Reliable Lakehouse Ingestion at Scale: How LendingKart Improved Data Correctness and Compressed Lake Ingestion Volume by 100×




How LendingKart reduced daily MongoDB data movement from gigabytes to megabytes while completing an 11 years historical backfill that their Debezium + Spark setup couldn't deliver reliably — Prasanna, Ankit & Abhishek, LendingKart
Overview
LendingKart is a leading digital lending platform in India, powering credit access for millions of consumers and small businesses. Data plays a central role in LendingKart's platform from underwriting and risk modeling to customer lifecycle management and internal decision systems.
As LendingKart's data platform evolved, the team built a robust lake architecture using open-source technologies, including Delta Lake, Spark, and Kubernetes. While their existing CDC pipelines worked well for transactional workloads in MySQL, a subset of large, long-lived MongoDB collections presented unique challenges when syncing data into the lake.
To address these challenges without disrupting their broader data infrastructure, LendingKart adopted OLake as a focused ingestion layer improving data reliability, dramatically reducing ingestion volume, and laying the groundwork for future lakehouse evolution.
The Data Platform at LendingKart
LendingKart operates a production-grade data platform with:
- Primary sources: MySQL and MongoDB
- CDC & streaming: Debezium and Kafka
- Lakehouse storage: Open source Delta Lake on object storage
- Compute: Spark on Kubernetes
- Architecture: Medallion-style (Bronze, Silver, Gold)
Over time, the platform grew to include:
- ~700 active tables (consolidated from 1200+)
- ~100–150 MongoDB collections
- Transactional and historical datasets spanning 11+ years
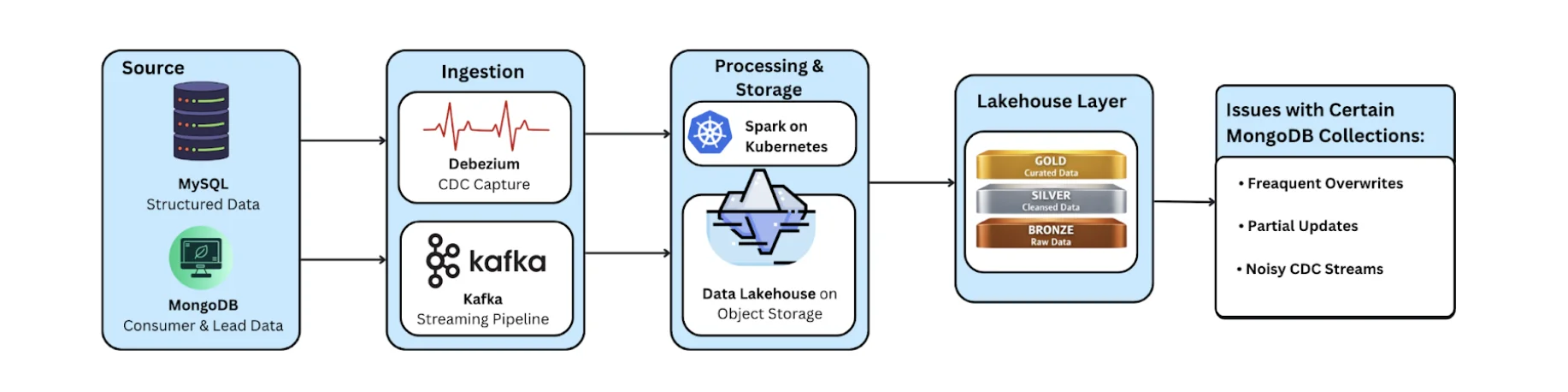
For most use cases, this architecture was reliable and well understood. However, some MongoDB collections, particularly customer and lead datasets did not fit cleanly into traditional CDC or incremental ingestion patterns because of the huge size and nature of json objects.
The Challenge: Long-Lived MongoDB Data with Unpredictable Updates
LendingKart relied on CDC pipelines for MySQL and MongoDB, with Spark Streaming jobs propagating changes into object storage, followed by batch ETL pipelines to build analytical tables. This architecture worked well for many transactional and operational use cases.
However, MongoDB introduced a different class of problems.
One of LendingKart's most business-critical datasets, the leads collection dataset spans more than a decade of data and continues to receive updates even today.
"Our leads data goes back to 2014, and even today around 5 percent of very old records still get updated without any reliable updated timestamp."
Prasanna
Associate Director - Data Strategy & Engineering, LendingKart
Because many MongoDB documents lacked a dependable audit field, it was difficult to identify which historical records had changed. Incremental syncs became unreliable, forcing the team to make trade-offs between correctness and operational feasibility.
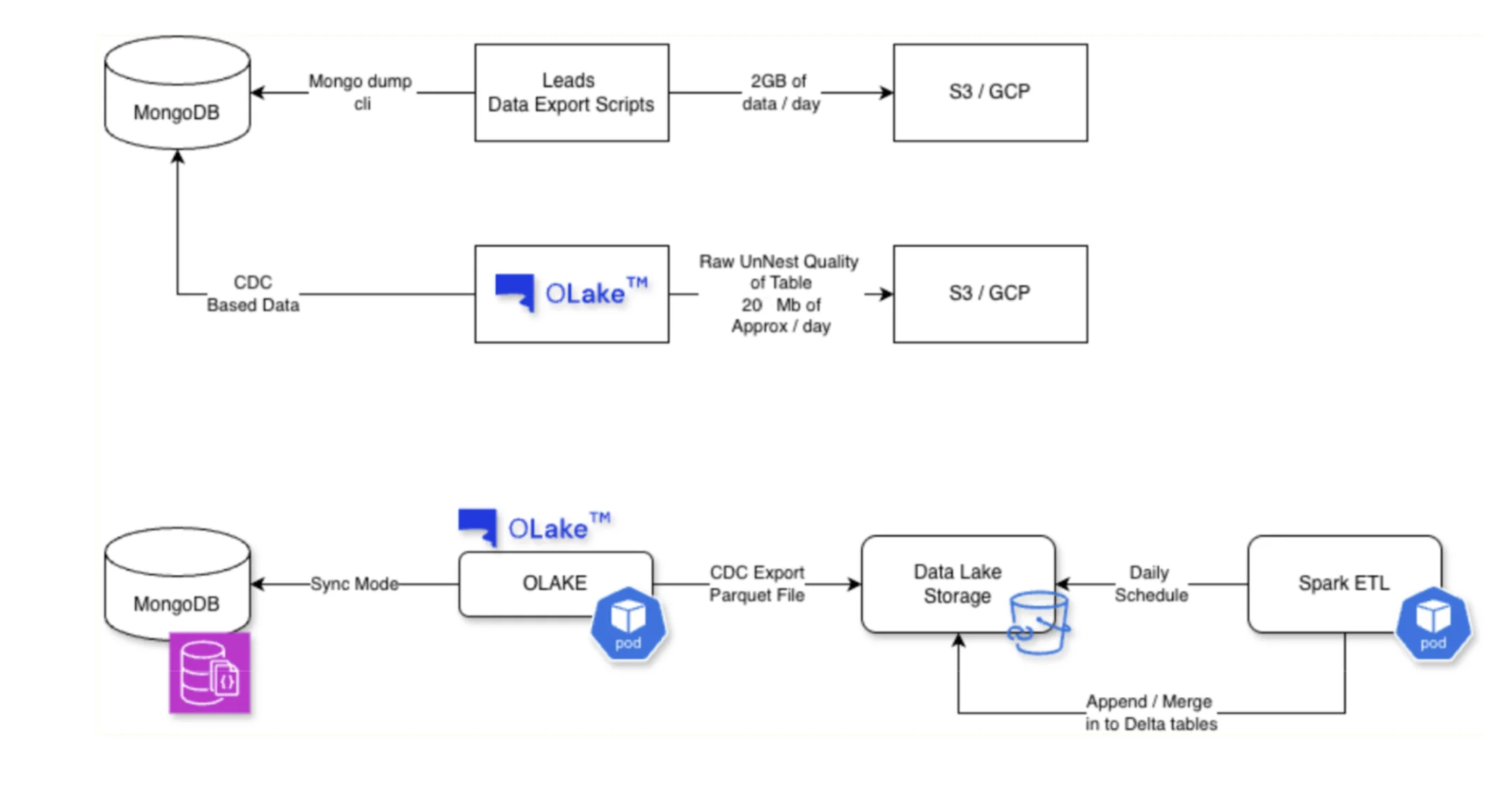
To manage load, the team limited daily ingestion to recent data and relied on periodic MongoDB dumps for large collections. Over time, this became increasingly heavy: daily dumps meant large transfers and unpredictable downstream costs.
"We were dumping close to 2 GB of Mongo data (Limited for the last 6 months only) every day, and eventually the pipeline just collapsed."
Prasanna
Associate Director - Data Strategy & Engineering, LendingKart
Beyond cost and performance, this approach introduced data gaps. Older records that changed outside the defined ingestion window were silently missed, and analysts began seeing mismatches in numbers — reducing confidence in downstream reporting and models.
It's also important to note: LendingKart's CDC stack wasn't broken. They continue to use Kafka and their CDC pipelines for transactional workflows (especially MySQL CDC) and event propagation. The gap showed up in a specific place: a few high-churn MongoDB collections like leads that span years, contain large/schema-flexible documents, and don't reliably expose an audit timestamp.
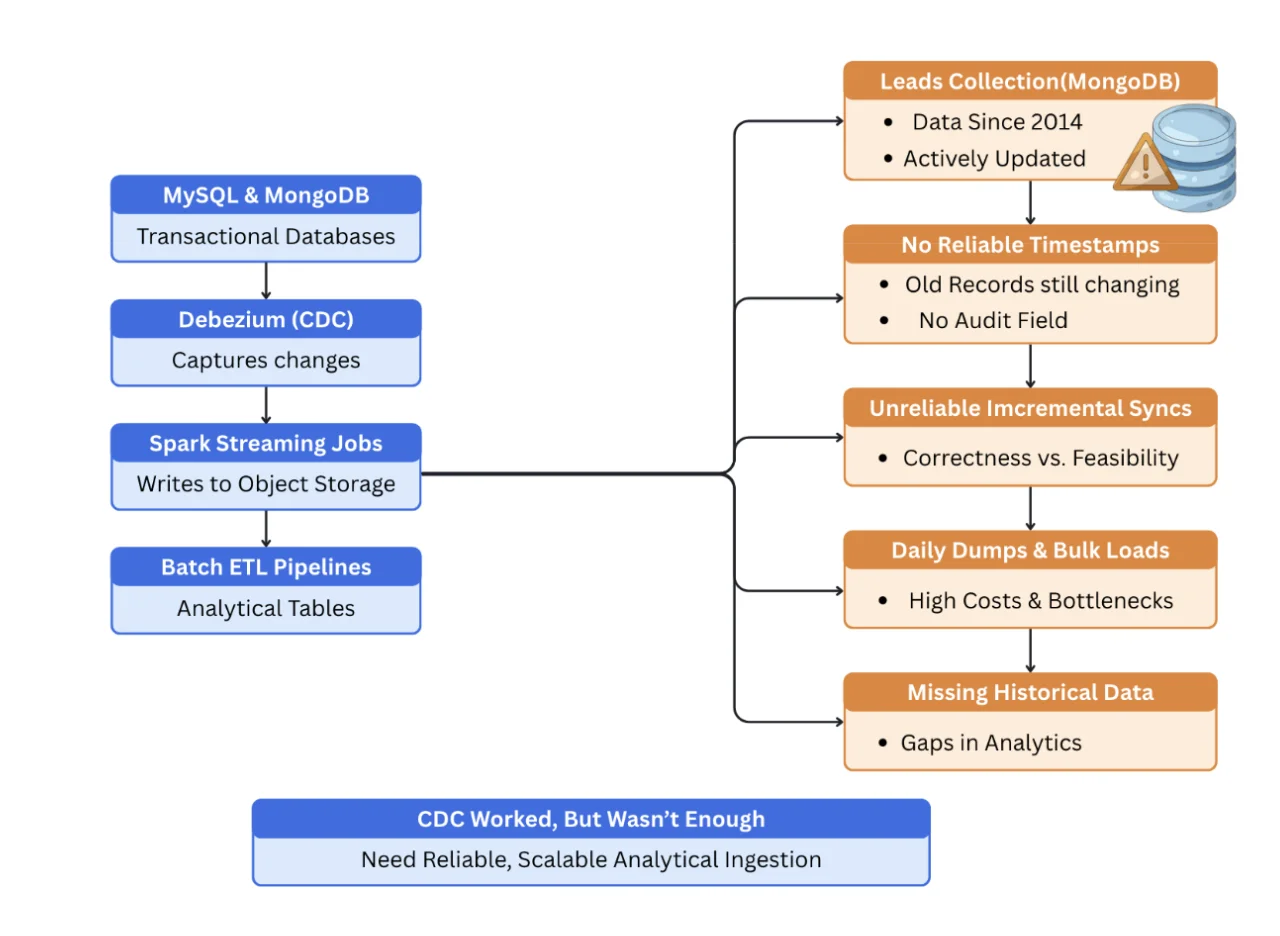
The team needed a solution that complemented their existing CDC systems, while reliably capturing updates across the full historical dataset — without reprocessing gigabytes every day.
Existing Pipelines Were Not Built for the Use Case of Database to Lakehouse Replication
LendingKart kept their existing MySQL CDC and event streaming pipelines as-is. But for a few MongoDB collections like leads, the combination of long history, large nested documents, and updates without a reliable audit timestamp made daily ingestion expensive and hard to keep correct — so they introduced OLake as a targeted lake-ingestion layer.
For these "blind spot" collections:
- Incremental ingestion for these collections became unreliable without an audit timestamp
- The fallback was reprocessing only the last ~6 months daily to keep load manageable
- Operational effort increased as volumes grew
- Updates to older records were missed, creating analytics blind spots
Discovering OLake
While digging into recurring CDC issues, the team began searching for better ways to ingest complex schemas at scale. It was through a community discussion that they first learned about OLake.
Initial experimentation was lightweight: the team spun up OLake locally using Docker Compose and the CLI, tested sync modes with a handful of documents, and validated that OLake could consistently extract delta changes from MongoDB documents that had previously caused pain.
"We spun up OLake locally with Docker Compose, tested the CLI, and did a POC on a single MongoDB collection."
Prasanna
Associate Director - Data Strategy & Engineering, LendingKart
They intentionally started with the most challenging collection first — not the easiest — to see if OLake could truly solve the real blind spots in their pipeline.
Those early validations showed promise, and LendingKart moved forward with a controlled, incremental adoption of OLake for problematic datasets.
Architecture with OLake
Instead of replacing Kafka or their existing CDC setup across the platform, LendingKart kept their current MySQL CDC and event streams as-is, and introduced OLake for a small set of large, high-churn MongoDB collections (for example, the leads collection) where running history + CDC reliably had become operationally heavy and costly.
In other words, OLake was adopted as a targeted MongoDB lake-ingestion layer—handling historical backfill and ongoing changes for the collections that were previously blind spots.
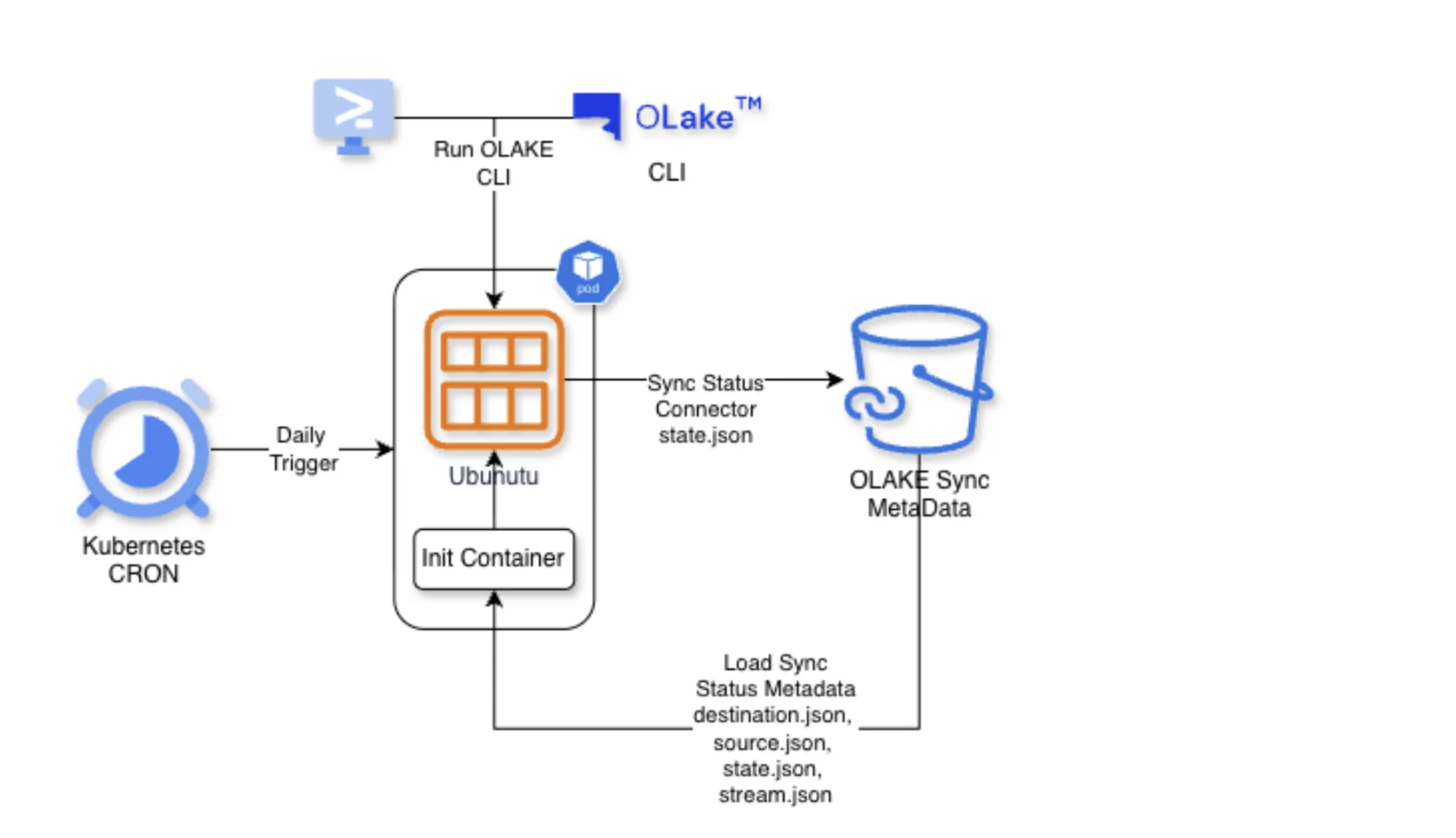
Key aspects of the OLake deployment:
- The flexible Open Source nature of OLake, help them run it as a Kubernetes cron job using the Docker-CLI
- Sync state and stream metadata are stored externally (in GCS) so incremental runs resume cleanly
- Each OLake job produces Parquet files for downstream analytics
- Spark ETL jobs then pick up Parquet and load into Delta tables (bronze/silver/gold)
The result is a stable, maintainable process that fits easily into LendingKart's existing data platform without adding unnecessary complexity.
"We run OLake as a Kubernetes cron with the CLI and custom scripts — and it's been rock solid. For the last 4-5 months, we have never looked back except for couple of feature requirement testing."
Prasanna
Associate Director - Data Strategy & Engineering, LendingKart
Below is the difference between their old architecture and new OLake based architecture.
Past Architecture
New Architecture with OLake
Results: Immediate and Measurable Impact
1. 100× Reduction in Ingestion Volume
One of the first and most visible outcomes was the dramatic drop in data movement for problematic collections.
"For the same collections, our daily data movement dropped from nearly 2 GB to under 20 MB."
Prasanna
Associate Director - Data Strategy & Engineering, LendingKart
This reduction came from OLake's efficient handling of delta changes and conversion to parquet directly from source.
2. Better Data Correctness and Reliability
More important than size reduction was correctness. With OLake, LendingKart can now reliably capture updates to historical records that were previously invisible or unreliable.
"The bigger win wasn't cost it was correctness: we can now capture updates across the full 11-year history, not just the last 6 months."
Prasanna
Associate Director - Data Strategy & Engineering, LendingKart
This improved predictability has increased confidence in analytical outputs and downstream decision systems.
3. Lower Compute Costs with Predictable Workloads
Smaller daily volumes and better-shaped Parquet files meant that Spark jobs run more efficiently, with less variance in timing and cost.
- Reduced Spark compute usage by ~3–5×
- More predictable job runtimes
- Lower operational overhead by ~60–70%
- Increased business impact by unlocking analytics on 10+ years of lead data (up from 6 months)
4. Incremental Adoption Without Disruption
OLake did not replace Debezium or Kafka.
Instead, it complemented them, solving a specific class of lake ingestion problems while allowing existing systems to continue operating as designed.
What's Next
LendingKart plans to:
- Expand OLake usage to additional MongoDB and MySQL backfills
- Evaluate OLake's Kafka ingestion for application event streams
- Increase sync frequency for fresher lake data
- Explore Apache Iceberg as they evaluate new query engines, including BigQuery
OLake is expected to play a central role in this future transition by acting as the lake-first ingestion layer.
Summary
By adopting OLake, LendingKart addressed a critical data reliability challenge without rearchitecting their entire platform.
OLake helped them:
- Reduce MongoDB ingestion volume by 100×
- Reliably capture updates across 11 years of data
- Lower Spark compute costs
- Improve confidence in analytical correctness
Most importantly, it gave the team a predictable, scalable foundation for evolving their lakehouse as their data platform continues to grow.
Note
Interested in replicating MongoDB to your lakehouse like LendingKart?
Check out our guide on how to set up MongoDB with Apache Iceberg.
If you're considering Delta Lake, see our comparison of Delta Lake vs Data Lake.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.