Blogs on OLake

Ingesting Files from S3 with OLake: Turn Buckets into Reliable Streams (AWS + MinIO + LocalStack)
A comprehensive guide to ingesting data from Amazon S3 and S3-compatible storage using OLake, covering stream discovery, format support, incremental sync, and best practices for AWS, MinIO, and LocalStack.

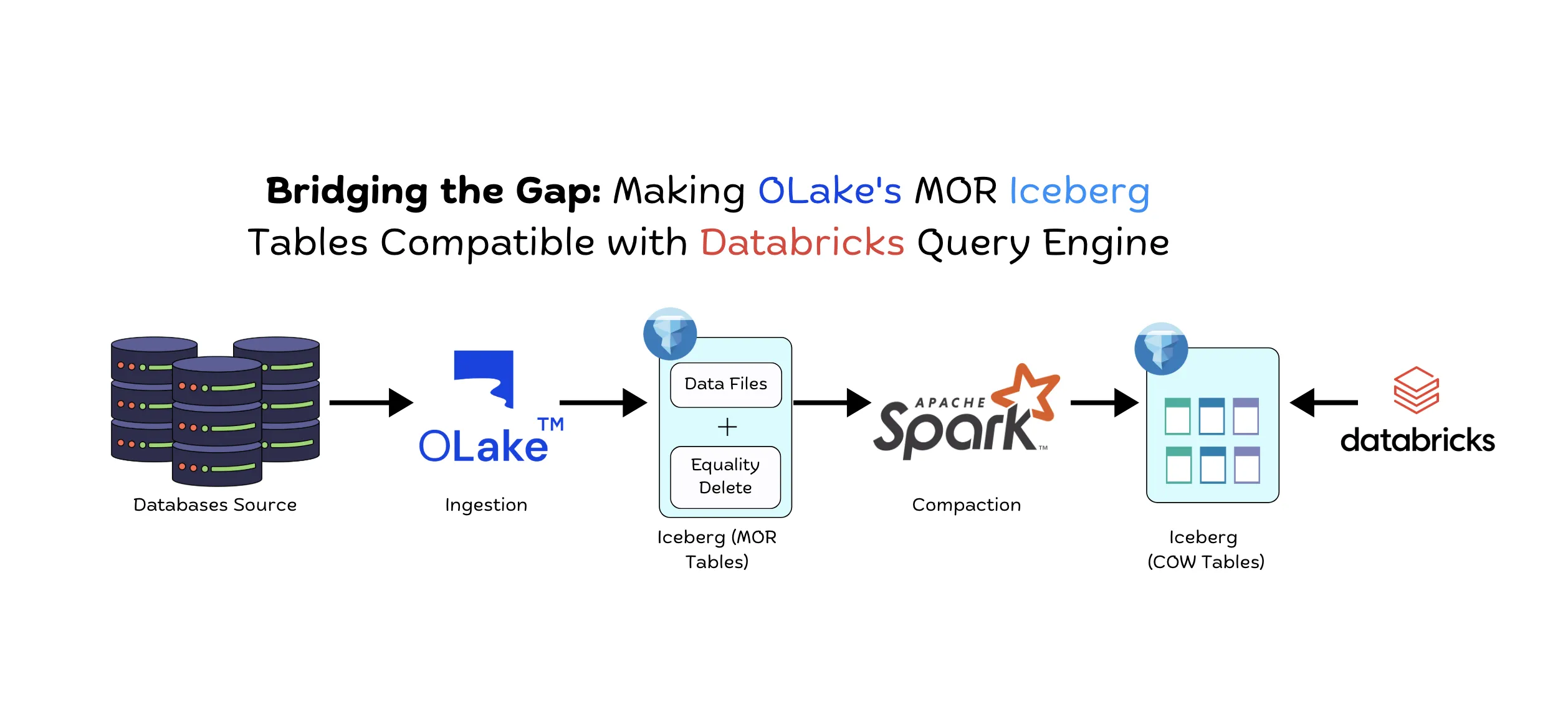
Bridging the Gap: Making OLake's MOR Iceberg Tables Compatible with Databrick's Query Engine
Learn how to make OLake's Merge-on-Read (MOR) Iceberg tables compatible with Databricks using an automated MOR to COW write script that transforms MOR tables into Copy-on-Write (COW) format for accurate analytics queries.

OLake — now an Arrow-based Iceberg Ingestion Tool
Discover how OLake's new Arrow-based architecture delivers 1.75x faster ingestion performance.


Building a Data Lakehouse with Apache Iceberg + ClickHouse + OLake Go
Learn how to build a complete data lakehouse using Apache Iceberg, ClickHouse, OLake Go and MinIO for real-time CDC, scalable storage, and fast analytics. Step-by-step guide with Docker setup.

Beyond Structured Tables: Variant and Geospatial Data in Apache Iceberg v3
Explore how Apache Iceberg v3 introduces native support for Variant and Geospatial data types, enabling unified storage and querying of structured, semi-structured, and spatial data in modern data lakehouses.


Apache Iceberg: Why This Open Table Format is Taking Over Data Lakehouses
Explore why Apache Iceberg has become the leading open table format for data lakehouses, offering ACID transactions, schema evolution, time travel, and multi-engine support for modern analytics at scale.