Postgres → Iceberg → Doris: A Smooth Lakehouse Journey Powered by Olake

If you've been working with data lakes, you've probably felt the friction of keeping your analytics engine separate from your storage layer. With your data neatly sitting in Iceberg, the next challenge is querying it efficiently without moving it around.
That's a pretty fair reason to bring Doris in.
Building a modern data lakehouse shouldn't require stitching together a dozen tools or writing complex Spark jobs. In this guide, I'll show you how to create a complete, production-ready lakehouse architecture that:
- Captures real-time changes from PostgreSQL using CDC (Change Data Capture)
- Stores data in open Apache Iceberg format on object storage
- Queries data at lightning speed with Apache Doris
- All orchestrated seamlessly by OLake
By the end, you'll have a running system that syncs database changes in real-time and lets you query — without moving or duplicating data.
So, what is Apache Doris?
Apache Doris is a real-time analytical database built on MPP (Massively Parallel Processing) architecture, designed to handle complex analytical queries at scale — often delivering sub-second query latency, even on large datasets.
Probably, too much of technical jargon, isn't it? Here is what it means in simple terms:
"A fast, intelligent query engine that lets you analyze your Iceberg tables directly, without having to move or duplicate your data anywhere else."
Why Doris for Your Lakehouse?
At its core, Doris combines three powerful execution capabilities:
Vectorized Execution Engine: Unlike traditional row-by-row processing, Doris processes data in batches (vectors), allowing it to leverage modern CPU capabilities like SIMD (Single Instruction, Multiple Data) instructions. This translates to faster query execution on the same hardware.
Pipeline Execution Model: Doris breaks down complex queries into pipeline stages that can execute in parallel across multiple cores and machines. Think of it like an assembly line where each stage processes data simultaneously, rather than waiting for the previous step to complete entirely.
Advanced Query Optimizer: The query optimizer automatically rewrites your SQL queries to find the most efficient execution plan. It handles complex operations like multi-table joins, aggregations, and sorting without you having to manually optimize your queries.
We are currently at version 4.0.0 of Apache Doris, currently to the time of writing this blog, and it has introduced comprehensive support for Apache Iceberg's core features.
What Doris brings to your Iceberg tables:
- Universal Catalog Support: Works with all major Iceberg catalog types — REST, AWS Glue, Hive Metastore, Hadoop, Google Dataproc Metastore, and DLF.
- Full Delete File Support: Reads both Equality Delete Files and Positional Delete Files, which is crucial for CDC workloads where updates and deletes happen frequently.
- Time Travel Queries: Query historical snapshots of your Iceberg tables to see how data looked at any point in time.
- Snapshot History: Access complete snapshot metadata via table functions to understand data evolution.
- Transparent Query Routing: Doris automatically routes queries to materialized views when available, accelerating common query patterns without changing your SQL.
The Data Pipeline: How the Pieces Fit Together
Let's understand the complete data flow from your operational database to real-time analytics.
The Architecture
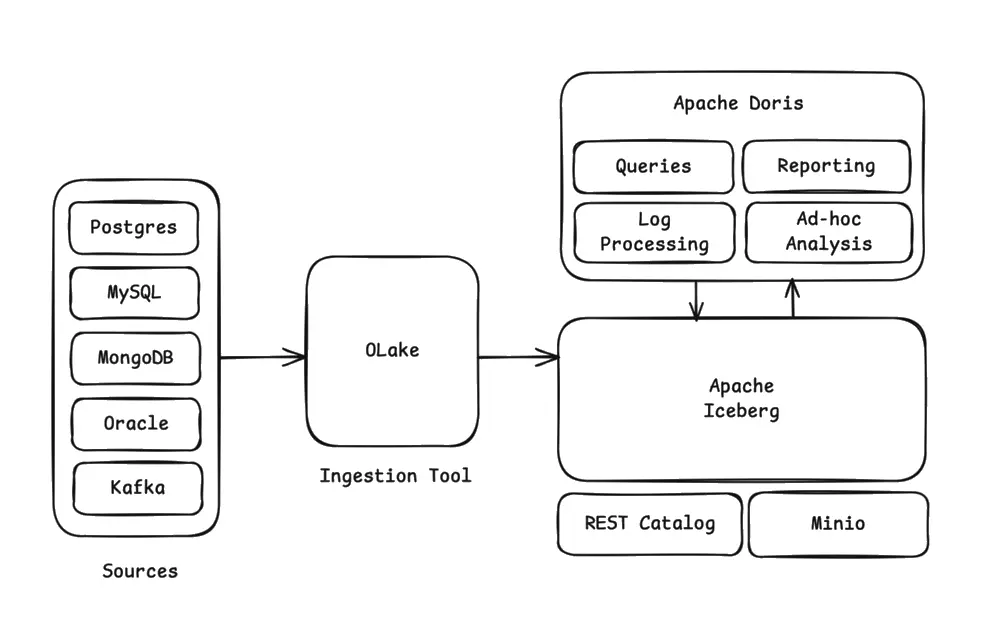
Here's how data flows through our lakehouse stack:
-
Source Database (PostgreSQL): Your operational database continues running normally, handling transactional workloads.
-
OLake CDC Engine: Captures changes from PostgreSQL using logical replication and writes them directly to Apache Iceberg format.
-
Apache Iceberg Tables: Your data lands in Iceberg tables stored in object storage (MinIO/S3), maintaining full ACID guarantees with snapshot isolation.
-
REST Catalog: Tracks the current state of your Iceberg tables, managing metadata pointers so query engines always read the latest consistent snapshot.
-
Apache Doris: Queries your Iceberg tables directly from object storage, delivering sub-second analytics without moving data.
Why This Stack?
No Data Duplication: Unlike traditional ETL pipelines that copy data multiple times, your source data is written once to Iceberg and queried directly by Doris.
Real-Time Insights: Changes in PostgreSQL appear in your analytics, OLake's CDC sync captures inserts, updates, and deletes as they happen.
Cost-Effective Storage: Object storage (S3/MinIO) costs a fraction of traditional data warehouse storage, while Iceberg's efficient metadata handling keeps query performance high.
Decoupled Compute and Storage: Scale your query engine (Doris) independently from storage. Need more query power? Add Doris nodes. Need more storage? Just expand your object store.
About OLake
OLake is an open-source CDC tool specifically built for lakehouse architectures. It supports these sources: PostgreSQL, MySQL, MongoDB, Oracle, and Kafka. You can check out our official documentation for detailed source configurations.
What makes OLake different? It writes directly to Apache Iceberg format with proper metadata management, schema evolution support, and automatic handling of CDC operations (inserts, updates, deletes). No need for complex Spark jobs or Kafka pipelines — OLake handles the entire ingestion flow. We support all major Iceberg catalogs.
Our Demo Setup
For this tutorial, we're using:
- tabulario/iceberg-rest: A lightweight REST catalog implementation
- MinIO: S3-compatible object storage that runs locally
- Apache Doris: Hosted on a cloud instance for remote querying
This setup mirrors what Apache Doris recommends in their official lakehouse documentation.
Prerequisites
Before we dive into the setup:
- A cloud instance (AWS EC2, Azure VM, or GCP Compute Engine) with SSH access
- Docker installed
- At least 4GB RAM and 20GB disk space
- Basic familiarity with Linux terminal commands
Let's get started.
Step 1 – Start your REST Catalog + MinIO + Doris
Configure System Parameters
First, we need to configure a critical Linux kernel parameter. Apache Doris uses memory-mapped files extensively for its storage engine, and the default limit is too low.
sudo sysctl -w vm.max_map_count=2000000
This sets the maximum number of memory map areas a process can have. Without this, Doris Backend (BE) nodes will fail to start with memory allocation errors.
Make it permanent across reboots:
echo "vm.max_map_count=2000000" >> /etc/sysctl.conf
Verify the setting:
sysctl vm.max_map_count
You should see vm.max_map_count = 2000000.
Deploy the Lakehouse Stack
Apache Doris provides a convenient docker-compose setup that includes everything we need:
git clone https://github.com/apache/doris.git
Navigate to the lakehouse sample directory:
cd doris/samples/datalake/iceberg_and_paimon
This directory contains a complete lakehouse stack with the following services:
- Apache Doris: MPP query engine with Frontend (FE) and Backend (BE) nodes for analytics
- Iceberg REST Catalog: Manages table metadata and schema evolution
- MinIO: S3-compatible object storage for Iceberg table data files
- MinIO Client (mc): Automatically initializes buckets and sets permissions
- Sample configurations: Pre-configured with connectors and initialization scripts
Start all services:
bash ./start_all.sh
This script will take some amount of time to execute, it will:
- Pull required Docker images (first run takes 5-10 minutes depending on your connection)
- Start MinIO and create necessary buckets
- Initialize the Iceberg REST catalog
- Start Doris Frontend and Backend nodes
- Wait for all services to be healthy
You'll see output as each service starts. Wait until you see:
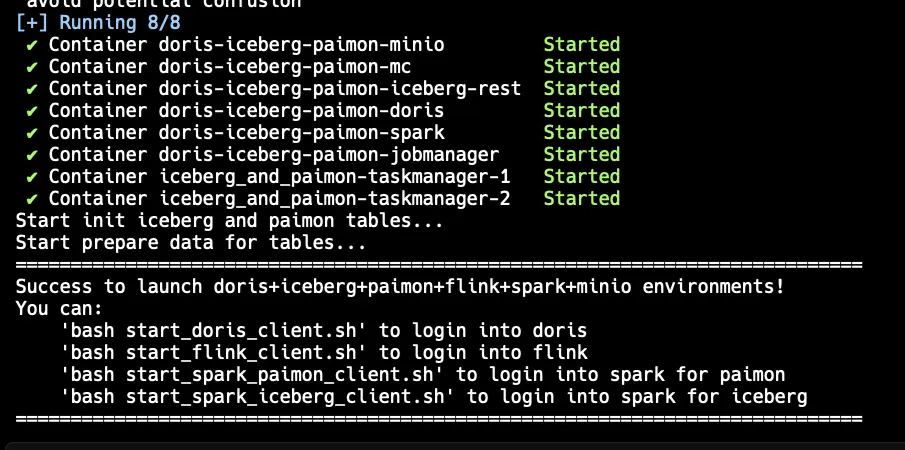
Access the Doris CLI
bash start_doris_client.sh
This opens the Doris SQL client, and you can now run queries against your lakehouse. We'll use this later to query the Iceberg tables.
Step 2 – Set Up OLake for CDC Ingestion
Now we'll configure OLake to capture changes from your PostgreSQL database and write them to Iceberg tables.
Start OLake UI
Open a new terminal session on your cloud instance and deploy OLake:
curl -sSL https://raw.githubusercontent.com/datazip-inc/olake-ui/master/docker-compose.yml | docker compose -f - up -d
This starts the OLake UI and backend services. OLake runs on port 8000, but since it's on your remote cloud instance, you'll need to access it from your local machine.
Set Up SSH Port Forwarding
To access both OLake UI and MinIO from your local browser, create SSH tunnels. Run these commands on your local machine (not on the cloud instance):
ssh -L 8000:localhost:8000 olake-server
ssh -L 19002:localhost:19002 olake-server
What's happening here?
-L 8000:localhost:8000: Forwards local port 8000 to the instance's port 8000 (OLake UI)-L 19002:localhost:19002: Forwards local port 19002 to the instance's port 19002 (MinIO)
If you haven't configured an SSH alias, add this to your local ~/.ssh/config:
Host olake-server
HostName <YOUR_INSTANCE_PUBLIC_IP>
User azureuser
IdentityFile <PATH_TO_YOUR_PEM_FILE>
Replace the values with your instance details. This lets you use olake-server instead of typing the full SSH command each time.
Access the Web Interfaces
With port forwarding active, you can now access both services from your local browser:
- OLake UI:
http://INSTANCE_IP:8000 - MinIO Console:
http://INSTANCE_IP:19002
Replace INSTANCE_IP with your cloud instance's public IP address.
Prepare MinIO Storage
MinIO needs a bucket to store Iceberg table data:
- Open MinIO at http://INSTANCE_IP:19002
- Login with default credentials (typically
admin/password) - Create a new bucket named
warehouse
This bucket will hold all your Iceberg table data files (Parquet) and metadata (JSON/Avro).
Configure OLake Job
Now let's configure OLake to sync data from your source database to Iceberg.
Create Source Connection:
- In OLake UI, navigate to Sources → Create Source
- Choose your source database type (PostgreSQL, MySQL, MongoDB, etc.)
- Enter connection details:
- Host, port, database name
- Username and password
- For PostgreSQL CDC: Enable logical replication and provide publication/slot names, etc.
You can follow a detailed doc for creating postgres source connection.
Create Destination (Iceberg):
Setup the config like this,
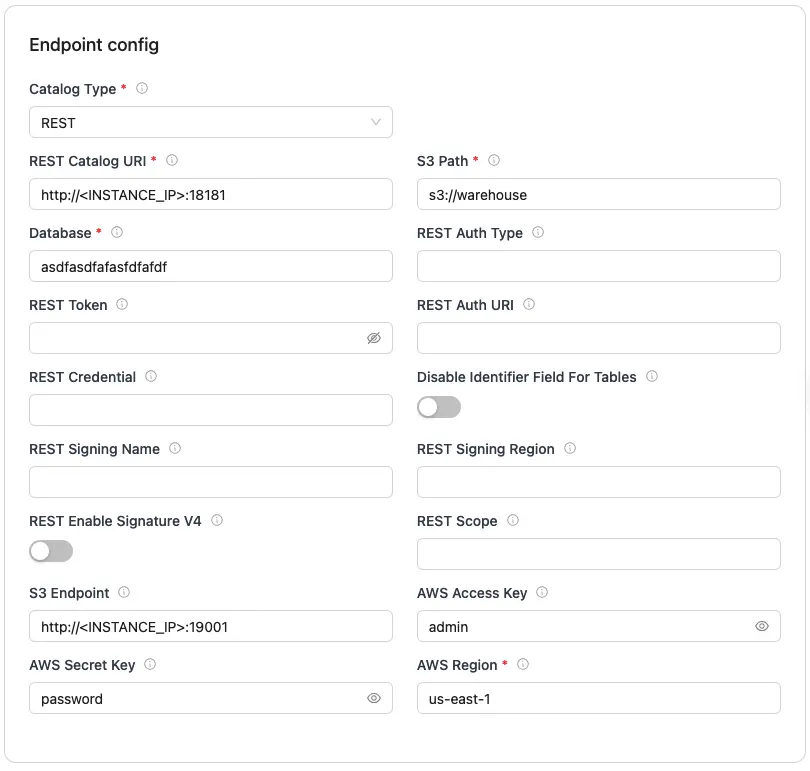
For any other detail you can check out our official documentation.
Create and Run Job:
- Navigate to Jobs → Create Job
- Select your source and destination
- Choose tables/collections to sync
- Select sync mode:
- Full Refresh + CDC: Initial snapshot followed by real-time changes
- CDC Only: Stream only new changes
- Start the sync
You can check out our official documentation for a detailed workflow from creating your job pipeline to managing ongoing sync operations.
Step 3 – Query Your Iceberg Tables with Doris
With OLake continuously syncing data to Iceberg, it's time to query that data using Apache Doris. Let's explore your lakehouse!
Connect to Doris
Now, in the Doris CLI which we created in Step 1, run the following commands.
List all available catalogs in Doris:
SHOW CATALOGS;
You should see the iceberg catalog listed. This catalog was pre-configured in the docker-compose setup to point to the REST catalog.
Switch to Iceberg Catalog
Set the Iceberg catalog as your active context:
SWITCH iceberg;
Now all queries will run against Iceberg tables unless you explicitly specify another catalog.
Refresh Catalog Metadata
The Iceberg catalog might not immediately reflect newly created tables. Refresh it to pull the latest metadata:
REFRESH CATALOG iceberg;
Why refresh? Doris caches catalog metadata for performance. When OLake creates new tables or updates schemas, refreshing ensures Doris sees the latest state.
Explore Your Data
List all databases (namespaces in Iceberg terminology):
SHOW DATABASES;
Switch to your database:
USE <database_name>;
List all tables:
SHOW TABLES;
Query Your Synced Data
Now run a simple query:
SELECT * FROM iceberg.<database_name>.<table_name> LIMIT 10;
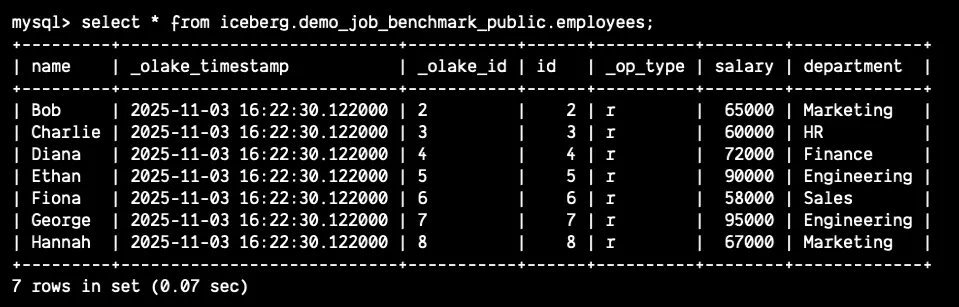
What you're seeing: Data from your source database, stored in Iceberg format, queried through Doris's MPP engine. No data movement, no duplication — just direct querying from object storage.
Troubleshooting
ERROR 1105 (HY000): errCode = 2, detailMessage = There is no scanNode Backend available.[10002: not alive]
You need to set vm.max_map_count to 2000000 under root. So, run this command:
sudo sysctl -w vm.max_map_count=2000000
then restart your Doris BE and then run your table query command and it should work fine.
Happy Engineering! Happy Iceberg!
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.