Blogs on Apache Iceberg
Explore IcebergQuery Engines
Discover comprehensive guides for Apache Spark, Trino, Flink, DuckDB, and more. Compare features, capabilities, and find the perfect engine for your data workloads.

TPC-H Databricks vs Apache Iceberg - (OLake + AWS Glue + EMR)
A detailed TPC-H benchmarking study comparing Iceberg and Databricks to determine which delivers better performance and cost efficiency.

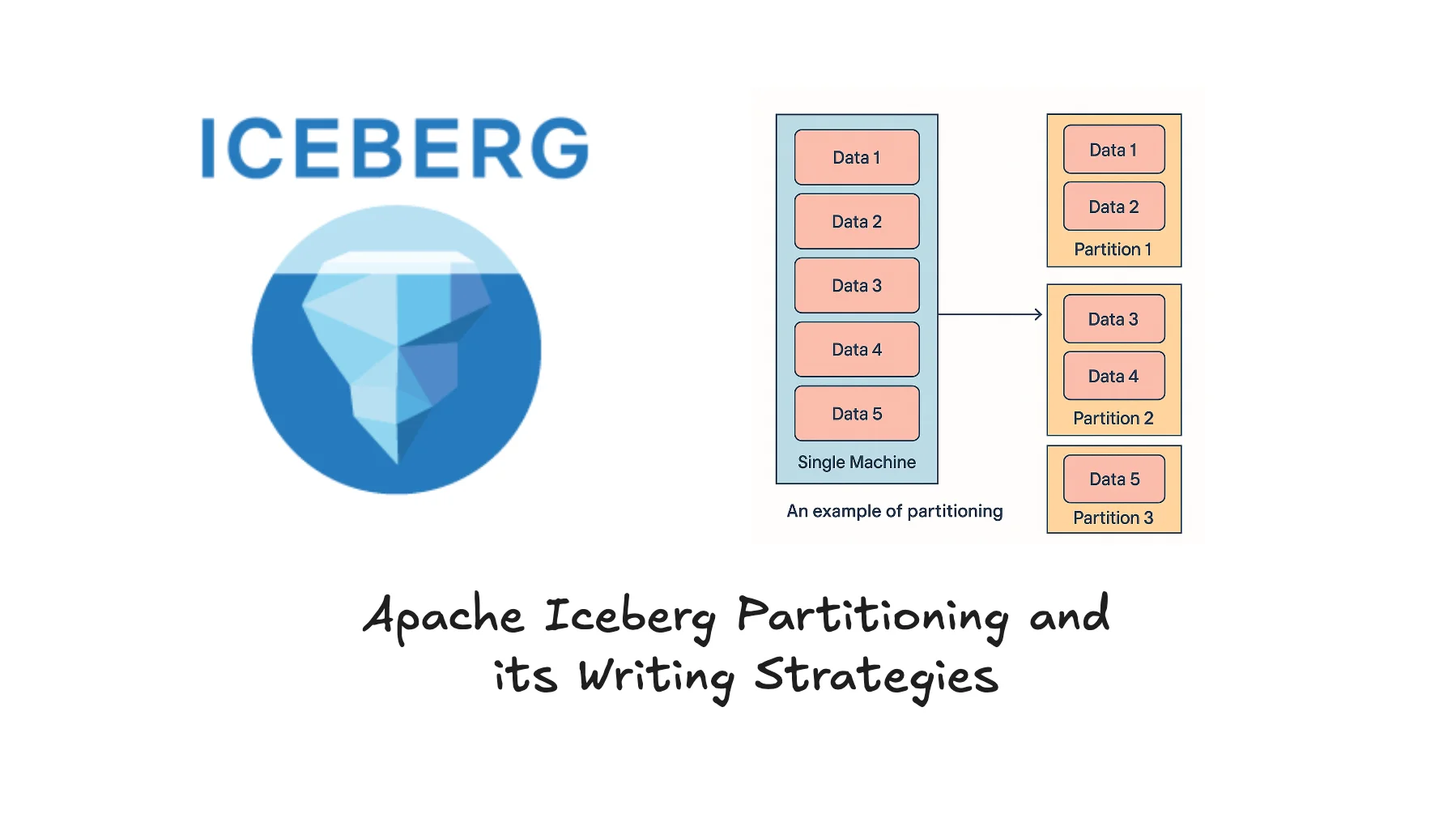
All about Iceberg Partitioning and Partitioning Writing Strategies
Ever wondered how partitioning in big table formats like Apache Iceberg works out? And what partitioned writing strategies Iceberg can assist...


OLake + Glue + Snowflake - A Deep Dive into Modern Data Partitioning
OLake lets you quickly go from full data snapshots to near real-time updates. It handles large amounts of data fast, works with changing data structures...


Iceberg Partitioning vs. Hive Partitioning
This blog presents an in-depth examination of modern data partitioning techniques, with a strong focus on the transition from Apache Hive's explicit, folder-based approach to Apache Iceberg's innovative metadata-driven...


OLake for Simple Iceberg Ingestion using Glue Catalog, Athena for Query
This is where the combination of OLake, Apache Iceberg, AWS Glue Data Catalog, and Amazon Athena provides a powerful, simple, and serverless solution...
OLake for Simple Iceberg Ingestion using Glue Catalog, Trino for Query
This is where the combination of OLake, Apache Iceberg, AWS Glue Data Catalog, and Trino provides a powerful, simple, and serverless solution