Deep Dive into Kafka as a Source in OLake: Unpacking Sync, Concurrency, and Partition Mastery



In the world of data pipelines, Kafka has become the backbone of real-time event streaming. That's why we built OLake's Kafka source connector. It's designed to pull data directly from Kafka topics and land it in Apache Iceberg tables - with proper schema evolution, atomic commits, and state management. No external streaming engines, no complex orchestration. Just OLake reading from Kafka and writing to your data lake.
If you're familiar with OLake's technology, you’ll see how OLake connects effortlessly with Kafka’s distributed ecosystem through its flexible, pluggable design. This post breaks down how we built it, the design decisions we made, and why certain things work the way they do. If you're running data pipelines from Kafka to a lakehouse, this might save you some pain.
What OLake Does? A Quick Primer
OLake treats sources like Kafka as "streams" of data, where topics become logical streams with inferred schemas (e.g., JSON payloads augmented with Kafka metadata like offsets and partitions). OLake ingests Kafka topics into respective Iceberg tables with atomic commits (to achieve exactly-once semantics) and seamless schema evolution.
Key goals:
- Scalability: Handle hundreds of partitions across multiple streams/Topics.
- Resilience: Retry logic, offset management, state persistence, and graceful error handling.
- Efficiency: Sync while respecting resource limits (e.g., threads, connections).
Under the hood, we use the segmentio/kafka-go library for its Go-native performance and simplicity—no Java dependencies, just pure concurrency via goroutines.
Configurations: The Dial for Kafka Syncing
Before diving into architecture, let's talk configurations. OLake's Kafka source is declarative, exposing configs which go through strict early validations. Here is the schema:
- Bootstrap Servers
- Comma-separated broker addresses (e.g.,
broker-1:9092,broker-2:9092). Provide 2+ for high availability; the rest are auto-discovered.
- Comma-separated broker addresses (e.g.,
- Protocol
- Security settings for auth/encryption:
- Security Protocol:
PLAINTEXT|SASL_PLAINTEXT|SASL_SSL. - SASL Mechanism (when
SASL_*):PLAIN|SCRAM-SHA-512. - SASL JAAS Config (when
SASL_*): JAAS credential string, e.g.,org.apache.kafka.common.security.plain.PlainLoginModule required username="user" password="pass";
- Security Protocol:
- Security settings for auth/encryption:
- Consumer Group ID
- Optional. Uses user-provided ID; otherwise OLake generates
olake-consumer-group-{timestamp}and persists it for future syncs.
- Optional. Uses user-provided ID; otherwise OLake generates
- MaxThreads
- Defaults to 3. Enforces a cap concurrent readers/writers. Higher = more throughput, more resources will be utilized.
- RetryCount
- Defaults to 3. Retries transient failures with exponential backoff (~1 minute between attempts).
- ThreadsEqualTotalPartitions
- If
True: one reader per partition. IfFalse: readers capped bymax_threads.
- If
Architectural Design: From Topics to Tables
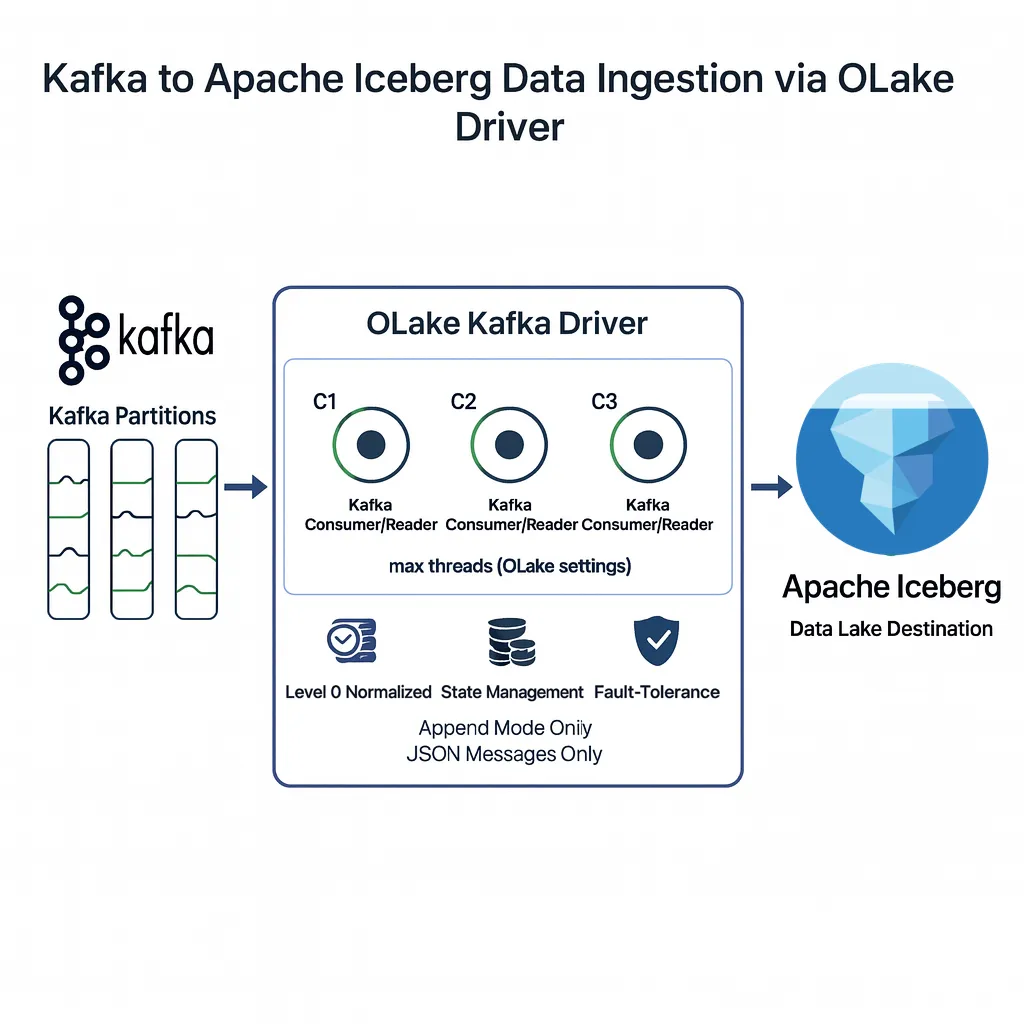
OLake’s abstraction methods wrap the Kafka-specific resources, handling Kafka-based fields and JSON-message schema discovery and batch-inclined syncing mechanism.
Core Design Principles
-
Decoupling: Separating High-Level Orchestration from Low-Level Kafka Mechanics
- Orchestration lives in
abstract/; Kafka protocol/auth/setup/close lives in driver-specific code inkafka/folder. - Why: clean orchestration, independently testable protocol layer, safer evolution, stable core engine.
- Current beta: reuses CDC-style method names (
pre_cdc,RunChangeStream,post_cdc) to structure the run; may be refactored. - Note: CDC naming only—Kafka isn’t CDC; it’s used just for method structure.
- Orchestration lives in
-
Commit Action: Ensuring Destination Sync Before Kafka Offset Commit
- When: commit occurs only after all partitions assigned to a reader reach the latest offsets.
- We note down all partition latest-offsets assigned to individual reader at the start.
- Order: destination commit first (e.g., Apache Iceberg/S3 Parquet), then Kafka offsets.
- Why: guarantees exactly-once and atomicity; safe retries on write failure; prevents loss/duplication.
- When: commit occurs only after all partitions assigned to a reader reach the latest offsets.
-
Configurable Parallelism: Granular Control Over Consumers
- One OLake thread = one consumer/reader.
- Users set
max_threads; OLake caps active readers and writers accordingly. - Balances throughput versus resource use; prevents CPU/memory/network oversubscription.
- Without this, you risk under/over-utilization, uneven partition progress, and delayed writes.
-
Data Access: Normalizing Topic Messages To Columnar Tables
- Kafka JSON messages are level-0 normalized into columns for Iceberg/Parquet.
- Benefits: efficient queries, predicate pushdown, schema evolution, and metadata management.
- Today: JSON-only; append-only writes; normalization can be disabled per stream/table if not required.
-
Operational Efficiency: Pre-Consumption Analysis and Partition Filtering
- Pre-consumption analysis filters empty or fully-read partitions; we only read where data exists.
- Prevents wasted CPU/network, endless loops, and thread starvation on large multi-partition topics.
-
Global State Persistence: Managing Consumer Group State Across Topics
- Persist consumer group state (committed offsets) across runs.
- Avoids duplicate or missed reads and improves reliability in production.
The Concurrency Conundrum: Scaling with Intelligent Readers
- We scale via a pool of reader tasks; each handles a subset of partitions.
- Concurrency is governed by
max_threadsandthreads_equal_total_partitions. If false, readers are capped atmax_threadsand partitions are distributed across them. - Standard balancers can be uneven, so we built a custom Round Robin Group Balancer.
The "Why" Behind Round Robin Group Balancer
Standard balancers (e.g., in segmentio/kafka-go) can assign partitions unevenly for our workload. To align with OLake’s concurrency model, we introduced OLake’s Round Robin Group Balancer for even, exclusive assignment.
How the Process Flows
-
Determine reader count from concurrency settings and the number of partitions with new data.
New data is identified using two criteria:
- The partition is not empty, and
- The partition contains new messages pending commit for the assigned consumer group.
For each selected stream, OLake performs a pre-flight check per partition and fetches three metadata points (
Partition Metadata): first available offset, last available offset, and last committed offset. -
Create that many consumer group-based reader instances (unique IDs).
-
The balancer assigns partitions evenly and exclusively via round-robin.
-
Start position: last committed offset if present; otherwise the first offset (full load).
-
Readers fetch, process, and write; progress is tracked via
[Topic:Partition] → Partition Metadata. A reader stops when all assigned partitions reach their recorded latest offset. -
If a thread/reader is assigned partitions from X different topics, it will create X writers to parallelize writes.
-
After writing: commit per writer at the destination, then commit Kafka offsets per partition assigned to that reader; close consumers; persist the consumer group ID in state.
Result: fine-grained resource control and maximum useful parallelism up to max_threads, without idle consumers or writers.
Let’s Do A Dry Run, Shall We?
Case: two topics × 3 partitions = 6 partitions. Effect of max_threads:
- 6: one reader per partition; optimal parallelism.
- 5: minor reuse across streams; near‑optimal.
- 4: balanced reuse; moderate concurrency.
- 3: high reuse; low concurrency.
- 2: heavy reuse; very low concurrency.
- 1: single thread; minimal concurrency.
Fetch Sizes and Beyond — Prioritizing Low Latency
During reader initialization, we set:
- MinBytes: 1 byte — immediate broker responses; low latency.
- MaxBytes: 10 MB — memory cap; mitigates OOM on high throughput.
- Trade-off — prioritize latency;
MaxBytesacts as a safety guard.
Future scope / roadmap
- Support other message formats
- Schema registry integration
- Finer control over JSON normalization
- Continuous sync mode (between streaming and batching)
- Graceful generation-end handling and rebalancing
- Offset-lag-based rebalance and custom assignment policies
Wrapping Up: Kafka in OLake, Production-Ready
We've built OLake's Kafka source to tame the complexity of Kafka sync: secure auth, partition-savvy readers, and concurrency that scales as needed—plus an incremental loop that knows when to stop. Decisions like custom balancing and offset filtering come from real pain points: uneven loads, stalled syncs, and wasted resources.
Next steps? Use Docker or deploy via Helm, tweak max_threads for your cluster, and monitor offsets with Kafka tools.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.