Docker (CLI)
Docker CLI can be installed and executed using the official Docker images. Each supported source driver has a dedicated image available on the OLake DockerHub page.
Prerequisites
- Docker installed and running on the host system
- Internet access to pull Docker images
In the subsequent commands, replace [SOURCE-TYPE] with the value corresponding to the required driver.
| Driver Name | [SOURCE-TYPE] |
|---|---|
| Postgres | postgres |
| MySQL | mysql |
| Oracle | oracle |
| MongoDB | mongodb |
With the driver identified, the next step is configuring the source system.
Sources
Each source driver requires specific configuration. Detailed setup instructions can be found in the following guides:
What's Next : Once the source has been configured, the next step is to define the destination.
Destination
Destinations specify where ingested data will be written. OLake supports multiple destinations. The following guides provide setup of:
- Working with AWS S3
- Working with Iceberg Glue Catalog
- Working with Iceberg Hive Catalog
- Working with Iceberg JDBC Catalog
- Working with Iceberg REST Catalog
What's Next : Once both source and destination are configured, the next step is to discover available streams/tables.
Discover Command
-
To discover the available streams from the source, run the following command:
discover commanddocker run --pull=always \
-v "[PATH_OF_CONFIG_FOLDER]:/mnt/config" \
olakego/source-[SOURCE-TYPE]:latest \
discover \
--config /mnt/config/source.jsonRunning this command generates a streams.json file, which contains the list of available streams along with their metadata.
-
To compare the differences between two streams—specifically, an old stream and a new stream—run the following command:
discover commanddocker run --pull=always \
-v "[PATH_OF_CONFIG_FOLDER]:/mnt/config" \
olakego/source-[SOURCE-TYPE]:latest \
discover \
--streams /path/old_streams.json \
--difference /path/new_streams.jsonInternal testing commandThis command is primarily used internally for testing purposes to compare differences between old and new streams. It is not typically required for production use. However, if you want to check the differences between streams, you can use this command.
Running this command generates a
difference_streams.jsonfile containing the differences between the old and new streams.
Using a version specific image is recommended instead of using latest in the commands for production use case.
What's Next : Understanding the streams config file for stream/table level modifications
Streams Config
The streams.json file is organized into two main sections:
selected_streams: Lists the streams that have been chosen for processing. These are grouped by namespace.streams: Contains an array of stream definitions. Each stream holds details about its schema, supported synchronization modes, primary keys, and other metadata.
1. Selected Streams
The selected_streams section groups streams by their namespace. For example, the configuration might look like this:
"selected_streams": {
"my_db": [
{
"partition_regex": "/{dropoff_datetime, year}",
"stream_name": "table1",
"normalization": true,
"append_mode": false,
"filter": "UPDATED_AT >= \"08-JUN-25 07.19.23.690870000 AM\""
},
{
"partition_regex": "",
"stream_name": "table2",
"normalization": false,
"append_mode": false,
"filter": "city = \"London\""
}
]
}
Details about all the fields mentioned in selected streams
| Component | Type | Example Value | Description |
|---|---|---|---|
namespace | string | my_db | Groups streams that belong to a specific database or logical category |
stream_name | string | "table1", "table2" | Identifier for the stream. Must match the stream name defined in the Streams configurations. |
partition_regex | string | "/{dropoff_datetime, year}" | A pattern defining how to partition the data. To read more, refer the Partition Regex for S3 or Partition Regex for iceberg |
normalization | boolean | true | Converts top-level JSON fields into columns, while nested JSON objects are stored as string values. |
append_mode | boolean | false | Disables upserts in Iceberg when set to true. (In upsert mode dedupe happens via equality delete) |
filter | string | "UPDATED_AT >= \"08-JUN-25 07.19.23.690870000 AM\"" | Ensures that only data matching the specified condition is synced. |
2. Streams
The streams section is an array where each element is an object that defines a specific data stream. For example, one stream definition looks like this:
{
"stream": {
"name": "table1",
"namespace": "my_db",
"type_schema": {
"properties": {
"_id": {
"type": ["string"],
"destination_column_name":"_id"
},
"name": {
"type": ["string"],
"destination_column_name":"name"
},
"marks": {
"type": ["integer"],
"destination_column_name":"marks"
},
"updated_at": {
"type": ["timestamp"],
"destination_column_name":"updated_at"
},
...
}
},
"supported_sync_modes": ["full_refresh", "cdc", "incremental", "strict_cdc"],
"source_defined_primary_key": ["_id"],
"available_cursor_fields": ["_id", "name", "marks", "updated_at"],
"sync_mode": "incremental",
"cursor_field": "updated_at",
"destination_database": "prefix:my_db",
"destination_table": "table1"
}
}
2.1 Stream Configuration Elements
| Component | Example Value | Description & Possible Values |
|---|---|---|
name | "stream_8" | Unique identifier for the stream. Each stream must have a unique name. |
namespace | "olake_db" | The grouping or database name that the stream belongs to. |
type_schema | (JSON object with properties) | Defines the columns in streams or tables, including the destination column name. The source column name is normalized by replacing special characters and spaces with underscores (_) and is used as the final column name in the destination table. |
supported_sync_modes | ["full_refresh", "cdc", "incremental","strict_cdc"] | Lists the sync modes the stream supports. Includes "full_refresh", "cdc", "strict_cdc" and "incremental". To read more about sync modes read |
source_defined_primary_key | ["_id"] | Specifies the field(s) that is set as a primary key in the source. |
available_cursor_fields | ["_id", "name", "marks", "updated_at"] | Lists fields that can be used to track synchronization progress in incremental sync mode. |
sync_mode | "incremental" | Indicates the active sync mode. Possible values are defined in supported_sync_modes. |
cursor_field | "updated_at" | Defines the cursor field used to track incremental sync. To read more about incremental sync read this |
destination_database | "prefix:my_db" | Specifies the destination database name where data will be stored. By default, the driver name is used as the prefix, but you can override it using the --destination-database-prefix flag. The source namespace is always appended to the database name. All special characters and spaces are replaced with (_), and the database is automatically created if it doesn’t exist. |
destination_table | "table1" | Specifies the name of the destination table where the data will be stored. The table name is derived from the source stream name and normalized by replacing special characters and spaces with underscores (_). |
Whats's Next: Once the streams.json file is configured as required, sync can be initiated.
Sync
The Sync section describes how to start the sync process using the configuration files.It also explains how to run sync with a state file when operating in Incremental (Bookmark/cursor) or CDC mode.
Sync command
This command is executed when a sync needs to be run in Full Refresh mode or when running a sync for the first time (i.e., before a state file has been created).
docker run --pull=always \
-v "[PATH_OF_CONFIG_FOLDER]:/mnt/config" \
olakego/source-[SOURCE-TYPE]:latest \
sync \
--config /mnt/config/source.json \
--streams /mnt/config/streams.json \
--destination /mnt/config/destination.json
Sync with state command
When using Incremental (Bookmark/cursor) or CDC mode, the state gets saved, and this file is used to start the sync from last saved point.
docker run --pull=always \
-v "[PATH_OF_CONFIG_FOLDER]:/mnt/config" \
olakego/source-[SOURCE-TYPE]:latest \
sync \
--config /mnt/config/source.json \
--streams /mnt/config/streams.json \
--destination /mnt/config/destination.json \
--state /mnt/config/state.json
Whats's Next: Monitor sync progress and performance using the stats.json file.
Stats
The stats.json file is created as soon as the sync starts. The file looks like this:
{"Estimated Remaining Time": "1642.00","Memory": "2228 mb","Running Threads": 21,"Seconds Elapsed": "186.00","Speed": "76542.20 rps","Synced Records": 14236868}
| Componenet | Example Value | Description |
|---|---|---|
| Estimated Remaining Time | 1642.00 | A rough estimation in seconds, indicating when the sync is expected to complete |
| Memory | 2228 mb | Memory which is currently getting utilizied |
| Running Threads | 21 | Number of parallel threads actively syncing data |
| Seconds Elapsed | 186.00 | Time in seconds elapsed since the sync started |
| Speed | 76542.20 rps | How many rows per second are being synced in this sync. |
| Synced Records | 14236868 | Total number of records which have been synced since the sync started. |
The stats.json file remains available after sync completion.
What's Next: Similarly logs get saved for every command that is executed. And those can be reviewed for additional information.
Logs
During a sync, Olake automatically creates an olake.log file inside a folder named sync_<TIMESTAMP_IN_UTC> (for example: sync_2025-02-17_11-41-40).
This folder is created in the same directory as the configuration files.
- The olake.log file contains a complete record of all logs generated while the command is running.
- Console logs are displayed in real time with color formatting for easier identification.
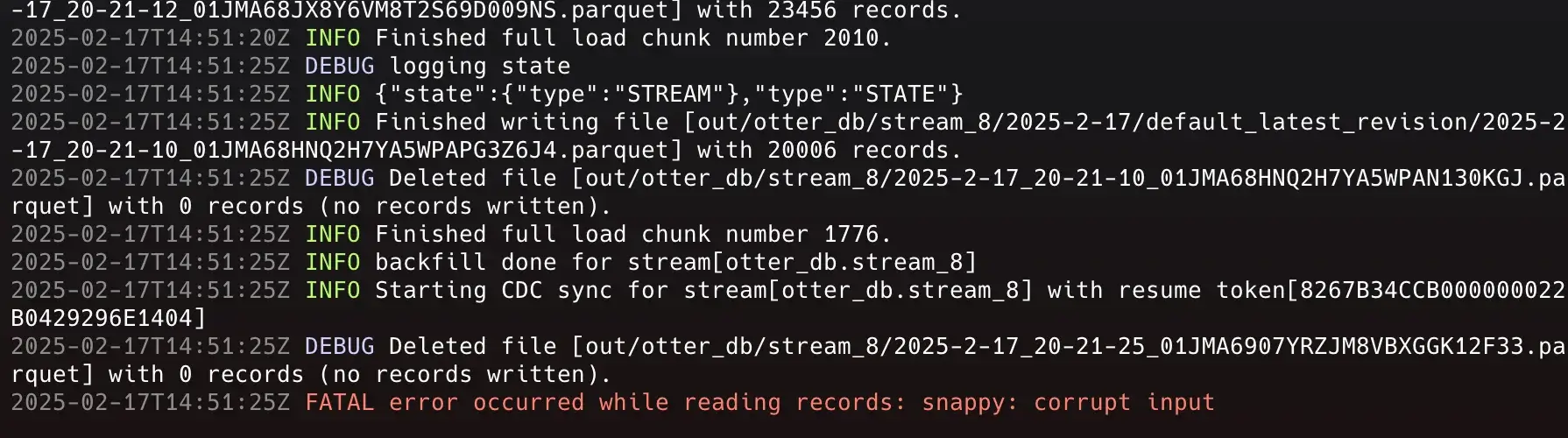
"debug": "\033[36m", // Cyan
"info": "\033[32m", // Green
"warn": "\033[33m", // Yellow
"error": "\033[31m", // Red
"fatal": "\033[31m", // Red
With this, the sync setup using the OLake CLI is complete, from configuring source and destination to reviewing key outputs such as stats and logs.