Source
A Source is the system from which OLake reads data. This could be a database (MongoDB, Postgres, MySQL, Oracle), basically a data service. When you create a source in OLake, you are telling the platform where the data should come from.
-
Active Source
A source becomes active once it is linked to at least one job. This means OLake is actively pulling data from this source and sending it to a destination. They are visible in the "Active Sources" section of the OLake UI.
-
Inactive Source
A source is inactive when it has been created in OLake but is not yet assigned to any job. It exists in the system, but no data is being read from it until a job is created. They are visible in the "Inactive Sources" section of the OLake UI.
-
Source Properties
1. SSH Configuration
OLake can connect to a database through an SSH tunnel instead of connecting directly.
Currently, SSH tunneling is supported for Postgres and MySQL.The following parameters can be configured to establish connection via SSH tunnel:
- For OLake UI
- For OLake CLI

Field Description Example Value SSH Config requiredDescribes how user want to connect to the SSH tunnel. No Tunnel
SSH Key Authentication
SSH Password AuthenticationHost requiredHost address of the SSH tunnel my-hostPort requiredPort number of the SSH tunnel 22Username requiredUsername for the SSH tunnel my-userPrivate Key ^ Private key used for SSH authentication. -----BEGIN OPENSSH PRIVATE KEY-----
my-private-key
-----END OPENSSH PRIVATE KEY-----Passphrase Passphrase to decrypt the private key. Leave blank if the key is not encrypted. my-passphrasePassword ^ Password for SSH authentication. my-password"ssh_config": {
"host": "my-tunnel-host",
"port": 22,
"username": "my-tunnel-user",
"password": "tunnel-password",
"private_key": "-----BEGIN OPENSSH PRIVATE KEY-----\nmy-private-key\n-----END OPENSSH PRIVATE KEY-----",
"passphrase": "my-passphrase"
}Field Description Type Example Value host requiredHost address of the SSH tunnel String "my-host"port requiredPort number of the SSH tunnel Integer 22username requiredUsername for the SSH tunnel String "my-user"private_key ^ Private key used for SSH authentication. String "-----BEGIN OPENSSH PRIVATE KEY-----\nmy-private-key\n-----END OPENSSH PRIVATE KEY-----"passphrase Passphrase to decrypt the private key. Leave blank if the key is not encrypted. String "my-passphrase"password ^ Password for SSH authentication. String "my-password"^ Only one among
private_keyorpasswordis requiredpassphraseis required only if you use an encryptedprivate_key.- When defining
private_keyin thesource.jsonfile, use\nto represent newlines within the single-line string.
Destination
A Destination is the system where OLake writes data after it has been extracted from a source. In OLake, destinations define where your data will be stored and in what format. Currently, OLake supports two types of destinations: Amazon S3 and Apache Iceberg.
-
Active Destination
A destination is active when it is assigned to at least one job. This means OLake is currently delivering data into this destination. They are visible in the "Active Destinations" section of the OLake UI.
-
Inactive Destination
A destination is inactive when it has been created in OLake but is not linked to any job. It is available for use but will not receive any data until a job is configured. They are visible in the "Inactive Destinations" section of the OLake UI.
Jobs
A Job is the pipeline or process in OLake that moves data from a source to a destination. A job defines what data is moved, how it is moved (full refresh, incremental, CDC), and where it is delivered. Jobs are the central element of OLake, as they connect sources and destinations.
-
Active Job
A job is active when it is running or scheduled to run. This means OLake is currently transferring data according to the job's configuration. Any newly created job will also appear on the "Active Jobs" section of the OLake UI.
-
Inactive Job
A job is inactive when it has been paused. No data transfer takes place until it is resumed, but all configurations and previous states are preserved. They are visible in the "Inactive Jobs" section of the OLake UI.
When a job is inactive, certain job-level features become unavailable:
- Sync Now - Cannot trigger immediate syncs
- Edit Streams - Stream configuration cannot be modified
- Clear Destination - Cannot clear the destination data
To use these features, resume the job to move it back to active status.
-
Saved Job
These jobs are saved configurations that can be used to create new job runs. A saved job when scheduled or run will appear under the Active Jobs tab. They are visible in the "Saved Jobs" section of the OLake UI.
-
Failed Job
A job is failed when OLake encounters an error during execution (such as network issues, schema conflicts, or permission problems). Failed jobs require troubleshooting to identify the reason that led to the failure of the job. They are visible in the "Failed Jobs" section of the OLake UI.
Streams
A Stream in OLake represents a unit of data (such as a table or collection) discovered from a source. This panel lets you choose which streams to sync, how the data is synced (i.e. you can choose from different sync modes), what schemas they use, and also allows the user to do partitioning on data before loading it into the destination.
Streams Properties
1. Normalization
Normalization in OLake is the transformation step that does Level-1 flattening of data in nested JSON format, mapping fields to proper columns, thus making data ready to be written into Iceberg/Parquet format tables.
- Detects schema evolution (adds, drops, type promotions) and writes according to Iceberg v2 spec.
- Flattens nested structures so records become query-friendly.
- Focuses on mapping source types to Iceberg/Parquet types.
For input as given below,
Normalization must be enabled at the schema configuration step per table or stream within the job.

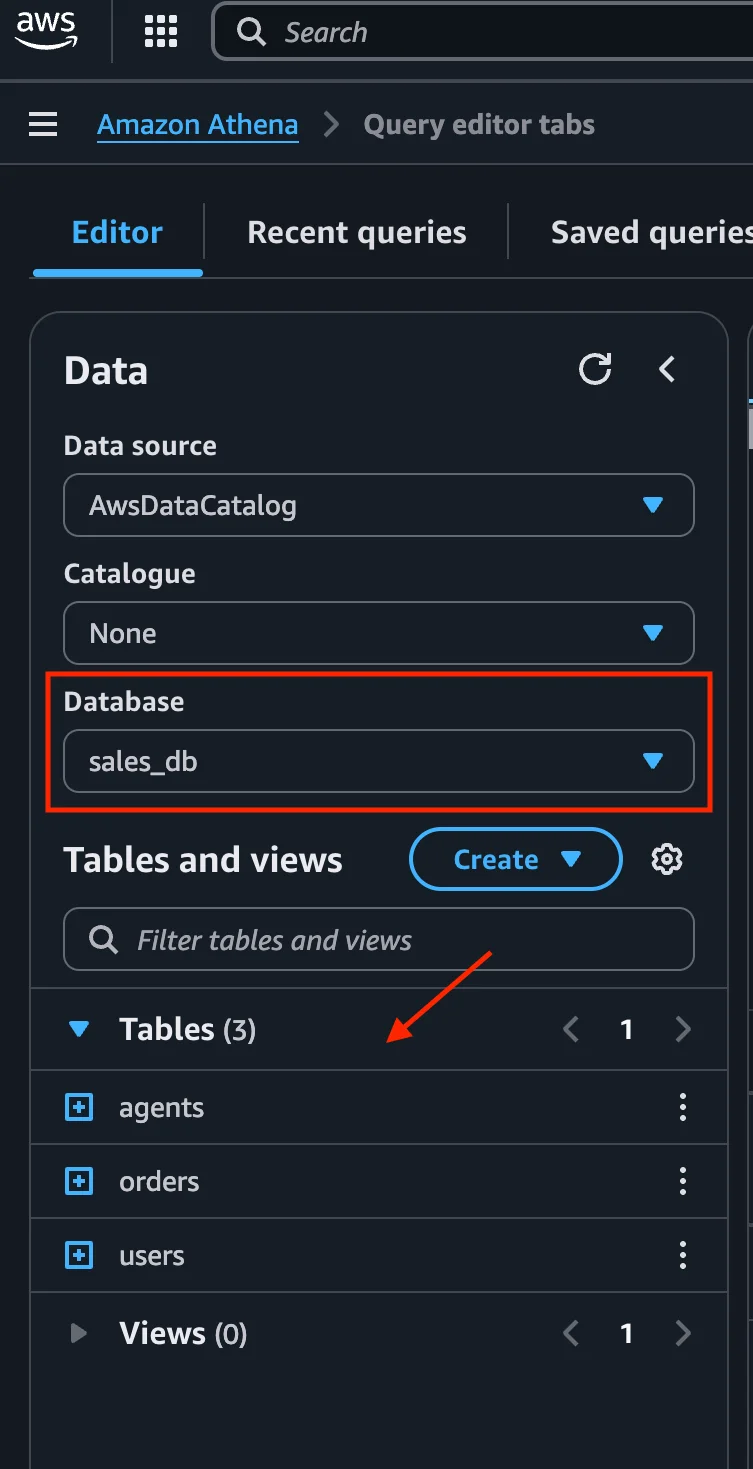
Queried using AWS Athena
Initial state: Sync done, when normalization is off. Focus on the data column.
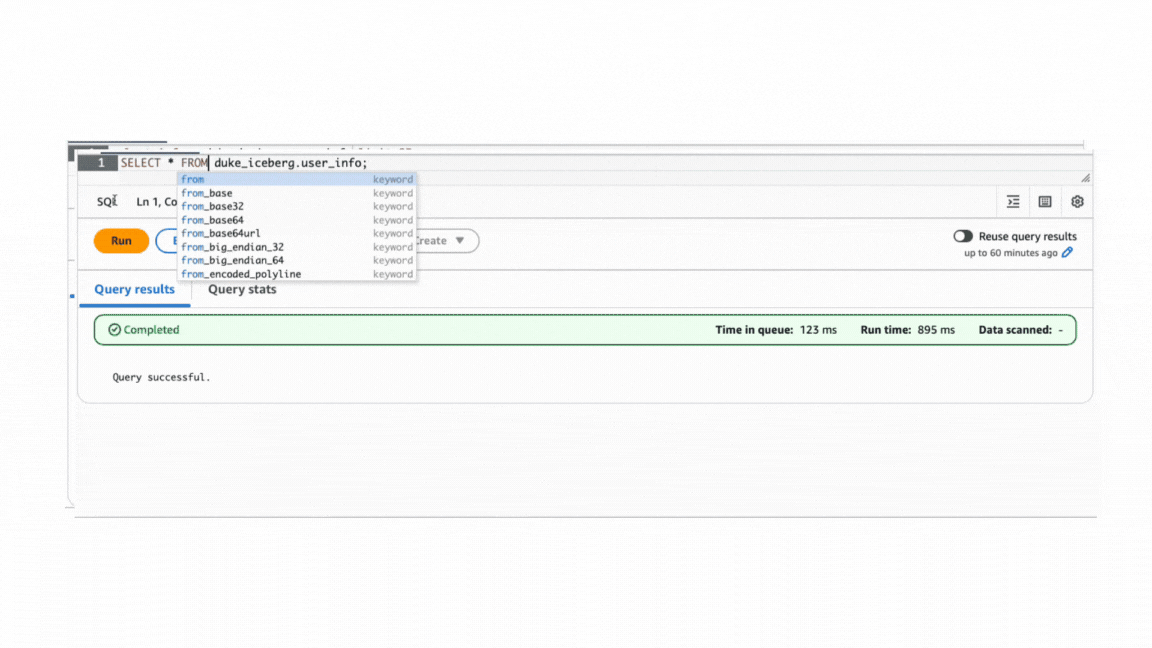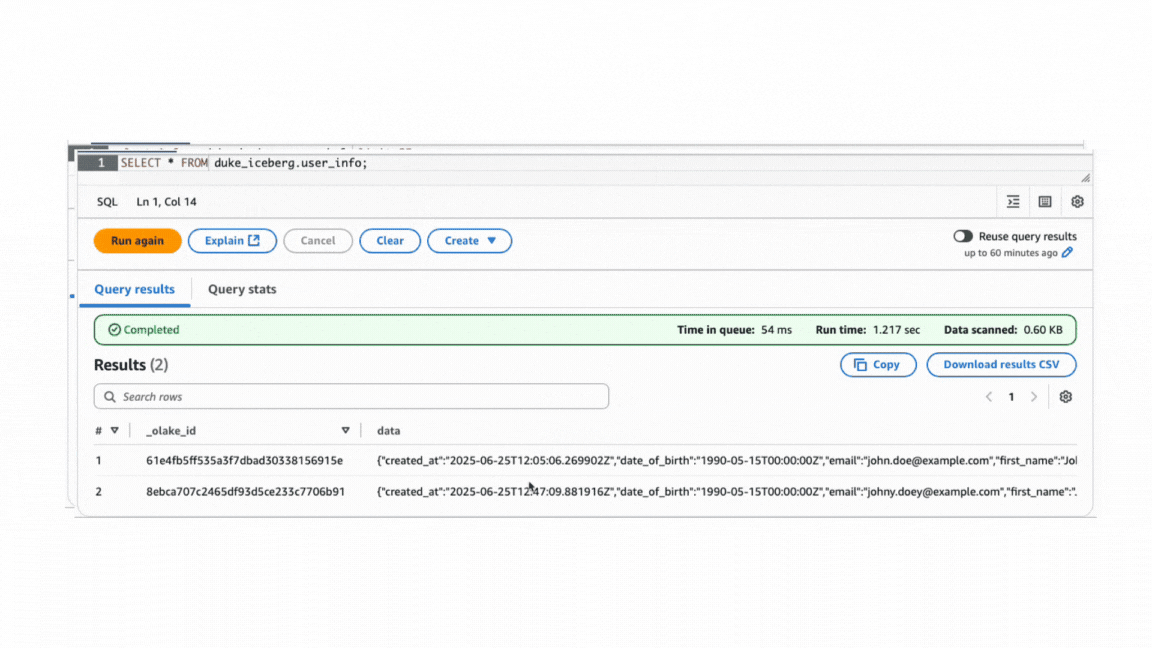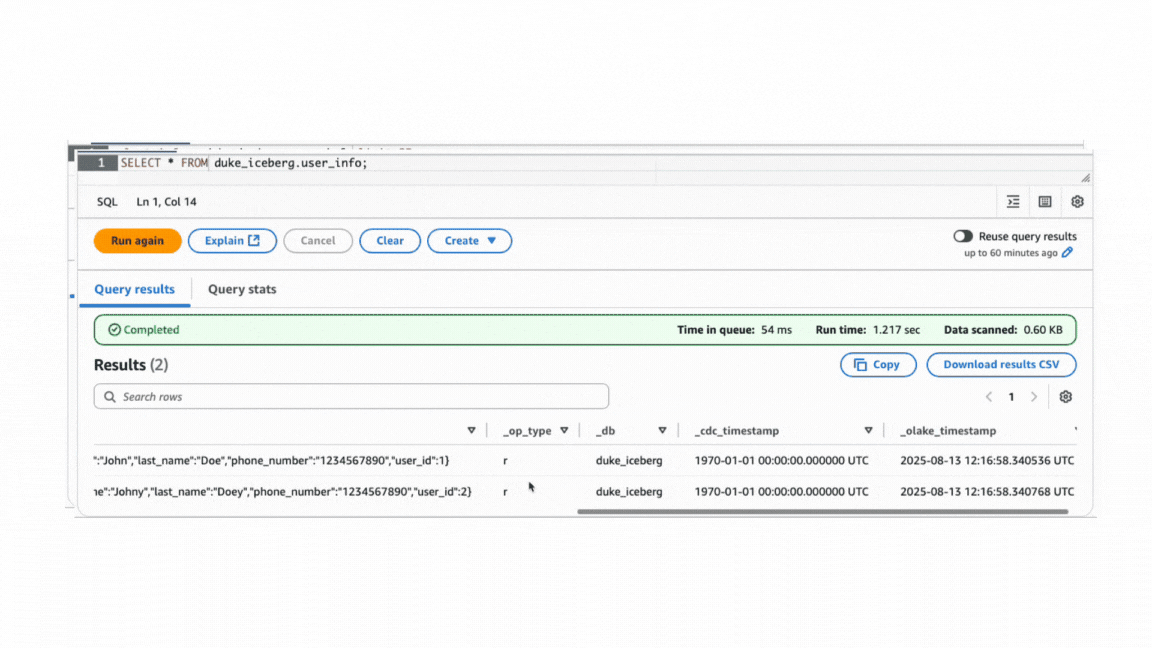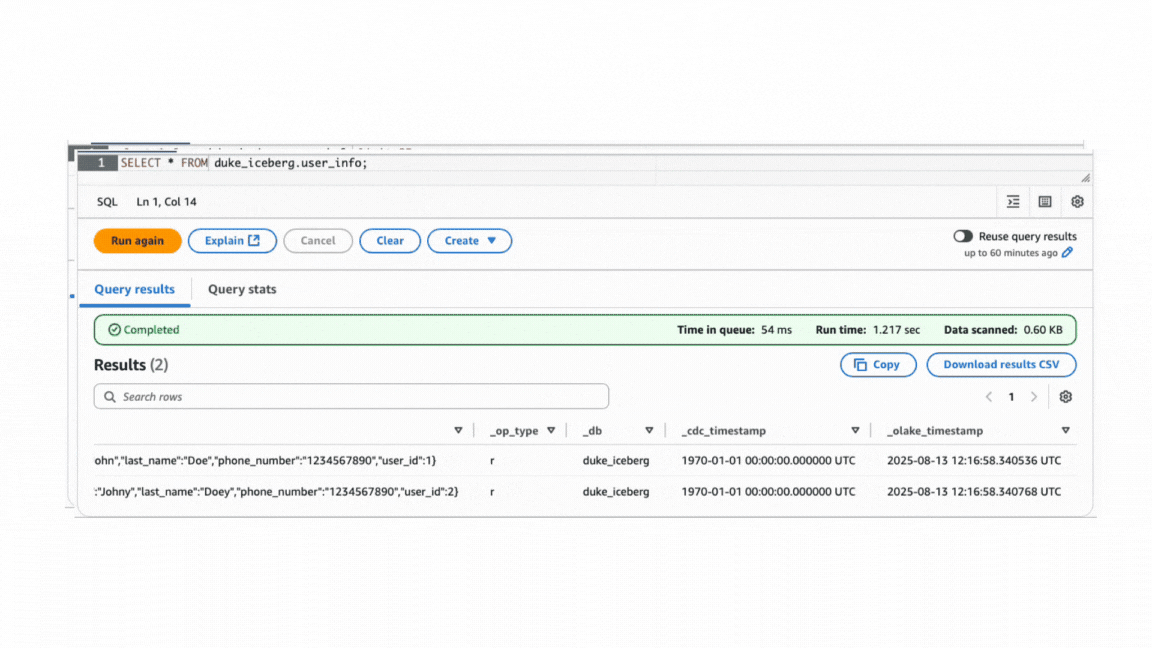
After state: Sync done, when normalization is on.
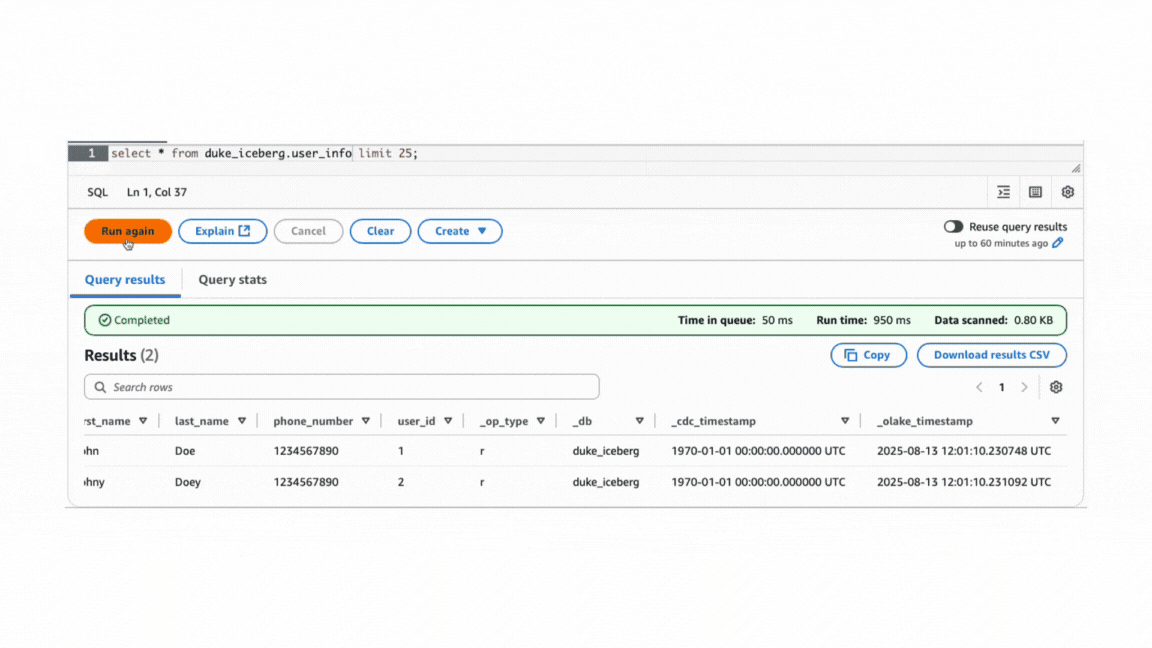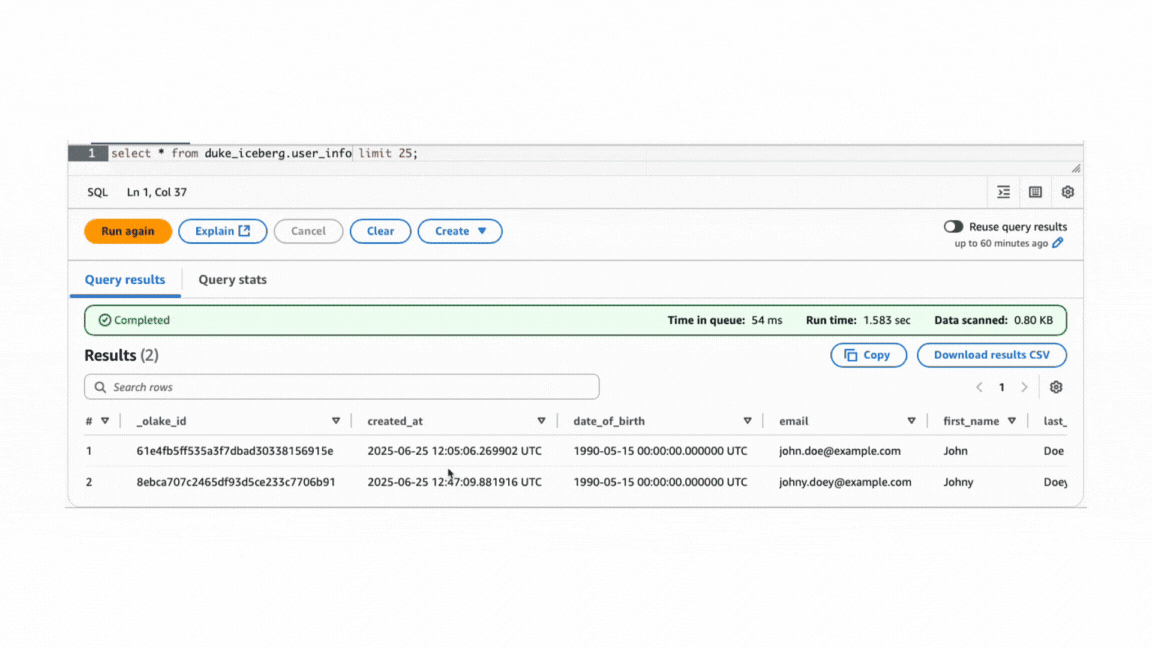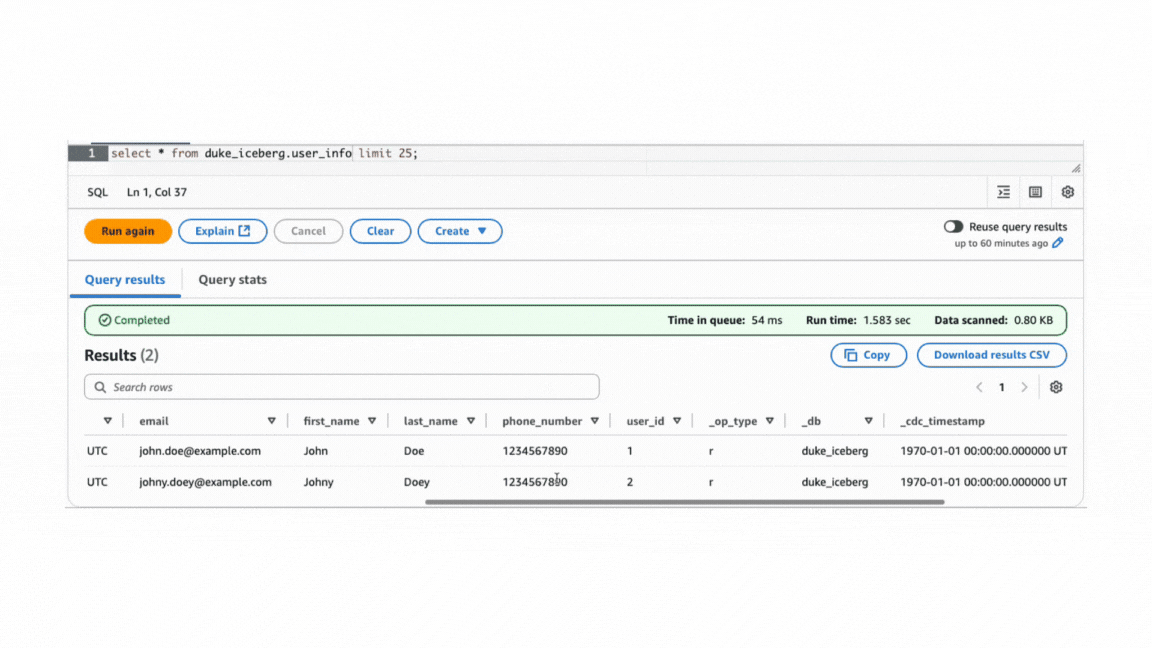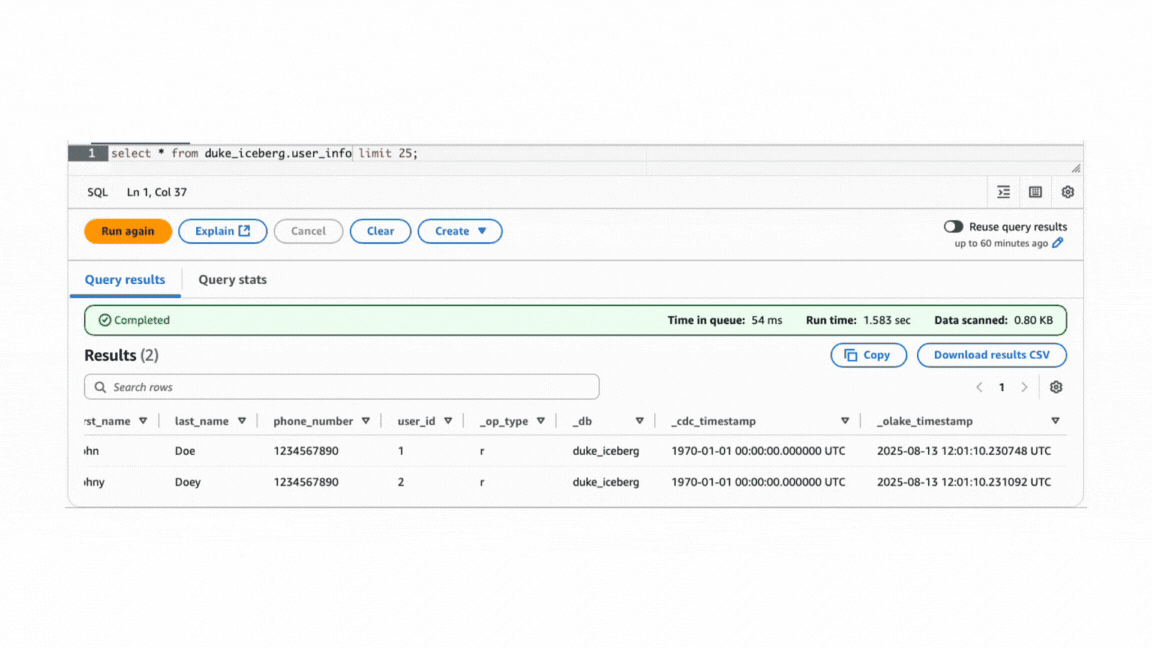
Advantages:
- Normalized streams can be queried with standard SQL—no unusual parsing or UDFs needed.
- Schema evolution (adds/drops/type promotions) is detected and written per Iceberg v2 spec, so downstream tables continue to operate without pipeline breaks as source schemas evolve.
- With transformation and normalization integrated into the pipeline (before the write) mean no extra post-processing jobs, so no extra Spark/DBT/Glue jobs later to "fix" the shape is required.
2. Sync Modes
Sync modes in Olake define the strategy used to replicate data from a source system to a destination. Each mode represents a different approach to data synchronization, with specific behaviours, guarantees, and performance characteristics.
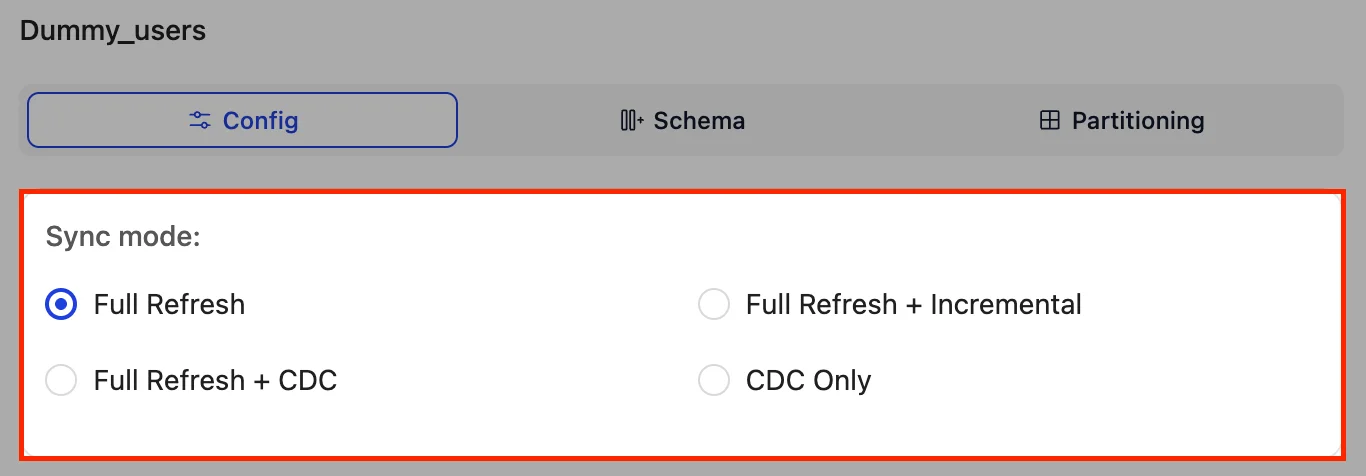
OLake supports 4 distinct sync modes:
-
Full Refresh:
Entire table is re-copied from source to destination in parallel chunks. Useful as a main sync mode or for initial loads. -
Full Refresh + CDC (Change Data Capture):
Real-time replication that first does a full-refresh, then streams changes (inserts, updates, deletes) in real-time. -
Full Refresh + Incremental:
A delta-sync strategy that only processes new or changed records since the last sync. Requires primary (mandatory) and secondary cursor (optional) fields for change detection. Similar to CDC sync, an initial full-refresh takes place in this as well.infoCursor fields are columns in the source table used to track the last synced records.
Olake allows setting up to two cursor fields:- Primary Cursor: This is the mandatory cursor field through which the changes in the records are captured and compared.
- Secondary Cursor: In case primary cursor's value is null, then the value of secondary cursor is considered if provided.
-
CDC Only:
A CDC variant that skips full-refresh entirely, focusing on processing only the new changes after CDC begins.
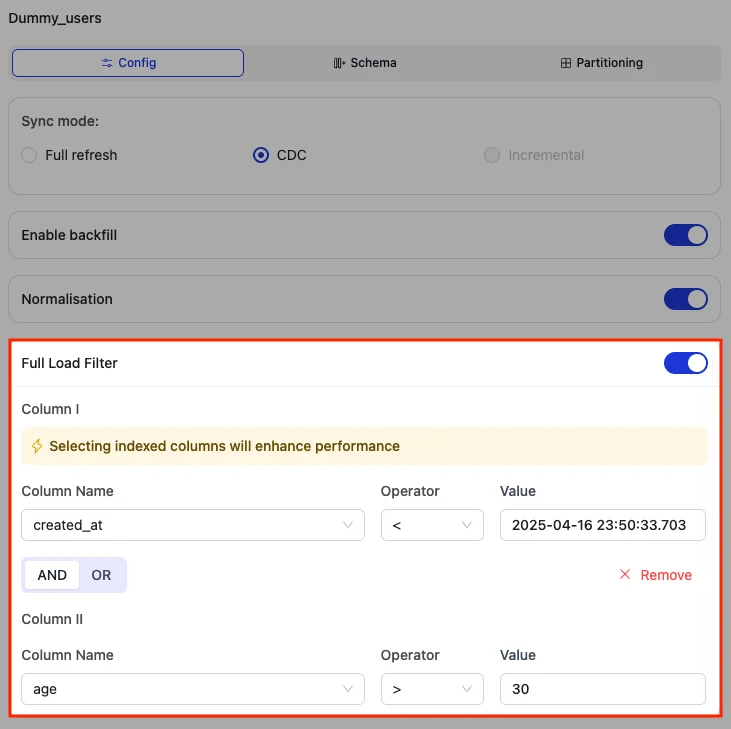
3. Data Filter
The data filter feature allows selective ingestion from source databases by applying SQL-style WHERE clauses or BSON-based conditions during ingestion.
- Ensures only selected data enters the pipeline, saving on transfer, storage, and processing.
- Supports combining up to two conditions with logical operators (AND/OR).
- Operators:
>,<,=,!=,>=,<= - Values can be
numbers,quoted strings/timestamps/ids (eg.created_at > \"2025-08-21 17:38:35.017\"), ornull.
Adoption of filter in drivers:
-
Postgres: During chunk processing, filters are applied alongside chunk conditions, ensuring only matching records are ingested—even with CTID-based chunking.
-
MySQL: During chunk processing, filters are applied within each chunk so only relevant rows are returned, even with limit-offset chunking.
-
MongoDB: During chunk processing, filters are enforced in the aggregation pipeline’s $match stage to ensure only compliant documents are processed.
-
Oracle: Similar to Postgres and MySQL, filters are applied within each chunk’s scan, guaranteeing only records satisfying conditions are ingested.
-
DB2: Similar to Postgres and MySQL, filters are applied within each chunk’s scan, guaranteeing only records satisfying conditions are ingested.
noteIf using DB2 as source, then filter for timestamp should be in the format of
2025-01-01 10:15:30.123456
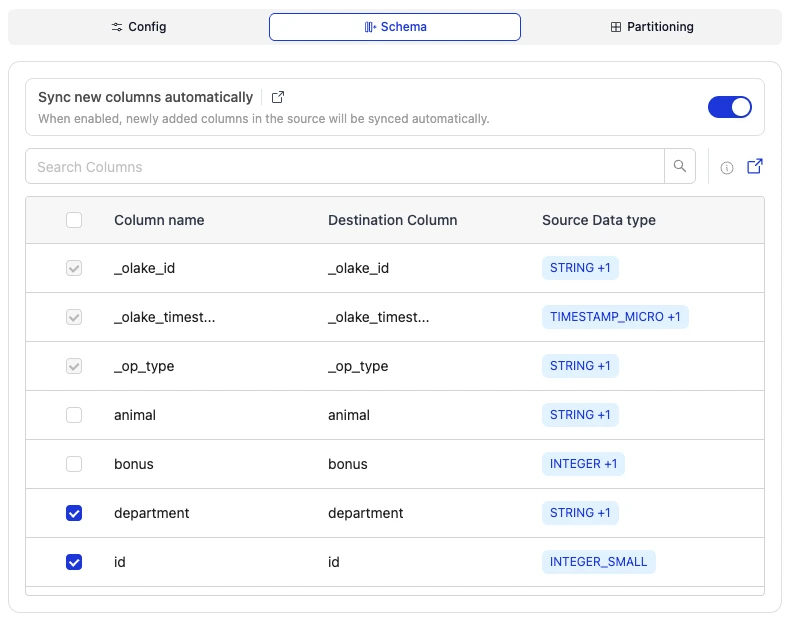
4. Schema
Schema is the structure of the tables (or streams) that OLake creates when it scans and discovers the source data. The ability to adjust a schema (add/remove columns, change types) without rewriting the entire table is called Schema Evolution. For more information, refer to Schema Evolution Feature.
After streams discovery is complete, OLake presents all available columns for each selected table. Schema management in OLake allows you to control which columns from your source tables are synced to the destination, enabling you to evolve your schema by selecting or deselecting columns as needed.
-
Column Selection:
- By default all the columns are selected, and users can unselect any column they do not want to sync to the destination.
- OLake-generated columns cannot be deselected. For more information about these columns, refer to OLake-Generated Columns.
- Any modifications to column selection will take effect starting from the next sync.
How Column Selection Impacts Existing Data- If a job previously had all columns selected and some columns are later deselected, the deselected columns will no longer sync new data in subsequent syncs. However, the historical data for those columns will remain in the destination.
- When new columns are added to the source and enabled in OLake, they will be synced starting from the next run. Previously ingested records in the destination will not be backfilled, and the new columns will remain null (or blank) for those older rows.
- If you want data for newly selected columns to be populated for all existing rows in the destination, you must run Clear Destination to clear all existing data in the destination and perform a full load again.
- Sync new columns automatically:
- By default, this toggle is enabled, ensuring that any new columns added to the source are automatically selected and synced in the next sync.
- When disabled, users must manually edit their streams and select the new columns which they want to be included in the sync.
Column selection and automatic sync of new columns are available in OLake v0.4.0 and OLake UI v0.3.1 or later.
Jobs created before these versions must be run on OLake v0.4.0+ and OLake UI v0.3.1+ to use these features; newly created jobs have them enabled by default.
5. Partitioning
Partitioning organizes data by grouping similar rows based on column values or transformations, enabling efficient query processing and data management. In simple terms, routes output by record values. The result is fewer data files scanned, less I/O, and faster queries.
Unlike traditional systems like Hive, Iceberg's approach uses "hidden partitioning," where partition details are managed in metadata rather than physical folders or explicit columns.
- Usage Format:
"partition_regex" = "/{field_name, transform}/{next_field, transform}"
Example:-- Partition Regex :
"/{created_at, day}"=> Partitioning done on thecreated_atfield, transformed using 'day'.
- Partition Regex :
For input as given below,
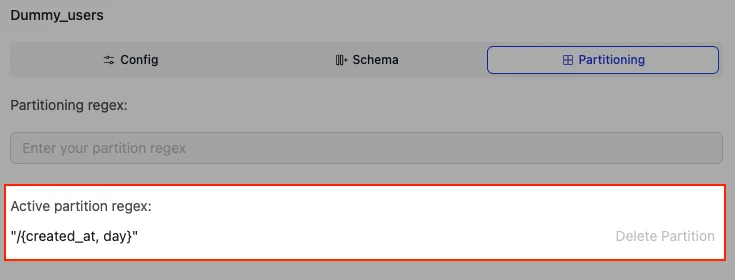
As seen below, partition on created_at field, tranformation using 'day' has been done.

Benefits of Partitioning:
- Faster Data Retrieval: Queries filtering on partitioned columns (e.g., time ranges) only scan relevant partitions, avoiding full table scans. For instance, in a logs table partitioned by date, a query for a specific day skips files from other dates, potentially speeding up results by orders of magnitude for large tables.
- Automatic Partition Pruning: In case of Iceberg, it derives partition filters from logical predicates without requiring users to add extra filters, unlike Hive where missing partition conditions lead to scanning all data. This can improve query times highly in real-world scenarios, such as financial data analysis. This feature is vital for streaming logs, e-commerce orders, or IoT telemetry etc.
- Efficient Handling of High-Volume Data: For high-cardinality fields (e.g., user IDs), transforms like bucketing distribute data evenly, preventing hotspots and enabling balanced query loads. Combined with sorting within partitions, this further optimizes scans by leveraging min/max statistics in file footers. For example, using
“/{user_id, bucket[512]}", will hash user_id and assign it to buckets ranging from 0 - 511. - Diverse Transforms: Supports flexible operations like identity, year/month/day/hour extraction, bucketing, and truncation, enabling tailored partitioning for various use cases (e.g., time-series data or categorical grouping). For example, bucketing high-cardinality keys like UUIDs into fixed groups improves write distribution and query efficiency.
- Schema Independence: Partitioning isn't tied to the table's schema, so you can evolve schemas (e.g., add columns) without breaking partitioning or queries.
- Hidden Partitioning: Writers don't need to manually compute or supply partition values; For example, Iceberg derives them from source columns (e.g., converting a timestamp to a date). This avoids silent errors like incorrect formats or time zones (common in Hive).
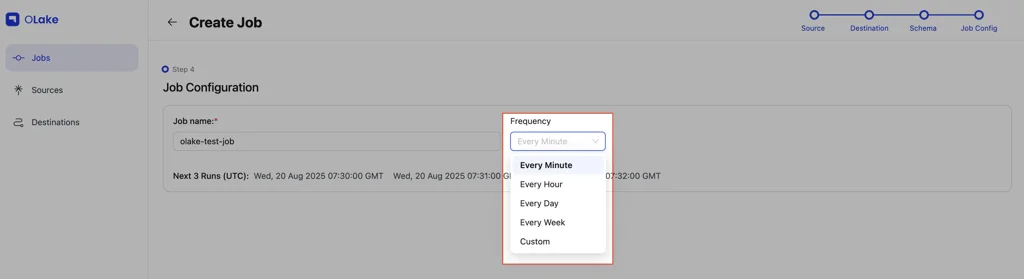
6. Job Configuration
The job configuration property refers to the options that defines job’s name, schedule, and execution in the Olake’s system.
User has to start with job creation, which will be followed with source configuration, then destination configuration, checking and enabling relevant streams from the schema for sync, and then finally in job configuration, job name and frequency has to be set.
- Frequency Options:
- Default options i.e every minute, hourly, daily, weekly
- Custom frequency: Specify a cron expression.
Guide to Cron Expression:
| * | * | * | * | * |
|---|---|---|---|---|
| minute (0-59) | hour (0-23) | day of the month (1-31) | month (1-12) | day of the week (0-6) |
Cron Examples:
* * * * *= Every minute0 * * * *= Every hour0 0 * * *= Every day at 12:00 AM0 0 * * FRI= At midnight only on Fridays0 0 1 * *= At midnight on the 1st day of each month
7. Table/Column Normalization & Destination Database Creation
Table/Column Normalization
Table and column names are normalized to ensure compatibility with tools like AWS Glue etc., which do not support uppercase letters or special characters. Specifically:
- Uppercase letters are converted to lowercase
- Spaces and special characters are replaced with underscores (_)
Example:
Customer Details-1 → customer_details_1
Destination Database
When a job is created and streams are discovered, a destination database is automatically created to store the synced tables.
The default destination database name is:
jobname_database_{$source_namespace$}
In case of sources like MySql, Oracle etc., it will be:
jobname_{$source_namespace} where source_namespace = database
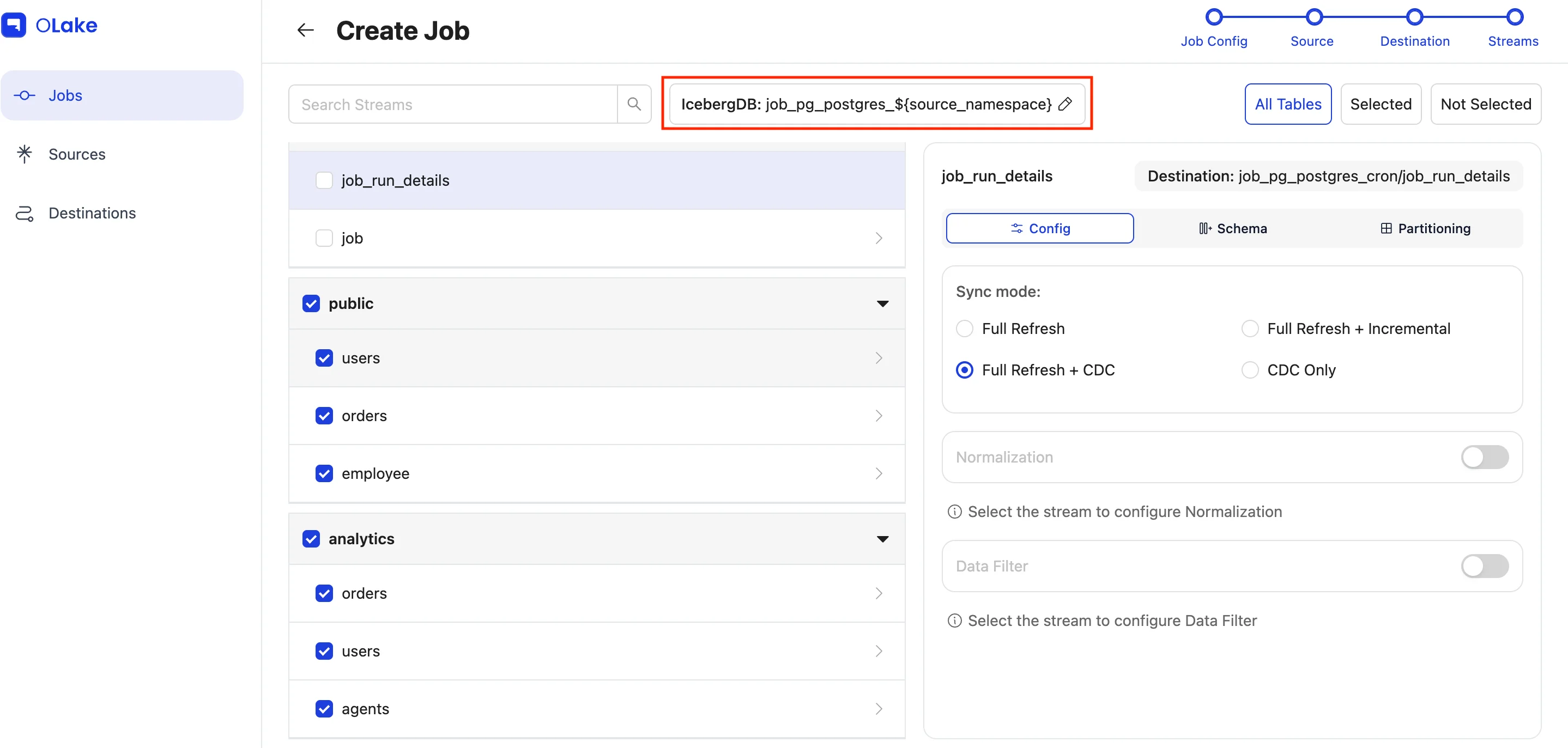
Users can rename/modify the database name by clicking the edit icon.
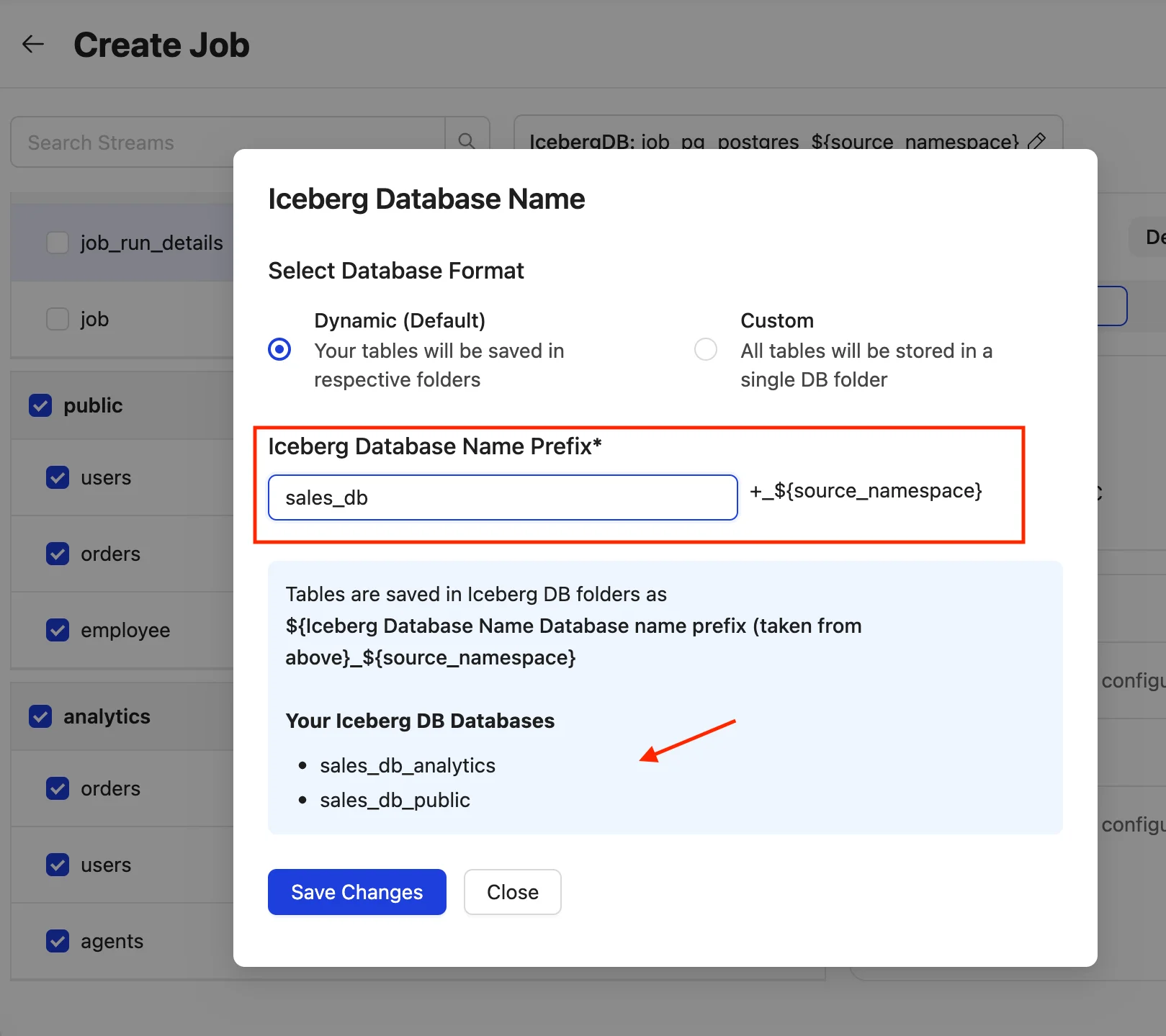
When editing the destination database, there are two options:
1. Dynamic (Default)
The database name prefix is set to jobname_database by default, followed by the dynamic source namespace. Users can customize the prefix to any value, which will then be applied across all namespaces. The resulting destination databases with the chosen prefix will be displayed in a list.
2. Custom
This option allows users to create a single, custom destination database for all streams, without including the namespace. As a result, all streams will share a single destination database name.
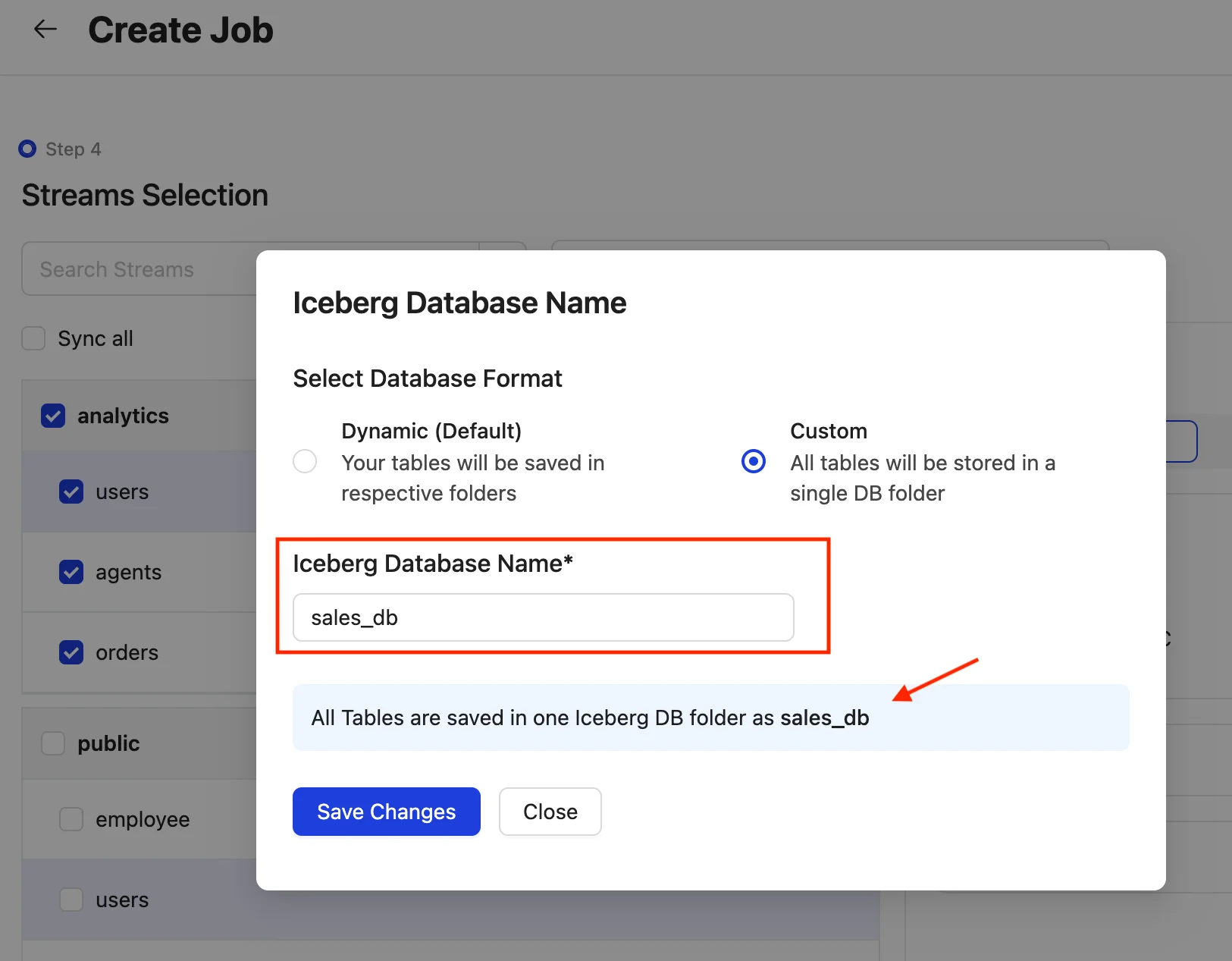
The database name will be updated here after saving the changes.

For each stream, the destination will be displayed within the stream’s configuration settings as:
destinationDB/normalised_tablename
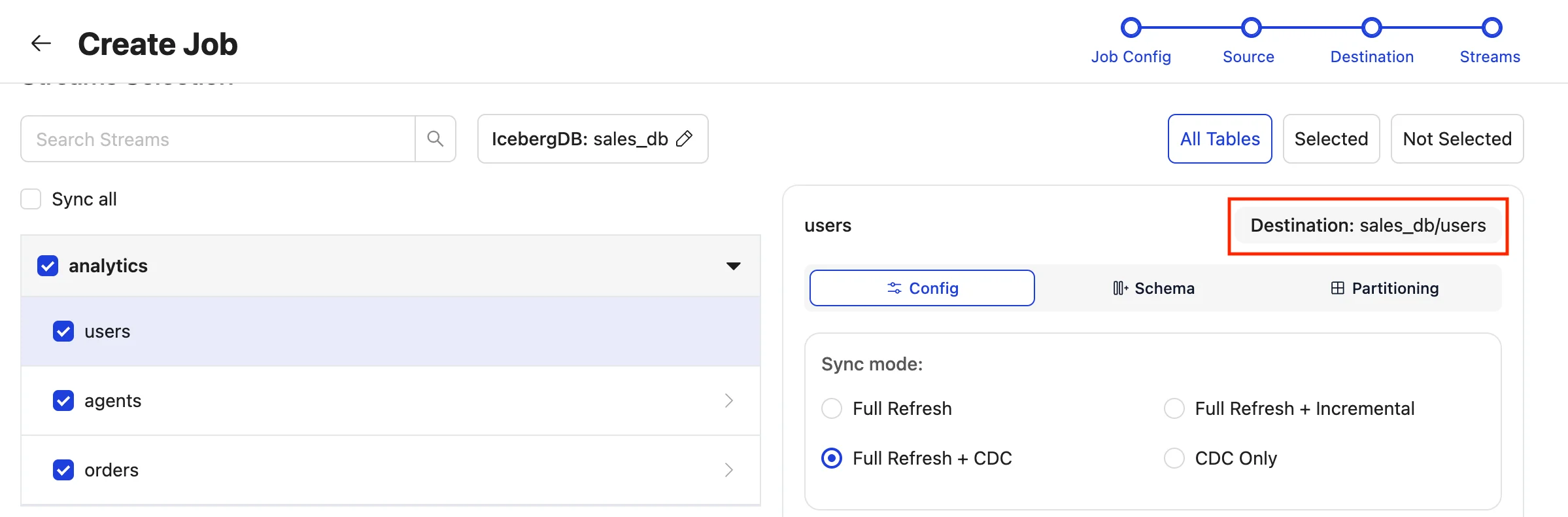
Once the sync is complete, the streams will be available in the Iceberg database at the destination, with the corresponding tables stored within it and can be queried by any query engine.
8. Modes to Ingest Data (Upsert vs Append)
These modes control how records are written to the destination for CDC and Incremental syncs. These modes can be configured in the Streams panel after discovery completes.
- By default, all streams are set to
All Upsert. - All streams can be switched to Append with the global selector
All Append, or overridden per table via the stream’s Ingestion Method.

Upsert
-
Ensures no duplicate records at the destination. For a given key, only the most recent row value is transferred and kept in the destination.
-
Example: Suppose a transaction with
id = 1changes over time:- T1: amount = 100, status = "created"
- T2: amount = 120, status = "closed" (latest)
With Upsert, the destination keeps only the latest version for
id = 1(T2: amount = 120, status = "closed"). Earlier versions are not kept as separate rows. -
How duplicates are avoided: A delete file is maintained that stores the
_olake_idof the previous version.- Before change (T1 ingested): destination has
id = 1with amount = 100, status = "created". - On change (T2 ingested via CDC): the existing
id = 1is referenced in the delete file; the new row forid = 1with amount = 120, status = "closed" is written to destination. - Result: destination retains only the latest row for
id = 1(T2), so no duplicates.
- Before change (T1 ingested): destination has
-
Recommended for transactional tables where the latest state is required (e.g., orders, customers, products).
Append
- Adds all incoming records to the destination without deduplicating. Every change event becomes a new row.
- Example: Using the same sequence for
id = 1, the destination will contain both T1 and T2 as separate rows. This preserves the change history, enabling analysis of how the record evolved over time. - Recommended for audit, logs, and event streams where full change history is desired.
- No delete files: All records are transferred to the destination as-is, even if duplicates occur.
Ingestion Mode

- Available in the Streams panel for each table/collection via the stream’s Ingestion Method control.
- Use it to override the global selection (
All UpsertorAll Append) for specific tables. - Example: Consider three tables— orders, customers, and logs in the
Streamsview. Keep the global mode asAll Upsertfor orders and customers to only observe the latest state, and set logs toAppendin itsIngestion Methodto retain full history; the global selector then showsCustomwhich indicates that we have a combination of append and upsert modes in the particular sync.
- What happens when newly discovered streams show up in the Streams panel?
- If all tables are Upsert (global
All Upsert), new tables default to Upsert. - If all tables are Append (global
All Append), new tables default to Append. - If the selection is
Custom(mix of Append and Upsert), new tables default to Upsert. To change this for any table, adjust the per-table Ingestion Method in the Streams section or apply a global selection before running.
- If all tables are Upsert (global
- Full Refresh is always Append. The Append/Upsert choice applies to CDC and Incremental phases.
OLake-Generated Columns
When OLake replicates data from source (like PostgreSQL, MySQL, Oracle or MongoDB) to destination formats (Apache Iceberg, Parquet), it automatically adds several metadata columns to track the lifecycle and processing history of each record. These columns help users understand how and when each row was captured and written to the destination.
OLake adds these metadata columns to every destination table: _op_type, _olake_id, _olake_timestamp, and _cdc_timestamp.
1. Operation Types (_op_type):
- Read/Snapshot (
r) -- Appears during initial full table loads (snapshots) from the source database.
- Example: When you first sync a table i.e. full refresh, all existing rows get
_op_type = 'r'.
- Create/Insert (
c) -- Generated during CDC, when new records are inserted into the source database.
- Example: After initial sync, inserting a new record creates a row with
_op_type = 'c'.
- Update (
u) -- Created when existing records are modified in the source database.
- Example: Updating a column value from the table generates a new row with
_op_type = 'u'.
- Delete (
d) -- Generated when records are deleted from the source database.
- When a record is deleted, primary key column and OLake-generated columns retain their values for tracking, while all other columns are set to either
Noneor they appear blank. - Example: Deleting a record from the table creates a tombstone row with
_op_type = 'd'.
2. Timestamps:
_olake_timestamp-- Captures the exact time when OLake processed and wrote the record to the destination.
- Useful for tracking when data was ingested into the data lake and for debugging sync latency and understanding processing order.
_cdc_timestamp-- Reflects the actual time when the change occurred in the source database.
- Present only when using Update Method (during Source Configuration) as
CDC. - Whenever a full refresh is performed, snapshot records
(_op_type = 'r')will have the_cdc_timestampset to the epoch time (1970-01-01) indicating that it is not a CDC record. Even in (Full Refresh+ CDC) mode, the very first sync run starts with a full refresh — in this case too, you may see (1970-01-01) timestamps. - For CDC records
(_op_type = 'c', 'u', 'd'), it provides the precise timestamp of when the insert, update, or delete happened in the source.
3. Record Identification (_olake_id):
OLake assigns a unique, deterministic identifier to every record as it is processed. The identifier is designed primarily for deduplication and internal ordering/tracking.
How it is generated:
- Single primary key present in the source table -
_olake_idequals the record’s primary key value and duplicates on the key will be detected.- Example: If the primary key is
idwith value 123, then_olake_idwill be 123.
- Composite primary key present in the source table -
_olake_idis a stable hash of all primary key columns for the record. Hence ensures that duplicates on the key will be detected.- Example: If the composite primary key is
(order_id, product_id)with values (456, 789), then_olake_idwill be a hash of (456, 789).
- With no primary key in the source table -
_olake_idequals the hash of all columns of the record. But in this situation, deduplication cannot be guaranteed as two different records could have the same hash value.- Example: If a record has columns
(name, age, city)with values (Alice, 30, NY), then_olake_idwill be hash of (Alice, 30, NY).
4. CDC Metadata Columns
OLake also writes driver-specific CDC ordering metadata columns. These fields capture the exact log position and ordering information from each source system’s native CDC mechanism and is supported for MongoDB, Postgres, MySQL and MSSQL drivers.
These columns are especially useful in scenarios where multiple changes happen within the same transaction (and thus share a single _cdc_timestamp), because they provide a stable, log-based key (for example, binlog position or LSN) that downstream systems can use to order events exactly as they occurred in the source.
MongoDB
- Column:
_cdc_resume_token_cdc_resume_tokenstores the MongoDB Change Streams resume token that identifies the exact position in the oplog where this change event was captured.- Example:
_cdc_resume_token:"82698C3243000000022B0429296E1404"
MySQL
- Columns:
_cdc_binlog_file_name,_cdc_binlog_file_pos- Together, these columns identify the exact location in MySQL's binary log where the change event was read.
_cdc_binlog_file_namespecifies which binlog file, and_cdc_binlog_file_posindicates the byte position within that file. - Example:
_cdc_binlog_file_name = "mysql-bin.000003",_cdc_binlog_file_pos = 1027
- Together, these columns identify the exact location in MySQL's binary log where the change event was read.
Postgres
- Column:
_cdc_lsn_cdc_lsnstores the Write-Ahead Log (WAL) Log Sequence Number that represents the precise position in Postgres's transaction log where this change was recorded. LSN values are monotonically increasing and can be used to order events in the exact sequence they were applied by Postgres.- Example:
_cdc_lsn = "16/B374D848"
MSSQL
- Columns:
_cdc_start_lsn,_cdc_seqval_cdc_start_lsnindicates the starting Log Sequence Number for the change row in SQL Server's CDC change table, while_cdc_seqvalis a sequence value that orders multiple changes that share the same LSN. Together, they provide a stable ordering key that matches SQL Server's internal CDC ordering.- Example:
_cdc_start_lsn = "000000bb000055d00003",_cdc_seqval = "000000bb000055d00002"
This feature is available starting from v0.3.16.
For jobs created before this feature was released, these columns are always present for Parquet-on-S3 destinations, but for Iceberg they appear only when Normalization was turned on and will not be present for older jobs where Iceberg Normalization was off.