24 posts tagged with "Apache Iceberg"
Blogs on the topic Apache Iceberg
View All Tags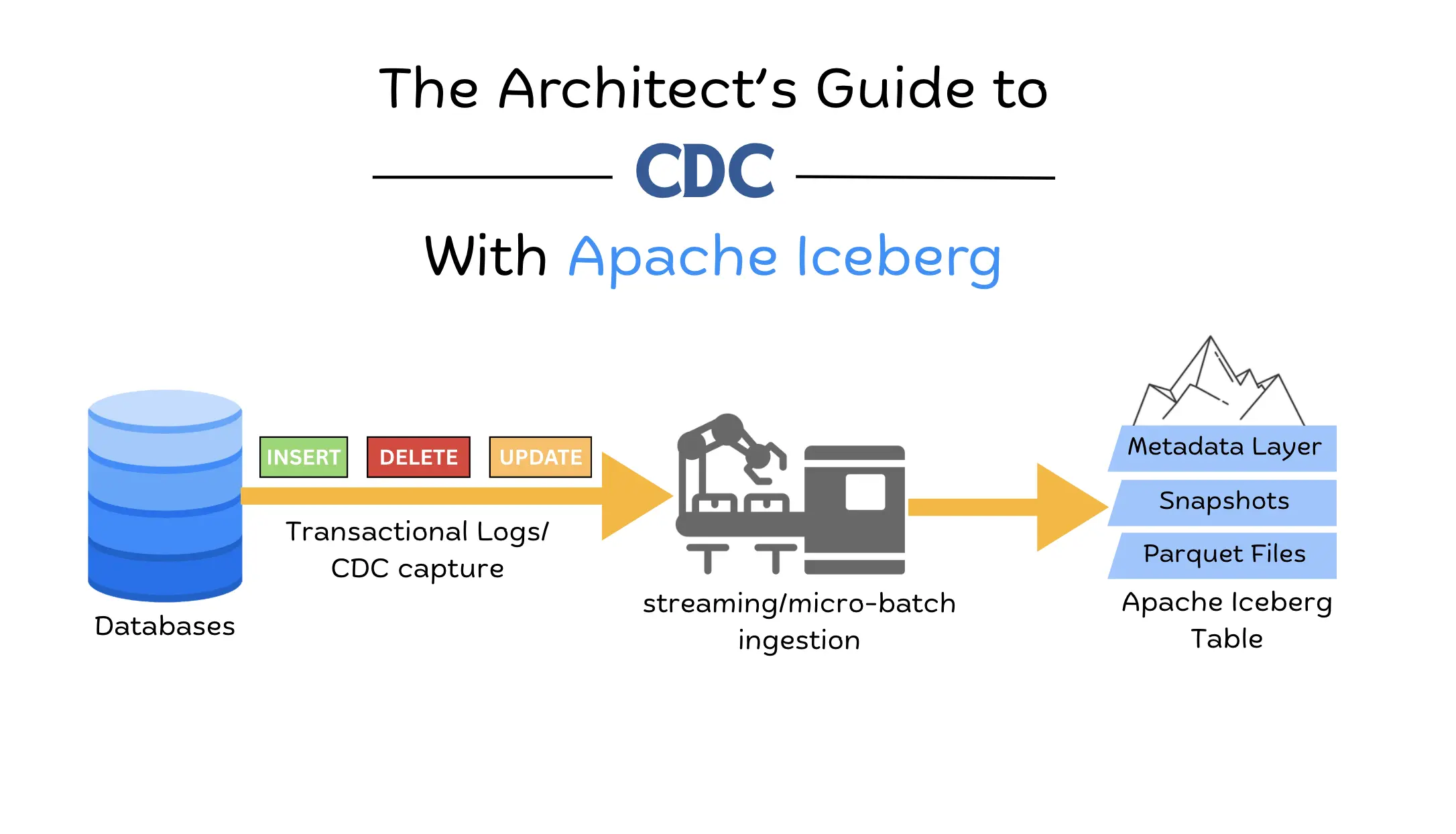
The Architect’s Guide to CDC with Apache Iceberg
Learn how to design reliable CDC pipelines into Apache Iceberg, covering ingestion patterns, delete handling, and architecture best practices.

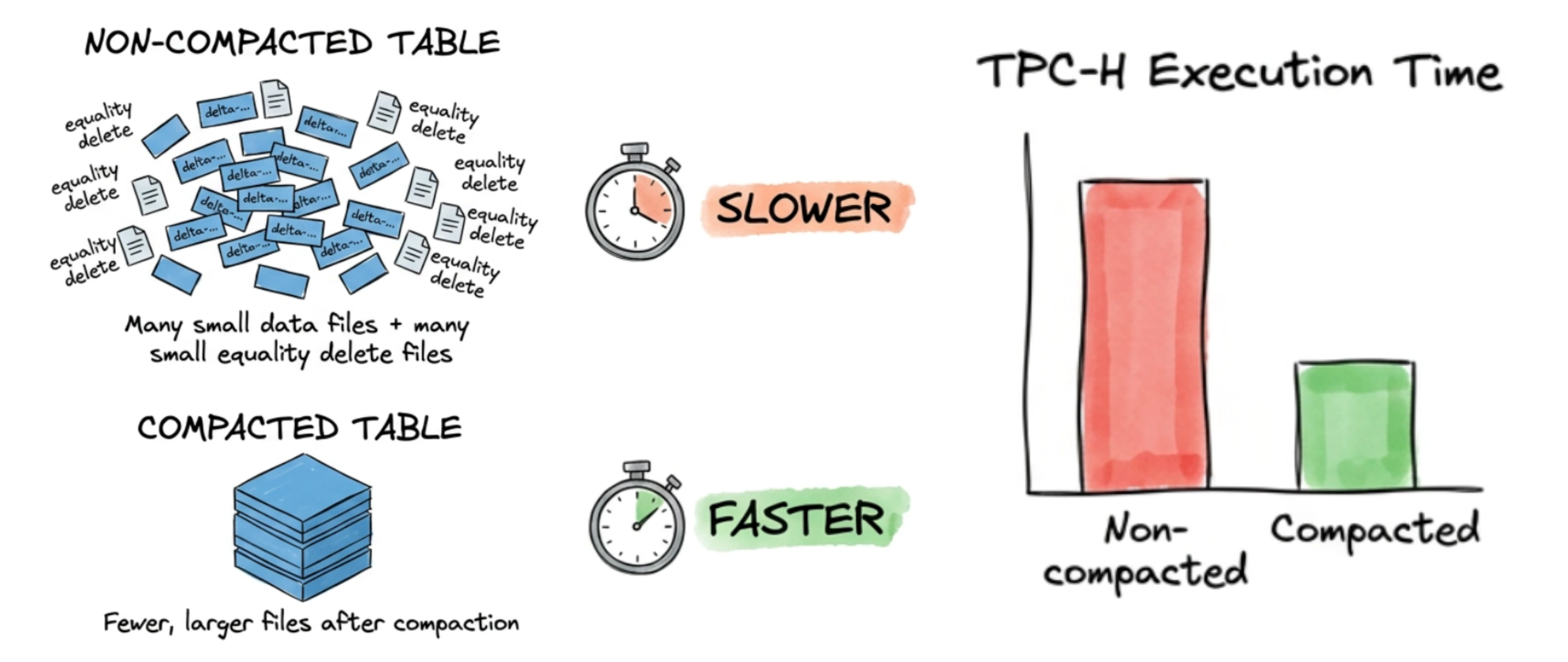
Iceberg Compaction: How Much Faster Are TPC-H Queries?
We ran TPC-H queries on Iceberg tables with many small files, then compacted them and ran the same queries again. Here's how much faster compaction made them.


IBM Db2 LUW to Lakehouse: Sync to Apache Iceberg Using OLake
A practical guide to syncing IBM Db2 for LUW databases to Apache Iceberg using OLake, covering setup, configuration, sync modes, troubleshooting, and DB2-specific considerations like RUNSTATS and REORG.

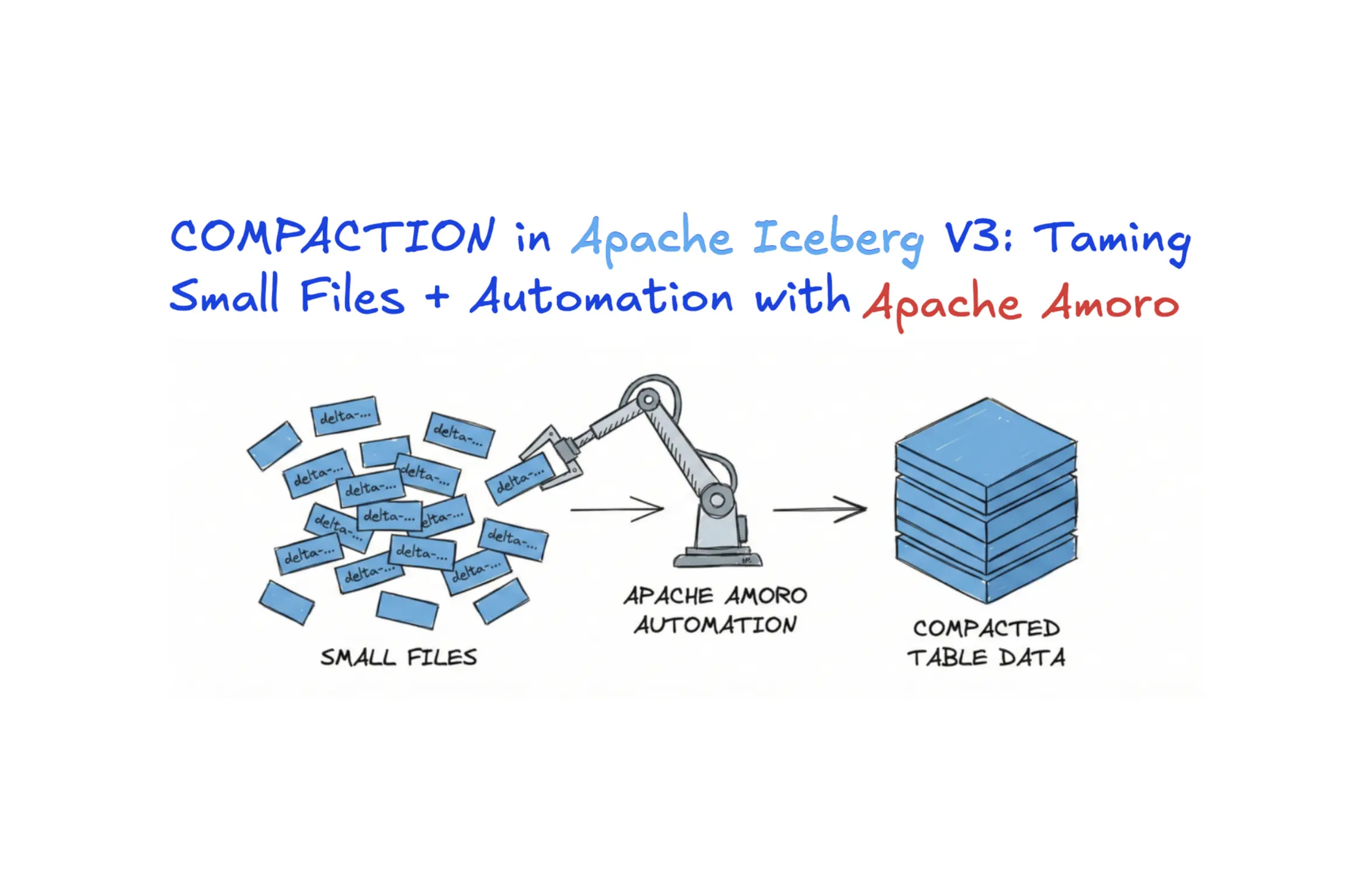
How to Compact Apache Iceberg Tables: Small Files + Automation with Apache Amoro
A practical guide to fixing small-file bloat in Apache Iceberg, showing when and how to run compaction, the performance gains you can expect, and how Amoro automates it to turn Iceberg tables into self-optimizing lakehouses.


Sync MSSQL to Your Lakehouse with OLake
A practical guide to syncing Microsoft SQL Server (MSSQL) into Apache Iceberg using OLake, covering sync modes, CDC setup, schema changes, data type mapping, and troubleshooting.
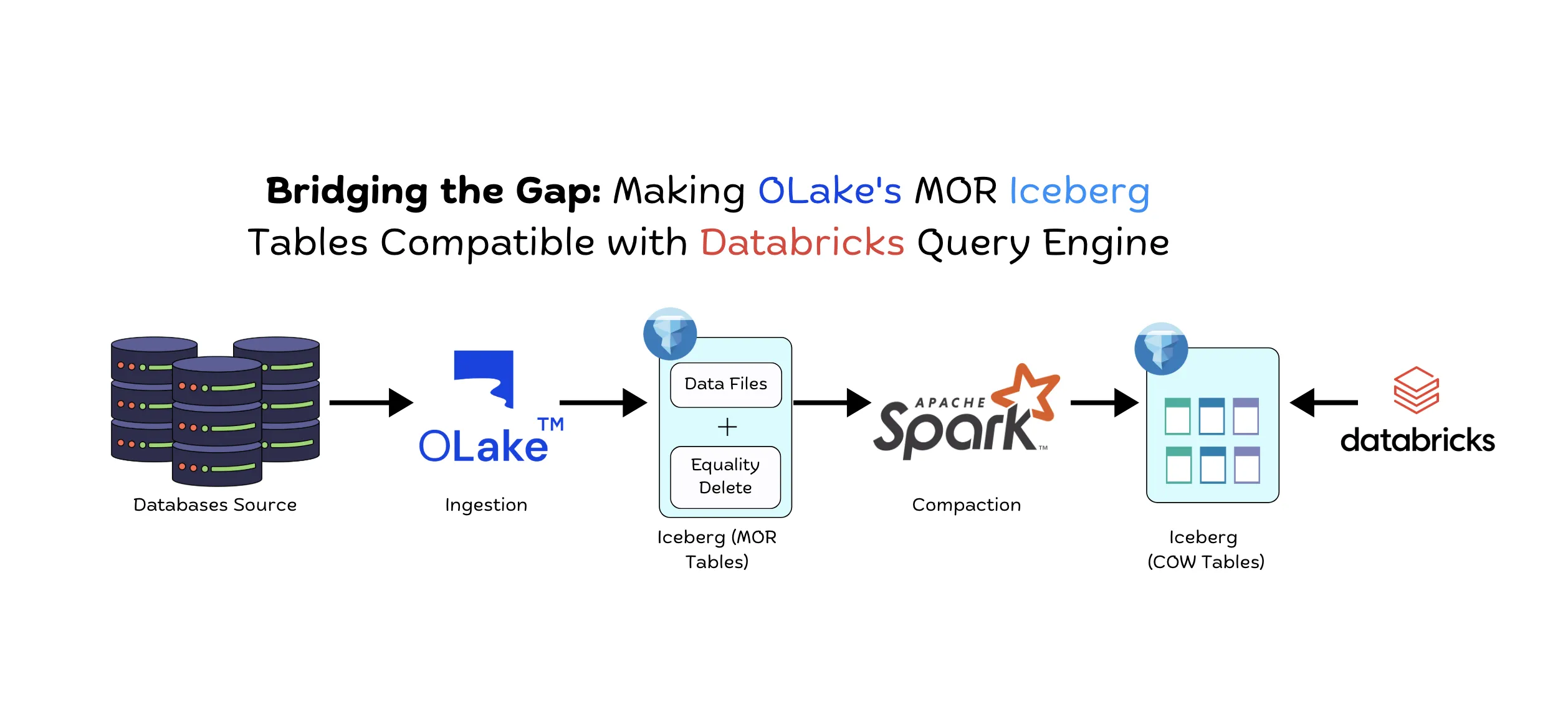
Bridging the Gap: Making OLake's MOR Iceberg Tables Compatible with Databrick's Query Engine
Learn how to make OLake's Merge-on-Read (MOR) Iceberg tables compatible with Databricks using an automated MOR to COW write script that transforms MOR tables into Copy-on-Write (COW) format for accurate analytics queries.