Building a Serverless Iceberg Lakehouse: OLake's Speed + Bauplan's Git Workflows


If you've ever tried to build a data lake, you know it rarely feels simple. Data sits across operational systems (PostgreSQL, Oracle, MongoDB) and getting it into a usable analytical format means chaining together multiple tools for ingestion, transformation, orchestration, and governance. Each layer adds cost, complexity, and maintenance overhead. You end up managing clusters, debugging pipelines, and paying for infrastructure that sits idle more often than it runs.
This is where OLake and Bauplan change the game. OLake moves your data from databases to Apache Iceberg seamlessly skipping the headache of developing custom ETL pipelines. Bauplan, on the other hand, lets you build and run your data transformations serverlessly — in Python or SQL, with no provisioning or maintenance. Together, they form a serverless open data lakehouse.
In this blog, I'll show you how OLake and Bauplan work together with Apache Iceberg to create a data platform that actually makes sense - one where your operational data flows seamlessly into your Data Lakehouse, where your data team can work like software engineers with branches and merges.
What's a Data Lakehouse, Anyway?
Imagine combining the best of two worlds: the flexibility and low cost of a data lake with the performance and reliability of a data warehouse. That's a lakehouse. You get to store massive amounts of raw data cheaply, but query it with the speed and structure of a traditional database.
But here's the challenge: building a modern lakehouse that's real-time, version-controlled, and truly open has been frustratingly complex. Until now.
The Three Building Blocks
OLake is the fastest and most efficient way to replicate your data from databases (like Postgres, MySQL, MongoDB) to a Data Lakehouse. It's an open-source tool that captures changes using CDC (Change Data Capture) and writes them directly as Apache Iceberg tables on object storage. Think of it as a high-speed bridge between your production databases and your data lakehouse.
Bauplan is a serverless data processing platform built for Apache Iceberg. It automatically runs your SQL queries and Python transformations whenever you need them—no servers to set up, no infrastructure to manage. What makes it special? It works like Git: you can create separate branches to test your data transformations, run queries against branch-specific data, and only merge to production when you're confident everything works. No more accidentally breaking production dashboards while testing.
Apache Iceberg is the table format that makes this magic possible. It's open-source, battle-tested, and supported by virtually every modern data tool. Iceberg tables track their own history, support ACID transactions, and enable time travel queries - all while sitting on cheap object storage.
Make sure to checkout these GitHub repositories:
How It All Flows Together:
Here's the complete picture of how data moves through the system:
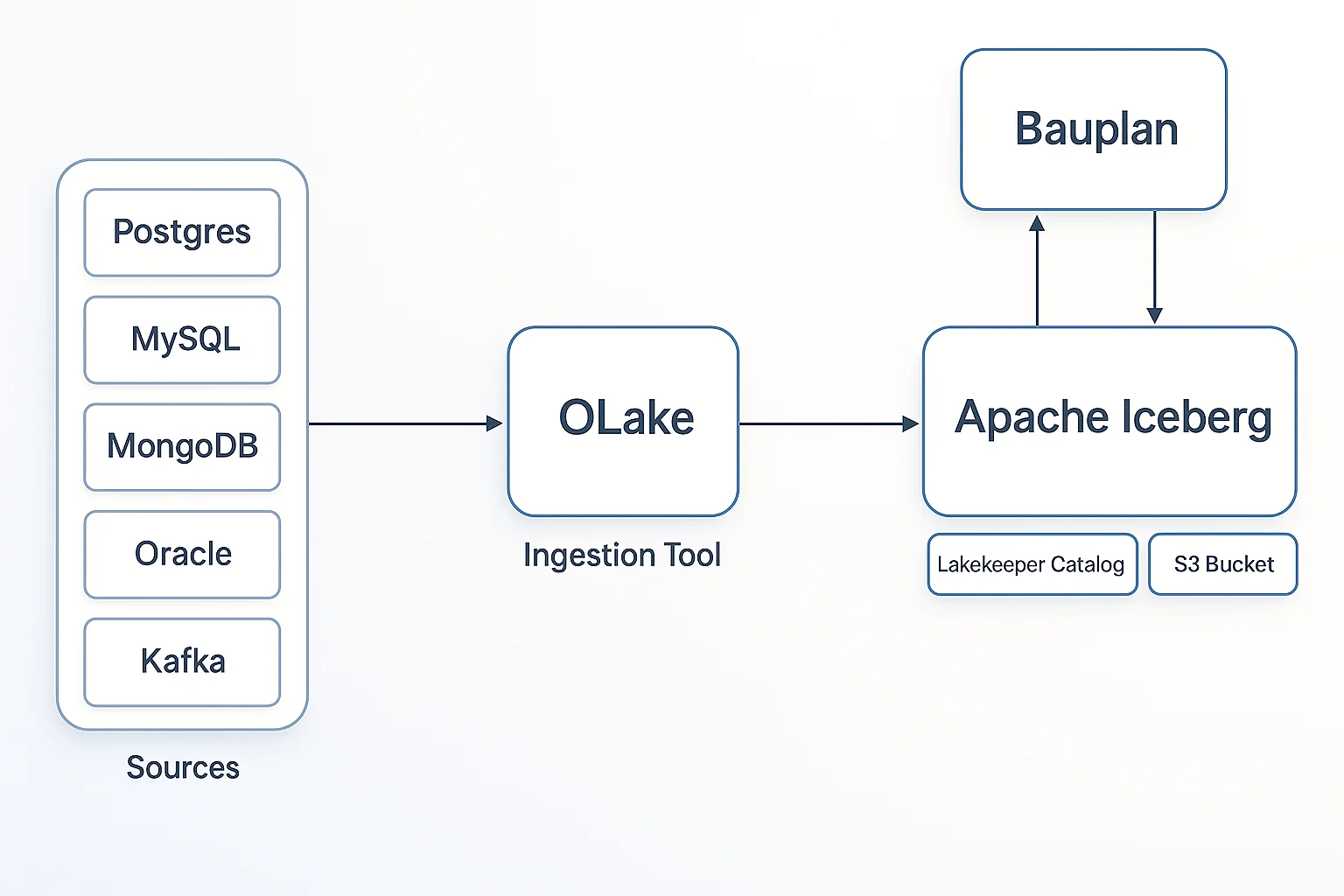
The Architecture
1. OLake performs a historical-load and CDC of data from Postgres to Iceberg tables stored in an S3 bucket.
2. Iceberg Tables are written directly to S3 by OLake. Each table consists of data files (Parquet), metadata files, and manifest files that track the table's structure and history.
3. Lakekeeper acts as the Iceberg REST Catalog. It manages table metadata, tracks table versions, and coordinates access across different tools.
4. Bauplan fetches the metadata.json file from S3 bucket. Lets you branch, test, and evolve your data safely before merging to production.
Prerequisites
- An instance that has write access to an S3 bucket
- See minimum S3 access requirements needed by Bauplan to connect to and read your S3 bucket
- S3 bucket must be in
us-east-1region - Docker installed
- Install Bauplan. Please refer to the Bauplan installation guide.
Step-by-Step Implementation
In this implementation: We'll use Postgres as the source and perform a historical load of tables to Iceberg (S3 bucket). This gives us a complete snapshot of the data that we can then query and transform through Bauplan.
Ready to build this yourself? Here's how to set up the complete stack.
Optional: Need a Test Postgres Database?
If you don't have your own Postgres database available, you can easily spin up a local Postgres instance with sample data using Docker. Follow the Setup Postgres via Docker Compose guide to get started with a pre-configured database for testing.
Step 1: Set up Lakekeeper
Start by setting up Lakekeeper with Docker. This will be the brain of your lakehouse, managing all table metadata.
- For detailed instructions on configuring the docker-compose file, deploying Lakekeeper, and setting up warehouse in Lakekeeper refer to the OLake documentation for REST Catalog Lakekeeper setup.
- To access Lakeeper UI from your local machine make sure to set up SSH port forwarding.
Once you have started the services you can access the Lakekeeper UI at: http://localhost:8181/ui
Step 2: Set up OLake
Deploy the OLake UI with a single command. This starts the OLake UI and backend services:
curl -sSL https://raw.githubusercontent.com/datazip-inc/olake-ui/master/docker-compose.yml | docker compose -f - up -d
Access the services at: http://localhost:8000.
Default credentials: Username: admin, Password: password
To access OLake UI from your local machine, make sure you set up SSH port forwarding.
Step 3: Configure OLake Job
Now let's configure OLake to sync data from your source database to Iceberg.
If you're new to OLake, refer to our guide on creating your first job pipeline for detailed instructions.
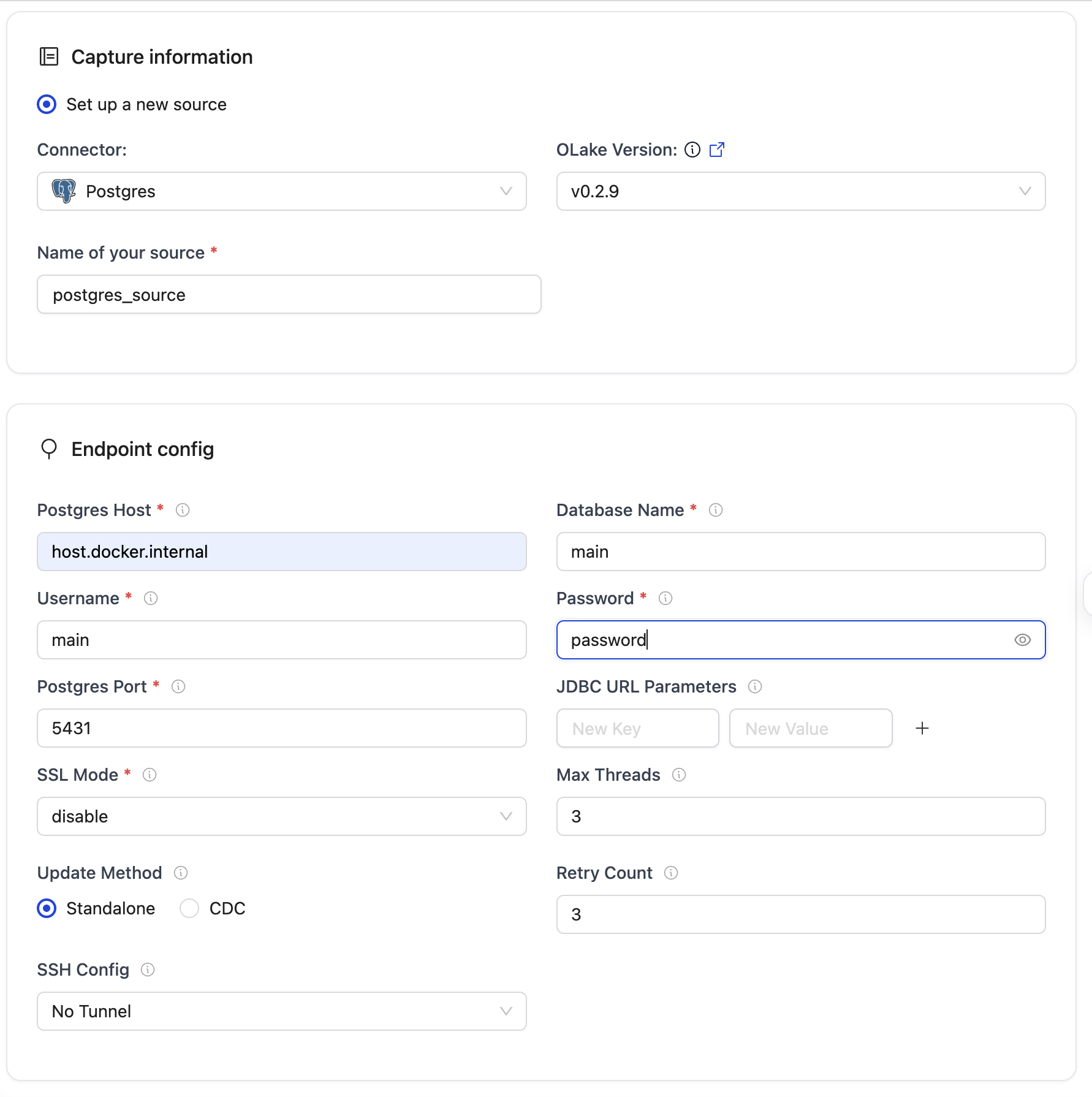
- Source Configuration
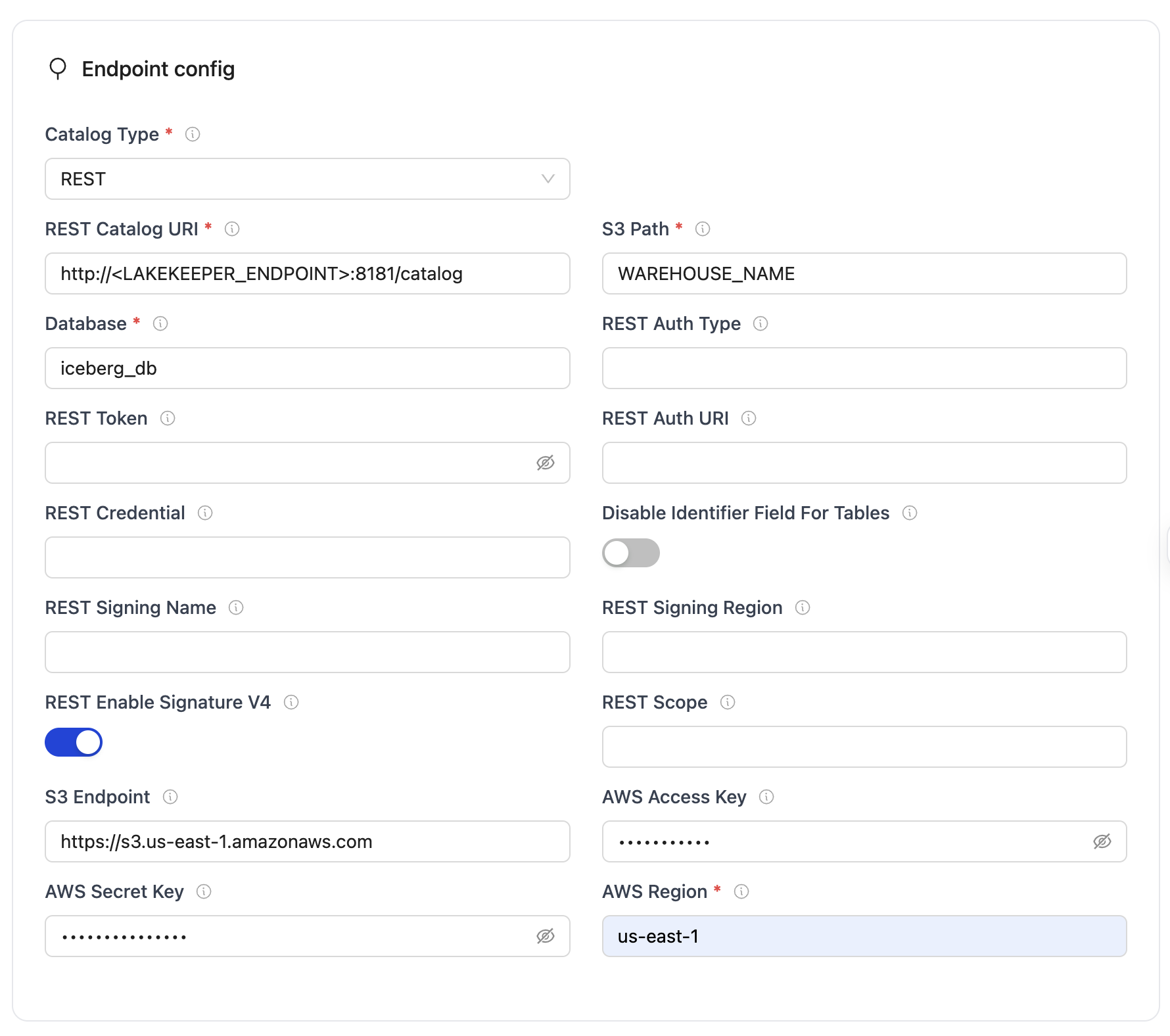
- Destination Configuration
Please refer to the below image to set up your source:
Please refer to the below image to set up your destination:
Step 4: Set Up Bauplan
First make sure that Bauplan is installed in your local system. To set up your Bauplan API key, you'll need to create an account at Bauplan and generate an API key from the dashboard. For API key configuration, please refer to the Bauplan API Key setup.
Step 5: Register Tables in Bauplan
Now we need to make Bauplan aware of the Iceberg tables.
Before running the script, update the following variables to match your setup:
CATALOG_URI- Your Lakekeeper endpointLAKEKEEPER_WAREHOUSE- Your warehouse nameS3_ENDPOINT,S3_ACCESS_KEY,S3_SECRET_KEY,S3_REGION- Your S3 credentialsICEBERG_NAMESPACE- Your database name (e.g.,postgres_mydb_public)ICEBERG_TABLE- The table name you want to register
Python script: Register table in Bauplan
# register_fivetran_external_table.py
import bauplan
from pyiceberg.catalog import rest
# ===============================
# Lakekeeper configuration
# ===============================
CATALOG_URI = "http://localhost:8181/catalog" # or your deployed Lakekeeper endpoint
LAKEKEEPER_WAREHOUSE = "<WAREHOUSE_NAME>" # Adjust as needed
# Optional S3 configuration (if required)
S3_ENDPOINT = "https://s3.us-east-1.amazonaws.com"
S3_ACCESS_KEY = "<YOUR_ACCESS_KEY>"
S3_SECRET_KEY = "<YOUR_SECRET_KEY>"
S3_REGION = "us-east-1"
# ===============================
# Iceberg namespace & table
# ===============================
ICEBERG_NAMESPACE = "<DATABASE_NAME>"
ICEBERG_TABLE = "<TABLE_NAME>"
# ===============================
# Function: get metadata.json path from Lakekeeper
# ===============================
def get_metadata_location(namespace: str, table_name: str) -> str:
"""Return the metadata.json location for an Iceberg table from Lakekeeper."""
lakekeeper_catalog = rest.RestCatalog(
name="default",
type="rest",
uri=CATALOG_URI,
warehouse=LAKEKEEPER_WAREHOUSE,
**{
"s3.endpoint": S3_ENDPOINT,
"s3.access-key-id": S3_ACCESS_KEY,
"s3.secret-access-key": S3_SECRET_KEY,
"s3.region": S3_REGION,
},
)
table = lakekeeper_catalog.load_table((namespace, table_name))
return table.metadata_location
# ===============================
# Step 1: Resolve metadata.json location
# ===============================
metadata_location_string = get_metadata_location(
namespace=ICEBERG_NAMESPACE,
table_name=ICEBERG_TABLE,
)
# ===============================
# Step 2: Register the Iceberg table in Bauplan
# ===============================
client = bauplan.Client()
bauplan_user = client.info().user.username
# Create a non-main branch for safe testing
branch_name = f"{bauplan_user}.olake_integration"
client.create_branch(branch=branch_name, from_ref="main", if_not_exists=True)
# Define how the table will appear in Bauplan
BAUPLAN_TABLE_NAME = f"{ICEBERG_NAMESPACE}__{ICEBERG_TABLE}"
# Ensure namespace exists
try:
client.create_namespace(namespace="olake", branch=branch_name)
except Exception:
pass
client.create_external_table_from_metadata(
table=BAUPLAN_TABLE_NAME,
metadata_json_uri=metadata_location_string,
branch=branch_name,
namespace="olake",
overwrite=True,
)
print(f"✅ Successfully registered {BAUPLAN_TABLE_NAME} to Bauplan branch '{branch_name}'")
Save the script in the working directory by the name bauplan_register_table.py. Then run:
python3 bauplan_register_table.py
This will fetch the metadata location and register the table as an external table in Bauplan.
To verify the same you will see an output like this on your terminal:
✅ Successfully registered {ICEBERG_NAMESPACE}_{ICEBERG_TABLE} to Bauplan branch '{bauplan_user}.olake_integration'
Step 6: Build and test on branches
Now comes the fun part! The registration script created a development branch in Bauplan (named something like {bauplan_user}.olake_integration), and your Iceberg table is now registered there. This isolated branch is your sandbox—experiment freely without touching production data.
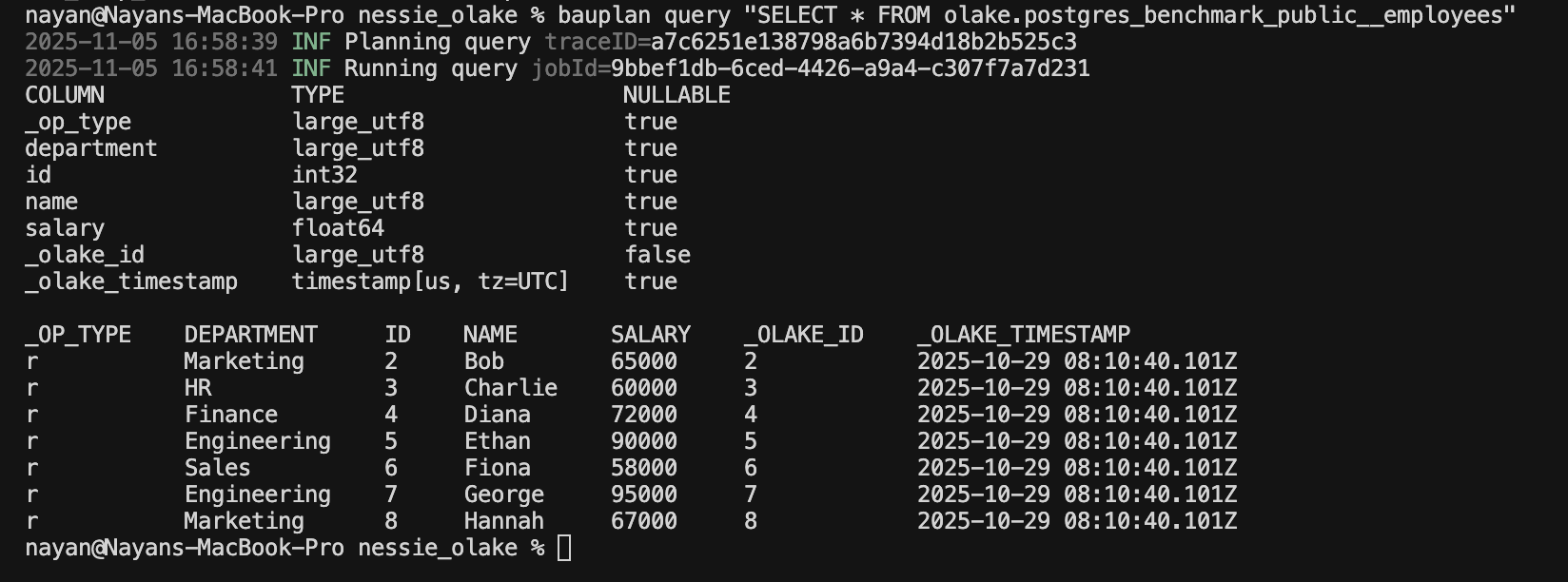
Let's verify everything is working by running a simple query.
# Replace `<ICEBERG_NAMESPACE>` and `<ICEBERG_TABLE>` with your actual namespace and table name.
bauplan query "SELECT * FROM olake.{ICEBERG_NAMESPACE}_{ICEBERG_TABLE} LIMIT 10"
You will see the query results like this:
You've just built a complete data lakehouse stack that bridges operational databases and analytics—without vendor lock-in, without proprietary formats, and without complexity. OLake continuously syncs your Postgres data to Iceberg tables, Lakekeeper manages the metadata catalog, and Bauplan gives your team Git-style workflows for safe, collaborative data development.
Useful Resources
- OLake Documentation - Complete guide to setting up OLake with various sources and destinations
- Bauplan Documentation - Learn about branch workflows and data transformations
- Lakekeeper - Open-source Iceberg REST catalog
- Apache Iceberg - The open table format powering this architecture
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.