deletes.
Different Flavours of CDC
CDC isn't one-size-fits-all. There are various methods to implement it, each with its own pros and cons:
-
Log-Based CDC: This method reads the database’s transaction logs (like the
oplogin MongoDB). It’s efficient because it leverages the database’s internal mechanisms to track changes. -
Trigger-Based CDC: Here, you set up database triggers that activate on data changes. While straightforward, it can add overhead to your database operations.
-
Timestamp-Based CDC: This involves periodically checking records’ timestamps to find changes. It’s simpler but can miss changes or require complex logic to handle deletions.
-
Query-Based CDC: Similar to timestamp-based but relies on specific queries to detect changes. It’s the least efficient and most error-prone.
For our purposes, log-based CDC is the star of the show because of its real-time capabilities and minimal performance impact.
Real-World Applications
CDC is everywhere once you realize its potential:
-
Data Warehousing: Keep your data warehouse updated with the latest transactional data without lag.
-
Microservices: Ensure that different microservices have consistent and up-to-date data.
-
Event-Driven Architectures: Trigger events based on data changes to drive workflows or notifications.
In essence, CDC is the backbone of modern, responsive data architectures.
Introduction to Debezium and Kafka
What is Debezium?
Enter Debezium, an open-source CDC platform that plays really well with databases and streaming platforms like Kafka. Think of Debezium as the bridge that watches your database’s transaction logs and translates those changes into events that Kafka can understand and distribute. It’s like having a translator who converts your database’s whispers into a loudspeaker broadcast.
Debezium Architecture:
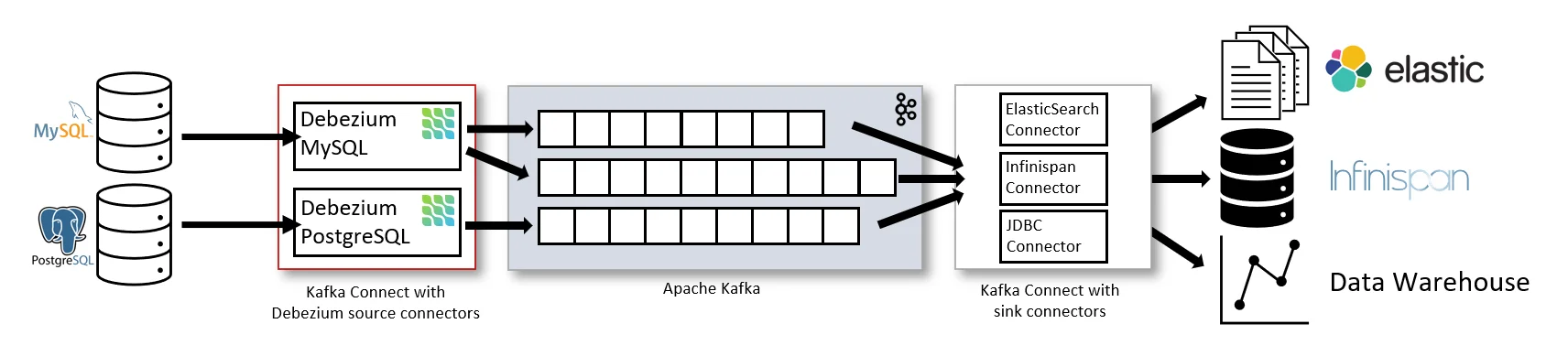
image source: debezium official docs
What is Kafka?
Now, let’s talk about Apache Kafka. If you’re not familiar, Kafka is this great distributed event streaming platform. Picture it as a high-throughput messaging system where producers send messages (events) to topics, and consumers read from those topics.
It’s designed for speed, scalability, and reliability, making it perfect for handling real-time data streams.
How Debezium and Kafka work Together
When you combine Debezium with Kafka, you get a powerful setup:
-
Debezium Monitors Your Database: It hooks into MongoDB’s
oplog(operation log) and keeps an eye on every change happening in your database. -
Debezium Converts Changes to Events: Every insert, update, or delete operation is transformed into a Kafka event. These events contain all the necessary information about what changed and how.
-
Kafka Distributes the Events: Kafka takes these events and streams them to various consumers—be it your data warehouse/lakes, analytics tools, or other microservices.
This combo ensures that your data changes are captured in real-time and are instantly available wherever you need them, well not always (we will discuss why this might not be the best approach below).
Why Use Debezium and Kafka Together?
-
Scalability: Both Debezium (built on top of kafka connect to capture changes from databases and stream them into Apache Kafka) and Kafka are built to scale horizontally. Whether you’re dealing with a few changes a minute or thousands per second, they can handle it most of the time.
-
Flexibility: You can route your data changes to multiple destinations simultaneously. Need to update your data warehouse and trigger a notification system? No problem.
-
Reliability: Kafka’s robust architecture ensures that your events are stored durably and can be replayed if needed. Debezium ensures that no change misses out.
How Debezium Captures Changes from MongoDB
There are a few ways to do this, but the best way is to read from:
1. Directly oplogs
Alright, let’s get into the nitty-gritty of how Debezium actually takes out changes in MongoDB. MongoDB has this feature called the oplog. Think of the oplog as MongoDB’s diary where it records every single write operation—whether it's an insert, update, or delete. This is crucial for replication and, of course, for tools like Debezium to tap into.
2. Via Change streams (based on oplogs only)
But there’s more! MongoDB also offers Change Streams, which provide a real-time feed of these changes. Essentially, Change Streams leverage the oplog under the hood to push changes as they happen, making it a good fit for CDC.
The primary distinction is that the connector does not directly read from the oplog. Instead, it relies on MongoDB's change streams feature to capture and decode oplog data.
We will discuss about change streams in further sections.
How Debezium Uses the Oplog?
So, how does Debezium make use of the oplog? Here’s the breakdown:
-
Connecting to the Oplog: Debezium connects to the MongoDB replica set’s oplog (or sharded cluster’s). Would not work on standalone deployment of MongoDB.
-
Using a Cursor to Track Position: Debezium employs a cursor to keep track of where it left off in the oplog. Imagine it as bookmarking the last read entry so that if something goes wrong or if it restarts, it knows exactly where to pick up without missing a beat.
-
Reading New Entries: As new operations get logged in the oplog, Debezium reads them in real-time. It’s like having a vigilant librarian who immediately notes down every new book that comes into the library.
-
Transforming to Events: These oplog entries are then transformed into structured events. Each event contains details about what changed, including the operation type (insert, update, delete), the affected document, and metadata like timestamps.
Below is the change event structure:
{ "schema": { ... }, "payload": { ... }, "schema": { ... }, "payload": { ... }, }
Key - Schema (schema)
-
Description: Defines the structure of the event key.
-
Purpose: Specifies how the key data is organized, helping consumers understand the key's structure.
Key - Payload (payload)
-
Description: Contains the actual key data. Part of the event key.
-
Purpose: Identifies the specific document that was changed (e.g., the document's unique
ID).
Value - Schema (schema)
-
Description: Defines the structure of the event value.
-
Purpose: Describes how the change data is organized, including any nested fields.
Value - Payload (payload)
-
Description: Contains the actual data of the changed document. Part of event value.
-
Purpose: Provides the details of the change, such as the inserted, updated, or deleted fields and their new values.
- Publishing to Kafka: Finally, these events are published to specific Kafka topics. Each collection in MongoDB typically maps to its own Kafka topic, making it super organized and easy to manage downstream.
Things to note about oplog configuration:
-
The oplog is a capped collection with a fixed size. When it reaches its maximum capacity, it overwrites the oldest entries.
-
If the connector is stopped and later restarted, it will try to resume streaming from the last recorded oplog position and the marker for that is maintained by something called a cursor (talked in detail below).
-
If the oplog has overwritten that last position, the connector may fail to restart, showing an "invalid resume token" error.
-
The snapshot.mode setting in the connector determines the behavior upon restart. If set to "
initial," the connector may fail and require a new setup to resume capturing changes. This means that you have to resync/re-snapshot the data if it fails ONLY because of losing the CDC cursor.
The Role of Change Streams
While Debezium primarily relies on the oplog for capturing changes, it’s worth mentioning Change Streams. Change Streams provide a more abstracted and user-friendly way to access the oplog data without dealing directly with the complexities of the oplog format.
However, under the hood, Debezium is still interacting with the oplog (via change streams) to fetch these changes.
MongoDB Replication Basics
MongoDB uses a replication mechanism to ensure your data is safe and always available. Here’s a simple breakdown:
-
Replica Set:
-
A group of MongoDB servers that all hold copies of the same data.
-
The oplog here is a special MongoDB collection (oplog.rs in replica sets) that records all insert, update, and delete operations
-
Primary Server: The main server where all writes happen.
-
Secondary Servers: These servers copy the data from the primary to keep everything in sync.
-
-
How Replication Works:
-
The primary server records every change in its oplog.
-
Secondary servers read the primary’s oplog and apply those changes to their own data.
-
If you add a new server to the replica set, it first copies all the existing data and then keeps up with the latest changes by reading the oplog.
-
Will Debezium sync my new collection / table?
In case there is a new collection/table that needs to be synced, under normal circumstances Debezium syncs incremental changes only, but if there is a possibility that the initial snapshot has become stale, lost, or incomplete, there is an option to trigger ‘ad-hoc snapshot’.
When you start an ad hoc snapshot for an existing collection, the connector adds data to the existing topic for that collection. If the topic was previously deleted, Debezium can automatically create a new one, provided automatic topic creation is enabled.
Modify the connector configuration if you have added a new table.
{
"type": "incremental", // or “blocking”
"data-collections": [
"Sales_db.orders", // format database.collection
"sales_db.customers",
"inventory_db.products"
]
}
Example of an ad hoc execute-snapshot signal record.
Value: "blocking": Specifies that a blocking snapshot should be performed. This type of snapshot ensures that all CDC operations are paused until the snapshot is fully captured, providing a consistent state of the data.
In other words, “A blocking snapshot behaves just like an initial snapshot, except that you can trigger it at run time.”
Value: "incremental": Start an ad hoc incremental snapshot by sending an execute-snapshot signal to the signaling collection or a Kafka signaling topic. Debezium will then partition each collection into key-based chunks and sequentially perform the snapshot for each chunk.
How Change Streams work with Debezium?
Debezium can use Change Streams to monitor and capture changes in MongoDB without directly accessing the oplog. Here’s how it works:
-
Change Streams:
-
MongoDB’s Change Streams provide a real-time feed of changes happening in your collections.
-
Debezium listens to these change streams to get updates on data modifications.
-
-
How ?
-
Initial Setup:
-
When Debezium first connects, it starts the initial snapshot of the database.
-
It then takes a snapshot of the current state of the database.
-
After the snapshot, Debezium starts listening to the change stream from where it left off.
-
-
Continuous Monitoring:
-
As changes occur in MongoDB, Change Streams send these updates to Debezium.
-
Debezium records the position of each change to ensure nothing is missed.
-
-
Handling Connector Operations
Debezium’s MongoDB connector is designed to be quite resilient and reliable. Here’s how it manages different scenarios:
-
Resuming After a Stop:
-
If the connector stops for any reason, it remembers the last change it processed.
-
When it restarts, it picks up right where it left off, ensuring no data is lost.
-
-
Managing Oplog Size:
-
The oplog has a limited size, so if Debezium is stopped for too long, some changes might be removed.
-
In such cases, Debezium takes another snapshot and resumes streaming from the latest changes.
-
Note: This might take a long time if the initial snapshot size is of too big of a collection.
-
-
Handling Replica Set Changes:
-
Primary Election: If the primary server changes (due to a failure or maintenance), Debezium automatically connects to the new primary and continues streaming changes.
-
Network Issues: If there are network problems, Debezium tries to reconnect using a smart retry strategy (called exponential backoff) to avoid overloading the network.
-
Types of CDC Involved - Log-Based CDC is the way to go!
As we touched on earlier, Debezium uses log-based CDC with MongoDB. Why? Because log-based CDC is efficient and has minimal performance impact on your database.
By reading directly from the oplog (internally), Debezium avoids the need for intrusive mechanisms like triggers or constant polling, which can be resource-heavy and slower.
How Cursors Keep Everything in Sync
Let’s talk about cursors for a moment. In the context of Debezium and MongoDB, a cursor is a pointer that keeps track of the current position in the oplog.
A cursor is returned whenever you query a collection. It points to the first document in the result and moves forward as you fetch more documents. They often have a hexadecimal ID that identifies them uniquely (e.g., 5d2b9f4c8a22).
Example:
const cursor = db.collection('products').find({ price: { $gt: 100 } });
cursor.forEach(doc => console.log(doc));
Here, cursor is an iterator over the documents in products that match the query. MongoDB uses a unique ID or token internally to keep track of the cursor’s position.
Nature and Structure of the MongoDB Cursor in CDC
-
BSON Timestamps: In MongoDB CDC with Debezium, the cursor is often represented as a BSON timestamp (combining a Unix timestamp and an increment value) that uniquely identifies each entry in the oplog.
-
Example of an oplog position:
{ ts: Timestamp(1635458412, 1) } -
ts: Represents the timestamp at which the change happened.
-
increment: Differentiates operations that happen within the same second, ensuring unique identification. Here, increment is 1
-
-
Static ID with Moving Position: The cursor doesn’t itself increment as a single value. Instead, Debezium updates the cursor position to the timestamp of the last processed oplog entry as it processes each change, continually updating it to move forward through the oplog.
Here's how a cursor object looks like:
"cursor": {
"nextBatch": [],
"postBatchResumeToken": {
"_data": "8263515979000000022B0429296E1404"
},
"id": Long("7049907285270685005"),
"ns": "test.names"
},
In this example, nextBatch[] is empty, indicating that there are no immediate documents to process. Typically, this array contains the change events fetched in the current batch. It holds the next set of documents (change events) retrieved from the change stream.
Below is a summary of the default oplog sizes:
| Operating System | Storage Engine | Default Oplog Size Constraints |
|---|---|---|
| Unix/Windows | WiredTiger | - Minimum: 990 MB |
| Unix/Windows | In-Memory (Self-Managed Deployments) | - Minimum: 990 MB |
Streaming Data to Data Warehouses and Lakehouses
How the Data Moves
Once Debezium captures changes from MongoDB and sends them to Kafka, the next step is to move that data to your data warehouse or lakehouse. Here's how it works:
- Kafka Topics: Each change captured by Debezium is sent to a specific Kafka topic. Think of topics as channels where related data changes are grouped together. 1 topic = 1 collection / table.
Format:logicalName.databaseName.collectionName. Where logicalName is the name you set for the connector (usingtopic.prefix).
You can enable Kafka to automatically create topics as needed, or manually create them using Kafka tools before running the connector.
Note: All changes in a sharded collection (even if split across shards) go to a single Kafka topic for that collection
-
Kafka Connect Sink Connectors: These connectors take data from Kafka topics and push it to your data warehouse or lakehouse. There are different connectors available depending on where you want to send your data, such as:
-
JDBC Sink Connector: For relational databases like PostgreSQL or MySQL.
-
S3 Sink Connector: To store data in Amazon S3.
-
HDFS Sink Connector: For Hadoop Distributed File System.
-
BigQuery Sink Connector: To send data to Google BigQuery.
-
-
Configuration: You need to configure the sink connector with details about your target system, such as connection strings, authentication, and the specific topics to read from Kafka.
-
Data Transformation: Sometimes, the data needs to be transformed before it fits into your warehouse. Kafka Connect offers Single Message Transforms (SMTs) to modify data on the fly, like renaming fields or filtering out unnecessary information.
-
Loading Data: The sink connector reads the data from Kafka, applies any necessary transformations, and loads it into your data warehouse or lakehouse. This process can happen in real-time or near real-time, depending on your configuration.
Setting Up the Sink Connector
Here's a simple example of configuring a Kafka Connect sink connector to send data to PostgreSQL:
{
"name": "postgres-sink-connector",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "dbserver1.mydb.mycollection",
"connection.url": "jdbc:postgresql://localhost:5432/mywarehouse",
"connection.user": "postgres",
"connection.password": "password",
"auto.create": "true",
"insert.mode": "upsert",
"pk.mode": "record_key",
"pk.fields": "id"
}
}
To deploy this connector, you would use the Kafka Connect REST API similar to how you set up the Debezium connector.
Tip: One of the actual benefits of sending data to Kafka in streaming mode is, cursor is always near end, so probability of losing it reduces (compared to batch based environment)
Pros and Cons of This Method
Advantages
Other than what we discussed above, these are the advantages:
-
Decoupled Systems
-
Independent Scaling: Kafka acts as a buffer between MongoDB and your data warehouse, allowing each system to scale independently.
-
Flexible Integrations: Easily connect to multiple downstream systems without impacting the source database.
-
-
Ease of Use with Kafka Connect
-
Simplified Integration: Kafka Connect provides a framework for connecting Kafka with external systems, reducing the amount of custom code you need to write.
-
Pre-Built Connectors: Use existing connectors for popular databases and data stores, speeding up the setup process.
-
Disadvantages
-
Complexity of Setup
-
Multiple Components: Setting up and maintaining Kafka, Kafka Connect, Debezium, Zookeeper (if you are managing kafka internally) and your data warehouse involves managing several moving parts.
-
Configuration Management: Requires careful configuration to ensure all components work seamlessly together.
-
-
Resource Intensive
-
Infrastructure Requirements: Running Kafka and Debezium can consume significant system resources, especially for large-scale deployments.
-
Operational Overhead: Requires monitoring, maintenance, and potential troubleshooting to keep the data pipeline running smoothly.
-
-
Latency
- Debezium is JVM based so it's a bit slow in decoding and putting the data in Kafka. Also its slow because it doesn't parallelise the CDC for multiple collections / tables and parallel full load for initial snapshot of single collection.
-
Learning Curve
-
Technical Expertise Needed: Understanding how Kafka, Kafka Connect, and Debezium work together requires a good grasp of these technologies.
-
Debugging Challenges: Troubleshooting issues in a distributed system can be more complex compared to simpler data transfer methods.
-
-
Data Consistency and Ordering
-
Complex Scenarios: Ensuring data consistency and correct ordering of events can be challenging, especially in distributed environments with multiple consumers.
-
Handling Failures: Properly managing failures and ensuring no data is lost or duplicated requires careful planning and configuration.
-
Best Practices for Configuration
Configuring Debezium and Kafka correctly is crucial to ensure a smooth and efficient data streaming process. Here are some best practices to follow:
1. Optimize MongoDB Oplog Size
When using Debezium’s MongoDB connector, it's important to properly configure the oplog
Why Oplog Size Matters?
As we already know that debezium reads from the oplog to capture changes. If Debezium stops and restarts, it needs to find where it left off using the last recorded position in the oplog.
What are the problems with Small Oplog?
-
Missing Data: If Debezium is offline for too long, the oplog might delete the old changes it needs to resume, and if oplog is full already, it will start overwriting existing data causing Debezium to fail with an "invalid resume token" error (when it resumes back).
-
Manual Fixes: If this happens, you may need to set up a new connector and re-sync data manually to capture records from the database, which can be time-consuming.
How to Prevent Oplog Issues
-
Increase Oplog Size
-
How: Make the oplog larger than the maximum number of changes you expect in your busiest hour.
-
Example: If your database changes by 3 GB every hour (say) and you want Debezium to recover from a 2-hour outage, set your oplog size to at least 6 GB (3 GB/hour × 2 hours).
-
-
Set Minimum Retention Time (MongoDB 4.4+)
-
How: Configure MongoDB to keep oplog entries for a certain number of hours, regardless of the oplog size.
-
Why: This makes sure that even if the oplog reaches its size limit, it won’t delete entries within the set time frame.
-
Check the current oplog size using the MongoDB shell:
mongo
use local
db.oplog.rs.stats()
Adjust the oplog size by restarting MongoDB with a larger --oplogSize parameter if needed.
Can Debezium Lose Events?
Debezium, by design, should capture every change (insert, update, delete) from your database and send it downstream. It operates on an “at-least-once” basis, meaning duplicate events can happen if the connector shuts down improperly, but missing events would be a serious issue, marked as a bug to fix ASAP.
When Might Event Loss Happen?
Event loss can occur if part of the database’s transaction log gets deleted before Debezium captures it. This usually happens in two cases:
-
Connector Downtime: If Debezium isn’t running for a while, and the transaction log reaches its max retention time, parts of it may get discarded. For example, in MySQL, the log retention can be set with
binlog_expire_logs_seconds, and in SQL Server, it's managed with the CDC job. -
Disk Space Limit in Postgres: Postgres handles things differently using replication slots to retain logs until Debezium reads them. But if the connector is down for too long, these logs pile up, using more disk space. In extreme cases, this could lead to a full disk.
Preventing Event Loss
-
Log Retention Configuration: Adjust transaction log retention times if you expect any downtime for your Debezium connectors.
-
Replication Slot Control (Postgres): Set a max size for WAL retention to prevent disk space issues.
-
Monitoring: Set up alerts (like from the Kafka Connect REST API) to notify you if Debezium is down for too long.
By managing these configurations and monitoring your connector’s activity, you can avoid potential event loss with Debezium.
Monitoring is Essential
-
Metrics to Watch:
-
Oplog GB/Hour: How much data does your oplog record each hour?
-
Replication Oplog Window: The time span your current oplog size covers.
-
-
Why Monitor?: To make sure your oplog is big enough to handle any downtime Debezium might face. If Debezium is offline longer than your oplog can cover, it might miss some changes.
Example:
-
Oplog Growth Rate: 3 GB per hour
-
Expected Downtime: 2 hours
-
Needed Oplog Size = 3 GB/hour × 2 hours = 6 GB
So, set your oplog size to at least 6 GB to ensure Debezium can resume without issues even after 2 hours of downtime.
2. Secure Connections
-
Use SSL/TLS: Encrypt data in transit between MongoDB, Kafka, and Kafka Connect to protect sensitive information.
-
Authentication: Ensure that all services use strong authentication mechanisms. For MongoDB, create a dedicated user with only the necessary permissions for Debezium.
-
Example Configuration:
{
"mongodb.ssl.mode": "requireSSL",
"mongodb.ssl.invalid.hostname.allowed": "false",
"mongodb.auth.mechanism": "SCRAM-SHA-1"
}
3. Configure Kafka for High Availability
- Replication Factor: Set a replication factor greater than 1 for Kafka topics to ensure data is not lost if a broker fails.
kafka-topics --create --topic your_topic --replication-factor 3 --partitions 10 --bootstrap-server localhost:9092
- Multiple Brokers: Deploy multiple Kafka brokers across different machines or availability zones to distribute the load and provide redundancy.
4. Tune Kafka Connect Settings
- Increase Task Parallelism: Adjust the number of tasks in Kafka Connect to handle higher throughput.
{
"tasks.max": "5"
}
- Batch Size: Configure the batch size for connectors to optimize performance.
{
"batch.size": "1000"
}
5. Implement Monitoring and Alerting
-
Use Monitoring Tools: Tools like Prometheus and Grafana can help monitor Kafka, Debezium, and Kafka Connect metrics.
-
Set Up Alerts: Configure alerts for critical metrics such as lag, error rates, and resource usage to respond quickly to issues.
6. Handle Schema Changes Gracefully
-
Schema Registry: Use a schema registry to manage and version your data schemas, ensuring compatibility between producers and consumers.
-
Automatic Schema Evolution: Configure Debezium to handle schema changes without manual intervention.
7. Manage Offsets Properly
-
Enable Offset Storage: Ensure that Kafka Connect stores offsets in a durable storage to resume processing after failures.
-
Regular Backups: Regularly back up your offset storage topics to prevent data loss.
8. Use Proper Resource Allocation
-
Allocate Sufficient Resources: Ensure that your Kafka brokers, Kafka Connect workers, and Debezium connectors have enough CPU, memory, and storage to handle the data load.
-
Scale Horizontally: Add more instances of Kafka Connect workers or Debezium connectors if you need to handle increased traffic.
9. Test Your Configuration
-
Staging Environment: Always test your setup in a staging environment before deploying to production.
-
Simulate Load: Use tools to simulate data changes and ensure that your pipeline can handle the expected load without issues.
10. Document Your Setup
-
Configuration Files: Keep detailed records of all configuration settings for Kafka, Kafka Connect, and Debezium.
-
Operational Procedures: Document procedures for common tasks like restarting connectors, scaling services, and recovering from failures.
Deployment Options: Self-Hosted vs. Managed
When setting up Debezium and Kafka for streaming data from MongoDB, you have two main options for deployment: self-hosted or managed services.
Each approach has its own set of advantages and trade-offs. Let’s break them down so you can decide which one fits your needs best.
Self-Hosted Deployment
Self-hosted means you’re responsible for installing, configuring, and maintaining Kafka, Debezium, and any other components on your own servers or infrastructure.
Pros:
-
Full Control:
-
You have complete control over the configuration and customization of Kafka and Debezium.
-
Can optimize settings specifically for your workload and environment.
-
-
Cost Efficiency:
-
Potentially lower costs if you have existing infrastructure and the expertise to manage it.
-
No additional charges from cloud providers for managed services.
-
-
Flexibility:
-
Easier to integrate with on-premises systems or other custom setups.
-
Freedom to choose specific versions and configurations that suit your needs.
-
Cons:
-
Operational Overhead:
-
Requires significant time and effort to set up, monitor, and maintain.
-
You need to handle updates, scaling, and troubleshooting on your own.
-
-
Scalability Challenges:
-
Scaling Kafka and Debezium can be complex and may require expertise.
-
Ensuring high availability and fault tolerance is your responsibility.
-
-
Resource Intensive:
-
Demands robust infrastructure and skilled personnel to manage the systems effectively.
-
Potential for higher indirect costs due to maintenance and management efforts.
-
Managed Services
Managed services involve using cloud providers or specialized vendors to handle the setup, maintenance, and scaling of Kafka and Debezium. Examples include Confluent Cloud, AWS Managed Streaming for Apache Kafka (MSK), or other similar offerings.
Pros:
-
Ease of Use:
-
Simplifies the deployment process with pre-configured setups.
-
Reduces the time and effort needed to get Kafka and Debezium up and running.
-
-
Scalability:
-
Easily scale your Kafka clusters based on demand without manual intervention.
-
Managed services typically offer automatic scaling and load balancing.
-
-
Maintenance and Upgrades:
-
Providers handle updates, security patches, and maintenance tasks.
-
Ensures that your systems are always up-to-date with the latest features and security improvements.
-
-
Reliability and Availability:
-
Built-in high availability and disaster recovery options.
-
Providers often offer Service Level Agreements (SLAs) to guarantee uptime.
-
Cons:
-
Cost:
-
Managed services can be more expensive, especially at scale.
-
Ongoing subscription or usage fees might add up over time.
-
-
Less Control:
-
Limited ability to customize configurations beyond what the provider allows.
-
May not support all features or integrations you need.
-
-
Vendor Lock-In:
-
Dependence on a specific provider’s ecosystem and pricing model.
-
Migrating to another provider or back to self-hosting can be challenging.
-
Hybrid Approach
Some organizations opt for a hybrid approach, where critical components are self-hosted for maximum control, while other parts leverage managed services for ease and scalability. This can provide a balance between control and operational simplicity.
Configurations and Examples
Setting up Debezium with Kafka involves configuring several components to work together seamlessly. In this section, we’ll go through some configuration examples and provide sample setups to help you get started.
Docker Compose Example [SAMPLE]
Using Docker Compose can simplify the setup process by containerizing Kafka, Zookeeper, and Kafka Connect with Debezium. Here’s an example docker-compose.yml:
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ports:
- "2181:2181"
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9092:9092"
connect:
image: debezium/connect:latest
depends_on:
- kafka
environment:
BOOTSTRAP_SERVERS: kafka:9092
GROUP_ID: 1
CONFIG_STORAGE_TOPIC: my_connect_configs
OFFSET_STORAGE_TOPIC: my_connect_offsets
STATUS_STORAGE_TOPIC: my_connect_statuses
KEY_CONVERTER_SCHEMAS_ENABLE: "false"
VALUE_CONVERTER_SCHEMAS_ENABLE: "false"
KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_PLUGIN_PATH: "/kafka/connect"
ports:
- "8083:8083"
volumes:
- ./connectors:/kafka/connect
How to Use:
-
Save the File: Save the above YAML content to a file named
docker-compose.yml. -
Run Docker Compose:
docker-compose up -d
Verify Services: Ensure that Zookeeper, Kafka, and Kafka Connect are running by checking the Docker containers.
Tips for Configuration
-
Consistent Naming: Use clear and consistent naming conventions for connectors and topics to avoid confusion.
-
Secure Credentials: Store sensitive information like passwords securely, using environment variables or secret management tools.
-
Monitor Performance: Regularly check the performance of your connectors and Kafka cluster to identify and address bottlenecks.
-
Backup Configurations: Keep backups of your configuration files to quickly recover from accidental changes or failures.
Setting Up in a Cloud Environment
Deploying Debezium and Kafka in a cloud environment means you get scalability, reliability, and ease of management.
AWS (Amazon Web Services)
-
Use Amazon MSK for Kafka:
-
Provision MSK Cluster: Go to the AWS Management Console, navigate to Amazon MSK, and create a new Kafka cluster.
-
Configure Networking: Ensure the cluster is in the right VPC and has the necessary security groups.
-
-
Deploy Debezium on AWS ECS or EKS:
-
ECS (Elastic Container Service): Use ECS to run Debezium as Docker containers.
-
EKS (Elastic Kubernetes Service): For Kubernetes-based deployments, use EKS to manage Debezium pods.
-
OR - User AWS Kafka Connect, their managed offering.
-
-
Set Up MongoDB:
-
MongoDB Atlas: Use MongoDB Atlas, a managed MongoDB service, for easy setup and scaling.
-
Configure Replication: Ensure that your MongoDB instance has replication enabled to access the oplog.
-
-
Connect Debezium to MSK:
-
Network Configuration: Ensure Debezium can communicate with your MSK cluster.
-
Configure Debezium: Update Debezium’s configuration to point to the MSK brokers.
-
Azure
-
Use Azure Event Hubs for Kafka:
-
Provision Event Hubs: Create an Event Hubs namespace and configure Kafka-compatible endpoints.
-
Configure Networking: Set up necessary networking and security configurations.
-
-
Deploy Debezium on Azure Kubernetes Service (AKS):
-
AKS Cluster: Set up an AKS cluster to run Debezium containers.
-
Configure Debezium: Update Debezium’s configuration to connect to Azure Event Hubs.
-
-
Set Up MongoDB:
-
Azure Cosmos DB: Use Azure Cosmos DB with MongoDB API for a managed MongoDB experience.
-
Enable Replication: Ensure replication is enabled for oplog access.
-
Google Cloud Platform (GCP)
-
Use Confluent Cloud or Google Cloud Pub/Sub with Kafka Compatibility:
-
Confluent Cloud: A fully managed Kafka service available on GCP.
-
Google Cloud Pub/Sub: Use Pub/Sub with Kafka connectors for compatibility.
-
-
Deploy Debezium on Google Kubernetes Engine (GKE):
-
GKE Cluster: Create a GKE cluster to manage Debezium containers.
-
Configure Debezium: Point Debezium to the Kafka brokers provided by Confluent Cloud or Pub/Sub.
-
-
Set Up MongoDB:
-
MongoDB Atlas: Deploy MongoDB Atlas on GCP for a managed MongoDB solution.
-
Enable Replication: Ensure your MongoDB instance has replication enabled.
-
General Steps for Cloud Deployment
Regardless of the cloud provider, the general steps to set up Debezium and Kafka are:
-
Provision Managed Kafka Service:
- Use the cloud provider’s managed Kafka service or a third-party provider like Confluent Cloud.
-
Set Up MongoDB with Replication:
- Use a managed MongoDB service or set up MongoDB on cloud VMs with replication enabled.
-
Deploy Debezium:
-
Use container orchestration services (like ECS, EKS, AKS, or GKE) to run Debezium.
-
Ensure Debezium has network access to both MongoDB and Kafka brokers.
-
-
Configure Networking and Security:
-
Set up VPCs, subnets, security groups, and firewall rules to allow necessary traffic.
-
Implement encryption in transit and at rest for data security.
-
-
Monitor and Scale:
-
Use cloud monitoring tools to keep an eye on the performance and health of your Kafka cluster and Debezium connectors.
-
Scale your services based on load and performance requirements.
-
Benefits of Cloud Deployment
-
Scalability: Easily scale your Kafka cluster and Debezium connectors based on demand.
-
Reliability: Leverage the cloud provider’s infrastructure for high availability and disaster recovery.
-
Managed Services: Reduce operational overhead by using managed services for Kafka and MongoDB.
-
Security: Utilize advanced security features provided by the cloud platform, such as IAM, encryption, and network security.
Conclusion
Setting up a real-time data streaming pipeline using Debezium and Apache Kafka with MongoDB as the source can significantly enhance your data architecture. This setup enables you to capture and stream data changes instantly, ensuring that your data warehouse or lakehouse always has the most up-to-date information.
Key Takeaways:
-
Change Data Capture (CDC) is essential for real-time data integration, and Debezium excels at this by leveraging MongoDB’s oplog.
-
Apache Kafka serves as a robust and scalable platform for handling the streamed data, making it accessible to various downstream systems.
-
Configuration and Setup require careful attention to details such as MongoDB replication, Kafka Connect settings, and secure connections.
-
Deployment Options offer flexibility, whether you prefer the control of self-hosting or the convenience of managed services.
-
Best Practices ensure that your data pipeline is reliable, secure, and performs well under load.
-
Manual Implementation is challenging and time-consuming, making Debezium and Kafka a more efficient choice for most scenarios.
FAQs
1. Does Debezium use Kafka Connect?
Yes, Debezium uses Kafka Connect.
Debezium operates as a Kafka Connect connector. Kafka Connect is a framework that simplifies the integration of Apache Kafka with other data systems like databases, key-value stores, and more. By using Kafka Connect, Debezium can easily capture changes from your databases and stream them into Kafka topics without requiring you to write custom code.
Example:
-
Debezium Connector: Acts as a bridge between your MongoDB database and Kafka.
-
Kafka Connect Framework: Manages the connector, handling tasks like starting, stopping, and scaling the Debezium connector as needed.
2. Is Kafka and Kafka Connect different?
Yes, Kafka and Kafka Connect are different components, but they work together.
-
Apache Kafka:
-
What It Is: A powerful distributed streaming platform.
-
Main Functions: It handles publishing and subscribing to streams of records, storing them, and processing them in real-time.
-
Use Cases: Messaging system, real-time analytics, log aggregation, event sourcing, and more.
-
-
Kafka Connect:
-
What It Is: A tool within the Kafka ecosystem.
-
Main Functions: Simplifies the process of connecting Kafka with external systems like databases, file systems, or other data sources and sinks.
-
Use Cases: Importing data into Kafka from a database (source connector) or exporting data from Kafka to another system (sink connector).
-
How They Work Together:
-
Kafka: Manages the data streams.
-
Kafka Connect: Facilitates the movement of data between Kafka and other systems using connectors like Debezium.
Example:
-
Without Kafka Connect:
- You would need to write custom code to move data from MongoDB to Kafka.
-
With Kafka Connect:
- Use Debezium as a Kafka Connect connector to automatically capture and stream changes from MongoDB to Kafka without writing additional code.
Additional Resources
To further explore Debezium, Kafka, and their integrations with MongoDB, here are some valuable resources:
-
Debezium Documentation: https://debezium.io/documentation/
-
Apache Kafka Documentation: https://kafka.apache.org/documentation/
-
MongoDB Oplog Documentation: https://docs.mongodb.com/manual/core/replica-set-oplog/
-
Kafka Connect Documentation: https://kafka.apache.org/documentation/#connect
-
Debezium MongoDB Connector GitHub: https://github.com/debezium/debezium/tree/main/debezium-connector-mongodb
-
Tutorial: Getting Started with Debezium and Kafka: https://debezium.io/documentation/reference/3.1/tutorial.html
-
Monitoring Kafka with Prometheus and Grafana: https://grafana.com/docs/grafana/latest/datasources/prometheus/
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.