MySQL to Apache Iceberg Replication | Modern Analytics Pipeline


MySQL powers countless production applications as a reliable operational database. But when it comes to analytics at scale, running heavy queries directly on MySQL can quickly become expensive, slow, and disruptive to transactional workloads.
That's where Apache Iceberg comes in. By replicating MySQL data into Iceberg tables, you can unlock a modern, open-format data lakehouse that supports real-time analytics, schema evolution, partitioning, and time travel queries all without burdening your source database.
Apache Iceberg is more than an average table format and it's designed for large-scale, cost-effective analytics. With native support for ACID transactions, seamless schema evolution, and compatibility with query engines like Trino, Spark, and DuckDB, it's ideal for modern data lakehouses.
In this comprehensive guide, we'll walk through setting up a real-time pipeline from MySQL to Apache Iceberg using OLake, covering both UI and CLI approaches. We'll explore why companies like Netflix, Natural Intelligence, and Memed have successfully migrated to Iceberg architectures, achieving dramatic performance improvements and cost savings.
Key Takeaways
- Offload Analytics from Production: Replicate MySQL to Iceberg to run heavy analytical queries without impacting your production database performance
- Real-time Data Sync: CDC via binlog keeps Iceberg tables up-to-date with sub-second latency for real-time dashboards and reporting
- Massive Cost Savings: Companies like Netflix achieved 25% cost reduction and Memed saw 60x faster ETL processing times
- Open Format Freedom: Store data once in S3 and query with any engine (Trino, Spark, DuckDB) - no vendor lock-in
- Enterprise Features Built-in: Get automatic schema evolution, ACID transactions, time travel, and partitioning without complex engineering
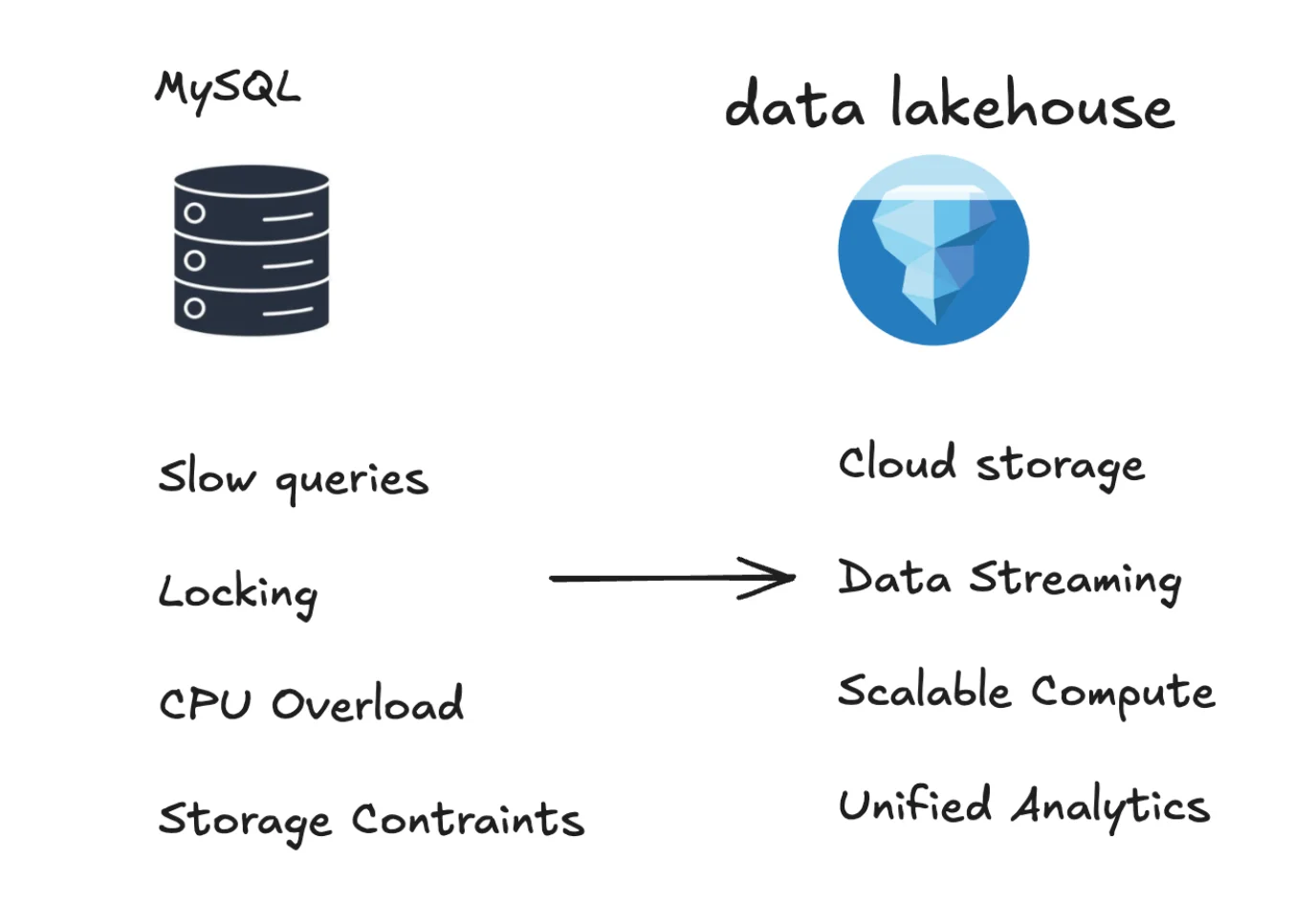
The Growing Problem: Why MySQL Analytics Hit Performance Walls
MySQL's OLTP Design vs. Large-Scale Analytics Requirements
MySQL was originally designed as a fast and stable OLTP (Online Transaction Processing) database. While it excels at handling simple, repetitive queries and supporting user-facing applications with high volumes of small transactions, analytics presents completely different challenges.
Row-Oriented Storage Limitations: MySQL's default InnoDB engine stores data in a row-based format optimized for fast inserts and small point-lookups. This structure works well for datasets in the tens or hundreds of gigabytes, but once you approach terabyte-level MySQL data volumes, queries requiring full table scans, multi-way joins, and aggregations often slow to a crawl.
Single-Node Architecture Constraints: Unlike distributed systems, MySQL typically runs on a single node, meaning you can't simply add more machines and expect linear performance gains. Manual sharding becomes complex and operationally challenging as data scales beyond 1-2TB.
Real-World MySQL Performance Bottlenecks
Research shows that MySQL analytics queries experience dramatic performance degradation as data volumes grow:
- Small datasets (< 10GB): Sub-second query responses
- Medium datasets (100GB+): Tens of seconds to minutes
- Large datasets (1TB+): Minutes to hours for complex analytics
Common Performance Issues Include:
- Slow Query Execution: Multi-join aggregation queries on 500 million rows might take minutes or hours in MySQL, whereas columnar, distributed systems could return similar results in seconds.
- Lock Contention Problems: When multiple analytical queries access the same resources concurrently, MySQL lock contention causes significant delays and reduced database concurrency.
- BI Dashboard Failures: Tools like Metabase, Tableau, or Power BI connected directly to MySQL often display endless loading spinners or timeout errors when processing large datasets.
- Inadequate Full-Text Search: MySQL full-text search capabilities don't scale well beyond a few gigabytes of text data, unlike specialized search engines or distributed systems with parallel search capabilities.
The Hidden Costs of MySQL Analytics at Scale
Infrastructure Costs Spiral: An in-house data warehouse with just one terabyte of storage costs approximately $468,000 annually, while MySQL analytics often require expensive hardware upgrades that don't solve the fundamental architectural limitations.
Operational Overhead: Sequential scans on large tables (200GB+) become I/O heavy, significantly increasing response times as MySQL must load far more data into memory than columnar engines would require.
Why Replicate MySQL to Apache Iceberg: The Modern Solution
Transforming Analytics Performance and Cost Structure
MySQL is excellent for powering production applications, but it wasn't designed for large-scale analytics. Running heavy queries on MySQL often slows down applications, causes lock contention, and hits scaling limits as data grows.
Replicating MySQL into Apache Iceberg solves these fundamental problems:
- Offload Analytics Workloads: Keep OLTP performance fast while running complex queries on Iceberg tables without impacting production systems.
- Handle Petabyte Scale: Iceberg supports petabytes of data on object storage like S3, with no sharding or archiving complexity.
- Near Real-time Synchronization: With MySQL CDC from binlog, Iceberg tables stay continuously up to date with sub-second latency.
- Advanced Lakehouse Features: Partitioning, schema evolution, ACID transactions, and time travel make analytics flexible and reliable.
- Lower Cost, Open Ecosystem: Store data cheaply in S3, query with engines like Trino or Spark, and avoid vendor lock-in.
Enterprise Success Stories: Real-World Cost and Performance Improvements
Netflix's Exabyte-Scale Migration: Netflix operates a data lake of approximately one exabyte and successfully migrated to an Iceberg-only data warehouse. Despite managing this massive scale, the migration delivered:
- 25% cost reduction through efficient compression and data cleanup
- Orders of magnitude faster queries compared to their previous system
- Enhanced data governance with ACID transactions and time travel capabilities
Watch Netflix's journey to Apache Iceberg at AWS re:Invent 2023 to learn about their modernization process and the development of custom tooling for exabyte-scale data management.
Natural Intelligence's Zero-Downtime Transformation: NI completed their migration with zero downtime, maintaining continuous operations while supporting hundreds of pipelines and dashboards. The result was a modern, vendor-neutral platform enabling seamless integration with multiple compute and query engines.
Memed's Healthcare Analytics Breakthrough: Brazilian health-tech company Memed achieved a 60x improvement in ETL processing time (from 30-40 minutes to 40 seconds) while enabling sub-10 minute analytical queries over large datasets. Read the full case study to learn how they modernized their data architecture.
Key Challenges in MySQL to Iceberg Replication
Moving data from MySQL into Iceberg sounds simple, but in practice there are several technical hurdles that require careful planning:
Change Data Capture Implementation Complexity
- MySQL CDC Setup Challenges: Getting MySQL binlogs configured correctly (ROW format, retention, permissions) is tricky, and mistakes can lead to missed changes. The binary log must be properly enabled with appropriate settings for reliable CDC.
- Real-time vs. Batch Processing: Choosing between real-time CDC streams and batch replication affects both data freshness and infrastructure complexity. Real-time offers low latency but requires more sophisticated monitoring and error handling.
Schema Evolution and Data Type Compatibility
- Dynamic Schema Changes: Developers add or drop columns in MySQL frequently. If your pipeline can't adapt to MySQL schema evolution, it breaks during routine database updates.
- Data Type Mismatches: MySQL types like JSON, ENUM, or complex temporal formats don't always translate cleanly into Iceberg-compatible schemas. Careful mapping strategies are essential for long-term reliability.
Performance Optimization and Partitioning Strategy
- MySQL Table Structure vs. Analytics: MySQL tables aren't designed for analytics, so choosing the right Iceberg partitioning strategy makes or breaks query performance. Poor partitioning decisions can result in slow queries and high file scan costs.
- Reliability and Monitoring: Network hiccups, binlog rotations, or failed writes can quietly push MySQL CDC pipelines out of sync without proper monitoring. Robust state management and recovery procedures are crucial for production deployments.
These challenges are why many DIY approaches get complicated quickly. Tools like OLake smooth over these technical edges while handling CDC configuration, schema evolution, partitioning optimization, and reliability monitoring automatically.
Step-by-Step MySQL to Iceberg Migration Workflow with OLake
How MySQL to Iceberg Replication Works
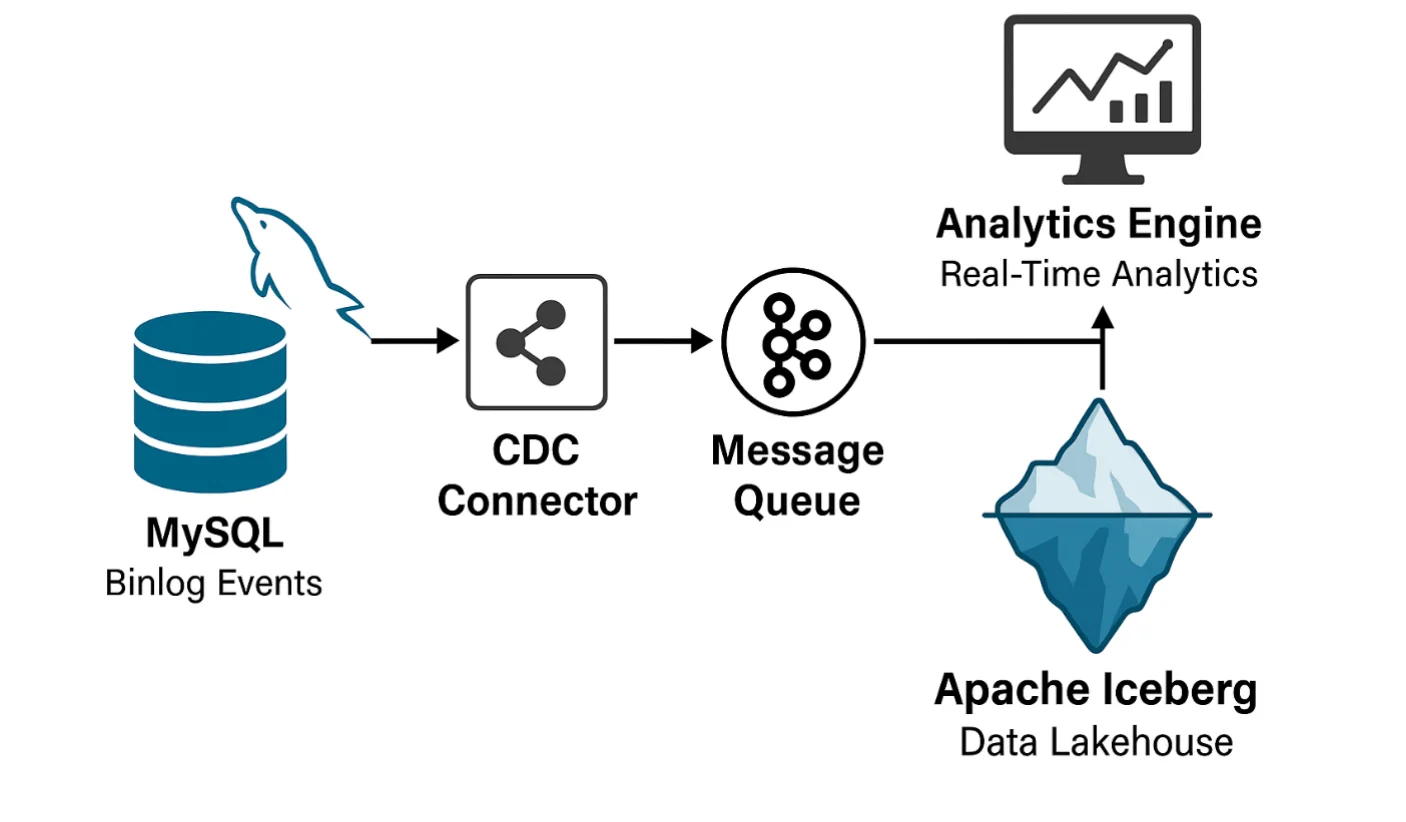
At a high level, the flow is straightforward: MySQL → OLake → Iceberg. Here's what happens behind the scenes to enable real-time MySQL analytics:
Real-Time Change Data Capture Process
- Listen to Changes: OLake connects to MySQL's binary logs, which record every insert, update, and delete operation in real-time. This approach provides millisecond-latency change detection without impacting production performance.
- Capture and Transform: Those changes are read continuously, normalized, and mapped into Iceberg-compatible data types while preserving data integrity and handling schema evolution automatically.
- Write to Iceberg: OLake writes the data into Iceberg tables in your data lake (S3, HDFS, MinIO, etc.), respecting partition strategies and schema requirements for optimal query performance.
- Stay in Sync: As new changes flow into MySQL, they automatically propagate to Iceberg, keeping your lakehouse tables fresh and query-ready for real-time analytics.
Automated Optimization and Reliability
The best part? You don't need to worry about edge cases like schema evolution, or partitioning logic, OLake handles these automatically while ensuring your Iceberg tables remain efficient and consistent.
Advanced Features Include:
- Schema drift detection and handling for seamless evolution
- Partition optimization based on query patterns and data volume
- State management with recovery capabilities for production reliability
For deeper technical insights into what makes OLake fast and reliable for MySQL-to-Iceberg pipelines, check out the performance optimization guide: OLake Performance Guide.
Step-by-Step Guide: MySQL to Iceberg Migration
Prerequisites for Your Migration
Before starting your MySQL to Apache Iceberg replication, ensure you have the following components configured:
OLake Platform: UI deployed (or CLI setup) - Complete setup documentation: OLake Quickstart Guide
MySQL Instance Requirements:
- Binary logging enabled (binlog_format=ROW)
- User with REPLICATION SLAVE and REPLICATION CLIENT privileges
- server_id configured for replication
- Appropriate binlog retention settings
Destination Catalog for Iceberg:
- AWS Glue + S3 (recommended for this guide)
- Hive Metastore + HDFS/MinIO (alternative)
- Other supported catalogs (Nessie, Polaris, Unity)
Optional Query Engine: Athena/Trino/Presto or Spark SQL for result validation
For comprehensive MySQL setup details, follow this documentation: MySQL Connector Setup For AWS Glue catalog quick setup: Glue Catalog Configuration
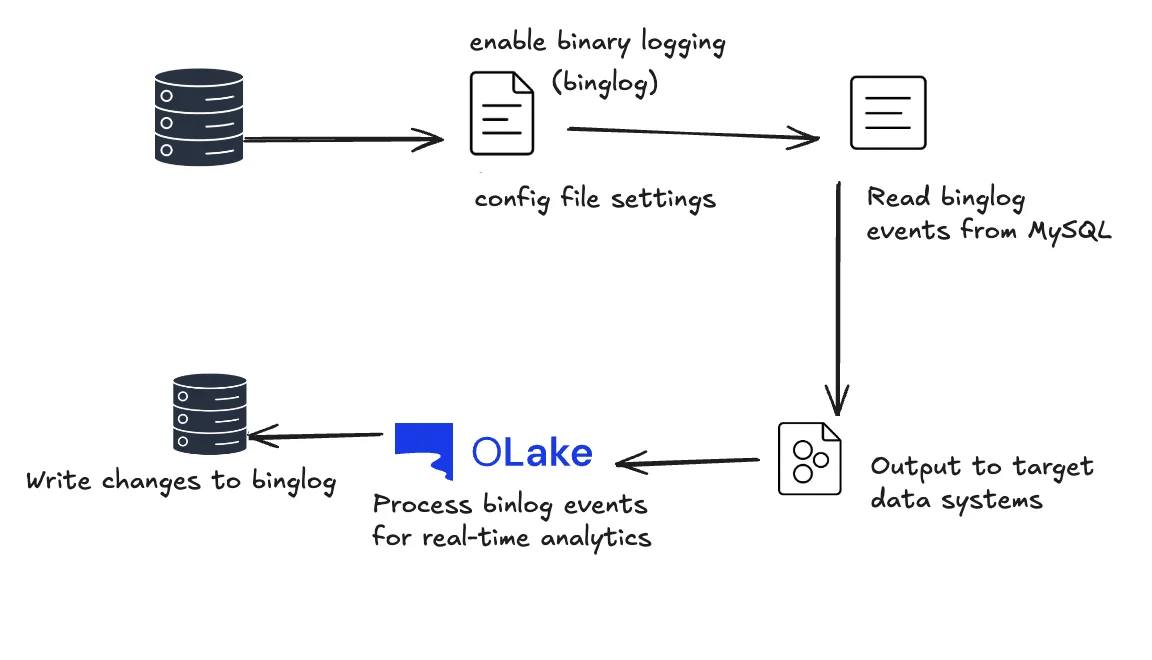
Step 1: Configure MySQL for Logical Replication
Important Note: OLake offers JDBC-based Full Refresh and Bookmark-based Incremental sync modes, so if you don't have permissions to create replication slots, you can start syncing your MySQL data immediately with standard database credentials.
Before OLake can implement real-time MySQL CDC, configure your database for logical replication using these SQL commands:
Prerequisites for MySQL CDC
- MySQL Version: 5.7 or higher for optimal compatibility
- User Privileges: Superuser or role with REPLICATION SLAVE, REPLICATION CLIENT, and SELECT privileges
Required Binary Logging Configuration:
-- Essential binlog settings
log_bin=ON
binlog_format=ROW
binlog_row_image=FULL
binlog_row_metadata=FULL
Enable Binary Logging and Create CDC User
-- Enable binary logging (add to my.cnf or my.ini)
[mysqld]
log-bin=mysql-bin
server-id=1
binlog_format=ROW
binlog_row_image=FULL
-- Create dedicated CDC user
CREATE USER 'cdc_replication'@'%' IDENTIFIED BY 'secure_password';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'cdc_replication'@'%';
FLUSH PRIVILEGES;
Restart MySQL after configuration changes to apply binlog settings.
For environment-specific MySQL CDC setup (RDS, Cloud SQL, etc.), refer to: MySQL CDC Configuration Guide
Step 2: Deploy OLake UI
OLake UI provides a web-based interface for managing replication jobs, data sources, destinations, and configurations. It offers an intuitive way to create, edit, and monitor jobs without command-line complexity.
Quick Installation with Docker
To deploy OLake UI, you'll need Docker and Docker Compose installed on your system.
Single Command Deployment:
curl -sSL https://raw.githubusercontent.com/datazip-inc/olake-ui/master/docker-compose.yml | docker compose -f - up -d
Access and Initial Configuration
- Access OLake UI: http://localhost:8000
- Default Login Credentials: admin / password
- Complete Documentation: OLake UI Getting Started
Alternative Setup: OLake provides a configurable CLI interface for advanced users preferring command-line operations. CLI documentation: Docker CLI Installation
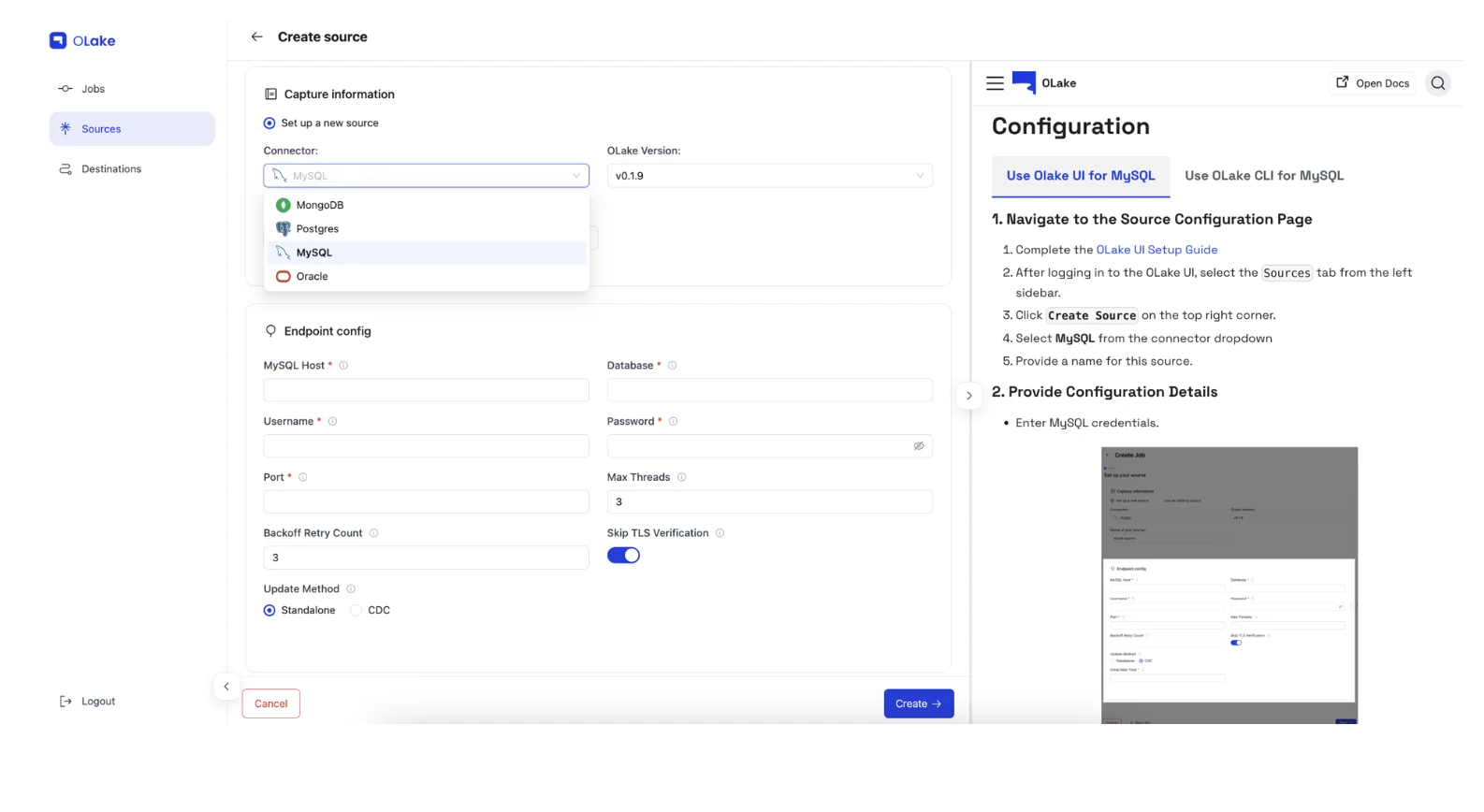
Step 3: Configure MySQL Source Connection
In the OLake UI, navigate to Sources → Add Source → MySQL.
Connection Configuration:
- Host and Port: Your MySQL server endpoint
- Username/Password: CDC user credentials created in Step 1
- Database Name: Source database identifier
- Advanced Options: Chunking strategy (OLake automatically detects optimal chunking based on primary keys for high throughput)
OLake automatically optimizes data chunking strategies for MySQL, using primary key-based chunking for maximum performance during initial loads and incremental sync operations.
Step 4: Configure Apache Iceberg Destination (AWS Glue)
Configure your Iceberg destination in the OLake UI for seamless lakehouse integration:
Navigation: Go to Destinations → Add Destination → Glue Catalog
AWS Configuration:
- Glue Region: AWS region for your Glue Data Catalog
- IAM Credentials: AWS access keys (optional if your instance has appropriate IAM roles)
- S3 Bucket: Storage location for Iceberg table data
- Catalog Settings: Additional Glue-specific configurations
Multi-Catalog Support: OLake supports multiple catalogs (Glue, Nessie, Polaris, Hive, Unity), providing flexibility for different architectural requirements.
Detailed Configuration Guide: See AWS Glue Catalog setup in Glue Catalog documentation Alternative Catalogs: For REST catalogs (Lakekeeper, Polaris) and other options: Catalog Compatibility Overview
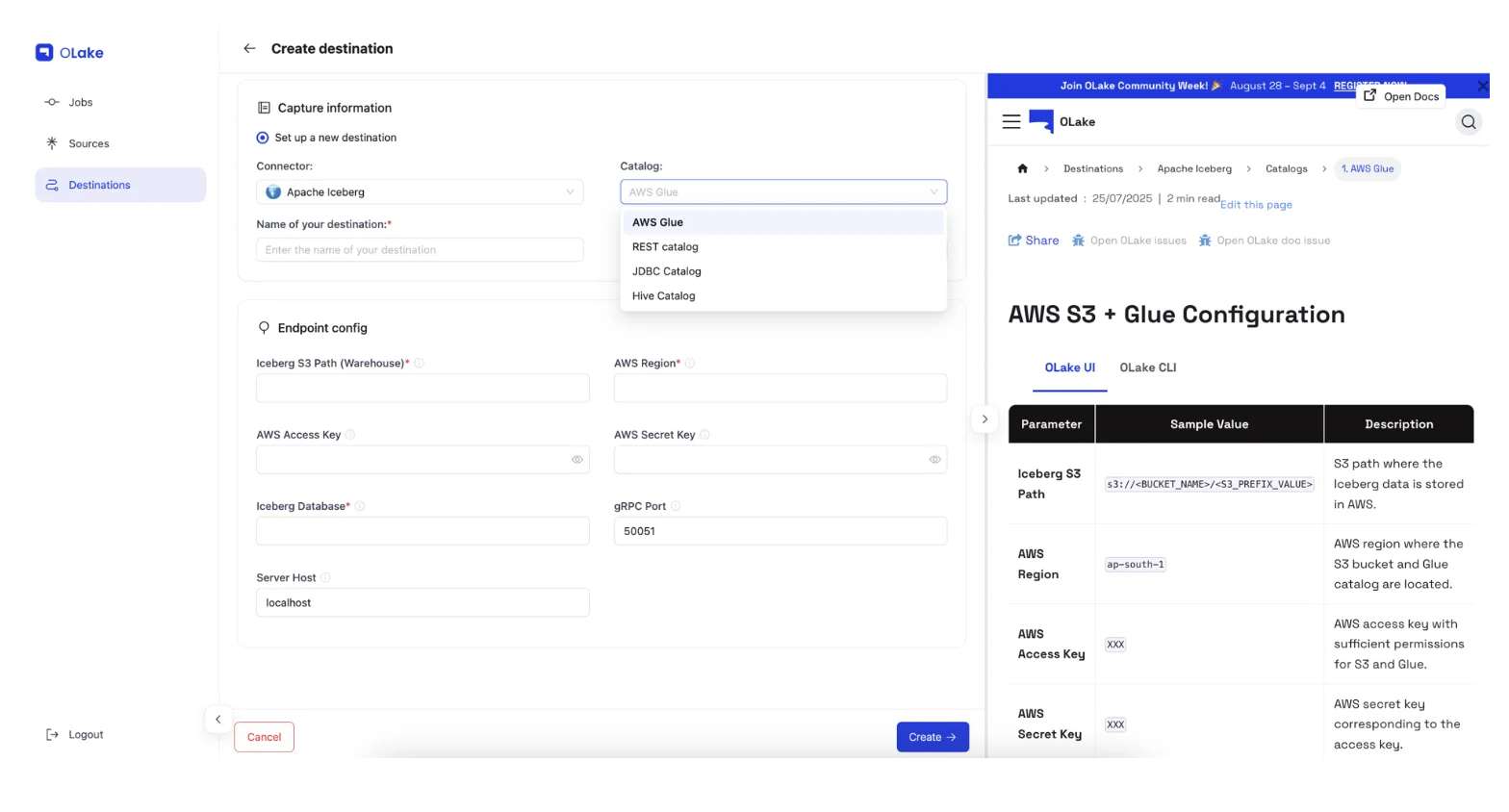
Step 5: Create Replication Job and Configure Tables
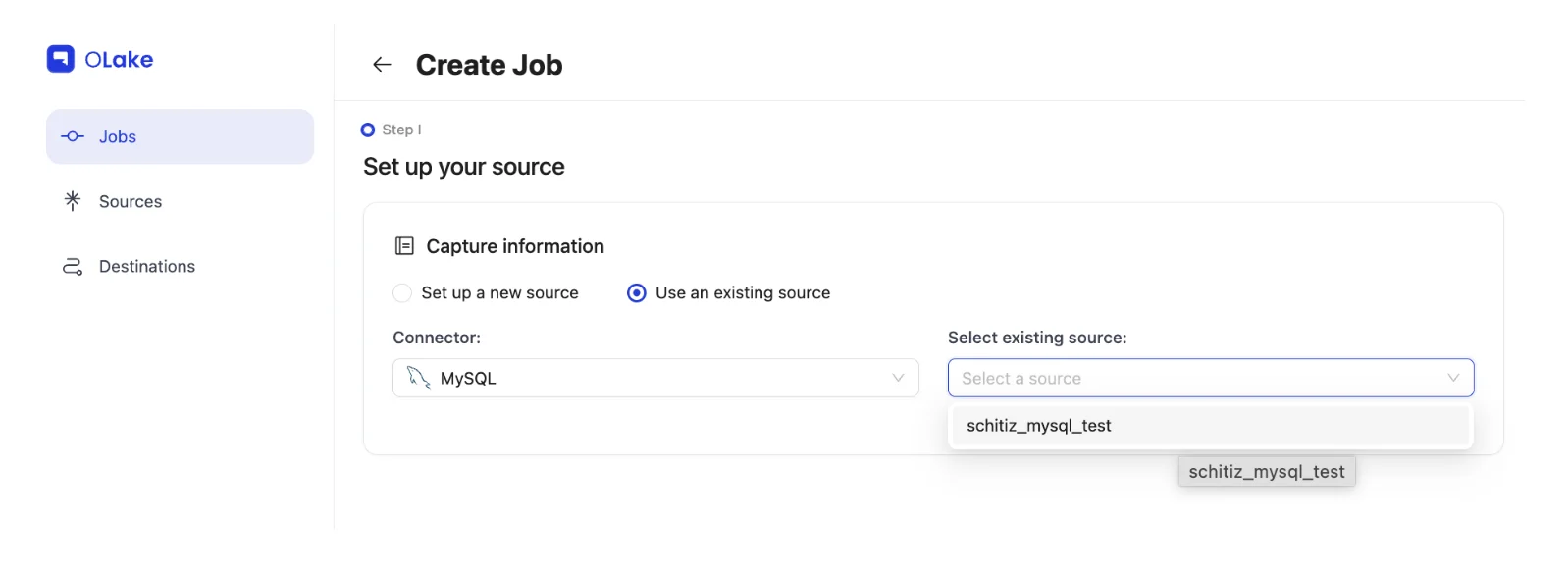
Once your source and destination connections are established, create and configure your replication job:
Job Creation Process:
- Navigate to Jobs section and create new job
- Configure job name and sync frequency
- Select existing source and destination configurations
- Choose tables/streams for Iceberg synchronization in schema section
Sync Mode Options for each table:
- Full Refresh: Complete data synchronization on every job execution
- Full Refresh + Incremental: Initial full backfill followed by incremental updates based on bookmark columns (e.g., "updated_at")
- Full Refresh + CDC: Initial full backfill followed by real-time incremental updates based on MySQL WAL logs
- CDC Only: Stream only new changes from current WAL log position
Advanced Configuration Options:
- Normalization: Disable for raw JSON data storage if needed
- Partitioning: Configure regex patterns to determine Iceberg table partitioning strategy
- Schema Handling: Automatic schema evolution and drift detection
Comprehensive partitioning strategies: Iceberg Partitioning Guide
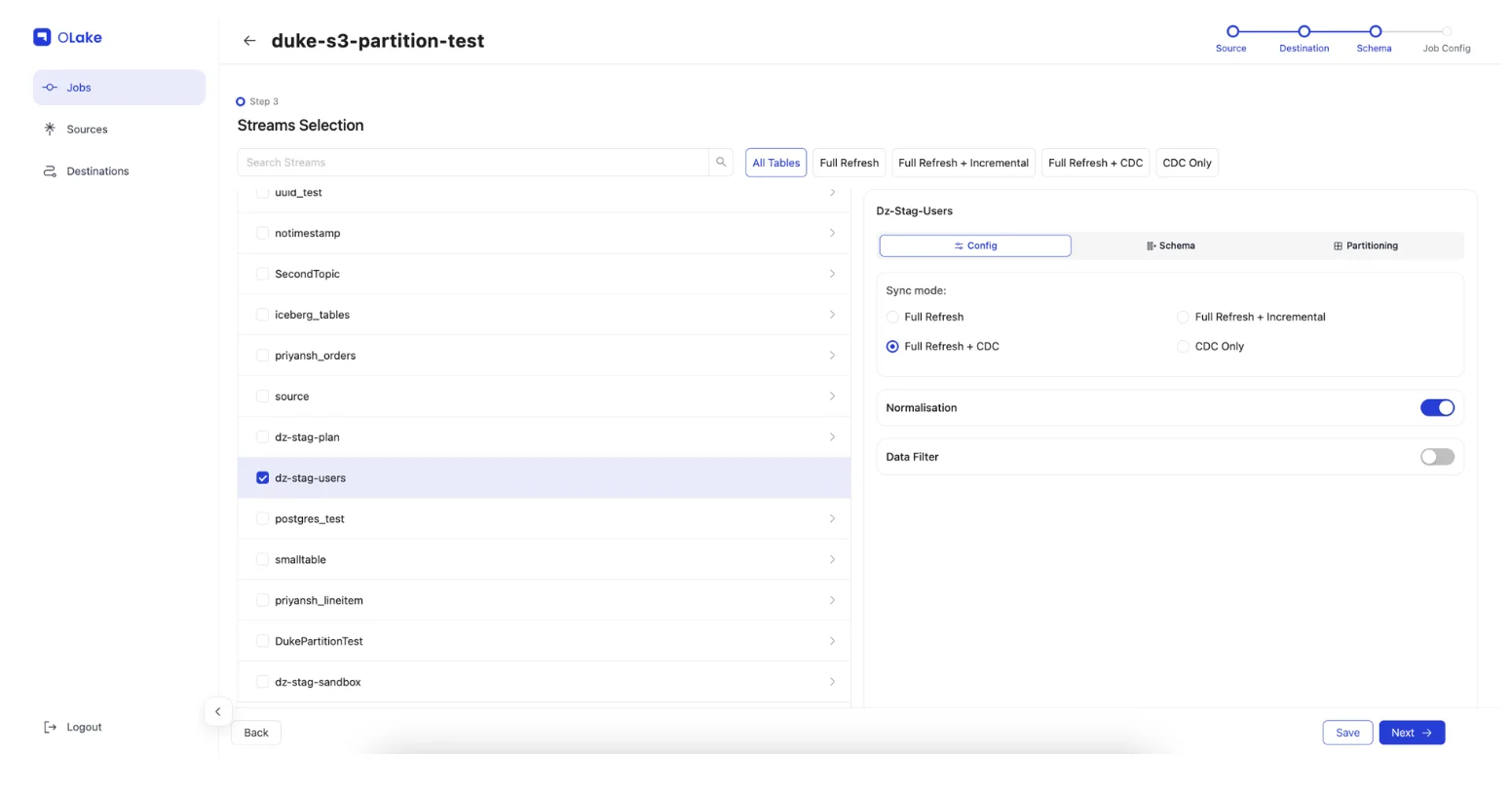
Step 6: Execute Your MySQL to Iceberg Sync
After configuring and saving your replication job:
Execution Options:
- Manual Trigger: Use "Sync Now" for immediate execution
- Scheduled Execution: Wait for automatic execution based on configured frequency
- Monitoring: Track job progress, error handling, and performance metrics
Important Considerations: Ordering during initial full loads is not guaranteed. If data ordering is critical for downstream consumption, implement sorting requirements during query execution or downstream processing stages.
Iceberg Database Structure in S3
Your MySQL to Iceberg replication creates a structured hierarchy in S3 object storage:
s3://your-bucket/
└── database_name.db/
├── table1/
│ ├── data/ (Parquet files)
│ └── metadata/ (JSON and Avro files)
├── table2/
│ ├── data/
│ └── metadata/
└── ...
Default File Formats: OLake stores data files as Parquet format with metadata in JSON and Avro formats, following Apache Iceberg specifications for optimal query performance.
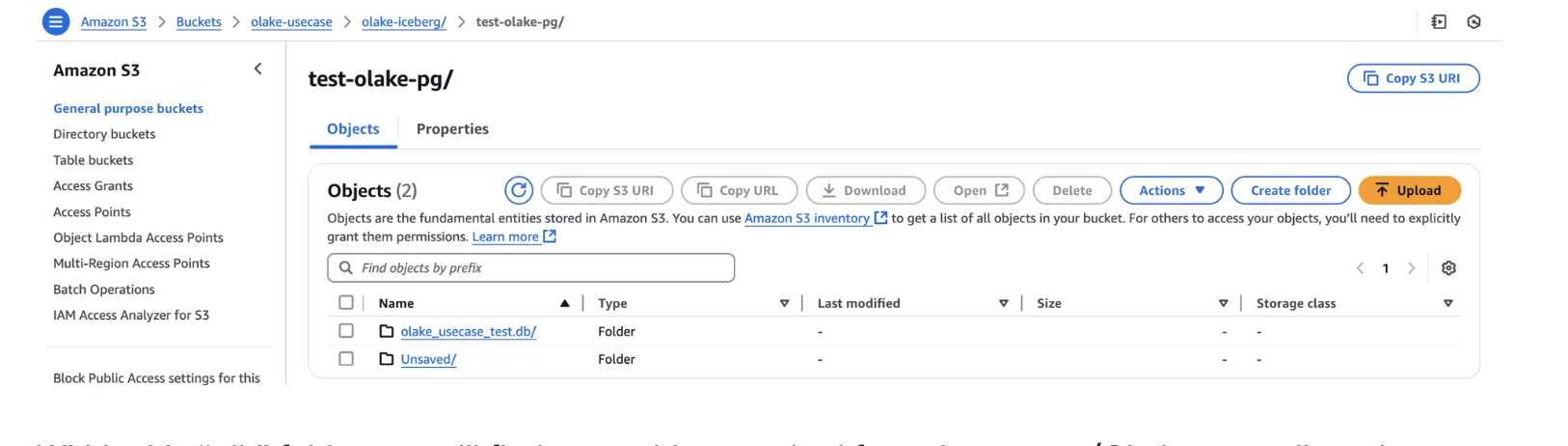
Data Organization: Within the ".db" folder, you'll find tables synced from MySQL source. OLake normalizes column, table, and schema names to ensure compatibility with Glue catalog writing restrictions.
File Structure: Each table contains respective data and metadata files organized for efficient querying and maintenance operations.
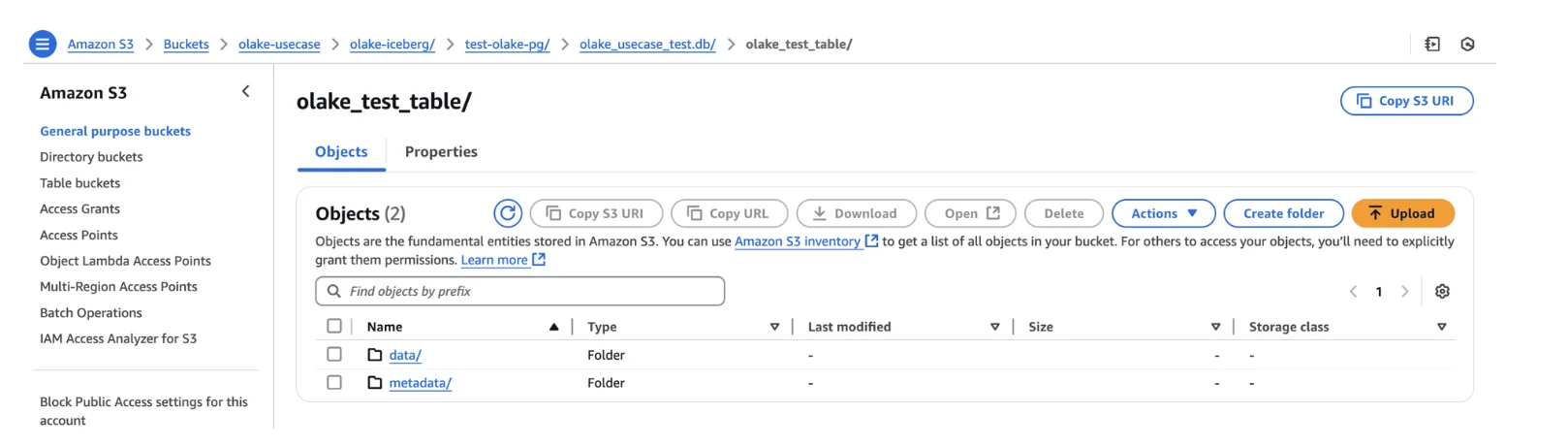
With this setup, you now have a fully functional MySQL-to-Iceberg pipeline running with CDC support, ready for analytics, lakehouse querying, and downstream consumption by various query engines.
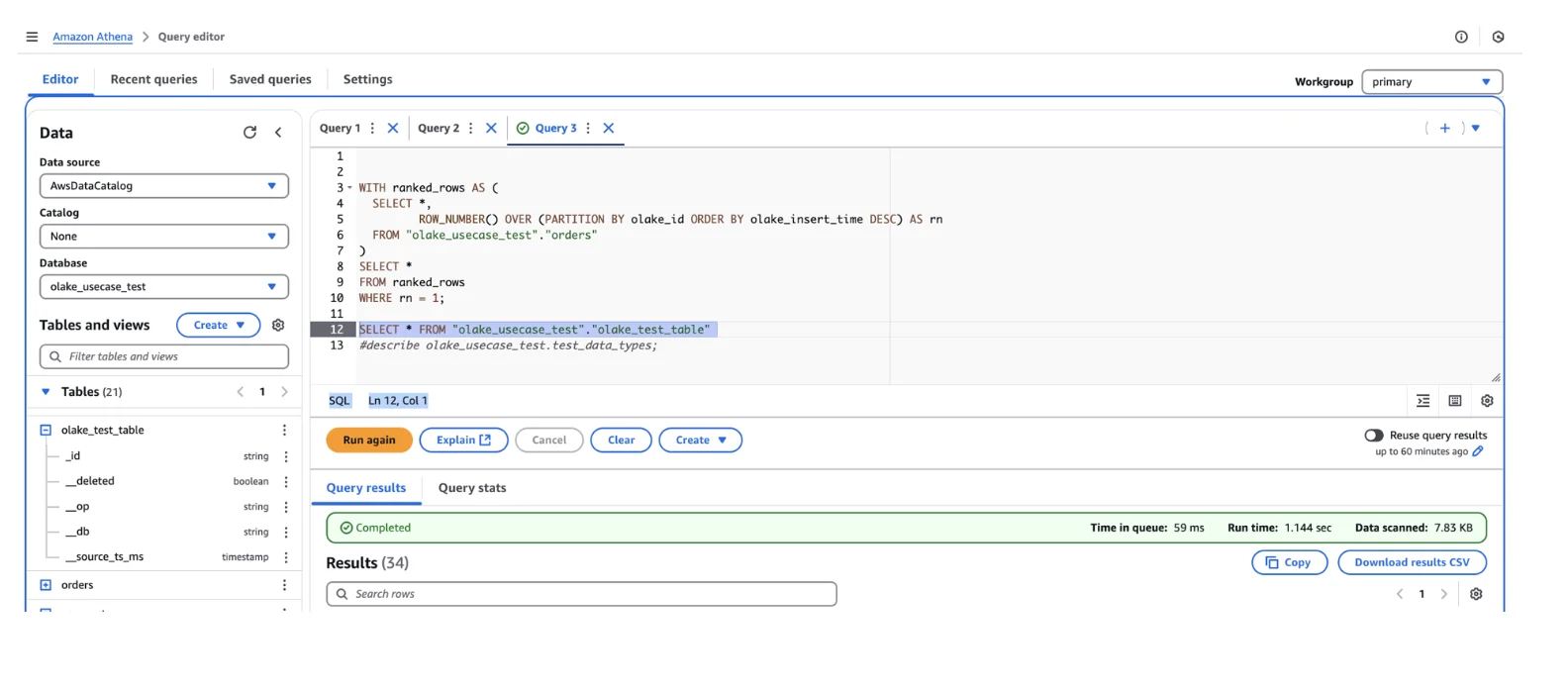
Step 7 (Optional): Query Iceberg Tables with AWS Athena
Validate your MySQL to Iceberg migration by configuring AWS Athena for direct querying:
Athena Configuration:
- Set up Athena to connect to your Glue Data Catalog
- Execute SQL queries against replicated Iceberg tables
- Verify data consistency, query performance, and schema accuracy
- Compare results with source MySQL data for validation
Benefits of Athena Integration:
- Serverless SQL querying without infrastructure management
- Pay-per-query pricing model for cost-effective analytics
- Direct Iceberg table access with full metadata support
- Integration with BI tools like QuickSight, Tableau, and Power BI
Production Best Practices for MySQL to Iceberg Replication
To keep your MySQL CDC pipeline running smoothly and your Iceberg analytics performing optimally, implement these proven strategies:
MySQL Binlog Configuration Best Practices
Set Up Binlogs Properly: Use ROW format and maintain sufficient retention so your pipeline doesn't miss updates during maintenance windows or temporary outages. Configure appropriate expire_logs_days or binlog_expire_logs_seconds settings based on your recovery requirements.
Monitor Binlog Growth: Track MySQL binlog size and rotation frequency to prevent disk space issues and ensure CDC continuity. Implement automated alerts for unusual binlog growth patterns that might indicate performance issues.
Smart Partitioning and Query Optimization
Choose Partition Columns Strategically: Select partition columns based on actual query patterns and data volume characteristics:
- Temporal Partitioning: Use created_at or updated_at for time-series analytics and event tables
- Dimensional Partitioning: Implement customer_id or region for customer analytics and dimensional data
- Hybrid Approaches: Combine temporal and dimensional partitioning for complex analytical workloads
Poor partitioning directly impacts performance: Improper partition choices result in slow queries and high file scan costs, making this optimization crucial for lakehouse query performance.
Automated Maintenance and Monitoring
Monitor Pipeline Health: Keep continuous oversight of replication lag and sync errors. Small network hiccups or MySQL configuration changes can disrupt CDC streams if not detected early.
Plan for Schema Changes: Database columns will be added, modified, or renamed during normal development cycles. Ensure your Iceberg pipeline and downstream consumers can evolve seamlessly with schema changes.
State Management and Recovery Procedures
Maintain State Backups: The state.json file serves as the single source of truth for replication progress. Implement regular backups to prevent:
- Accidental replication resets during maintenance operations
- Data loss scenarios during disaster recovery
- Manual recovery efforts that could introduce data inconsistencies
Automated Error Handling: With OLake, many of these operational concerns are handled automatically, but understanding the underlying mechanisms ensures successful production MySQL to Iceberg deployments.
Conclusion: Transforming MySQL Analytics with Apache Iceberg
MySQL remains an excellent choice for transactional applications, but it's not built for analytics at scale. By implementing MySQL to Apache Iceberg replication, you achieve the best of both worlds: fast, reliable OLTP performance on MySQL and powerful, cost-effective analytics on open lakehouse tables.
Immediate Benefits of Migration
Performance Transformation: Companies like Memed achieved 60x improvement in data processing time (from 30-40 minutes to 40 seconds), while Netflix saw orders of magnitude faster queries compared to previous systems.
Cost Optimization: Natural Intelligence completed migration with zero downtime while establishing a modern, vendor-neutral platform that scales with evolving analytics needs. Organizations typically see 50-75% cost savings compared to traditional warehouse approaches.
Operational Excellence: With OLake's automated approach, you get:
- Full + incremental synchronization (both JDBC and binlog-based) with minimal setup complexity
- Comprehensive schema evolution support for multiple tables and data types
- Open file format compatibility that integrates seamlessly with your preferred query engines
- Production-ready monitoring and state management for enterprise reliability
Strategic Advantages for Modern Data Architecture
Future-Proof Technology Stack: Apache Iceberg's open table format prevents vendor lock-in while supporting multiple query engines simultaneously. This architectural approach enables organizations to adapt to changing analytics requirements without costly data migrations or tool replacements.
Scalability Without Limits: Unlike MySQL's single-node constraints, Iceberg tables support petabyte-scale analytics on cost-effective object storage. This scalability foundation supports long-term growth without architectural limitations.
Real-Time Analytics Capabilities: MySQL CDC integration ensures your lakehouse tables stay continuously synchronized with operational data, enabling real-time dashboards, machine learning pipelines, and responsive business intelligence.
Getting Started with Your Migration
The combination of MySQL's transactional reliability and Iceberg's analytical capabilities provides a robust foundation for modern, data-driven decision making. Whether you're building real-time dashboards, implementing advanced analytics, or developing machine learning pipelines, this replication strategy offers the scalability and flexibility that modern organizations require.
Start your MySQL to Apache Iceberg migration today and unlock the full analytical potential of your operational data without compromising database performance. The proven success stories from Netflix, Natural Intelligence, Memed, and other enterprises demonstrate that this architectural transformation delivers measurable improvements in query performance, cost efficiency, and operational simplicity.
As the data landscape continues evolving toward open, cloud-native architectures, organizations embracing Apache Iceberg lakehouse patterns position themselves for scalable growth while maintaining operational excellence. The question isn't whether to migrate from MySQL analytics, it's how quickly you can implement this transformation to stay competitive in today's data-driven economy.
Frequently Asked Questions
What is the difference between MySQL and Apache Iceberg?
MySQL is an OLTP (Online Transaction Processing) database designed for handling live application transactions with fast reads and writes. Apache Iceberg is an open table format designed for large-scale analytics on data lakes, optimized for complex queries and petabyte-scale data storage.
How does CDC (Change Data Capture) work with MySQL?
CDC tracks changes in MySQL by reading the binary log (binlog), which records every insert, update, and delete operation. OLake connects to the binlog and streams these changes in real-time to your Iceberg tables without impacting production performance.
Can I replicate MySQL to Iceberg without CDC?
Yes! OLake offers JDBC-based Full Refresh and Bookmark-based Incremental sync modes. If you don't have permissions to enable binlogs, you can start syncing immediately with standard MySQL credentials.
What happens to my MySQL schema changes?
OLake automatically handles schema evolution. When you add, drop, or modify columns in MySQL, these changes are detected and propagated to your Iceberg tables without breaking your pipeline.
How much does it cost to store data in Iceberg vs MySQL?
Iceberg storage on S3 costs approximately $0.023 per GB/month, compared to MySQL RDS storage at $0.115 per GB/month - that's 5x cheaper. Plus, you separate compute from storage, so you only pay for queries when you run them.
What query engines can I use with Iceberg tables?
Apache Iceberg is an open format compatible with: Trino, Presto, Apache Spark, DuckDB, AWS Athena, Snowflake, Databricks, and many others. You can switch engines anytime without rewriting data.
How do I handle partitioning for optimal query performance?
Choose partition columns based on your query patterns: use timestamp fields (created_at, updated_at) for time-series queries, or dimensional fields (customer_id, region) for lookup queries. OLake supports regex-based partitioning configuration.
Is the initial full load safe for large MySQL databases?
Yes! OLake uses primary key-based chunking to load data in batches without locking your MySQL tables. The process runs in parallel and can be paused/resumed if needed.
What happens if my replication pipeline fails?
OLake maintains a state.json file that tracks replication progress. If the pipeline fails, it automatically resumes from the last successfully processed position, ensuring no data loss.
Can I query both MySQL and Iceberg simultaneously?
Absolutely! Your MySQL database continues serving production traffic while Iceberg handles analytics. This separation ensures operational workloads never compete with analytical queries for resources.
Happy syncing! 🧊🐘
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.