OLake Architecture - Fast, Modular & Scalable Data Pipeline

update: [18.02.2025]
- We support S3 data partitioning - refer docs here
- Support of Iceberg coming next week.
When building OLake, our goal was simple: Fastest DB to Data LakeHouse (Apache Iceberg to start) data pipeline.
Checkout GtiHub repository for OLake - https://github.com/datazip-inc/olake
Over time, many of us who’ve worked with data pipelines have dealt with the toil of building one-off ETL scripts, battling performance bottlenecks, or worrying about vendor lock-in.
With OLake, we wanted a clean, open-source solution that solves these problems in a straightforward, high-performing manner.
In this blog, I’m going to walk you through the architecture of OLake—how we capture data from MongoDB, push it into S3 in Apache Iceberg format or other data Lakehouse formats, and handle everything from schema evolution to high-volume parallel loads.
Architectural Overview
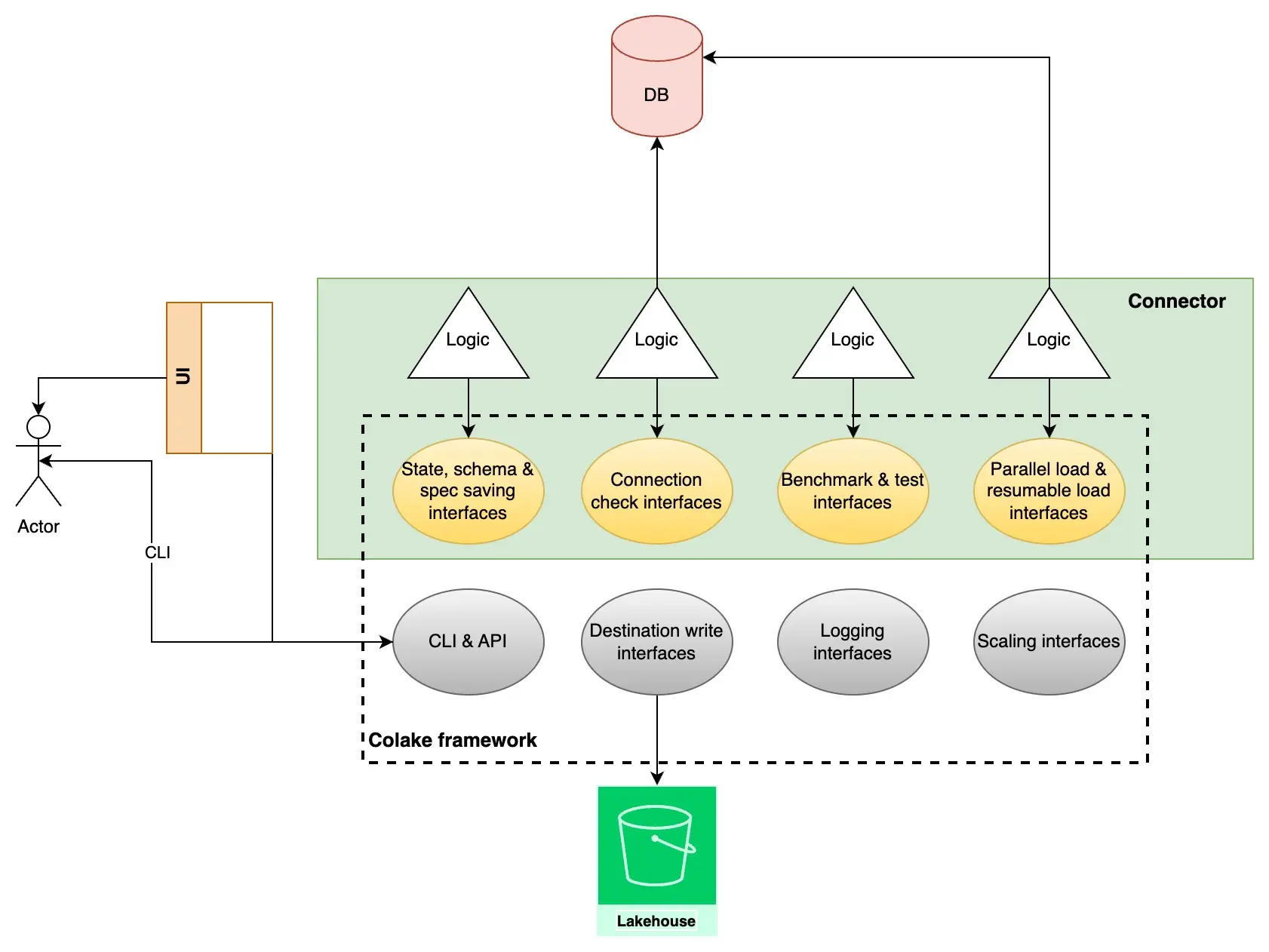
At a high level, OLake reads from source systems (currently focused on MongoDB) and writes directly to configurable destinations such as local Parquet, S3 Iceberg Parquet. Our architecture is built around four main components:
Components
-
CLI (Command Line Interface, v0), full fledged UI in progress
-
Framework (CDK)
-
Connectors (Drivers)
-
Writers
-
Testing Setup
-
Unit Testing
-
Integration Testing
-
Workflow testing
-
Time limit based testing to maintain the performance
-
-
-
Monitoring & Alerting
-
SDK
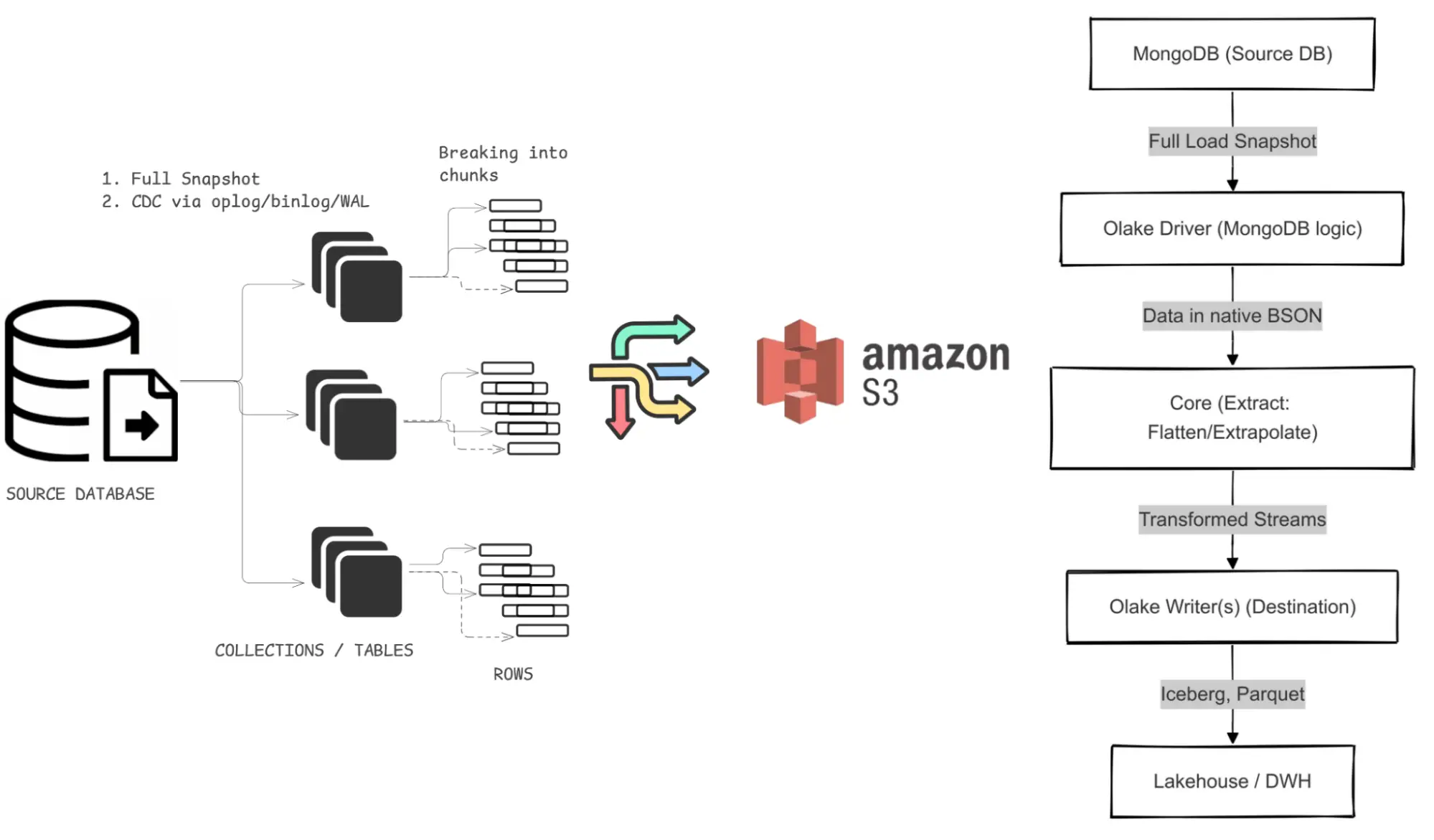
We wanted to keep these components as modular as possible so each one can excel at its responsibilities. Here’s a simplified conceptual diagram showing how data flows through OLake.
Here’s how it all ties together:
-
Initial Snapshot: We run a full collection read from MongoDB. That happens via query firing.
-
Change Data Capture (CDC): After completing the snapshot, OLake sets up MongoDB change streams (built on oplogs,a way for change data capture, CDC) for near real-time updates. For any record changes that occurred during the snapshot process, CDC reflects those changes as well just as initial snapshot finishes and from then on it continues to capture any other changes that occur in your source database (depending on your scheduled time).
-
The users have an option to set the number of parallel running threads so you can decide what’s the optimal configuration for you in terms of speed vs load on your mongodb cluster.
-
Transformation & Normalization: We flatten or extrapolate complex, semi-structured fields into relational streams. Level 0 flattening support in OLake and nested level 2,3,4 flattening of JSON coming soon.
-
Integrated Writes: We write the transformed data into destinations with minimal overhead.
-
Monitoring & Alerts: We keep a close watch on schema changes, raising alerts to help you address transformation logic issues or potential data loss early.
-
Logs: View logs to exactly know what the processes are doing under the hood.
-
Full refresh specific table - so you can quickly update a particular high priority table you need to sync immediately.
-
Testing support - Built in testing framework for normal sync tests, connection check for different flavours of the source databases.
Drivers (Connectors)
In OLake, each Driver (also called a Connector) embeds the logic necessary to interact with a particular source system. We started with MongoDB, but we’re planning connectors for Kafka, Postgres, Mysql and DynamoDB. The Driver’s job is to:
-
Perform Full Load: Issue queries to fetch an entire collection efficiently. We divide a collection into multiple chunks and process them parallel for faster replication.
-
Manage CDC: Set up streaming on the source system.
-
For MongoDB, that’s a matter of configuring change streams to read from the oplog.
-
We let the initial snapshot finish and then capture incremental changes so we never miss any updates that happen while the snapshot is in progress.
-
If someone adds a new collection after months of running the pipeline, we’ll do a fresh snapshot of that collection without stopping or disrupting the ongoing CDC for the existing ones.
Destinations
Our Destinations are tightly integrated so data can flow directly from the Driver into the destination, eliminating unnecessary read-and-write cycles to local disk. We plan on adding several Writers:
-
Local Parquet
-
S3 Simple Parquet
-
S3 Iceberg Parquet
Avoiding Bottlenecks with Integrated Destinations
By embedding Destinations inside each Driver, we cut down latencies significantly. Instead of collecting data in a queue or intermediary store, the Driver pushes records as soon as they’re extracted. This approach also avoids “blocking” reads while the Destinations are happening.
Core
The Core is the foundation on which OLake Drivers and Destinations rest. It gives us:
-
CLI & Commands:
-
spec: Returns a JSON Schema for the frontend to render form-based configurations. -
check: Validates config, streams, state files, and credentials. -
discover: Lists all streams and their schemas for a given source. -
sync: Orchestrates the extract, and load (ETL) process. -
Flags
-
--batch_size→ To push data into Destinations -
--thread_count→ Stream level concurrency i.e. how many parallel table execution
-
-
-
State Management: Ensures that the CDC streams can be resumed if they get interrupted.
-
Configuration: We store details about concurrency levels, connection credentials, and Destination configurations.
-
Logging & Monitoring: Through an
HTTPserver, we can track:-
How many processes are running concurrently.
-
The estimated finish time for the snapshot.
-
Live record counts and overall throughput.
-
Handling Schema Evolution & Error Recovery
When working with a schema-less store like MongoDB, we often encounter evolving document structures. OLake detects such changes in the source schema and raises alerts. We take care of new column creation or any non-breaking data type changes.
OLake’s Role in a Lakehouse Ecosystem
We emphasised early on that we wanted to avoid vendor lock-in. Hence, OLake stores data in open formats—like parquet—using a table format like Apache Iceberg.
This opens up the possibility for various query engines, including Spark, Trino, Flink, or even Snowflake external tables. By decoupling how data is written and how it’s consumed, we make sure you can leverage the best analytical tools without rewriting or re-ingesting the data.
Key Benefits:
-
Real-Time Replication: MongoDB’s oplogs feed near real-time changes, ensuring the lakehouse is promptly updated.
-
Equality deletes (Apache Iceberg) : We use this method to upsert the data which gives us the ability to go near real time when it comes to writing to a data lake.
Performance Benchmarks
We designed OLake from the ground up to focus on throughput, especially for high-volume data. We tested OLake on a Standard_D64as_v5 machine (64 vCPUs, 256 GiB RAM, 250 GB shared storage) connected to a three-node MongoDB replica set. Here’s a summary of the results:
-
Full Load
-
230 million rows (~664.81 GB) of Twitter data.
-
OLake completed this full load in 46 minutes, compared to several hours or more with other tools.
-
-
Incremental Sync
-
We measured ~50 million rows per month in ongoing incremental loads.
-
OLake handled this in 28.3 seconds, roughly 35,694 records/second, which was multiple times faster than the competition.
-
These results prove that with chunk-based parallel loading and direct Writer integration, we can handle hefty datasets much more efficiently than many existing solutions.
Detailed Data Flow
To illustrate how concurrency is handled, here’s a more extended ASCII diagram:
Each driver/writer pair can independently read chunks from MongoDB and write them directly to the target, while the Core monitors everything centrally.
Key Architectural Highlights
-
Native BSON Extraction: We pull data in its raw BSON form from MongoDB, decoding it on the ETL side. This approach maintains fidelity and boosts speed.
-
Parallel Chunking: Instead of serial reads, we split big collections into smaller virtual chunks to parallelize the process.
-
CDC Cursor Preservation: We never lose track of CDC offsets; even if a new large collection is added later, we do a full snapshot for it without interrupting ongoing incremental sync.
-
Custom Alerts: Configurable alerts for schema changes let you address issues quickly, preventing data corruptions or silent failures.
-
Open Format for Freedom: By embracing Parquet and Iceberg, we side-step vendor lock-in and enable multi-engine querying.
-
Both full snapshot and CDC are resumable as and when required by the customer.
-
Estimated time duration for the initial snapshot to be completed so you have a better insight on what’s going on inside the hood.
Concluding Remarks
In the future iterations we plan to:
-
Handle Nested JSON data (nested objects and nested arrays) flattening into either separate tables for arrays or horizontally exploding columns in case of object types.
-
Effortless deployment and maintenance with a single self-contained binary that simplifies setup, updates, and operational complexity
-
Flexible BYOC (Bring Your Own Cloud) support for both Cloud and On-Prem deployments to maintain complete data control and compliance
-
Enterprise-grade security ensuring no information leaves your infrastructure and seamless integration with existing security protocols
-
Instant transactional consistency providing sub-second accuracy for critical business operations and decision-making.
-
Resumable full loads capable of continuing even if the oplog expires, eliminating downtime and ensuring fault tolerance
-
Kafka integration as a destination and future connector framework for Kafka-like systems, protecting individual streams from cross-impact
-
Server and unified UI to manage all features in a user-friendly interface over the CLI
-
Horizontal scalability to handle increased throughput or growing data volumes as needed
-
Lake-based optimization and smart compaction using metadata tracking to determine optimal compaction times and maintain performance
-
Multiple cloud support including GCP and Azure, with multiple catalog support for enhanced flexibility and organization
Further Reading & References
Feel free to explore the official OLake documentation or check out our open-source repository to see how you can incorporate it into your own data pipelines.
By keeping performance, schema fidelity, and modular design at the forefront, OLake stands poised to simplify real-time data replication for modern analytics.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.