AWS DMS vs OLake: Choosing the Right Tool for Your Iceberg Pipeline

AWS DMS is a database migration service with CDC layered on. OLake is a replication engine built for streaming change data into Apache Iceberg. In a published benchmark on just over 4 billion rows, OLake ran the full load about 4.6x faster, sustained CDC about 1.38x faster, and cost roughly 4.61x less on compute for the full refresh. Memory use was close to a tie. Choose DMS for a finite move into AWS; choose OLake for an always-on pipeline into open table formats.
If you've ever run AWS DMS as the engine behind a lakehouse pipeline, you know the failure mode: A schema change breaks the task, the logs say almost nothing, and the only resolution anybody trusts is another full reload. That's not a misconfiguration. That's the difference between a migration tool and a replication tool and why most teams comparing AWS DMS and OLake show up with a specific problem rather than out of idle curiosity.
Both tools move data out of operational databases like PostgreSQL and MySQL into a place where you can analyse it, so at a glance they look interchangeable. What makes them different is what they were created for. AWS DMS is built to do a one-time migration of a database, with ongoing change data capture layered on. OLake is designed for CDC into open table formats such as Apache Iceberg, where the full load is just a step in the job, not the end goal. That first assumption drives almost everything else that follows: how much setup the pipeline needs, how it scales, what a schema change costs you, what the monthly bill looks like.
This comparison breaks down where each tool fits, across setup, continuous replication, schema evolution, scaling, and cost, with the benchmark numbers behind the claims and an honest look at when AWS DMS is still the right choice.
What each tool is built for
Both AWS DMS and OLake move data out of operational databases into a place where you can query, but they were built for different jobs, and the architecture of each makes that obvious.
AWS DMS: A Managed Database Migration Service
AWS DMS is a managed service to migrate databases to AWS with minimum downtime. AWS DMS supports both homogeneous moves (MySQL to MySQL) and heterogeneous moves (Oracle to PostgreSQL). The AWS Schema Conversion Tool handles engine-to-engine schema differences.
Architecturally, DMS uses a replication instance that you size, manage, and pay for as compute. You configure a source endpoint and a target endpoint and then run a replication task that performs a full load and optionally continuous CDC by reading the source transaction logs (binlog, WAL, or redo logs depending on the engine). A serverless option skips the instance sizing step but comes with its own constraints. The design as a whole assumes a finite move: get the data into AWS, and then either decommission the source or run both in parallel through a transition.

OLake: An Open-source Replication Engine for Apache Iceberg
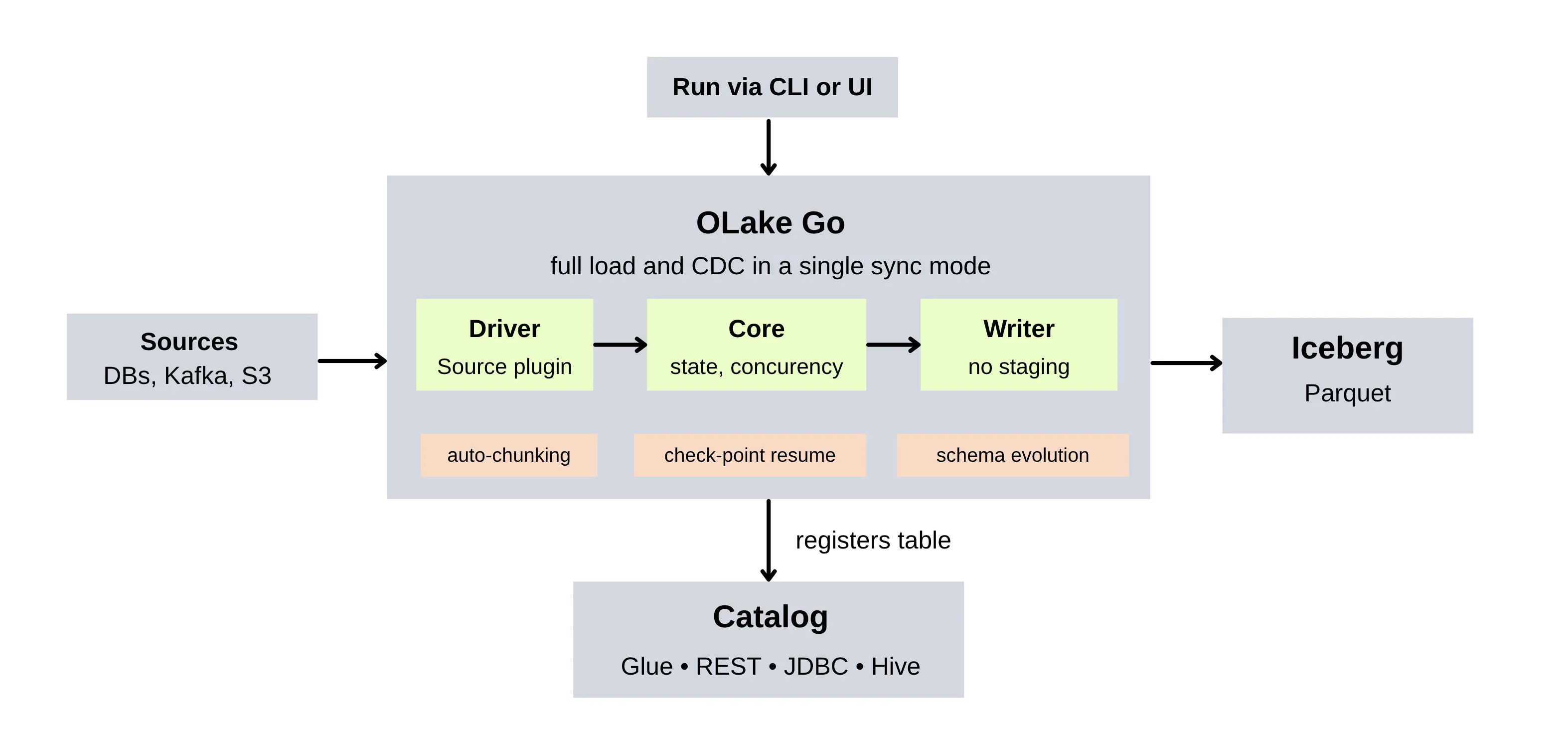
OLake is an open-source ingestion engine written in Go that replicates PostgreSQL, MySQL, MongoDB, Oracle, DB2 and MSSQL databases, as well as Kafka and S3 into Apache Iceberg or plain Parquet. It works at full load and CDC in a single sync mode, discovers and evolves schemas automatically, and writes to open tables readable by any Iceberg-compatible engine.
The architecture is modular: a Core for state, concurrency and monitoring and pluggable Drivers for sources and Writers for destinations. Each Writer is integrated with its Driver, pushing records directly to the target, without staging in an intermediary store, keeping latency low. The Core splits large tables into virtual chunks for parallel reads. It has a CDC cursor, so if a sync gets interrupted, it can pick up from the last checkpoint and not start over again. It registers tables in your catalogue, be it AWS Glue, REST, JDBC or Hive Metastore. You run it from the command line or the latest UI. OLake also provides table maintenance through OLake Fusion, which takes care of the compaction and small-file cleanup that Iceberg tables require over time. The project is on GitHub, the engine is OLake Go.
Head-to-head
| Dimension | AWS DMS | OLake |
|---|---|---|
| Primary design goal | One-time database migration to AWS | CDC replication into open lakehouse formats (Apache Iceberg) |
| Setup for Postgres parallelism | Manual partition-boundary scripting, pglogical configuration | Full Refresh plus CDC sync mode, minimal config |
| Full-load throughput | Baseline | Roughly 4.6x faster in the published test |
| CDC support | Supported, but one stalled table can block the whole source-to-target flow | Built for sustained CDC, around 1.38x faster in the same test |
| Schema evolution | DDL changes can break the pipeline; fallback is a full reload | Automatic schema discovery and evolution |
| Output format | Oriented toward Amazon targets | Open Iceberg or Parquet, readable by any engine |
| Compute cost | Baseline | About 4.61x cheaper on compute for the full refresh |
| Licensing | Managed AWS service | Open source |
| Destination targets | Many AWS targets, including databases (RDS, Aurora, Redshift), S3, DynamoDB | Object storage only (S3, ADLS, GCS) as Parquet or Iceberg; not a database target |
The rows worth expanding are the ones that bite teams after the pipeline is live, not during the demo.
Setup and configuration
There are a lot of moving parts to getting AWS DMS up and running. You provision and size a replication instance, create a source and target endpoint, enable source-side logging that CDC relies on (logical replication or pglogical for PostgreSQL, binlog for MySQL, or supplemental logging for Oracle), and define the table mappings. It's the parallelism that hits. With DMS you have to generate the partition boundaries yourself and if you want real throughput out of a large PostgreSQL table, you usually have to figure out what those boundaries are and script them by hand. None of this is difficult the first time, but each piece is a surface of maintenance someone has to own in the face of changing tables and schemas.
OLake collapses most of that into a guided setup. The UI walks you through connecting a source and destination, including the Iceberg catalog, then discovering the available streams and running a sync, without scripting any of it. You don't manage parallelism either. OLake splits large tables into virtual chunks and reads them in parallel by itself, and you shape behavior by picking a sync mode like Full-Refresh plus CDC rather than tuning boundaries by hand. Teams that want finer control can drive the same flow from the CLI with source.json and destination.json config files, but the UI covers the common path end to end.
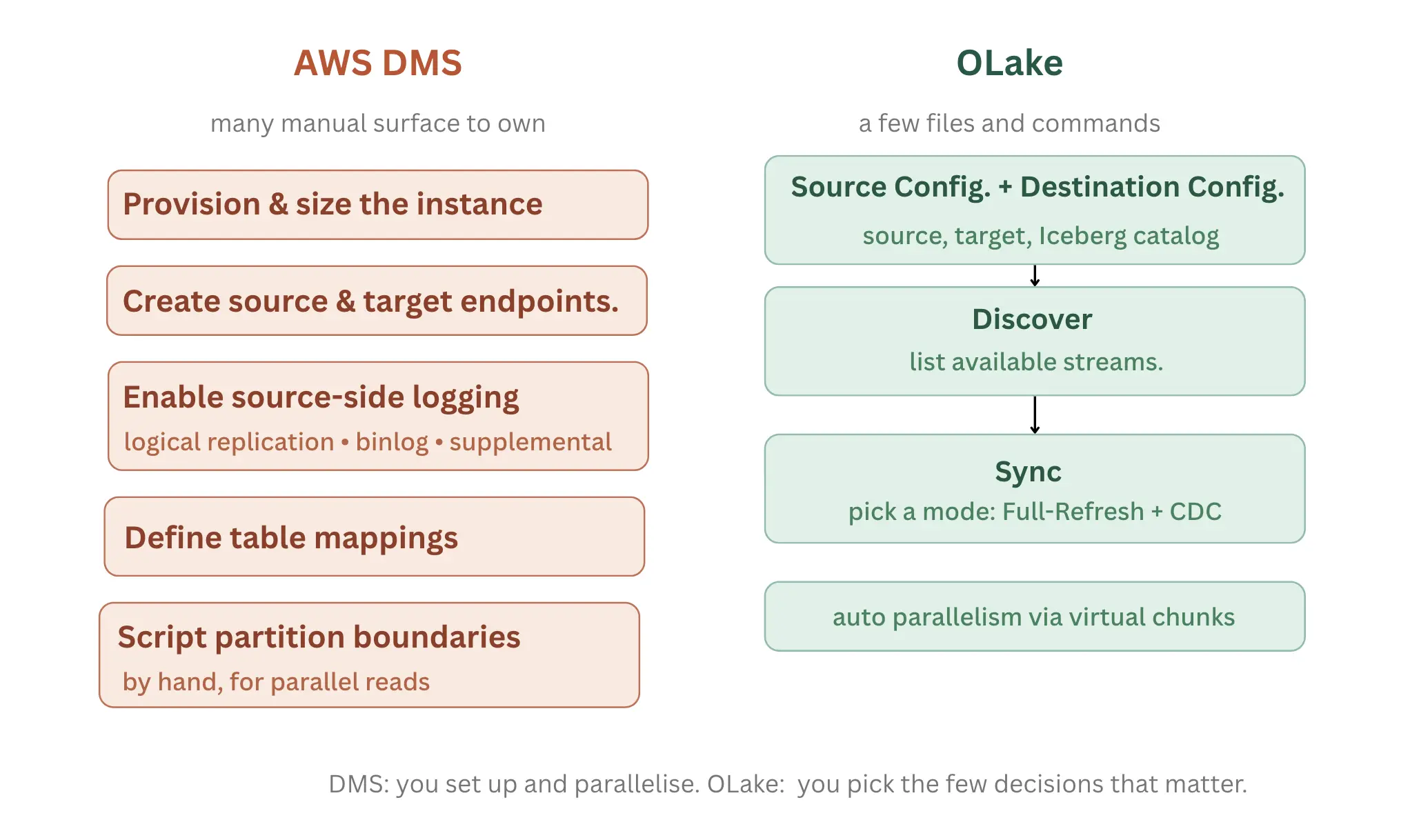
The real difference is the person doing the tuning. DMS asks you to set up and parallelise; OLake does those calls for you and exposes only the few decisions that really matter as configuration.
Data replication
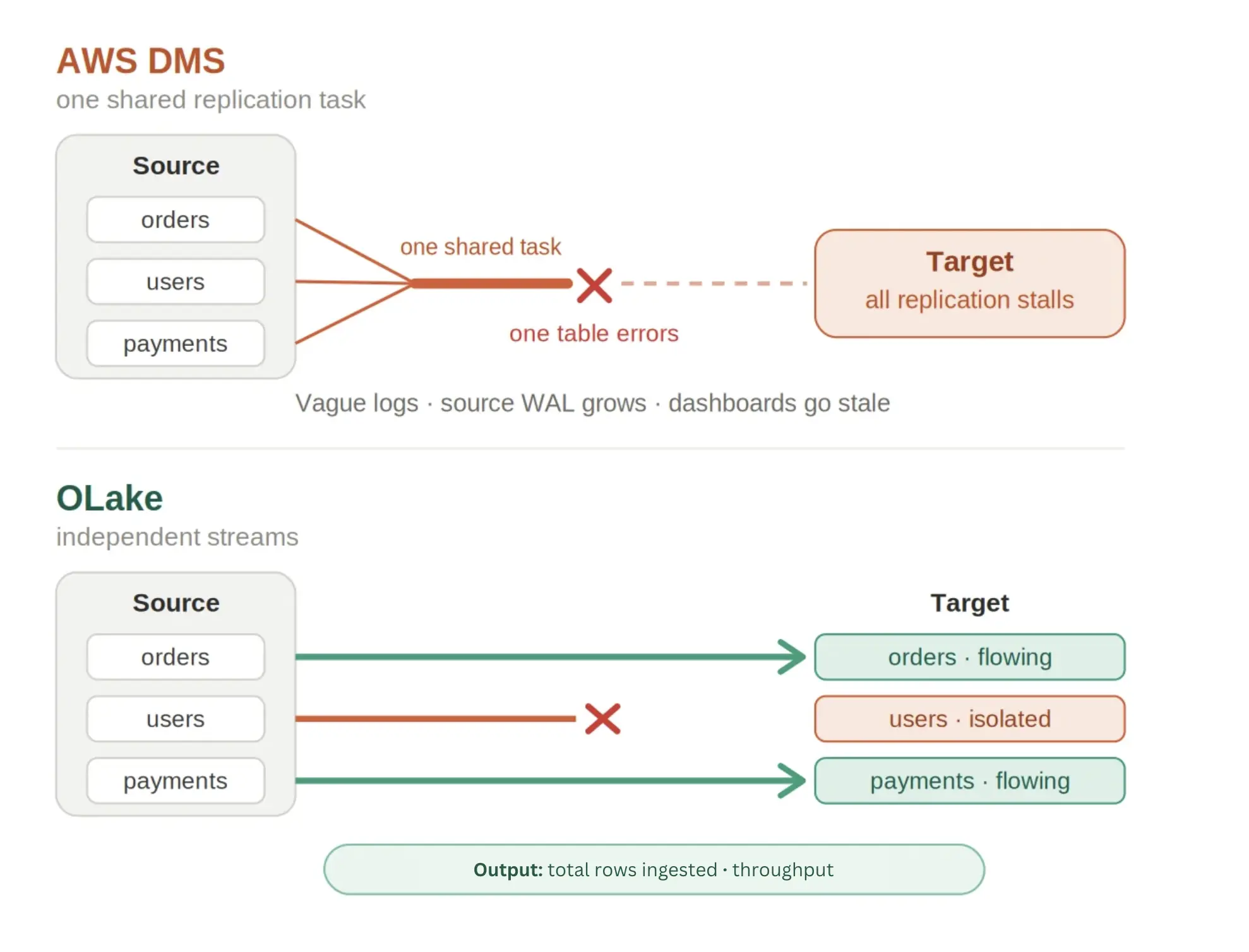
DMS does fine for a one-time migration. The trouble starts when teams run it as a long-lived CDC pipeline, and the same complaints come up again and again, both in public forums and from OLake's own users. One line sums it up: DMS is the Data Migration Service, not a replication service.
The pattern these users report is worth spelling out, because it is specific. When a task breaks, the logs give very little away about what failed or why, so root-causing turns into guesswork while the pipeline sits stalled. A single problem on one table can block all replication from the source to the target, which leaves downstream dashboards reading stale data and transaction logs growing inside the source RDS instances. More than one team has resorted to dropping the affected table on the warehouse side and letting DMS repopulate it from scratch, because that was faster than diagnosing the stall. Part of this is the shape of the tool itself. The migrate-then-catch-up model, a point-in-time load followed by replaying buffered changes, fits a finite move better than indefinite replication.
This isn't hypothetical. Xeno, a customer engagement platform, ran MySQL CDC on AWS DMS and kept hitting broken replication on routine schema changes, with recovery forcing full table reloads that stretched past 17 hours. After moving those pipelines to OLake, schema changes stopped breaking the flow and full-load time dropped from roughly 24 hours to around 13. You can read the full customer story here.
OLake is built for CDC as its main job, not a feature added on later, so it holds throughput on sustained incremental loads instead of drifting over time. Because streams are handled independently, a problem with one table does not freeze the rest of the pipeline, and the rest of your data keeps flowing while you deal with the single issue. When something does need attention, OLake exposes live sync stats, record counts, throughput, and an estimated finish time so you can see what is happening instead of piecing it together from vague logs. Together, steady throughput, isolated failures, and real visibility make CDC-based replication something you can rely on rather than something that surprises you.
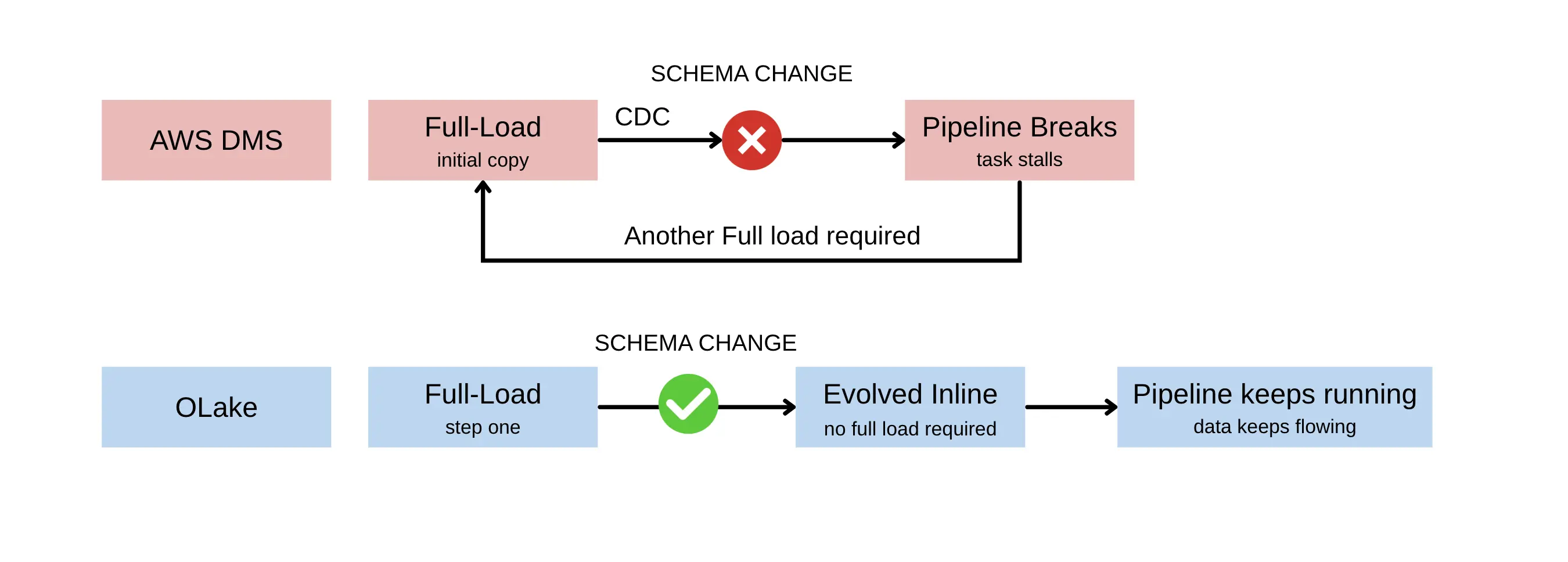
Schema evolution
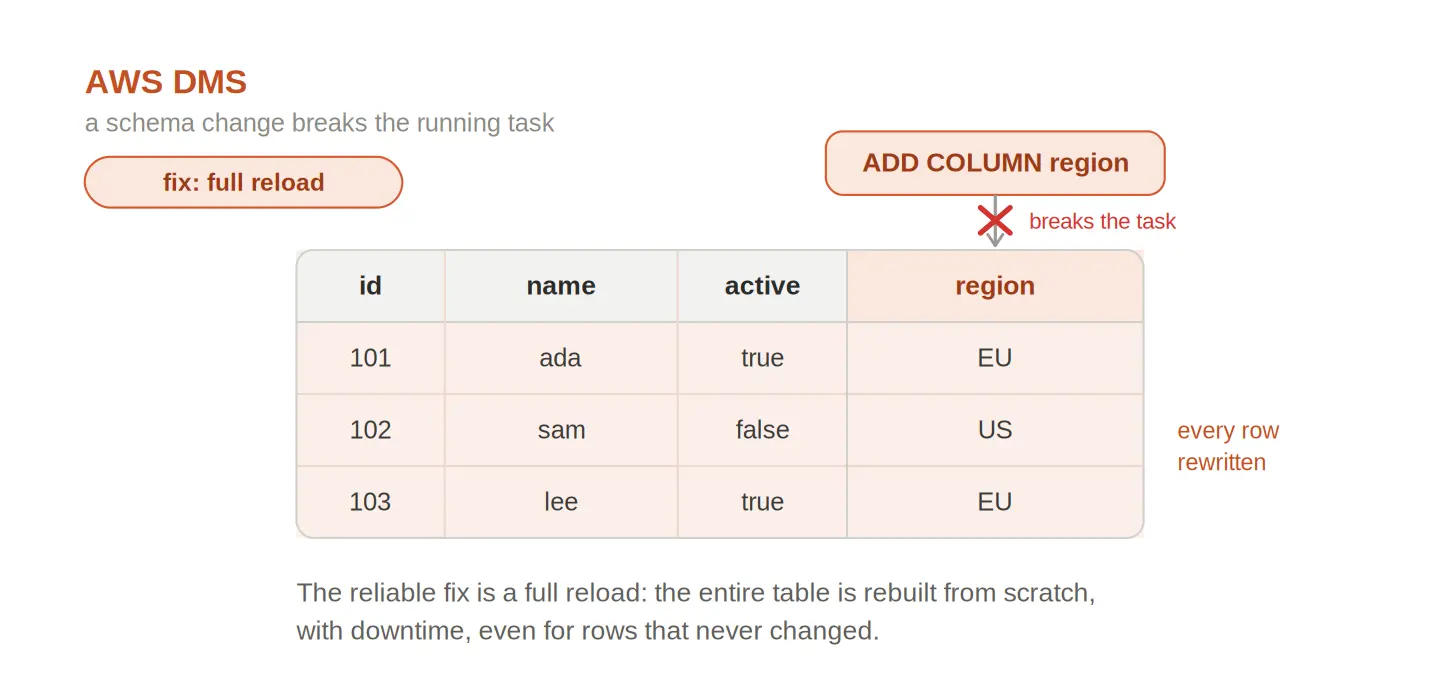
A DDL change on the source is where the two tools differ most in daily use. With DMS, a changing schema can break the running pipeline, and the usual fix is a full reload, which on a large table costs real time and downtime. It gets worse for teams that deliberately do not want DDL replicated, since they are left fixing schema drift by hand. Users also report data problems along the way: missing records, null values, and missing columns in the target, with a full reload again being the only reliable fix. There is even a known quirk where DMS, for some targets, stores boolean values as the strings "true" and "false", the kind of thing you find out in production, not in the docs.
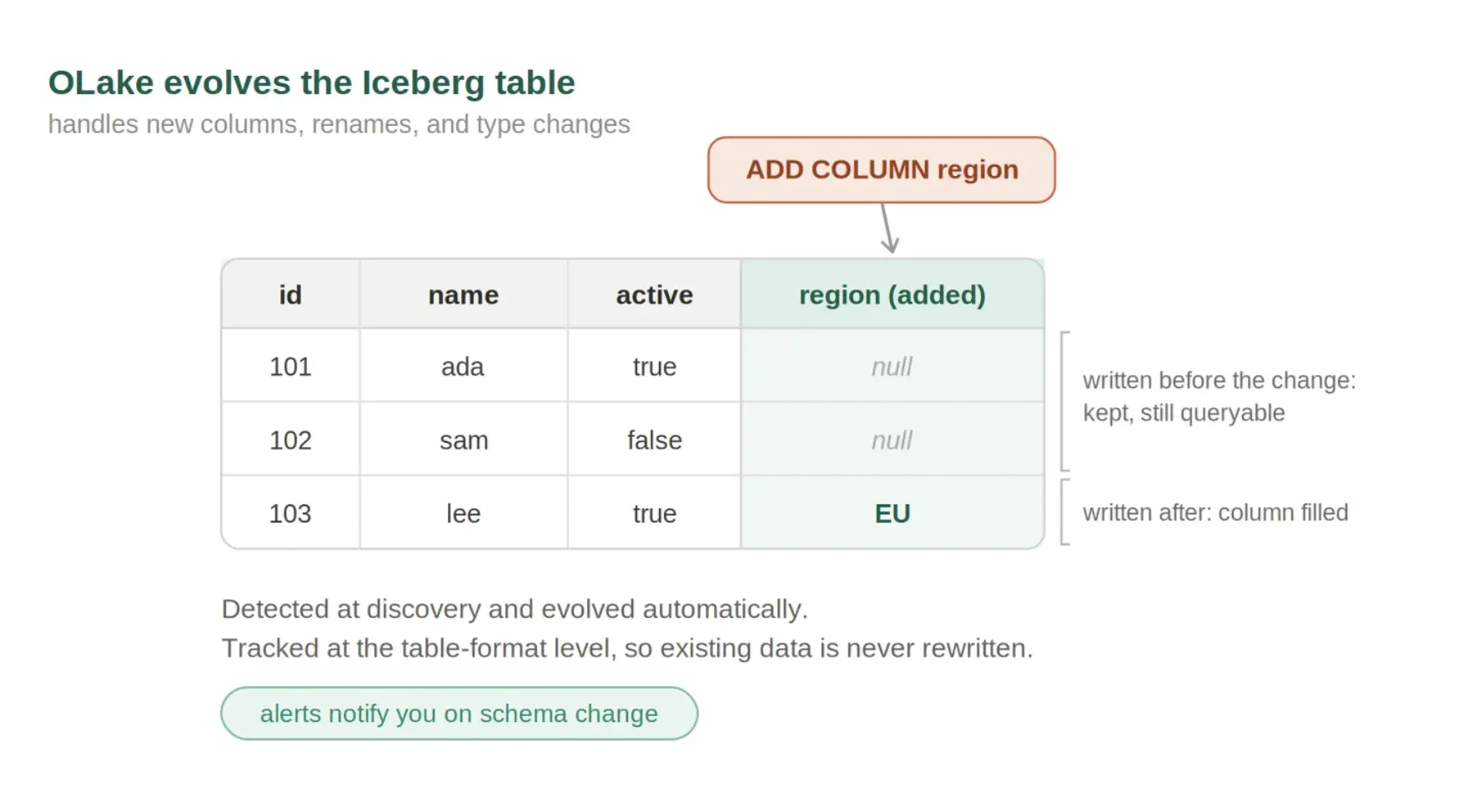
OLake handles this differently. It detects schema changes during the discovery step and evolves the target tables on its own, so a new column, a renamed field, or a type change upstream is picked up and applied rather than left to break the run. The pipeline keeps moving when the source moves, and a column added upstream does not turn into a reload. Because the destination is Apache Iceberg, which supports schema evolution at the table-format level, those changes are tracked without rewriting existing data, so old records stay queryable alongside the new shape. You can also set alerts on schema changes, so a shift on the source is something you are told about rather than something you find once the data already looks wrong.
Scaling and resource use
DMS ties throughput to the replication instance you size and pay for, so memory and CPU are capped by the instance class you choose, and a large table that outgrows that instance forces you to scale up or split the work. Getting good parallelism out of a big PostgreSQL table means generating partition boundaries by hand and tuning the load, which is more to set up and more to maintain. The initial load also works in stages: it captures each table at a point in time, holds the changes that happen meanwhile, and applies them before switching to CDC. That sequence needs table locks and puts heavy load on the source database at scale. Large tables, on the order of 100GB with heavy update traffic, were a common trigger for repeated full loads in the user reports above. DMS also does not move indexes, triggers, or stored procedures, so those have to be handled separately.
OLake needs a host too. It runs as a process on compute you provide, a VM, container, or Kubernetes pod, so there is a machine to size on this side as well. The difference is what that sizing involves. OLake is not a managed instance with a fixed class ceiling that you scale up the moment a table outgrows it, and it is built for high-throughput ingestion at terabyte scale, with memory efficiency treated as a goal rather than an afterthought. Instead of asking you to break large tables apart by hand, it splits them into virtual chunks on its own and reads those chunks in parallel, so a big table is a throughput opportunity rather than a problem to work around. It also streams records straight to the destination as they are read, rather than staging them in memory or an intermediary store first, which keeps memory use predictable even on very large loads and avoids the ceilings that force the splitting workarounds in the first place. Scaling is then a question of how many chunks to run in parallel and how much compute you give the host, not which instance class to jump to next.
Connectors, targets, and lock-in
DMS supports CDC database sources and points naturally at Amazon targets, with a VPC required for those targets and some cross-region paths unsupported, such as parts of DynamoDB. The serverless option trades instance management for further restrictions, so the limitations pages are worth reading closely before committing. If your pipeline needs to reach beyond that footprint, you end up adding tools around DMS to cover the gaps.
OLake writes to Apache Iceberg or Parquet, open formats that Spark, Trino, Flink, and other engines can query without copying the data again, and it pulls from databases, Kafka, and S3. For teams that want to avoid committing their analytics layer to a single vendor, open output is a structural advantage rather than a feature.
The benchmark, with the setup stated
But a benchmark is only useful if you know how it was run, so here's the setup:
Both tools moved the same data using the same hardware: an Azure PostgreSQL source (32 vCores and 128 GB RAM) writing Parquet to AWS S3. The dataset was the standard NYC Taxi data, the trips2 and fhv_trips tables, with a little over 4 billion rows in total. The full load test measured the time to move the full data set. Then the CDC test pushed 50 million change records across the two tables to see how each tool fared under sustained change. OLake ran in Full Refresh + CDC sync mode with 32 threads. DMS was running with 40 parallel tasks, and pglogical was to be enabled first.
Benchmark results:
- Full refresh: OLake ran the full load about 4.6x faster than AWS DMS on just over 4 billion rows.
- CDC: OLake was ~1.38x faster on the incremental load.
- Compute cost: OLake was around 4.61x cheaper for the full refresh, and that difference only adds up the more frequently the job runs, as a daily sync repeats the difference week after week. One result can be stated simply rather than flowery. The memory was almost a tie. OLake averaged about 31.76 GB across the full 4 billion rows and DMS about 30 GB, close enough to call it a tie. The difference between the two tools is speed and cost, not memory consumption. This does not need to be taken on trust, as the setup and dataset are open. You can run it again against your own data. The full numbers, including how cost adds up over time, are on the DMS vs OLake benchmark page.
One result can be stated simply rather than flowery. The memory was almost a tie. OLake averaged about 31.76 GB across the full 4 billion rows and DMS about 30 GB, close enough to call it a tie. The difference between the two tools is speed and cost, not memory consumption. This does not need to be taken on trust, as the setup and dataset are open. You can run it again against your own data. The full numbers, including how cost adds up over time, are on the DMS vs OLake benchmark page.
When AWS DMS is still the right call
An honest case for DMS. Because a comparison that praises only one side is not worth reading. It's a good choice for a one-off move into AWS, and it's especially good when the destination is a database engine such as RDS or Aurora, which OLake cannot target, and at heterogeneous migrations where the source and target run different engines. If your database is on the smaller side, can tolerate some downtime, and you are happy with a fully managed service which lands data in AWS rather than open formats, then the simple path is to stay inside the AWS toolchain. DMS can even feed Iceberg near real-time, but it takes some additional tooling on top, which some teams have set up and run well.
DMS does what it was built to do, well, as long as you follow the habits a migration tool expects. One small example is forgetting to drop a PostgreSQL replication slot once a migration is done, which can cause trouble on the source database later on. The message is not that DMS is a bad tool. DMS was built to migrate, and that is where the problems begin. When a migration tool is left running as permanent replication infrastructure.
When OLake is the better fit
OLake fits well when the work doesn't stop. OLake was built for the job of running a lakehouse pipeline on a daily basis once a migration has been completed. You're streaming changes into Apache Iceberg on an ongoing basis. You need to query that data from more than one engine. You want to keep your compute bill in check as volume grows. You want your analytics layer to stay on open formats instead of being tied to one vendor. OLake is built to satisfy each of those, not to bring additional tools.
It also takes away the ongoing costs that eat into teams on a long-lived DMS pipeline. Schema changes are absorbed, rather than breaking the run, so there is no manual-restart tax every time the source changes. If there is a failure, it stays local to that stream. It does not freeze the whole flow. And OLake Fusion handles the Iceberg table maintenance, the compaction and the small-file cleanup that prevent query performance from degrading over time, which DMS doesn't address at all.
And that's the real difference for an always-on database-to-lakehouse pipeline: not which tool is faster in a single run, but whether you spend your week watching the pipeline or trusting it.
Choosing between them
The right call comes down to the shape of the job, not a scorecard. The two tools are good at different things, and most of the regret comes from picking one for work it was never meant to do. The quickest way to place your own situation is to match it against the table below.
| If your situation looks like this | The better fit |
|---|---|
| A one-time migration of a database into AWS | AWS DMS |
| A heterogeneous move, where source and target run different engines (for example Oracle to Aurora) | AWS DMS |
| A fully managed service, staying inside AWS, with no need for open formats | AWS DMS |
| CDC into Apache Iceberg that runs indefinitely | OLake |
| Querying the same data from several engines (Trino, Spark, Snowflake, and others) | OLake |
| Keeping compute cost down at terabyte scale or with frequent syncs | OLake |
| Avoiding vendor lock-in by landing data in open table formats | OLake |
| Schema changes that should not turn into manual reloads | OLake |
| Iceberg table upkeep (compaction and small-file cleanup) handled for you | OLake |
Conclusion
Reach for AWS DMS when the work is finite and the destination is AWS. Its strength is getting a database, including one on a different engine, onto AWS through a managed service with little fuss. If you do not need open formats and the pipeline has an end date, the simplicity of staying inside one ecosystem is worth a lot.
Reach for OLake when the work does not end. Changes capture into Apache Iceberg, data that several query engines need to read, costs that have to stay flat as volume grows, and a stack you would rather not tie to a single vendor are all jobs it was built for. Its schema handling means a column added upstream does not cost you a reload, and OLake Fusion keeps the Iceberg tables healthy instead of leaving compaction as a chore for later.
Here is the pattern worth remembering. Most teams that struggle with DMS are not using a bad tool. They are using a migration tool to solve a replication problem, and the gap between those two jobs is where the late nights come from. If that sounds like your setup, the honest next step is to run the numbers on your own data. The OLake documentation is a good place to start, and the comparison holds up best when you test it against the workload you actually have rather than someone else's.
FAQs
Q1. Has anyone replaced AWS DMS with OLake in production?
Yes. Xeno moved its MySQL CDC pipelines off AWS DMS to OLake, self-hosted on Kubernetes, after schema changes kept breaking replication. Full-load time fell from about 24 hours to around 13, and schema changes no longer trigger reloads.
Q2. Is OLake a good AWS DMS alternative?
For an ongoing pipeline into Apache Iceberg, yes. DMS is built for a one-time migration with CDC added on, so teams that run it as permanent replication infrastructure tend to hit schema breaks and full reloads. OLake is built for sustained CDC into open table formats.
Q3. Can AWS DMS replicate into Apache Iceberg?
It can, but not on its own. DMS points naturally at Amazon targets and needs extra tooling on top to feed Iceberg in near real time. OLake writes Iceberg or Parquet directly.
Q4. Why does a schema change break an AWS DMS pipeline?
A DDL change on the source can stall the running task, and the fix most teams trust is a full reload. OLake detects schema changes during discovery and evolves the target tables on its own.
Q5. Is OLake faster than AWS DMS?
In the published test, on the same hardware and dataset, OLake ran the full load about 4.6x faster and sustained CDC about 1.38x faster. Memory use was close to a tie.
Q6. Can OLake write to a database such as RDS, Aurora, or Redshift?
No. OLake writes to object storage (S3, ADLS, GCS) as Parquet or Iceberg. If your destination is a database engine, DMS is the better fit.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.