OLake Ingestion Filters: Smart SQL-Style Data Filtering Guide

You know that feeling when you're staring at a massive dataset, and most of it isn't even relevant to what you're trying to achieve? Well, that's exactly why we built our filter feature for data ingestion pipelines - and trust me, it's been a game-changer for teams dealing with ever-growing data volumes.
Let's be honest - as data engineers, we've all been there. You set up a beautiful ingestion pipeline, only to realize you're pulling in millions of records when you actually need just the ones where we have age > 18 or country = "USA". Not only does this waste precious storage space, but it also slows down your entire downstream processing pipeline.
Why This Filter Feature Matters More Than You Think
Here's the thing about data ingestion - every unnecessary byte you pull costs you money and time. When you filter data at the source, you're essentially being smart about what enters your pipeline in the first place. Think of it like having a bouncer at your data warehouse door, only letting in the VIP records that actually matter to your business.
The benefits are pretty compelling when you think about it. First, you're dramatically reducing the volume of data that needs to be transferred and processed, which means lower costs and faster pipelines. This approach focuses on ingesting only the data pertinent to your use case, enhancing the quality and applicability of your processed dataset. Also, less data ingestion translates directly to reduced storage requirements and decreased load on processing systems.
Let me give you a real-world example that'll make this crystal clear. Imagine you're working with customer data, and you might want to ingest only records where age > 18 or country = "USA".
With filtering, you'd be avoiding the ingestion of irrelevant data and optimizing your entire pipeline. This kind of targeted approach can reduce your daily ingestion time dramatically - we've seen teams go from 6 hours to 45 minutes just by implementing smart filtering.
How Our Filter Feature Works Under the Hood
Now, here's where things get interesting technically. The filter feature is seamlessly integrated into the data ingestion process across multiple database drivers: Postgres, MySQL, and MongoDB. It begins with a user-defined filter string specified in the streams.json, particularly in selected streams which is then parsed and applied by each driver.
Filter Parsing - The Foundation of Everything
The filter string is parsed by the GetFilter method, and this is where the magic happens. It supports conditions in the format "column operator value", with optional logical operators (and or or) for combining multiple conditions. Here are some examples that show how flexible this system is:
age > 18
country = "USA"
age > 18 and country = "USA"
The method uses a regular expression (given below) to parse the string into a Filter struct:
(^(\w+)\s*(>=|<=|!=|>|<|=)\s*(\"[^\"]*\"|\d*\.?\d+|\w+)\s*(?:(and|or)\s*(\w+)\s*(>=|<=|!=|>|<|=)\s*(\"[^\"]*\"|\d*\.?\d+|\w+))?\s*$)
This parsed structure contains:
- Conditions: A list of Condition structs, each with Column, Operator, and Value.
- LogicalOperator: The operator (and or or) if multiple conditions exist.
This parsed filter is then passed to database-specific functions to generate the appropriate query filters, which is pretty neat when you see it in action.

Database-Specific Implementation: Where the Real Work Happens
SQL Databases: Postgres and MySQL
For SQL databases, the filter is converted into a SQL WHERE clause using the SQLFilter function in jdbc.go. This function handles various operators (>, <, =, !=, >=, <=) and value types (strings, numbers, nulls), ensuring proper quoting and escaping. Strings need to be provided in format "".
Here's a practical example that shows exactly how this works in your configuration:
{
"selected_streams": {
"public": [
{
"partition_regex": "",
"stream_name": "postgres_test",
"normalization": true,
"filter": "age > 18 and country = \"USA\""
}
]
}
}
This filter will be interpreted the following way:
- Postgres:
"age" > 18 AND "country" = 'USA' - MySQL:
`age` > 18 AND `country` = 'USA'
Pretty straightforward, right? Same logic, different quote styles - we handle all that complexity for you automatically.
Postgres Implementation Details
In the Postgres driver, things get a bit more sophisticated:
Chunk Generation: The filter is incorporated into the MinMaxQuery and PostgresNextChunkEndQuery to determine chunk boundaries based on filtered data. For instance, splitTableIntoChunks uses the filter in minMaxRowCountQuery to fetch min/max values of the chunk column only for rows satisfying the filter.
Chunk Processing: The PostgresChunkScanQuery includes the filter in the WHERE clause alongside chunk conditions (e.g., ctid >= '(0,0)' AND ctid < '(1000,0)' AND "age" > 18).
For more details on setting up PostgreSQL for production workloads and understanding how CDC works with filtering, check out our comprehensive guide on how to set up AWS RDS Postgres with CDC.
MySQL Implementation Details
In the MySQL driver, we follow a similar approach:
Chunk Generation: When using primary keys or a specified chunk column, splitViaPrimaryKey applies the filter in MinMaxQueryMySQL and Next InitiativeEndQuery to generate chunks based on filtered data ranges.
Chunk Processing: The MysqlChunkScanQuery or MysqlLimitOffsetScanQuery includes the filter in the WHERE clause (e.g., SELECT * FROM db.table WHERE (id >= '1' AND id < '1000') AND age > 18).
MySQL's binary logs play a crucial role in change data capture scenarios - learn more about what binlogs are and how they work to understand their impact on data ingestion performance and filtering strategies.
MongoDB: A Different Beast Altogether
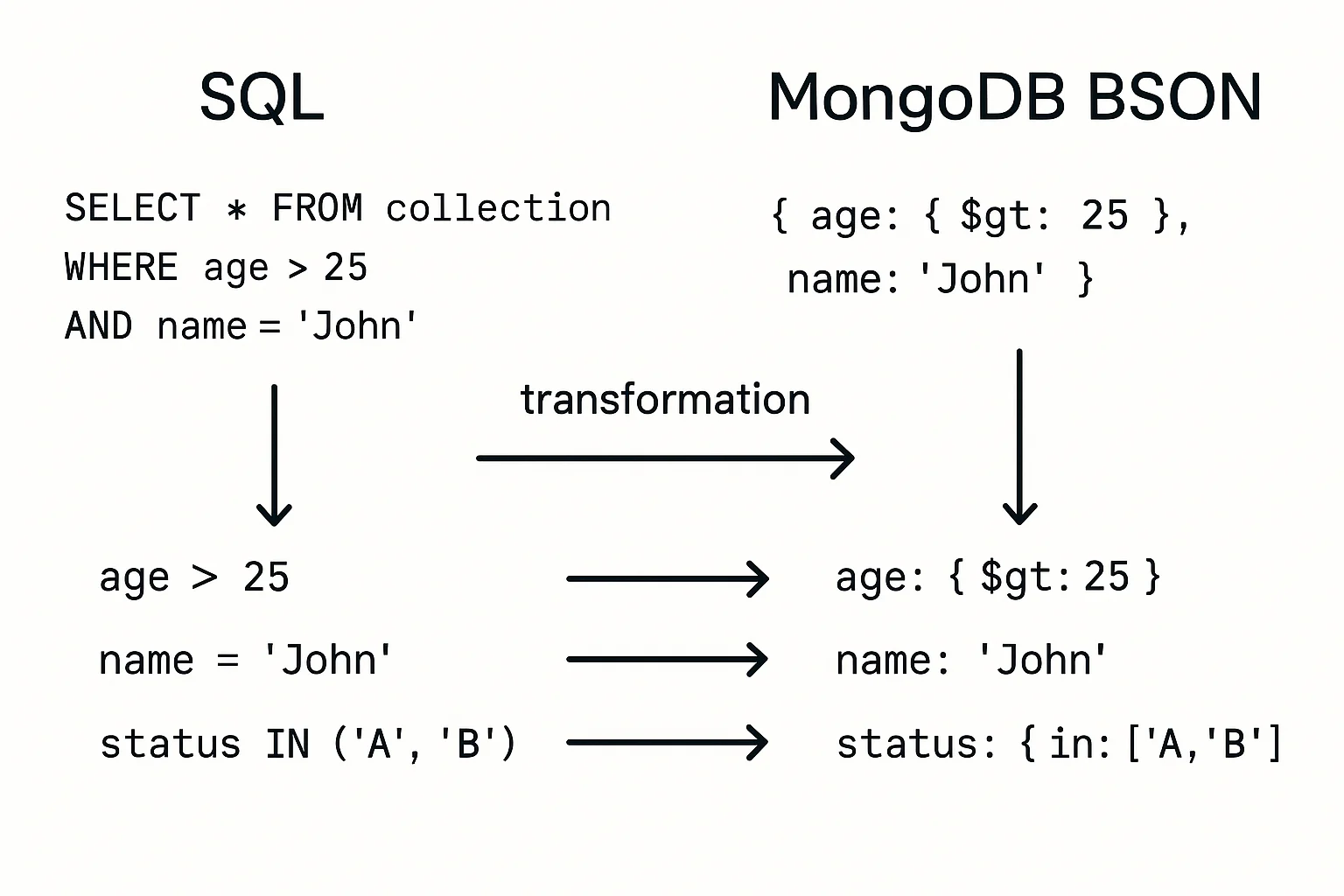
For MongoDB, the approach is completely different since it doesn't use SQL. We convert your filter into a BSON document using the buildFilter method. This function maps SQL-like operators to MongoDB equivalents (e.g., > to $gt, = to $eq) and handles data types like strings, numbers, ObjectIDs, and dates.
Example Filter Conversion
For age > 18 and country = "USA", the BSON document becomes:
{
"$and": [
{ "age": { "$gt": 18 } },
{ "country": { "$eq": "USA" } }
]
}
Implementation:
Chunk Generation: In splitChunks, the filter is applied in the split vector strategy (via the splitVector command) and bucketAutoStrategy (via the $match stage in the aggregation pipeline) to generate chunks containing only filtered data.
Chunk Processing: The generatePipeline function in ChunkIterator includes the filter in the $match stage of the aggregation pipeline, ensuring only relevant documents are processed within each chunk.
MongoDB CDC presents unique challenges and opportunities - dive deeper into MongoDB CDC using Debezium and Kafka to understand how filtering works in streaming scenarios.
The Art and Science of Chunking: Why We Filter Twice
Now, you might wonder why we apply filters during both chunk generation and processing. It's not because we don't trust our code - it's because chunking is complex, and different strategies require different approaches.
Understanding Chunking in Data Ingestion
In data ingestion, large datasets are split into smaller chunks for efficient processing, often running in parallel. This process involves two critical stages:
- Chunk Generation: Determining the boundaries of these chunks (e.g., ranges of primary keys, physical locators, or timestamps).
- Chunk Processing: Fetching and processing the data within each chunk.
For a comprehensive understanding of how OLake's chunking strategies work across different databases, read our detailed explanation here. This section covers all the various chunking approaches we use for MongoDB, MySQL, and PostgreSQL.
Why Apply Filters in Both Stages?
During Chunk Generation:
Applying the filter during chunk generation ensures that chunks are created based on the filtered dataset, which gives you several advantages:
- Smaller Chunks: Only data meeting the filter criteria is included, reducing chunk size.
- Fewer Chunks: Irrelevant data is excluded, potentially decreasing the total number of chunks.
- Efficiency: Smaller, relevant chunks lead to faster processing and reduced resource usage.
For example, in Postgres with a primary key id and filter age > 18, the MinMaxQuery might return id ranges only for rows where age > 18, resulting in fewer and smaller chunks.
During Chunk Processing:
Reapplying the filter during chunk processing ensures accuracy and consistency:
- Edge Cases: Chunk boundaries might include data not fully aligned with the filter due to data types or boundary conditions.
- Consistency: In distributed systems, data might change between generation and processing, requiring the filter to be reapplied.
- Fallback: For chunking strategies where filtering during generation isn't feasible, it ensures the filter is still enforced.
Implementation Details:
- Postgres: Filter in minMaxRowCountQuery (generation) and PostgresChunkScanQuery (processing).
- MySQL: Filter in MinMaxQueryMySQL (generation) and MysqlChunkScanQuery (processing).
- MongoDB: Filter in splitVector/bucketAuto commands (generation) and generatePipeline (processing).
When Filtering During Generation Isn't Feasible
While the filter enhances efficiency in many cases, certain chunking strategies make it impractical to apply during chunk generation due to their reliance on non-data-value-based boundaries.
Postgres: CTID-Based Chunking
Strategy: When no chunk column is specified, Postgres uses CTID ranges strategy(tuple ID), a physical locator of rows.
Limitation: CTID reflects physical storage, not data values, so filters like age > 18 can't influence chunk boundaries.
Solution: The filter is applied only in PostgresChunkScanQuery during processing (e.g., WHERE ctid >= '(0,0)' AND ctid < '(1000,0)' AND "age" > 18).
For more details on how PostgreSQL's CTID system works, see our explanation of CTID Ranges strategy.
MySQL: Limit-Offset Chunking
Strategy: Without a primary key or chunk column, MySQL uses a limit-offset approach (e.g., LIMIT 500000 OFFSET 0, LIMIT 500000 OFFSET 500000).
Limitation: Chunks are based on row counts, not data values, making it impossible to apply value-based filters during generation.
Solution: The filter is applied in MysqlLimitOffsetScanQuery during processing (e.g., SELECT * FROM db.table WHERE age > 18 LIMIT 500000 OFFSET 0).
MongoDB: Timestamp-Based Chunking
Strategy: The timestampStrategy generates chunks based on time ranges derived from the _id field's timestamp.
Limitation: Chunks are predefined by time intervals (e.g., 6-hour blocks), and the filter (e.g., age > 18) isn't directly applied during boundary calculation.
Solution: The filter is applied in the generatePipeline during processing, ensuring only relevant documents are fetched within each time-based chunk.
To understand how MongoDB's Split Vector approach works in practice, check out our detailed breakdown of the Split Vector Strategy. For PostgreSQL's non-numeric column chunking, see our guide on Split via Next Query.
Oracle's Chunking Approach
Strategy: Chunking in Oracle is done using the DBMS_PARALLEL_EXECUTE package's CREATE_CHUNKS_BY_ROWID method. This method generates synthetic ROWID-based chunk boundaries by grouping a specified number of blocks into each chunk.
Limitation: Since Oracle's built-in DBMS_PARALLEL_EXECUTE package is used, it does not accept user-defined filters. The only configurable inputs are chunking parameters such as the chunk size and method. As a result, filter conditions cannot influence how chunk boundaries are generated.
Solution: Filters are applied only during chunk processing, not when generating chunk boundaries. For example:
SELECT * FROM customers
WHERE ROWID >= :start_rowid AND ROWID < :end_rowid AND AGE > 18;
What Our Filter System Supports Right Now
Let's talk about what you can actually do with our current implementation, because understanding the capabilities and limitations is crucial for effective usage.
Supported Filter Formats
The current implementation supports:
- Single Conditions: column operator value (e.g., age > 18, country = "USA", id != "null").
- Combined Conditions: Two conditions with and or or (e.g., age > 18 and country = "USA"). As of now, only 2 filter conditions are handled followed by logical and / or.
- Operators:
>,<,=,!=,>=,<=. - Values: Numbers, quoted strings (e.g., "USA"), unquoted strings, null.
Edge Cases We Handle
- Null Handling: SQLFilter and buildFilter correctly handle null values (e.g., column = null becomes column IS NULL in SQL).
- Data Type Mismatches: Filters assume correct type inference (e.g., age > "18" might not sync data as required if age is numeric).
Potential Enhancements on the Horizon
Future iterations could support:
- Nested conditions (e.g., (age > 18 and country = "USA") or status = "active").
- Additional operators (e.g., LIKE, IN).
- Dynamic type validation during parsing.
Real-World Performance Impact and Best Practices
Based on what we've learned from our users, here are some practical insights that can make or break your filtering strategy.
Performance Benefits We've Observed
Teams using our filtering feature report significant improvements in pipeline performance, especially when dealing with large datasets where only a subset is relevant.
The impact is even more pronounced in streaming scenarios where you're dealing with high-velocity data streams - filtering at the source prevents your downstream systems from getting overwhelmed with irrelevant data.
This is particularly important for applications like fraud detection or real-time monitoring where latency matters. When you're paying for data transfer and storage in cloud environments, every filtered-out record translates directly into cost savings.
Smart Filtering Strategies
Here are some battle-tested approaches that actually work in production:
- Filter Early and Often: The sooner you eliminate irrelevant data, the better your entire pipeline performs. This is especially true in cloud environments where you're paying for data transfer and storage.
- Leverage Indexed Columns: Filters that can leverage indexed columns will perform much better than those that require full table scans. If you're filtering on columns that aren't indexed, consider working with your database administrator to add appropriate indexes.
- Keep It Simple: While it's tempting to create very specific filters, sometimes simpler conditions that eliminate the bulk of irrelevant data perform better than complex filters that are highly selective. You can always apply additional filtering in subsequent processing steps.
The Bigger Picture: Modern Data Architecture
Our filtering feature fits into a broader trend toward more intelligent data processing. Modern data architectures are moving away from the "ingest everything and figure it out later" approach toward more selective, purposeful data ingestion.
This shift makes sense when you consider the economics of cloud computing and the growing importance of real-time data processing. Every byte you don't need to store, transfer, or process saves money and improves performance.
Whether you're working with batch processing for historical analysis or real-time streaming for immediate insights, filtering at the source ensures your pipelines are efficient and cost-effective. It's one of those features that might seem simple on the surface but delivers substantial value when implemented thoughtfully.
Conclusion: Smart Ingestion for Smarter Teams
The reality is that data volumes will continue to grow, and the cost of processing irrelevant data will only increase. By implementing intelligent filtering at the ingestion layer, you're setting your team up for success both now and in the future.
Our filter feature significantly enhances our data ingestion system by enabling selective data processing, improving efficiency, and optimizing resource use. Its robust implementation across Postgres, MySQL, and MongoDB ensures flexibility while addressing edge cases through strategic application during both chunk generation and processing. Although limitations exist in certain chunking strategies, the system gracefully adapts by applying filters during processing, ensuring data relevance and pipeline performance.
Whether you're just starting your career in data engineering or you're a seasoned professional optimizing complex pipelines, effective filtering is one of those foundational skills that pays dividends across every project you work on.
Start filtering smarter, and watch your pipelines become faster, cheaper, and more reliable.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.