PhysicsWallah Evaluates MongoDB CDC Ingestion into a Lakehouse with Apache Iceberg and OLake


Background: MongoDB CDC at lakehouse scale
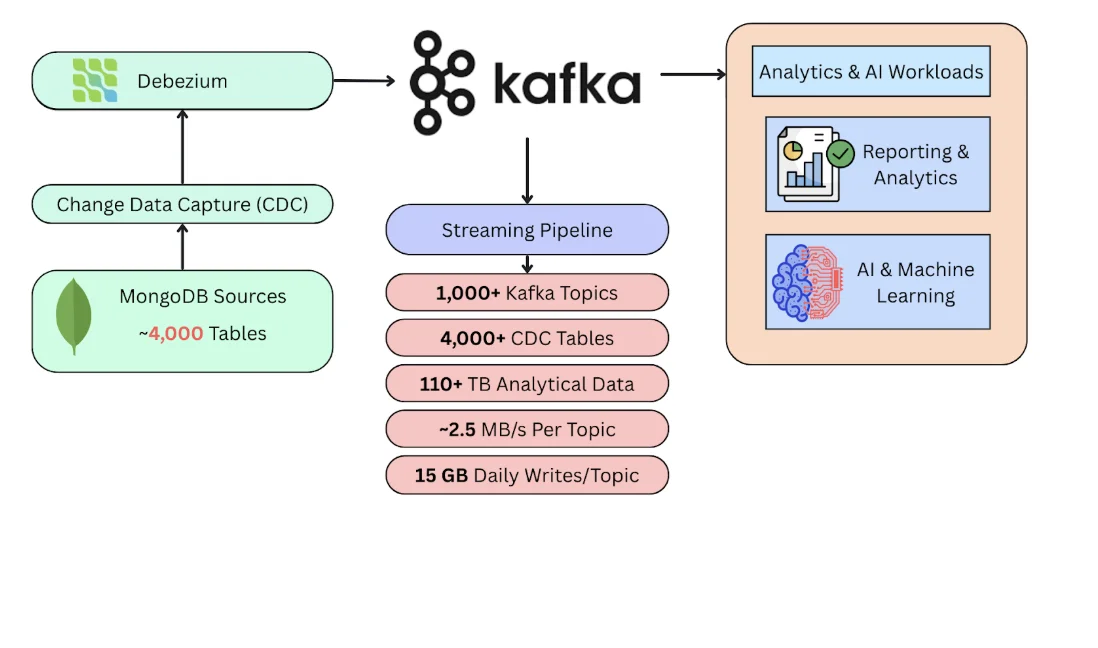
At PhysicsWallah, the Data Engineering team operates and evolves a large-scale lakehouse platform that powers analytics, reporting, and AI-driven use cases across the organization. A significant portion of our operational data originates from MongoDB, making reliable and scalable change data capture (CDC) ingestion a foundational requirement—especially when downstream consumers rely on consistent, queryable Iceberg tables and raw Parquet in the bronze layer.
Today, our CDC ecosystem spans (internal metrics shared for this customer story draft):
- 1,000+ Kafka topics
- 4,000+ CDC-backed analytical tables (including ~4,000 MongoDB-backed tables)
- 110+ TB of managed analytical data
- Average ingestion throughput of ~2.5 MB/s per topic
- Approximately 15 GB of daily writes per topic, translating into billions of events per day
As part of our platform evolution, we are evaluating alternatives to our existing Debezium + Kafka (Kafka Connect)–based CDC pipelines, particularly for MongoDB CDC sources where we currently operate at very large table and topic counts. Debezium's model—capturing MongoDB changes and emitting them as events into Kafka topics—is a proven pattern, but at our scale we continuously evaluate operational overhead and complexity.
Why we evaluated OLake for MongoDB Change Streams CDC into Apache Iceberg
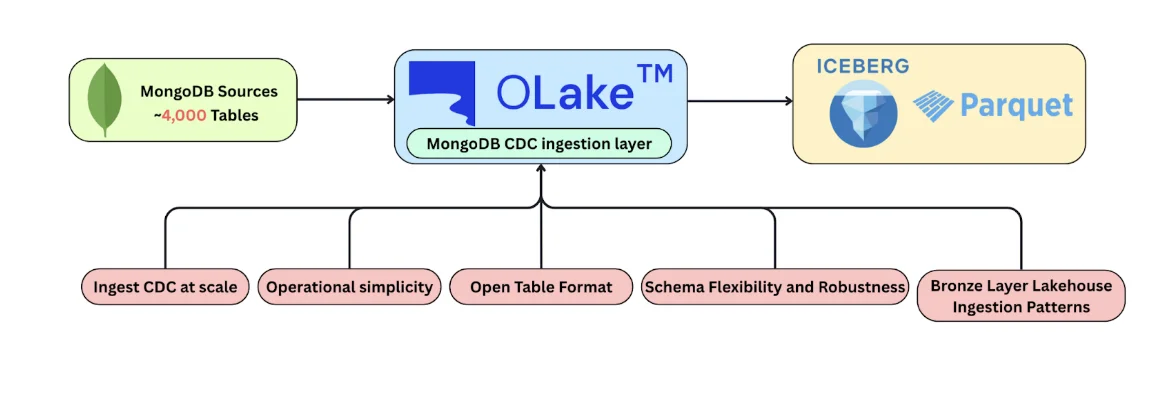
We initiated a proof-of-concept (POC) with OLake to assess its suitability as a MongoDB CDC ingestion layer into our lakehouse, which is built on Apache Iceberg and raw Parquet. OLake positions itself as an open-source data replication / ingestion tool that replicates data into open lakehouse formats like Apache Iceberg and Parquet, aiming to reduce infrastructure overhead compared to Kafka-heavy CDC stacks.
Our evaluation criteria focused on:
- Ability to ingest CDC from large numbers of MongoDB tables and collections
- Operational simplicity compared to traditional Debezium + Kafka pipelines (Kafka-centric CDC)
- Compatibility with open table formats such as Apache Iceberg and file formats such as Parquet
- Schema flexibility and robustness in the presence of evolving MongoDB documents (schema drift) and downstream schema evolution needs
- Alignment with modern bronze-layer lakehouse ingestion patterns (often described as the bronze layer in a medallion architecture)
POC observations: lakehouse-native CDC ingestion and schema evolution
During the POC, OLake demonstrated a clean and pragmatic approach to MongoDB CDC ingestion into our lakehouse stack:
- Source onboarding and configuration were notably simpler than Kafka-centric CDC stacks
- The ingestion model fit naturally into our existing lakehouse layering strategy (including bronze-layer landing patterns)
- Handling of heterogeneous MongoDB schemas required minimal manual intervention, which is important when upstream collections evolve over time (schema drift / schema evolution)
- The overall system felt lightweight and operationally efficient, which is a critical consideration at our scale
Even at the evaluation stage, OLake showed strong potential to reduce ingestion complexity while preserving the flexibility needed for downstream analytical and AI workloads on Iceberg tables. Apache Iceberg's positioning as an open table format—with capabilities such as schema evolution and time travel—makes Iceberg a natural target for CDC-fed lakehouse tables.
Early takeaways: Kafka-centric CDC vs open lakehouse architectures
While OLake is still under evaluation and not yet deployed in production, our early takeaways are:
- OLake appears well-suited for organizations managing thousands of MongoDB-backed tables
- The product philosophy aligns closely with open lakehouse architectures built around Apache Iceberg and Parquet
- It offers a compelling alternative to Kafka-heavy CDC pipelines (e.g., Debezium emitting MongoDB changes into Kafka topics) especially from an operational standpoint
Next steps: validating scale scenarios, backfills, and operational readiness
We are continuing to validate OLake across additional datasets, scale scenarios, and operational considerations as part of our POC—especially around end-to-end CDC correctness requirements that show up in most real-world CDC systems (snapshots, incremental ingestion, and recovery/resume semantics). For MongoDB CDC specifically, resumability and history retention are important considerations, given MongoDB's reliance on resume tokens and oplog history for change stream continuation.
"Based on our experience so far, OLake is a promising candidate for simplifying MongoDB CDC ingestion into a production-grade lakehouse environment at scale."
Utkarsh G. Srivastava
Software Development Engineer III, Data Engineering, PhysicsWallah
Optional FAQ add-on for SEO
What is MongoDB CDC (Change Data Capture)?
MongoDB CDC is commonly implemented using MongoDB Change Streams, which can be resumed using resume tokens (for example via resumeAfter or startAfter), assuming sufficient oplog history exists to locate the resume point.
Why ingest MongoDB CDC into Apache Iceberg tables?
Apache Iceberg is positioned as an open table format for analytic datasets and highlights features like schema evolution and time travel, which are frequently valuable when landing CDC into a lakehouse.
How do Kafka-centric CDC pipelines typically work for MongoDB?
A common approach is using Debezium's MongoDB connector to monitor MongoDB (replica sets/sharded clusters) and record document changes as events in Kafka topics.
What is the bronze layer in a lakehouse ingestion pattern?
In medallion architecture terminology, the bronze layer lands data "as-is" from source systems and often emphasizes quick CDC, historical archiving, and auditability/reprocessing.
Note
If you're interested in data architecture and want to experiment with Kafka for similar use cases, check out our blog on OLake with Kafka and Iceberg.
To get started with MongoDB CDC into Apache Iceberg, see our guide on how to set up MongoDB with Apache Iceberg.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.