Deep Dive into OLake Architecture & Data Replication

OLake is an open-source tool designed for efficiently replicating databases to data lakes in Open table formats like Apache Iceberg. It provides a high-performance, scalable solution for data ingestion, enabling real-time analytics by efficiently moving data from operational databases to analytical storage systems.
With OLake, organizations can seamlessly bridge their operational databases with analytics platforms, unlocking deeper insights faster than traditional methods.
In this blog post, we'll dive deep into OLake's architecture and explain how it works under the hood.
The Problem OLake Solves
Before diving into the architecture, let's understand the problem OLake addresses. Organizations often need to:
- Replicate data from operational databases (MongoDB, PostgreSQL, MySQL) to data Lakehouses (Apache Iceberg), with supoort of sources like AWS S3 and Kafka comming soon.
- Supports backfills (full data refreshes) and real-time change data capture (CDC).
- Handle schema evolution and type conversions as Apache Iceberg supports. Read more about it here.
- The architecture is designed to scale efficiently with large datasets.
- Maintain data consistency and data partitioning (AWS S3 Partitioning and Iceberg Partitioning)
Traditional ETL tools often struggle with these requirements, especially when dealing with real-time data changes and large volumes. They typically introduce latency, schema compatibility issues, and scalability challenges.
OLake was built specifically to address these challenges. OLake natively supports replicating advanced data types, giving better performance like resulting in 4x to 10x faster large data loads. See detailed benchmarks here.
Its tailored optimizations and resilience mechanisms ensure stable and efficient operations even under high-load conditions.
High-Level Architecture
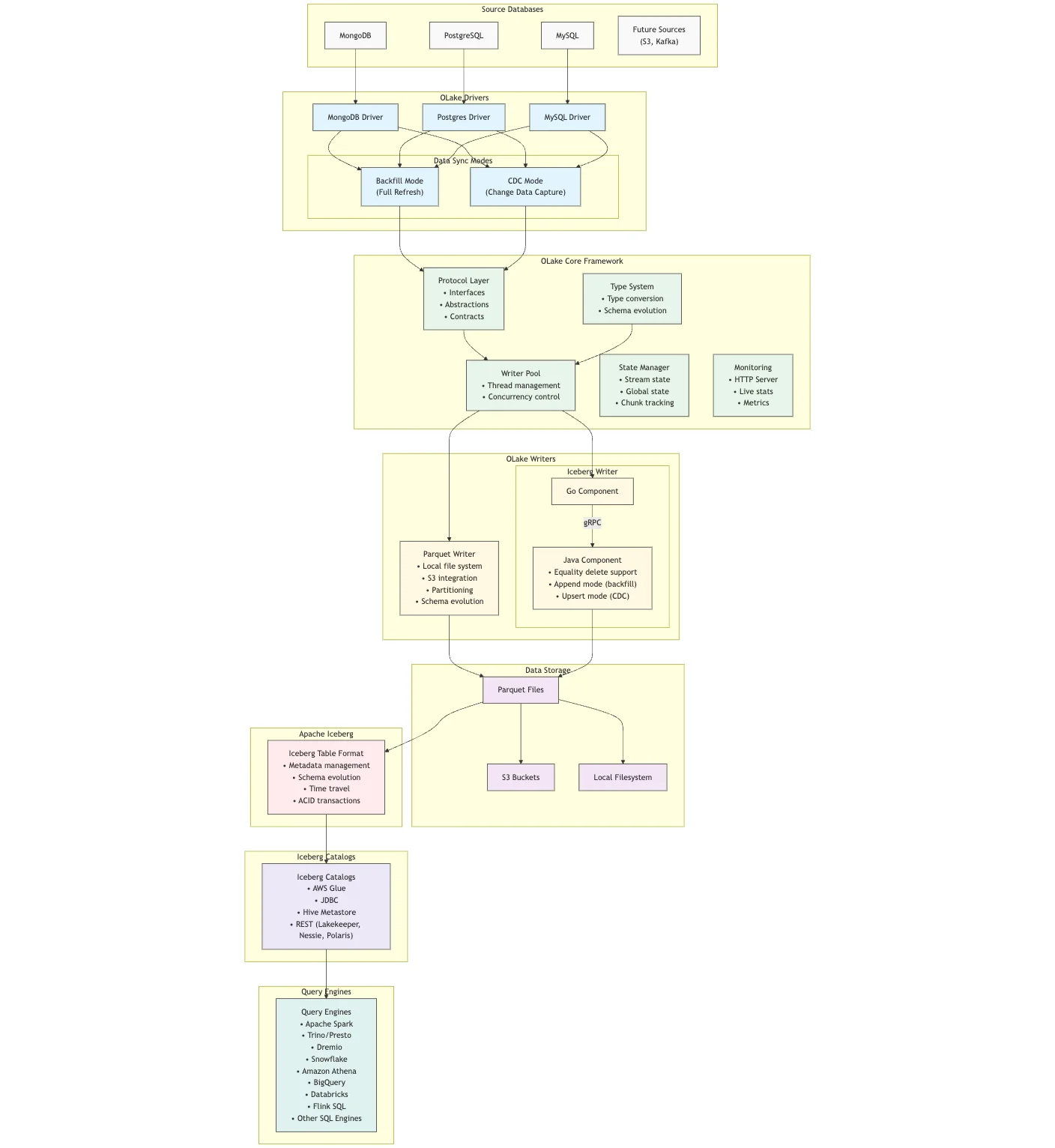
OLake follows a modular, plugin-based architecture with clear separation of concerns. At its core, OLake consists of:
- Core Framework: The central component that orchestrates the entire data flow
- Drivers (Sources): Connectors to source databases like MongoDB, PostgreSQL, and MySQL
- Writers (Destinations): Components that write data to destinations like Apache Iceberg and Parquet files
- Protocol Layer: Defines interfaces and abstractions for the entire system
- Type System: Handles data type conversions and schema management
Let's explore each of these components in detail.
Core Framework
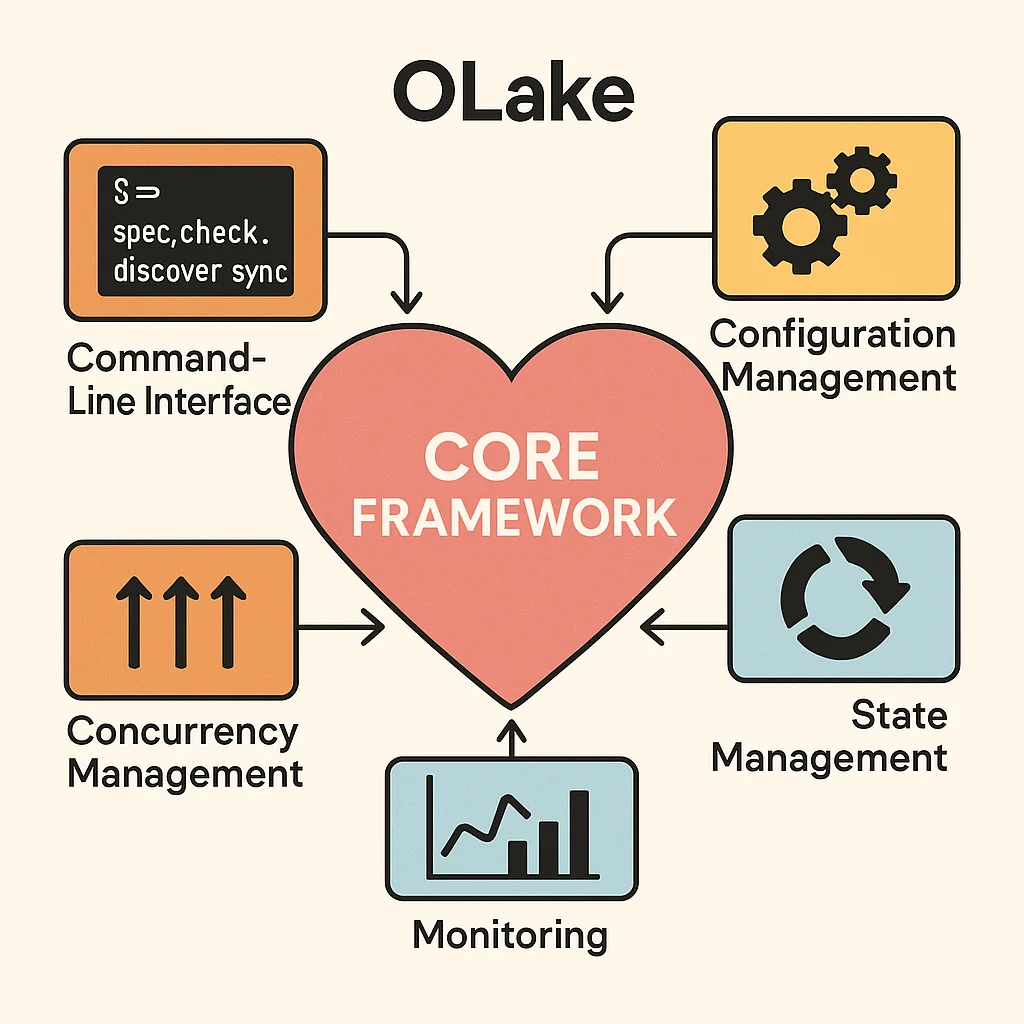
The core framework is the heart of OLake, providing:
- Modular Architecture: Each component (drivers, writers) is designed to be modular and extensible.
- Command-Line Interface: Built using Cobra, it exposes commands like
spec,check,discover, andsync - Configuration Management: Handles source, destination, streams, and state configurations
- Concurrency Management: Orchestrates parallel processing for efficient data extraction and loading
- State Management: Tracks synchronization progress for resumable operations
- Monitoring: Exposes metrics and statistics about running syncs in
stats.jsonfile in CLI mode.
This modularity allows developers to quickly introduce new sources or destinations without altering existing components, significantly reducing integration effort and potential bugs.
Protocol Layer
The protocol layer defines critical interfaces ensuring OLake's modularity and ease of extension. This design simplifies maintenance by clearly defining interaction points and responsibilities across components. Key interfaces include the Connector, Driver, and Writer interfaces, which standardize operations across sources and destinations.
type Connector interface {
GetConfigRef() Config
Spec() any
Check() error
Type() string
}
type Driver interface {
Connector
Setup() error
Discover(discoverSchema bool) ([]*types.Stream, error)
Read(pool *WriterPool, stream Stream) error
ChangeStreamSupported() bool
SetupState(state *types.State)
}
type Writer interface {
Connector
Setup(stream Stream, opts *Options) error
Write(ctx context.Context, record types.RawRecord) error
Normalization() bool
Flattener() FlattenFunction
EvolveSchema(bool, bool, map[string]*types.Property, types.Record) error
Close() error
}
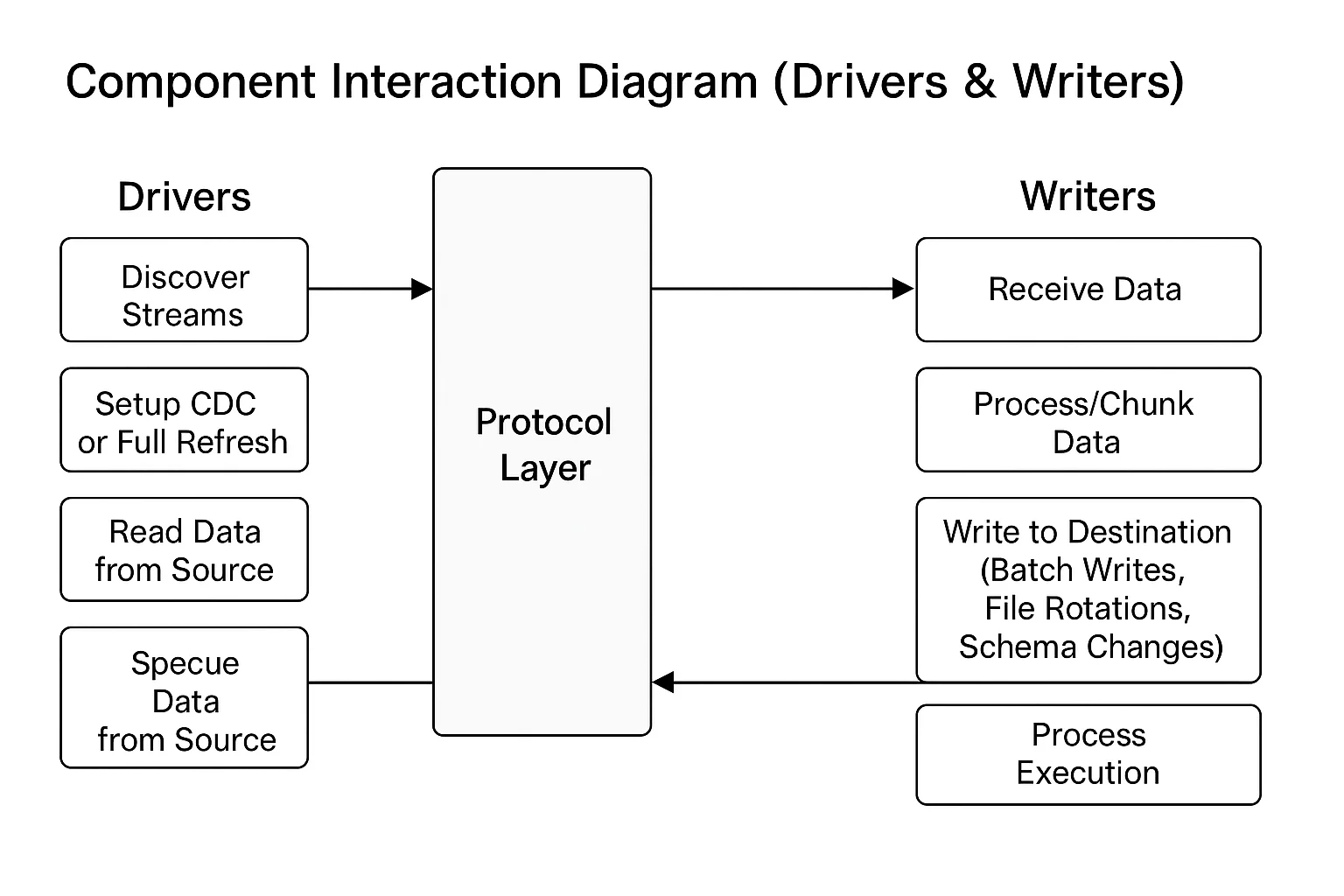
These interfaces ensure that all components adhere to a consistent contract, making the system more maintainable and extensible.
Drivers (Sources)
OLake supports multiple database sources through its driver architecture. Each driver implements the Driver interface and provides specific functionality for its database type.
MongoDB Driver
The MongoDB driver connects to MongoDB databases and supports:
- Full Refresh Mode: Reads all data from collections in batches
- CDC Mode: Uses MongoDB's change streams to capture real-time changes (oplog).
- Parallel Processing: Splits large collections into chunks for parallel processing
- Schema Detection: Automatically detects and adapts to MongoDB's flexible schema
The MongoDB driver handles MongoDB-specific data types and converts them to OLake's internal representation. For CDC, it uses MongoDB's change streams API to capture inserts, updates, and deletes in real-time.
Refer -> MongoDB documentation for more details.
func (m *Mongo) changeStreamSync(stream protocol.Stream, pool *protocol.WriterPool) error {
// Setup change stream with MongoDB
changeStreamOpts := options.ChangeStream().SetFullDocument(options.UpdateLookup)
pipeline := mongo.Pipeline{
{{Key: "$match", Value: bson.D{
{Key: "operationType", Value: bson.D{{Key: "$in", Value: bson.A{"insert", "update", "delete"}}}},
}}},
}
// Process change events
cursor, err := collection.Watch(cdcCtx, pipeline, changeStreamOpts)
// ...
// Process each change event
for cursor.TryNext(cdcCtx) {
var record CDCDocument
if err := cursor.Decode(&record); err != nil {
return fmt.Errorf("error while decoding: %s", err)
}
// Convert to OLake record format and write
opType := utils.Ternary(record.OperationType == "update", "u",
utils.Ternary(record.OperationType == "delete", "d", "c")).(string)
rawRecord := types.CreateRawRecord(
utils.GetKeysHash(record.FullDocument, constants.MongoPrimaryID),
record.FullDocument,
opType,
int64(record.ClusterTime.T)*1000,
)
err := insert.Insert(rawRecord)
// ...
}
}
PostgreSQL Driver
The PostgreSQL driver utilizes logical replication slots and the pglogrepl library for capturing real-time database changes. This approach ensures minimal performance impact on the PostgreSQL database while maintaining data integrity during replication.
The PostgreSQL driver supports:
- Full Refresh Mode: Reads all data from tables in batches
- CDC Mode: Uses PostgreSQL's logical replication to capture changes
- Parallel Processing: Splits tables into chunks based on primary keys or CTIDs
- Schema Detection: Maps PostgreSQL data types to OLake's type system
As already mentioned, for CDC, the PostgreSQL driver uses the pglogrepl library to connect to PostgreSQL's logical replication slots and process WAL (Write-Ahead Log) entries using the native pgoutput protocol, scoped by a PostgreSQL publication.
Refer -> Postgres documentation for more details.
func (p *Postgres) RunChangeStream(pool *protocol.WriterPool, streams ...protocol.Stream) (err error) {
// Setup WAL connection
socket, err := waljs.NewConnection(ctx, p.client, config)
// ...
// Process WAL messages
return socket.StreamMessages(ctx, func(msg waljs.CDCChange) error {
pkFields := msg.Stream.GetStream().SourceDefinedPrimaryKey.Array()
opType := utils.Ternary(msg.Kind == "delete", "d",
utils.Ternary(msg.Kind == "update", "u", "c")).(string)
return inserters[msg.Stream].Insert(types.CreateRawRecord(
utils.GetKeysHash(msg.Data, pkFields...),
msg.Data,
opType,
msg.Timestamp.UnixMilli(),
))
})
}
MySQL Driver
The MySQL driver processes binlog events via the go-mysql library, allowing precise tracking of database changes and high throughput data replication.
The MySQL driver supports:
- Full Refresh Mode: Reads all data from tables in batches
- CDC Mode: Uses MySQL's binlog to capture changes
- Parallel Processing: Splits tables into chunks for parallel processing
- Schema Detection: Maps MySQL data types to OLake's type system
For CDC, the MySQL driver uses the go-mysql library to connect to MySQL and process change events from binlogs.
Refer -> MySQL documentation for more details.
Writers (Destinations)
OLake supports multiple destination (S3 and Apache Iceberg) types through its writer architecture. Each writer implements the Writer interface and provides specific functionality for its destination type.
Parquet Writer
The Parquet writer efficiently manages file rotation, naming, partitioning, and supports normalization (basic, Level 1) and schema evolution (as supported by Iceberg v2 tables).
The Parquet writer writes data to Parquet files, either locally or on AWS S3:
- Local File System: Writes Parquet files to a local directory.
- S3 Integration: Uploads Parquet files to an S3 bucket
- Partitioning: Supports partitioning data based on record fields.
- Normalization: OLake supports L1 (level 1) normalization
- Schema Evolution: Handles schema changes by creating new
.parquetfiles (for S3 and local dump only, not to Iceberg Database)
func (p *Parquet) Write(_ context.Context, record types.RawRecord) error {
partitionedPath := p.getPartitionedFilePath(record.Data)
// Create new partition file if needed
partitionFolder, exists := p.partitionedFiles[partitionedPath]
if !exists {
err := p.createNewPartitionFile(partitionedPath)
if err != nil {
return fmt.Errorf("failed to create partition file: %s", err)
}
partitionFolder = p.partitionedFiles[partitionedPath]
}
// Write record to Parquet file
fileMetadata := &partitionFolder[len(partitionFolder)-1]
var err error
if p.config.Normalization {
_, err = fileMetadata.writer.(*pqgo.GenericWriter[any]).Write([]any{record.Data})
} else {
_, err = fileMetadata.writer.(*pqgo.GenericWriter[types.RawRecord]).Write([]types.RawRecord{record})
}
// ...
return nil
}
Iceberg Writer
The Iceberg writer leverages Java-based gRPC components to fully support Iceberg operations, including handling complex transactions and schema evolution. By using Apache Iceberg, OLake provides robust features for time-travel queries and data consistency guarantees essential for analytics workloads.
The Iceberg writer writes data to Apache Iceberg tables and offers the following:
- Iceberg Integration: Writes data to Apache Iceberg tables
- Catalog Support: Works with AWS Glue, JDBC, and other Iceberg catalogs
- Java Integration: Uses a Java gRPC server for Iceberg operations
- Batch Processing: Buffers records for efficient writing
func (i *Iceberg) Write(_ context.Context, record types.RawRecord) error {
// Convert record to Debezium format
debeziumRecord, err := record.ToDebeziumFormat(i.config.IcebergDatabase, i.stream.Name(), i.config.Normalization)
if err != nil {
return fmt.Errorf("failed to convert record: %v", err)
}
// Add the record to the batch
flushed, err := addToBatch(i.configHash, debeziumRecord, i.client)
if err != nil {
return fmt.Errorf("failed to add record to batch: %v", err)
}
// If the batch was flushed, log the event
if flushed {
logger.Infof("Batch flushed to Iceberg server for stream %s", i.stream.Name())
}
i.records.Add(1)
return nil
}
Data Flow in OLake
Now that we understand the components, let's look at how data flows through OLake:
- Configuration: The user provides configuration files for the source (
source.json) and destination (destination.json) and OLake generatesstreams.json, andstate.jsonfile. - Discovery: The driver discovers available streams (tables/collections) along with their detailed metadata like data types, indexed columns, etc
- Sync Execution:
- For full refresh: Executes a complete data replication, optimized through chunking and parallel processing.
- For CDC: Continuously captures and applies real-time database changes, ensuring data lake consistency and freshness.
- State Management: Sync state is maintained for resumable operations
- Monitoring: HTTP server exposes live stats about running syncs
Let's walk through a typical sync operation:
Full Refresh Sync
- The user runs the
synccommand (without passing the--stateargument for the first time). - OLake initializes the driver and writer based on the configurations.
- The driver discovers available streams and matches them with the streams.
- For each selected stream, OLake:
- Splits the data into chunks for parallel processing
- Creates writer threads for the destination
- Reads data from the source in batches
- Converts the data type to OLake's supported Data types.
- Writes the data to the destination
- Updates the state to track progress in
state.jsonfile andstats.jsonfile.
- Once all streams are processed, OLake finalizes the sync and reports statistics.
- It automatically generates a state file which can be used later to initial incremental or CDC sync. So that it can only process the newly arrived data.
CDC Sync
- The user runs the
synccommand with appropriate configuration files with--stateflag and state file (that stored the last sync state / pointer). - OLake initializes the driver and writer based on the configurations.
- The driver discovers available streams (with new column or table addition / modifications for schema evolution or schema data type changes) and matches them with the catalog.
- For each selected stream with CDC mode, OLake:
- Checks if a full refresh is needed (first run or incomplete previous run)
- If needed, performs a full refresh first (in case a new table is added or schema changes)
- Sets up a change stream connection to the source database
- Creates writer threads for the destination
- Captures change events (inserts, updates, deletes) from the last processed state (as noted by the state file cursor or pointer)
- Writes the events to the destination
- Updates the state to track progress
- The CDC process ends if there are no new updates. Use Airflow on ec2 or k8s to schedule the sync process periodically. Related docs and blogs on running OLake on AWS EC2 and Kubernetes.
Sync Execution in OLake: Advanced Chunking Strategies and Parallel Processing
To process large amounts of data efficiently, OLake employs DB specific chunking strategies. These strategies are critical for optimizing performance during Full Refresh (Backfill Mode) operations.
Database-Specific Chunking Strategies
PostgreSQL Chunking Strategies
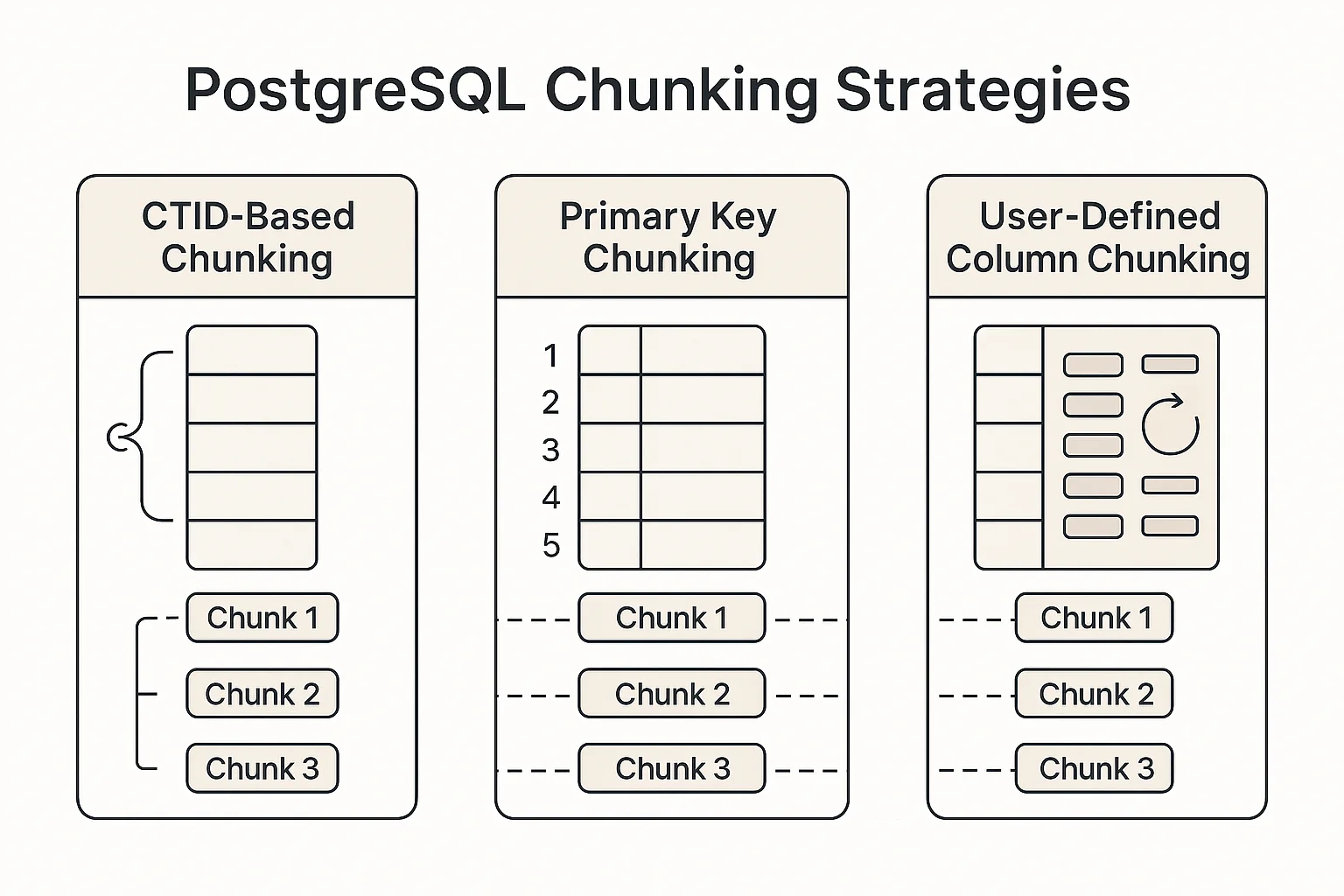
PostgreSQL supports three distinct chunking strategies, each optimized for different table structures:
1. CTID-Based Chunking
- Uses PostgreSQL's physical row identifier (CTID)
- Ideal for tables without primary keys or unique indexes
- Divides tables based on physical storage locations
func (p *Postgres) splitTableByCTID(ctx context.
Context, stream protocol.Stream) ([]types.Chunk,
error) {
var minCTID, maxCTID string
// Query to get min and max CTID values
err := p.client.QueryRowContext(ctx, fmt.Sprintf
("SELECT MIN(ctid), MAX(ctid) FROM %s", stream.
FullyQualifiedName())).Scan(&minCTID, &maxCTID)
// Split into chunks based on CTID ranges
}
2. Primary Key Chunking
- Uses table's primary key for chunking
- Optimal for tables with integer primary keys
- Creates evenly distributed chunks based on key ranges
func (p *Postgres) splitTableByPrimaryKey(ctx
context.Context, stream protocol.Stream, pkColumn
string) ([]types.Chunk, error) {
var minID, maxID, totalRows int64
// Query to get min, max, and count of primary
key values
err := p.client.QueryRowContext(ctx, fmt.Sprintf
("SELECT MIN(%s), MAX(%s), COUNT(*) FROM %s",
pkColumn, pkColumn, stream.FullyQualifiedName
())).Scan(&minID, &maxID, &totalRows)
// Calculate optimal chunk size based on total
rows and max threads
chunkSize := calculateOptimalChunkSize
(totalRows, p.config.MaxThreads)
// Create chunks with evenly distributed ID
ranges
}
3. User-Defined Column Chunking
- Uses any indexed column specified by the user
- Flexible approach for tables with non-standard structures
- Supports both numeric and non-numeric columns
func (p *Postgres) splitTableByColumn(ctx context.
Context, stream protocol.Stream, column string) ([]
types.Chunk, error) {
// Determine column type
var columnType string
err := p.client.QueryRowContext(ctx, `
SELECT data_type FROM information_schema.
columns
WHERE table_schema = $1 AND table_name = $2
AND column_name = $3
`, stream.Namespace(), stream.Name(), column).
Scan(&columnType)
// Apply different chunking strategies based on
column type
if isNumericType(columnType) {
return p.splitTableByNumericColumn(ctx,
stream, column)
} else {
return p.splitTableByNonNumericColumn(ctx,
stream, column)
}
}
MongoDB Chunking Strategies
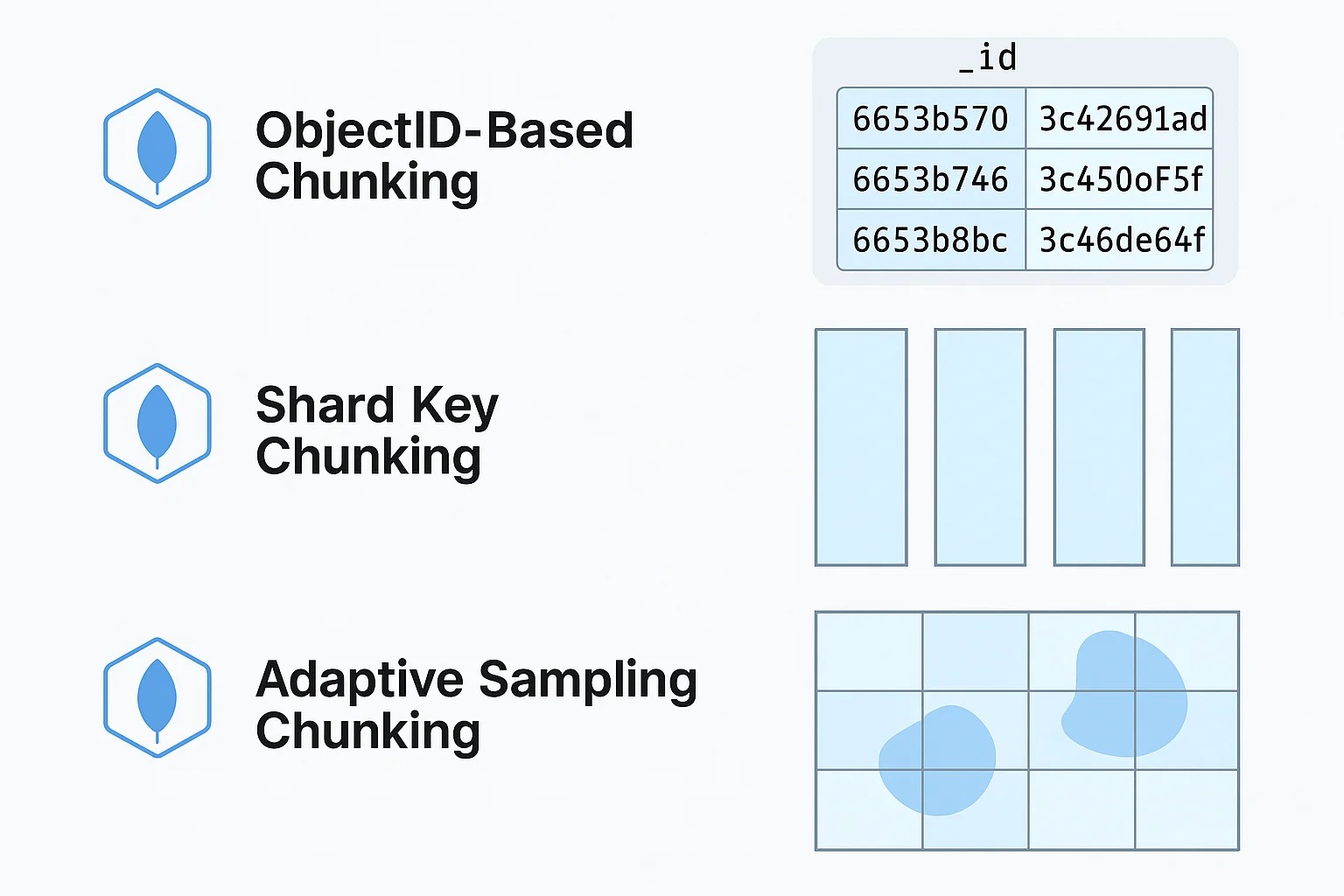
MongoDB implements specialized chunking strategies optimized for document collections:
1. ObjectID-Based Chunking
- Uses MongoDB's native
ObjectIDfor time-based chunking - Particularly efficient for collections with default
_idfield - Creates chunks based on
ObjectIDtimestamp component
func (m *Mongo) splitCollectionByObjectID(ctx
context.Context, collection *mongo.Collection) ([]
types.Chunk, error) {
// Find min and max ObjectIDs
var minDoc, maxDoc bson.M
err := collection.Find(ctx, bson.M{}).Sort
("_id").Limit(1).One(&minDoc)
err = collection.Find(ctx, bson.M{}).Sort
("-_id").Limit(1).One(&maxDoc)
minID := minDoc["_id"].(primitive.ObjectID)
maxID := maxDoc["_id"].(primitive.ObjectID)
// Create time-based chunks using ObjectID
timestamp
return createObjectIDChunks(minID, maxID, m.
config.MaxThreads)
}
2. Shard Key Chunking (SplitVector Strategy)
- Utilizes existing shard keys for distributed collections
- Aligns with MongoDB's own sharding strategy for optimal performance
- Leverages MongoDB's
splitVectorcommand for intelligent chunking
func (m *Mongo) splitCollectionByShardKey(ctx
context.Context, collection *mongo.Collection,
shardKey string) ([]types.Chunk, error) {
// Execute splitVector command to get optimal
chunk boundaries
cmd := bson.D{
{"splitVector", collection.Database().Name()
+ "." + collection.Name()},
{"keyPattern", bson.M{shardKey: 1}},
{"maxChunkSize", m.calculateOptimalChunkSize
()},
}
var result bson.M
err := m.client.Database("admin").RunCommand
(ctx, cmd).Decode(&result)
// Convert split points to chunks
return convertSplitPointsToChunks(result
["splitKeys"].(primitive.A))
}
3. Adaptive Sampling Chunking
- Uses statistical sampling for collections without obvious chunk keys
- Analyzes data distribution to create balanced chunks
- Adapts to varying document sizes and collection characteristics
func (m *Mongo) splitCollectionByAdaptiveSampling
(ctx context.Context, collection *mongo.Collection)
([]types.Chunk, error) {
// Sample the collection to understand data
distribution
pipeline := mongo.Pipeline{
{{"$sample", bson.M{"size": 1000}}},
{{"$project", bson.M{"_id": 1}}},
}
cursor, err := collection.Aggregate(ctx,
pipeline)
// Analyze sample and create optimized chunks
return createAdaptiveChunks(cursor, collection,
m.config.MaxThreads)
}
MySQL Chunking Strategies
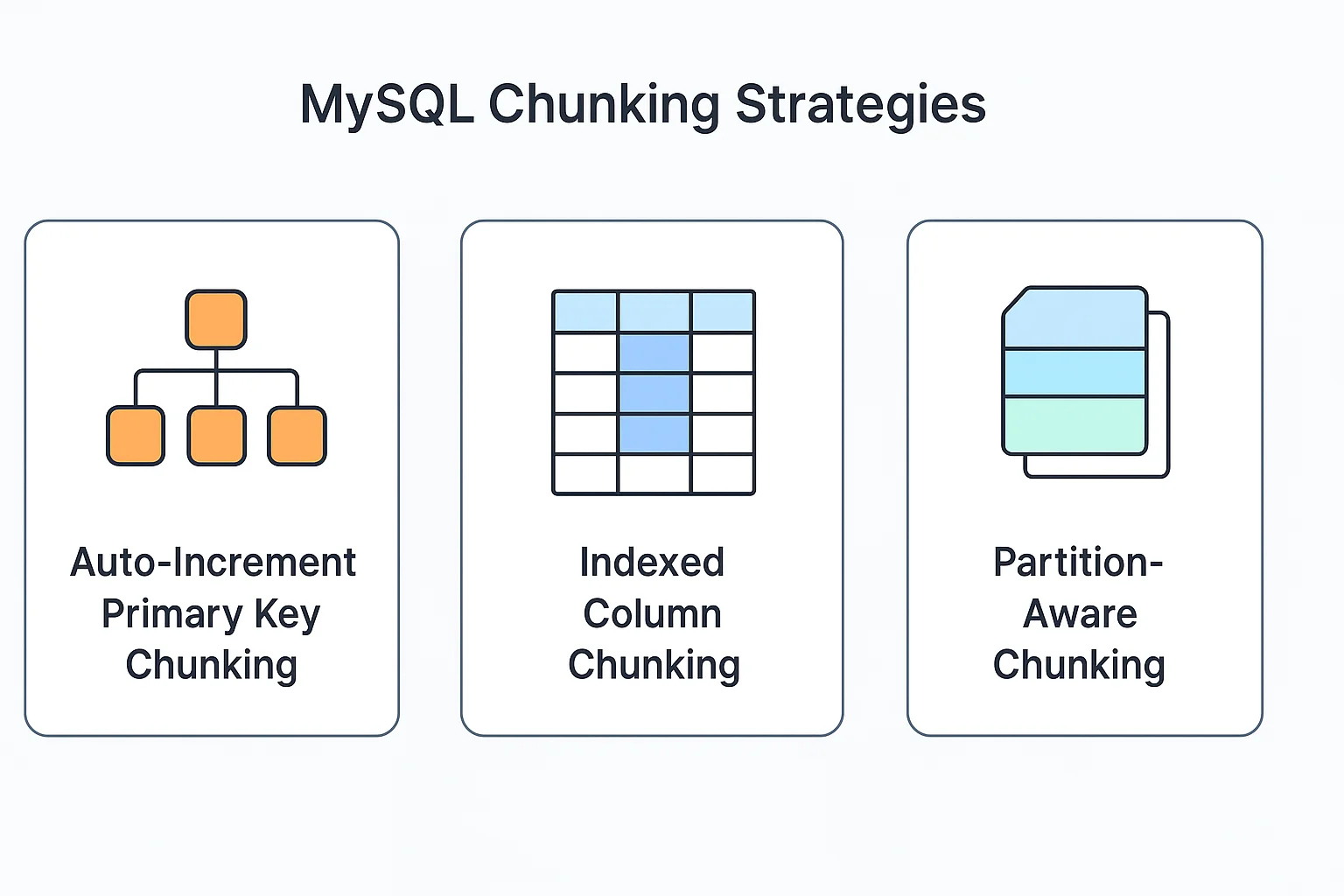
MySQL implements efficient chunking strategies tailored to its storage engine characteristics:
1. Auto-Increment Primary Key Chunking
- Optimized for MySQL's common auto-increment pattern
- Creates evenly sized chunks based on key ranges
- Particularly efficient with InnoDB storage engine
func (m *MySQL) splitTableByAutoIncrementPK(ctx
context.Context, tableName string, pkColumn string)
([]types.Chunk, error) {
var minID, maxID, totalRows int64
query := fmt.Sprintf("SELECT MIN(%s), MAX(%s),
COUNT(*) FROM %s", pkColumn, pkColumn, tableName)
err := m.db.QueryRowContext(ctx, query).Scan(&
minID, &maxID, &totalRows)
// Calculate optimal chunk size based on table
statistics
chunkSize := calculateMySQLOptimalChunkSize
(minID, maxID, totalRows, m.config.MaxThreads)
// Create evenly distributed chunks
return createIntegerRangeChunks(minID, maxID,
chunkSize)
}
2. Indexed Column Chunking
- Uses any indexed column for tables without auto-increment PKs
- Supports both numeric and string indexes
- Adapts chunk size based on column cardinality
func (m *MySQL) splitTableByIndexedColumn(ctx
context.Context, tableName string, column string) ([]
types.Chunk, error) {
// Get column statistics
var dataType string, cardinality int64
query := `
SELECT data_type, cardinality
FROM information_schema.columns c
JOIN information_schema.statistics s ON c.
table_schema = s.table_schema AND c.
table_name = s.table_name AND c.column_name
= s.column_name
WHERE c.table_name = ? AND c.column_name = ?
`
err := m.db.QueryRowContext(ctx, query,
tableName, column).Scan(&dataType, &cardinality)
// Apply type-specific chunking strategy
if isNumericType(dataType) {
return m.splitTableByNumericColumn(ctx,
tableName, column, cardinality)
} else {
return m.splitTableByStringColumn(ctx,
tableName, column, cardinality)
}
}
3. Partition-Aware Chunking
- Leverages MySQL's native partitioning for chunking
- Creates chunks aligned with existing table partitions
- Optimizes for already partitioned tables
- Implementation:
func (m *MySQL) splitTableByPartitions(ctx context.
Context, tableName string) ([]types.Chunk, error) {
// Query partition information
query := `
SELECT partition_name, partition_expression,
partition_description
FROM information_schema.partitions
WHERE table_name = ? AND partition_name IS
NOT NULL
`
rows, err := m.db.QueryContext(ctx, query,
tableName)
// Create chunks based on existing partitions
var chunks []types.Chunk
for rows.Next() {
var name, expr, desc string
err := rows.Scan(&name, &expr, &desc)
// Create chunk based on partition boundaries
chunks = append(chunks, createPartitionChunk
(expr, desc))
}
return chunks, nil
}
Parallel Processing Implementation
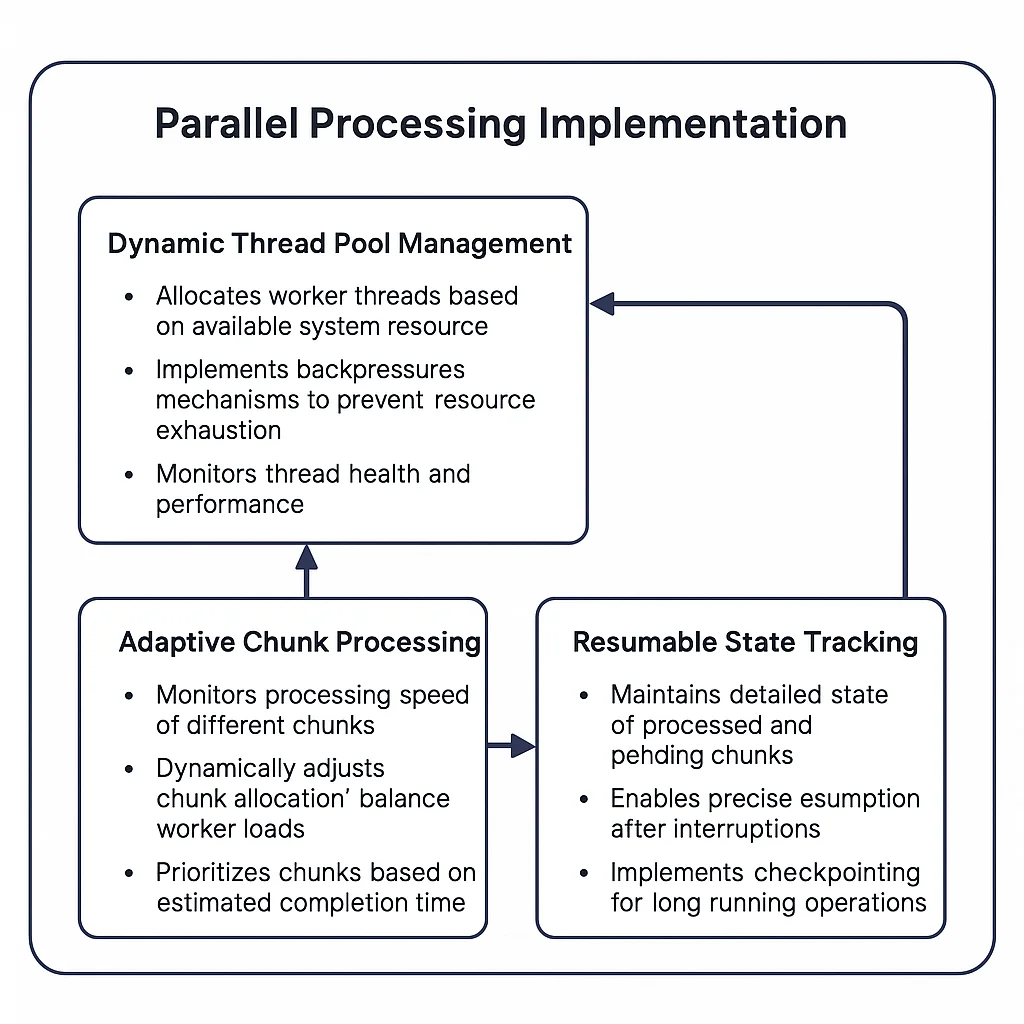
Once chunks are created, OLake processes them in parallel:
The parallel processing system includes:
- Dynamic Thread Pool Management
- Allocates worker threads based on available system resources
- Implements backpressure mechanisms to prevent resource exhaustion
- Monitors thread health and performance
- Adaptive Chunk Processing
- Monitors processing speed of different chunks
- Dynamically adjusts chunk allocation to balance worker loads
- Prioritizes chunks based on estimated completion time
- Resumable State Tracking
- Maintains detailed state of processed and pending chunks
- Enables precise resumption after interruptions
- Implements checkpointing for long-running operations
// Process chunks in parallel with controlled concurrency
return utils.Concurrent(backfillCtx, splitChunks, p.config.
MaxThreads, processChunk)
Performance Optimizations
OLake's chunking and parallel processing approach includes several key optimizations:
- Memory-Aware Chunk Sizing
- Adjusts chunk sizes based on available system memory
- Prevents out-of-memory errors during processing
- Optimizes for different data types and column widths
- I/O-Optimized Chunk Boundaries
- Aligns chunks with database storage patterns
- Minimizes random I/O operations
- Leverages database-specific access patterns
- Load Balancing
- Monitors worker thread performance
- Redistributes work to prevent straggler threads
- Adapts to varying processing speeds across chunks
- Resource Utilization
- Scales thread count based on available CPU cores
- Implements backoff strategies during high system load
- Prioritizes critical system resources
Configuration Options
The chunking behavior can be configured through several options for DB specific chunking strategies:
{
"max_threads": 50, // max threads for parallel processing
"chunking_strategy": "", // timestamp, default uses Split-Vector Strategy if left empty,
"backoff_retry_count": 2, // number of retries for chunk processing
}
You can add how partitioning should be done in streams.json file for each stream. For example:
For AWS S3 Data Partitioning
{
"selected_streams": {
"namespace": [
{
"stream_name": "table1",
"partition_regex": "/{column_name, default_value, granularity}",
"normalization": false,
"append_only": false
},
{
"stream_name": "table2",
"partition_regex": "",
"normalization": false,
"append_only": false
}
]
},
"streams": [
{
"stream": {
"name": "table1",
"namespace": "namespace",
"sync_mode": "cdc"
}
},
{
"stream": {
"name": "table2",
"namespace": "namespace",
"sync_mode": "cdc"
}
}
]
}
The partition_regex field in the stream configuration specifies how the data should be partitioned.
For Apache Iceberg Data Partitioning
{
"selected_streams": {
"my_namespace": [
{
"stream_name": "my_stream",
"partition_regex": "/{timestamp_col, day}/{region, identity}",
"normalization": false,
"append_only": false
}
]
}
}
Full refresh happens when the state file either is not provided or it is provided but the CDC cursor is outdated and expired by the DB.
This chunking and parallel processing approach significantly improves performance by:
- Maximizing throughput with concurrent processing
- Optimizing memory usage by processing manageable chunks
- Enabling efficient use of multi-core systems
- Provides resumable full-load by saving state of each chunk
This parallel chunking strategy is a key factor in OLake's high-performance data replication capabilities, especially for large datasets.
Concurrency Model in OLake
OLake implements a multi-level concurrency model that adapts to different sync modes and database types, optimizing performance while maintaining system stability.
Core Concurrency Architecture
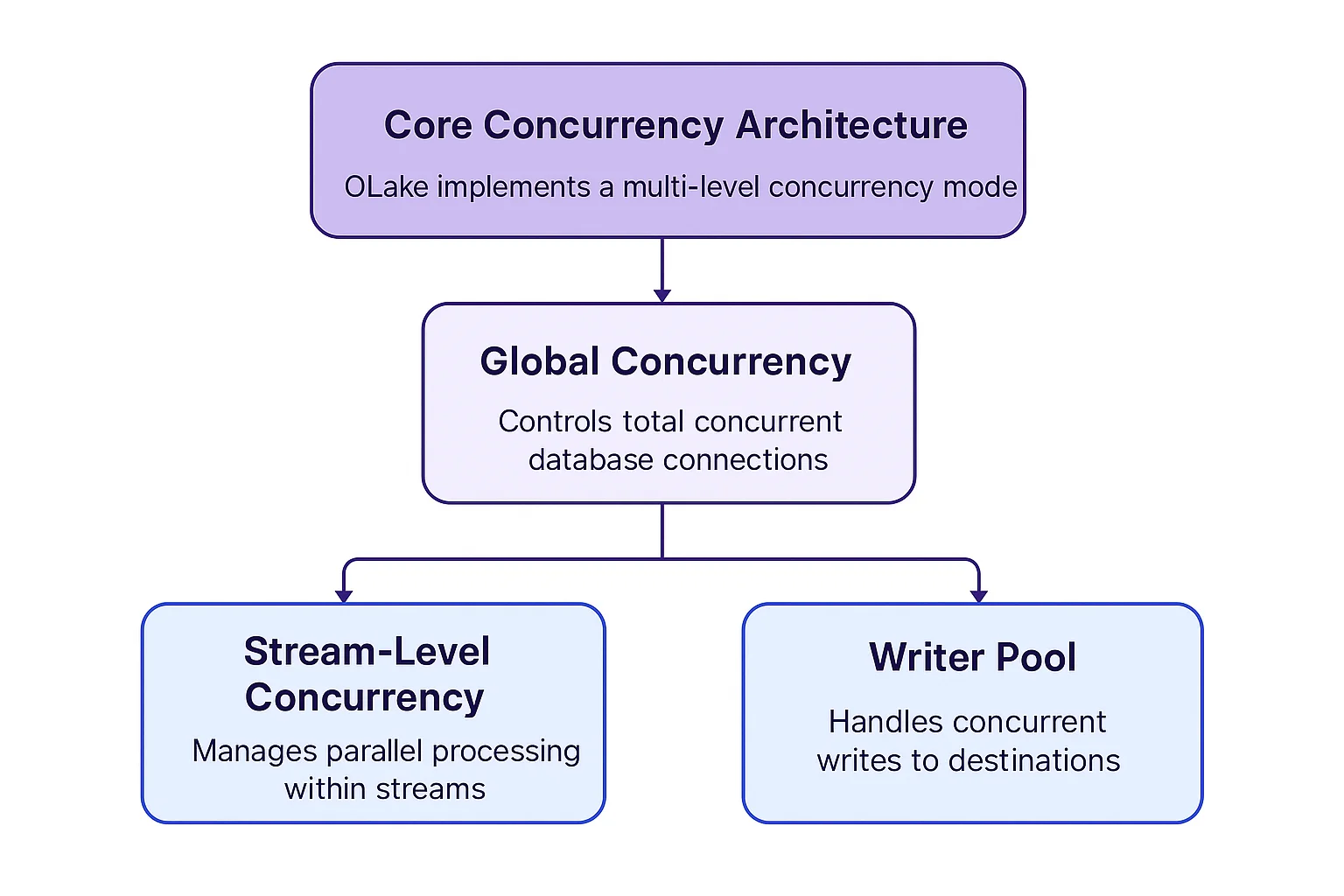
OLake's concurrency model strategically manages resources across three levels—Global, Stream-Level, and Writer Pool—to optimize throughput without overwhelming systems.
1. Global Concurrency
// Global Stream concurrency group
GlobalCxGroup = utils.NewCGroupWithLimit(context.Background
(), concurrentStreamExecution)
- Purpose: Controls the total number of concurrent database connections
- Configuration: Set via
concurrent_stream_executionparameter - Implementation: Uses a context-based concurrency group with limits
- Benefit: Prevents overwhelming source databases with too many connections
2. Stream-Level Concurrency
- Purpose: Manages parallel processing within individual streams
- Implementation: Varies by sync mode (backfill vs. CDC) and database type
- Benefit: Optimizes throughput for each stream based on its characteristics
// Execute streams in Standard Stream mode
utils.ConcurrentInGroup(GlobalCxGroup,
standardModeStreams, func(_ context.Context, stream
Stream) error {
logger.Infof("Reading stream[%s] in %s", stream.ID(),
stream.GetSyncMode())
streamStartTime := time.Now()
err := connector.Read(pool, stream)
if err != nil {
return fmt.Errorf("error occurred while reading
records: %s", err)
}
logger.Infof("Finished reading stream %s[%s] in %s",
stream.Name(), stream.Namespace(), time.Since
(streamStartTime).String())
return nil
})
3. Writer Pool
- Purpose: Manages concurrent writing to destinations
- Implementation: Thread pool with dynamic scaling based on workload
- Benefit: Ensures writing doesn't become a bottleneck, even during high-volume operations
// Initialize writer pool with multiple threads
pool, err := protocol.NewWriter(ctx, writerConfig)
if err != nil {
return fmt.Errorf("failed to initialize writer: %s",
err)
}
// Create a new writer thread
thread, err := pool.NewThread(ctx, stream, protocol.
WithIdentifier(fmt.Sprintf("thread-%d", threadID)))
Sync Mode-Specific Concurrency Models
OLake's concurrency model adapts to different sync modes, optimizing performance for each scenario:
Backfill (Full Refresh) Concurrency
For backfill operations, OLake implements a chunking-based concurrency model:
- Chunking: Divides data into logical chunks as described in the chunking strategies
- Thread Pool: Processes chunks in parallel up to
max_threadslimit - Load Balancing: Dynamically adjusts chunk allocation to balance worker loads
- State Tracking: Maintains progress of each chunk for resumability
// Process chunks in parallel with controlled concurrency
return utils.Concurrent(backfillCtx, splitChunks, p.config.
MaxThreads, processChunk)
CDC (Change Data Capture) Concurrency
CDC concurrency models vary significantly by database type:
MongoDB CDC Concurrency
MongoDB CDC implements a multi-threaded, stream-parallel approach:
- Per-Stream Parallelism: Each MongoDB stream can have multiple reader threads
- Change Stream Sharding: Distributes change events across multiple threads
- Pipeline Filtering: Uses MongoDB's aggregation pipeline for efficient filtering
- Resume Token Management: Coordinates resume tokens across parallel readers
// Execute CDC streams in parallel
utils.ConcurrentInGroup(GlobalCxGroup, cdcStreams, func(_
context.Context, stream Stream) error {
return m.changeStreamSync(stream, pool)
})
func (m *Mongo) changeStreamSync(stream protocol.Stream,
pool *protocol.WriterPool) error {
// Create multiple writer threads for this stream
for i := 0; i < m.config.MaxCDCThreads; i++ {
thread, err := pool.NewThread(cdcCtx, stream,
protocol.WithIdentifier(fmt.Sprintf
("cdc-thread-%d", i)))
// Each thread processes a subset of change events
}
// ...
}
PostgreSQL CDC Concurrency
PostgreSQL CDC uses a single-reader, multi-writer architecture:
- Single WAL Reader: One thread reads the PostgreSQL Write-Ahead Log
- Logical Replication Slot: Uses PostgreSQL's logical replication infrastructure
- Multi-Stream Demultiplexing: Routes changes to appropriate stream writers
- Parallel Writers: Multiple writer threads process changes for different streams
- Transaction Grouping: Maintains transaction boundaries for consistency
func (p *Postgres) RunChangeStream(pool *protocol.
WriterPool, streams ...protocol.Stream) (err error) {
// Single reader thread for WAL
socket, err := waljs.NewConnection(ctx, p.client,
config)
// Multiple writer threads
inserters := make(map[string]*protocol.ThreadEvent)
for _, stream := range streams {
// Create writer thread for each stream
inserters[stream.ID()], err = pool.NewThread(ctx,
stream)
}
// Process WAL messages and distribute to appropriate
writers
return socket.StreamMessages(ctx, func(msg waljs.
CDCChange) error {
return inserters[msg.Stream].Insert(types.
CreateRawRecord(
utils.GetKeysHash(msg.Data, pkFields...),
msg.Data,
opType,
msg.Timestamp.UnixMilli(),
))
})
}
MySQL CDC Concurrency
MySQL CDC also employs a single-reader, multi-writer pattern:
- Single Binlog Reader: One thread reads the MySQL binary log
- Binlog Position Tracking: Maintains precise position for resumability
- Table Filtering: Efficiently filters events by table at the binlog level
- Parallel Writers: Multiple writer threads for different streams
- Transaction Boundary Preservation: Maintains transaction integrity
func (m *MySQL) StartCDC(pool *protocol.WriterPool,
streams ...protocol.Stream) error {
// Single binlog reader
binlogReader, err := mysql.NewBinlogReader(m.config.
BinlogConfig)
// Multiple writer threads
writers := make(map[string]*protocol.ThreadEvent)
for _, stream := range streams {
writers[stream.ID()], err = pool.NewThread(ctx,
stream)
}
// Process binlog events and route to appropriate
writers
return binlogReader.ReadEvents(func(event *mysql.
BinlogEvent) error {
streamID := getStreamIDFromEvent(event)
if writer, exists := writers[streamID]; exists {
return writer.Insert(convertEventToRecord
(event))
}
return nil
})
}
Advanced Concurrency Features
Adaptive Concurrency Control
OLake implements adaptive concurrency that responds to system conditions:
- System Load Monitoring: Tracks CPU, memory, and I/O utilization
- Dynamic Adjustment: Increases or decreases concurrency based on system load
- Backpressure Mechanism: Slows down processing when system is overloaded
- Resource Optimization: Maximizes throughput while preventing resource exhaustion
// Monitor system load and adjust concurrency
go func() {
for {
select {
case <-ctx.Done():
return
case <-time.After(monitorInterval):
systemLoad := getSystemLoad()
if systemLoad > highLoadThreshold {
// Reduce concurrency
adjustConcurrencyLimit(GlobalCxGroup,
-concurrencyStep)
} else if systemLoad < lowLoadThreshold {
// Increase concurrency
adjustConcurrencyLimit(GlobalCxGroup,
concurrencyStep)
}
}
}
}()
Hybrid Sync Mode Coordination
For streams that require both backfill and CDC, OLake coordinates the transition:
// Execute hybrid mode streams
for _, stream := range hybridModeStreams {
// First perform backfill
err := connector.Read(pool, stream)
if err != nil {
return err
}
// Then switch to CDC mode
stream.SetSyncMode(types.CDC)
cdcStreams = append(cdcStreams, stream)
}
// Start CDC for all CDC streams
err = connector.RunChangeStream(pool, cdcStreams...)
- Sequential Execution: Completes backfill before starting CDC
- State Coordination: Ensures CDC starts from the correct position
- Resource Sharing: Efficiently transitions resources from backfill to CDC
- Consistency Guarantee: Maintains data consistency during the transition
Writer Pool Optimization
The writer pool implements several optimizations for efficient resource usage:
// Writer pool with thread management
func (w *WriterPool) NewThread(parent context.Context,
stream Stream, options ...ThreadOptions) (*ThreadEvent,
error) {
// Thread-local buffering
recordChan := make(chan types.RawRecord, bufferSize)
// Concurrent schema evolution
fields := make(typeutils.Fields)
fields.FromSchema(stream.Schema())
// Asynchronous processing
w.group.Go(func() error {
// Process records asynchronously
for record := range recordChan {
// Process and write record
}
return nil
})
// Return thread control interface
return &ThreadEvent{
Insert: func(record types.RawRecord) error {
select {
case recordChan <- record:
return nil
default:
// Implement backpressure if channel is
full
// ...
}
},
Close: func() {
close(recordChan)
},
}, nil
}
- Thread-Local Buffering: Each writer thread maintains its own buffer
- Non-Blocking Channels: Uses buffered channels for efficient communication
- Backpressure Mechanism: Slows down producers when writers can't keep up
- Graceful Shutdown: Ensures all buffered records are processed before closing
State Management
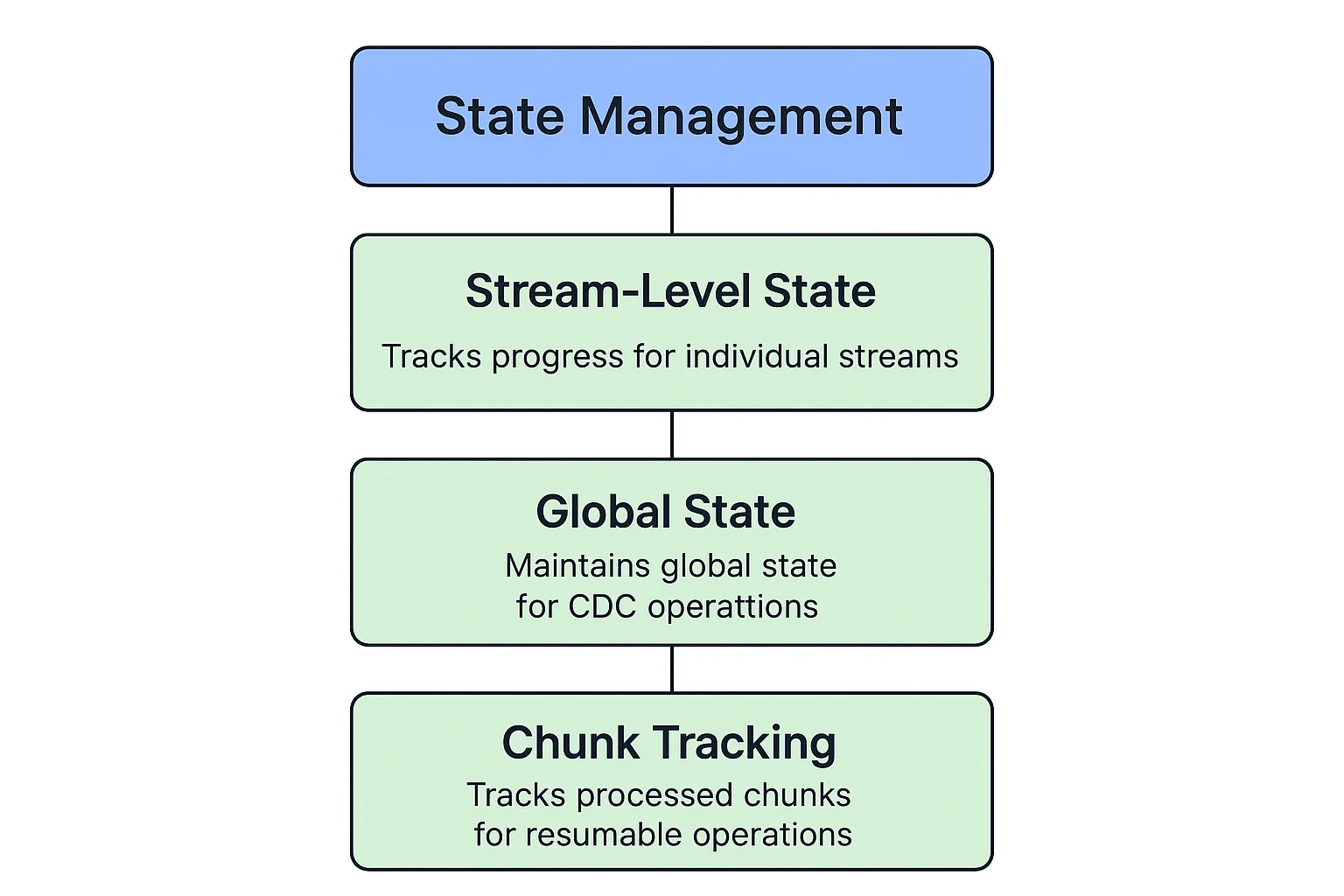
OLake uses a state management system to track sync progress and enable resumable operations:
- Stream-Level State: Tracks progress for individual streams
- Global State: Maintains global state for CDC operations
- Chunk Tracking: Tracks which chunks have been processed for resumable operations
type State interface {
ResetStreams()
SetType(typ types.StateType)
GetCursor(stream *types.ConfiguredStream, key string) any
SetCursor(stream *types.ConfiguredStream, key, value any)
GetChunks(stream *types.ConfiguredStream) *types.Set[types.Chunk]
SetChunks(stream *types.ConfiguredStream, chunks *types.Set[types.Chunk])
RemoveChunk(stream *types.ConfiguredStream, chunk types.Chunk)
SetGlobalState(globalState any)
}
{
"type": "STREAM",
"streams": [
{
"stream": "funny",
"namespace": "reddit",
"sync_mode": "",
"state": {
"_data": "8267F61C5B000000022B0429296E1404",
"chunks": []
}
}
]
}
This state management system ensures that OLake can resume operations after interruptions, making it resilient to failures.
Key Design Principles
OLake's architecture is guided by several key design principles:
- Integrated Writers: Writers are directly integrated with drivers to avoid blocking reads
- Connector Autonomy: Each connector is autonomous and can operate independently. (dependencies are separate for each connector to keep the whole executable smaller in size.)
- Efficiency Focus: Fast read and write operations that don't contribute to increasing record throughput are avoided
- Modularity: Clear separation of concerns through well-defined interfaces
- Extensibility: Easy to add new drivers and writers through the plugin architecture
These principles ensure that OLake remains efficient, maintainable, and extensible as it evolves.
Conclusion
OLake provides a powerful, high-performance solution for replicating databases to data lakehouses. Its modular architecture, support for both full refresh and CDC modes, and efficient concurrency model make it an excellent choice for organizations looking to enable real-time analytics. Also, OLake includes several performance optimizations like parallel processing, adaptive batch sizing to achieve high throughput even with large datasets.
By clearly understanding OLake's internal workings and principles, developers and organizations can better leverage its capabilities to drive insightful analytics and informed decision-making. Whether using OLake for MongoDB, PostgreSQL, or MySQL, and writing to Parquet files or Apache Iceberg tables, the system's consistent design principles ensure a reliable and efficient data replication experience.
If this excites you, check out OLake, check out the GitHub repository and join the Slack community to get started.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.