TPC-H Databricks vs Apache Iceberg - (OLake + AWS Glue + EMR)


The year is 2025, and the data engineering landscape has never been more exciting—or more confusing. Walk into any tech conference, and you'll hear buzzwords flying around like "lakehouse," "Delta Lake," "Iceberg," and "unified analytics." But beneath all the marketing noise lies a fundamental question that keeps data architects awake at night: Which platform can actually deliver on the promise of fast, reliable, cost-effective analytics at scale?
To answer this question, we embarked on the most comprehensive benchmark we could design: 1TB of industry-standard TPC-H data, 8.6 billion rows, and two of the most talked-about platforms in modern data engineering going head-to-head in an epic performance showdown.
This isn’t another vendor shootout. We’re comparing two different takes on data architecture—one with UC Berkeley roots, one from Netflix’s open‑source world—to see how they perform in practice.
Buckle up. We're about to dive deep into the technologies that are reshaping how the world thinks about data.
Chapter 1: The Genesis Stories - How Giants Are Born
Databricks: From Academic Research to Enterprise Dominance
Born out of UC Berkeley’s AMPLab, Spark set out to make distributed computing actually usable. In 2013, its creators launched Databricks to turn that power into something teams could run day to day—first as managed Spark, then as a full platform.
Highlights, at a glance:
- 2013–2015: Managed Spark + notebooks.
- 2016–2018: Cluster automation, collab notebooks, early MLflow.
- 2019–2021: Delta Lake brings ACID, schema enforcement, time travel.
- 2022–2025: Unity Catalog, Photon, tighter AI/LLM workflows.
Net-net: Databricks evolved from “Spark‑as‑a‑service” into a unified analytics platform focused on speed, reliability, and usability.
Apache Iceberg: The Open Source Rebellion
While Databricks doubled down on an integrated platform, Netflix, Apple, and LinkedIn hit classic data‑lake pain: tiny files, slow planning, brittle schema changes—and growing discomfort with vendor lock‑in.
How Iceberg showed up:
- 2017: Netflix kicked off Iceberg to fix those fundamentals.
- 2018–2019: Open‑sourced to Apache; Apple and LinkedIn joined.
- 2020–2021: Built for multi‑engine use (Spark, Flink, Trino/Presto, etc.).
- 2022–2025: Rapid adoption across clouds and tooling.
At its core, Iceberg stands for open, interoperable data architecture you can move across systems without rewriting everything.
Chapter 2: Technical Deep Dive - The Architecture That Powers Performance
When we talk about TPC-H benchmarking at 1TB scale, we're not just comparing query engines—we're comparing entire data ecosystems. The real performance story lies in how each architecture handles the complete journey from source data ingestion to final query execution. In the case of Databricks, its tightly integrated Delta Lake foundation plays a key role in how data is stored, optimized, and queried. Let's examine how both architectures orchestrate this complex dance of data movement, storage optimization, and compute execution.
Checkout feature level differences in following blog Apache Iceberg VS Delta Lake. Read our guide: Apache Iceberg vs Delta Lake: Ultimate Guide for Data Lakes.
Databricks: The Integrated Performance Machine
The Databricks approach represents a vertically integrated philosophy where every component is designed to work seamlessly with every other component. Think of it as a Formula 1 racing team where the engine, chassis, and aerodynamics are all custom-built to work together.

Stage 1: Data Ingestion and Landing
The journey begins with PostgreSQL as our source system. Databricks connects to PostgreSQL through a JDBC connector, establishing a straightforward yet efficient data pipeline to Delta Lake. The transfer mechanism is deliberately simple: data flows in batches of 200,000 rows at a time.
Stage 2: Delta Lake - The Smart Landing Zone
This is where Databricks shows its architectural sophistication. As TPC-H data lands in Delta Lake, the engine automatically optimizes the storage layout through optimized writes and auto-compaction, merging small files into larger, well-sized Parquet files to reduce metadata overhead and improve query performance.
Stage 3: The Compute Layer When TPC-H queries execute, the Databricks Runtime orchestrates a sophisticated execution strategy:
-
Adaptive Query Execution: Real-time query plan adjustments based on actual data distribution
-
Dynamic Resource Allocation: Clusters scale compute resources based on query complexity and data volume
-
Adaptive Partition Coalescing: Specifically merges small shuffle partitions post-shuffle to reduce task overhead and improve parallelism balance.
Apache Iceberg: The Federated Architecture Approach
The Iceberg architecture takes a fundamentally different approach—instead of tight integration, it achieves performance through open standards and intelligent metadata management. In our benchmark setup, OLake serves as the critical bridge between PostgreSQL and the Iceberg ecosystem.

Stage 1: OLake-Powered Data Ingestion
The journey begins with OLake as the data movement engine. OLake isn't just another EL tool—it's specifically designed for high-performance data lake ingestion with Iceberg optimization.
Stage 2: Iceberg Table Creation and Optimization
This is where Iceberg’s design efficiency comes into play. As data lands in Iceberg tables, it automatically maintains metadata and organizes files into an optimized layout, pruning unnecessary reads and ensuring consistent query performance without manual tuning.
Stage 3: AWS Glue Catalog Integration
The AWS Glue Catalog acts as a universal metadata layer, enabling seamless table discovery and interoperability for our query engine Spark.
Stage 4: Spark Query Execution
While Iceberg supports seamless query access from multiple engines such as Trino, Flink, and Spark, for an apples-to-apples comparison with Databricks, we used Spark on AWS EMR as the query layer. The setup leveraged adaptive query execution (AQE), skew join handling, and partition coalescing for runtime optimization.
Chapter 3: The Benchmark Design
Benchmarks only matter if they look like real work. We used the industry‑standard TPC‑H suite at the 1TB scale—about 8.66B rows spread across 8 tables—and ran all 22 queries sequentially on both platforms.
- What we ran: The exact 22 TPC‑H queries, unmodified.
- How we ran them: Same dataset, same scale, same order, measured to the second.
- Why it’s fair: Identical source data and equivalent cluster profiles on each side.
What TPC‑H actually stresses:
- Multi‑table joins and planning under skew
- Predicate/partition pruning and scan efficiency
- Heavy aggregations, group‑bys, and rollups
- Subqueries, EXISTS/NOT EXISTS patterns, and selective filters
- Ordered outputs, top‑N, and window‑style workloads
Why this design matters:
- It captures the mix of quick lookups and long, complex reports most teams run daily.
- It reveals not just raw speed, but how each system prunes, caches, joins, and schedules work under pressure.
Chapter 4: The Battle Begins
A. The Battlefield Setup
To ensure a true apples‑to‑apples comparison, both environments were provisioned with equivalent resources, identical connector parameters, and their recommended destination‑side optimizations.
- Source and Compute configurations
- Data Ingestion configuration
- Query Execution configuration
| Component | Deatils |
|---|---|
| Source | Azure PostgrSQL |
| Compute | 32 vCPU, 128GB RAM |
| Environment | Deatils |
|---|---|
| Databricks | n2-standard-32 (32 vCPU, 128 GB RAM) |
| OLake | Standard_D32s_v6 (32 vCPU, 64 GB RAM) |
| Environment | Deatils |
|---|---|
| Databricks | - Master node: n2-standard-32 (32 vCPU, 128 GB RAM) - Worker nodes: 1-3x n2-standard-16 (16 vCPU, 64 GB RAM) |
| Iceberg | - Master node: m6g.8xlarge (32 vCPU, 128 GB RAM) - Core nodes: 1-3x m6g.4xlarge (16 vCPU, 64 GB RAM) |
B. Data Transfer
Before we can benchmark query performance, we need to get our 1TB of TPC-H data into both systems efficiently.
Moving 8.66 billion rows from PostgreSQL to analytical platforms isn't trivial. Traditional ETL tools often struggle with this scale, creating bottlenecks that can take hours or even days to resolve. The performance of data ingestion directly impacts how fresh your analytical insights can be—a critical factor in today's real-time business environment.
1. Databricks (Using JDBC)
For our Databricks implementation, we used a straightforward approach that prioritizes reliability over maximum throughput. This conservative strategy reflects real-world production constraints where stability often takes precedence over raw speed.
Our Implementation Approach:
-
Single JDBC Connection: One dedicated connection stream to prevent overwhelming the PostgreSQL source
-
Fixed Batch Size: Consistent 200,000-row batches was chosen as optimal batch size to maintain memory usage after testing on different batch sizes.
-
Single Write Operations: Each batch written individually to Delta Lake, ensuring transaction integrity
-
Sequential Processing: Linear data flow from source to destination without complex parallelization
We enabled Delta’s Auto Optimize and Auto Compaction features to automatically merge small files and improve write performance without manual intervention.
Code used for the data transfer:
Show ETL code (PostgreSQL → Databricks Delta)
import time, json, traceback
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# Keep it minimal
spark.conf.set("spark.sql.adaptive.enabled", "true")
# -------- Conn --------
host = "dz-olake-benchmark-postgres.postgres.database.azure.com"
port = "5432"
database = "database_name"
user = "postgres_username"
password = "password" # e.g., dbutils.secrets.get("scope","key")
jdbc_url = (
f"jdbc:postgresql://{host}:{port}/{database}"
"?sslmode=require&connectTimeout=30&socketTimeout=28800&queryTimeout=27000"
"&tcpKeepAlive=true&keepalives_idle=120&keepalives_interval=30&keepalives_count=5"
)
JDBC_PROPS = {
"driver": "org.postgresql.Driver",
"user": user,
"password": password,
"fetchsize": "200000" # single-stream batches
}
SRC_SCHEMA = "tpch"
TARGET_SCHEMA = "datazip.testing3" # adjust if needed
TABLES = ['lineitem','orders','partsupp','customer','part','supplier','nation','region']
def log(msg):
ts = time.strftime("%Y-%m-%d %H:%M:%S")
print(f"[{ts}] {msg}", flush=True)
def rows_bytes_from_history(fq):
try:
h = (spark.sql(f"DESCRIBE HISTORY {fq}")
.where("operation in ('WRITE','MERGE','CREATE TABLE AS SELECT')")
.orderBy("timestamp", ascending=False)
.limit(1)
.collect()[0]["operationMetrics"])
def g(k, default="0"): return int(h.get(k, default))
num_rows = g("numOutputRows", h.get("numInsertedRows","0"))
bytes_written = g("bytesWritten")
files_added = g("numFiles", h.get("numAddedFiles","0"))
return num_rows, bytes_written, files_added
except Exception:
return 0, 0, 0
def ensure_table_with_props(fq, src_table):
# Build empty DF (0 rows) to carry schema
empty_df = (spark.read.format("jdbc")
.option("url", jdbc_url)
.option("dbtable", f"(SELECT * FROM {SRC_SCHEMA}.{src_table} WHERE 1=0) s")
.options(**JDBC_PROPS)
.load())
view = f"v_{src_table}_empty"
empty_df.createOrReplaceTempView(view)
# Create once with table-level Auto Optimize before first real write
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {fq}
USING DELTA
TBLPROPERTIES (
'delta.autoOptimize.optimizeWrite'='true',
'delta.autoOptimize.autoCompact'='true'
)
AS SELECT * FROM {view} WHERE 1=0
""")
# Ensure props in case table existed without them
spark.sql(f"""
ALTER TABLE {fq} SET TBLPROPERTIES (
'delta.autoOptimize.optimizeWrite'='true',
'delta.autoOptimize.autoCompact'='true'
)
""")
spark.catalog.dropTempView(view)
def truncate_table(fq):
spark.sql(f"TRUNCATE TABLE {fq}")
def read_whole_table(src_table):
t0 = time.time()
df = (spark.read.format("jdbc")
.option("url", jdbc_url)
.option("dbtable", f"{SRC_SCHEMA}.{src_table}")
.options(**JDBC_PROPS)
.load())
return df, time.time() - t0
# -------- MAIN --------
overall_t0 = time.time()
spark.sql(f"CREATE SCHEMA IF NOT EXISTS {TARGET_SCHEMA}")
log("="*80)
log("🚀 SIMPLE TPCH COPY (single JDBC stream, fetchsize=200000, create-first with table-level Auto Optimize)")
log("="*80)
summary = []
for t in TABLES:
fq = f"{TARGET_SCHEMA}.{t}"
start = time.time()
log(f"\n========== {t} ==========")
try:
# 1) Ensure empty table exists with desired properties, then truncate for a fresh load
ensure_table_with_props(fq, t)
truncate_table(fq)
# 2) Single-stream READ
df, read_sec = read_whole_table(t)
log(f"Read {t} finished in {read_sec:.2f}s")
# 3) Single WRITE (append into truncated table)
w0 = time.time()
(df.write
.format("delta")
.mode("append")
.saveAsTable(fq))
write_sec = time.time() - w0
rows, bytes_written, files = rows_bytes_from_history(fq)
total = time.time() - start
log(f"✅ {t} written in {write_sec:.2f}s | total {total:.2f}s")
log(f" rows={rows:,} | bytes={bytes_written:,} | files={files}")
summary.append({
"table": t,
"read_sec": round(read_sec,2),
"write_sec": round(write_sec,2),
"total_sec": round(total,2),
"rows": rows,
"bytes": bytes_written,
"files": files
})
except Exception as e:
log(f"❌ FAILED {t}: {e}")
log(traceback.format_exc())
summary.append({"table": t, "error": str(e)})
overall = time.time() - overall_t0
log("\n" + "="*80)
log("🎉 PIPELINE COMPLETED")
log("="*80)
log(f"Total elapsed: {overall/60:.2f} min")
log("\n📋 FINAL SUMMARY:")
log(json.dumps(summary, indent=2))
Why This Conservative Approach?
When we initially attempted to parallelize the data transfer using multiple concurrent JDBC connections, we hit a wall of technical constraints that made the simple sequential approach far more practical.
The Core Issues:
-
Memory and GC Pressure: Eight parallel tasks meant eight JDBC connections and eight batch buffers in memory simultaneously. This exceeded our 128 GB node's capacity, triggering aggressive garbage collection pauses (10-30 seconds) that froze all tasks, timed out connections, and forced retries.
-
Source Database Throttling: Multiple concurrent readers exhausted PostgreSQL's connection slots and created I/O contention on the source, slowing all parallel reads.
Sequential writes with a single JDBC connection proved faster and more reliable. Each 200K-row batch maintained stable resource usage—no contention, no memory pressure, no unexpected timeouts.
- Memory Utilization
- CPU Usage
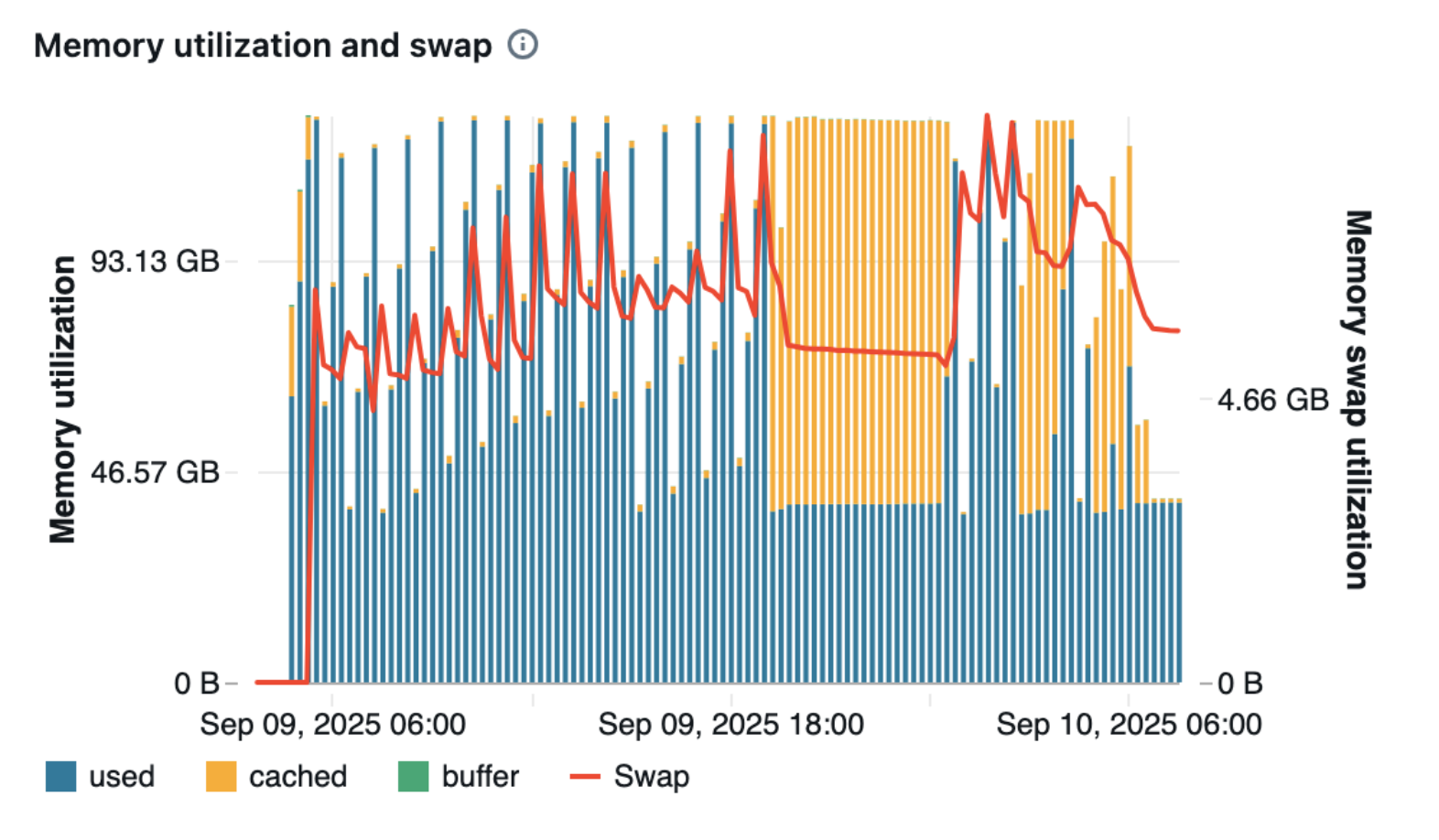
The cluster maintained memory utilization between 46-93 GB throughout the data transfer process, with very low swap usage. This indicates that the 128 GB RAM instance was sufficient to handle the PostgreSQL to Delta Lake data ingestion efficiently, with most data processing happening in memory rather than relying on disk-based swap.
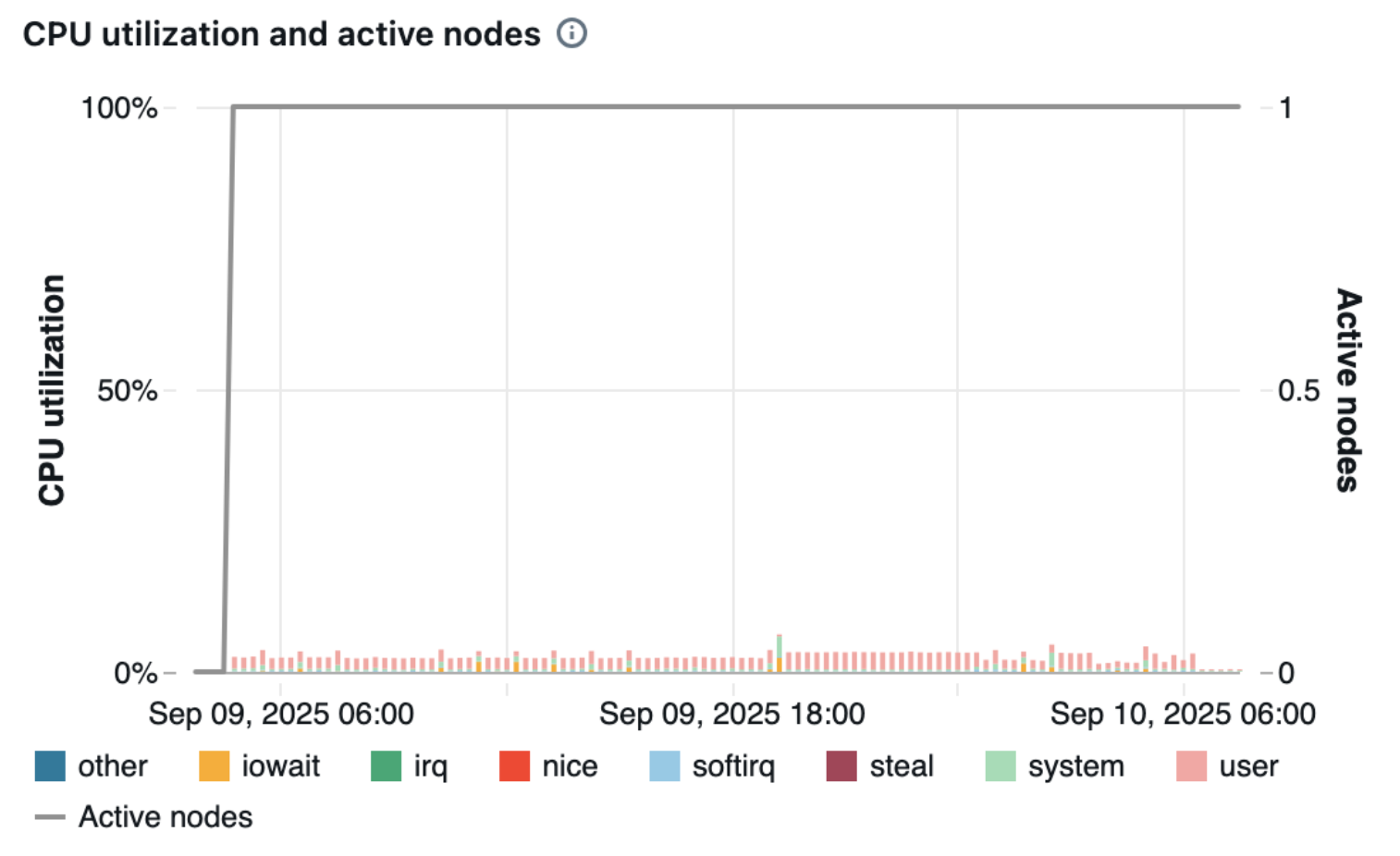
The CPU utilization remained extremely low (near 0%) throughout the entire data transfer period from PostgreSQL to Delta Lake. This was due to the sequential transfer approach rather than parallel processing, which meant that the 32 vCPU capacity was not utilized to its limit.
2. Iceberg (Using OLake)
For the Iceberg path, we leveraged OLake, an open-source data replication tool specifically optimized for high-throughput data lake ingestion.
OLake's Advantage:
- Delivers high throughput through parallelized data chunking, resumable historical snapshots, and lightning-fast incremental updates, ensuring exactly-once reliability even at massive scale.
- OLake's setup is really simple and UI-driven, which made our data ingestion process much easier. Instead of spending time writing and optimizing code like in traditional ETL tools, we just configure everything through OLake’s intuitive interface which is extremely user friendly.
In our runs, OLake was configured with max_threads=32 for ingestion parallelism.
- Memory Utilization
- CPU Usage
"system_memory_used_gb": {
"min": 4.023582458496094,
"max": 61.19172668457031,
"mean": 49.14759881837982,
"count": 8628
}
- The system memory usage ranged from a minimum of 4.02 GB to a maximum of 61.19 GB, with an average of 49.15 GB throughout the transfer process. This indicates that the 128GB RAM instance was sufficient.
- We could have increased the parallel processing by increasing the number of threads, and still would have been within the 128GB RAM limit. The optimal memory usage has been observed here on the OLake's side.
"cpu_usage_percent": {
"min": 0.14021625333129503,
"max": 97.88296172040852,
"mean": 93.47998879565941,
"count": 8628
}
- The CPU usage ranged from 0.14% to 97.88%, with an average of 93.48% throughout the transfer process. This indicates that OLake maintained consistently high CPU utilization during the data ingestion, suggesting that the tool was actively processing data at a very high rate.
Comparing both the approaches:
When comparing our two data transfer approaches from local PostgreSQL to their destinations—Databricks Delta tables via a single-stream JDBC pipeline and Iceberg on S3 via a high‑throughput OLake pipeline—we observed clear differences in speed, operational effort, and cost, along with meaningful trade‑offs in reliability and flexibility.
| Dimensions | Databricks | OLake |
|---|---|---|
| Transfer Time | 25.7 hours | ~12 hours |
| Transfer Cost | n2-standard-32($1.55/hr) = ~$39 | Standard_D32s_v6 (32 vCPU, 64 GB RAM)($1.61/hr) = ~$20 |
| Operational Comfort | Tedious | Extremely Simple |
The transfer time clearly shows the difference—one method took around 25 hours, while the other finished in less than half that time.
Time and cost move together in data engineering—longer runs mean higher bills. OLake’s high throughput reduces runtime and, by extension, infrastructure cost. Plus, OLake is open source, so you’re only paying for the compute and storage you choose to provision.
The final question is comfort: How effortless is it for a data engineer to get from “connect” to “complete”?
-
On Databricks, we wrote extensive Python—managing source/target connections, selecting tables, and building a custom transfer pipeline—powerful, but undeniably tedious for bulk loads.
-
With OLake, the workflow was point‑and‑click: enter source and destination configs, select tables, hit Sync, and watch progress. It’s the kind of setup where you can watch a movie and eat pizza while the data moves—because that's how easy it is!
C. Running TPCH queries
With our 1TB dataset successfully loaded into both platforms, the real test begins. This is where architectural decisions, query optimization strategies, and compute orchestration converge into raw performance numbers. Over the course of our benchmark, we executed all 22 TPC-H queries sequentially on both platforms, measuring execution time down to the second.
Important benchmarking note: To keep the comparison apples-to-apples, we aimed to run the same Spark TPC-H code on both platforms. On the Iceberg side, we observed minor difficulties and adjusted accordingly:
-
With 64 shuffle partitions, we encountered memory pressure (OOM) and failures, so we set partitions to 128.
-
We had to turn off vectorized reading due to an Arrow "Buffer index out of bounds" error (when processing certain Parquet pages with DOUBLE columns, the Arrow buffer allocation logic did not size the buffer correctly, creating a 0‑byte buffer when ~40KB was required). Because of this, we switched to non‑vectorized reading, which definitely affects the speed to query the data.
Code used to run the TPC-H queries for Databricks:
Show query runner code — Databricks
import time
import logging
# Setup logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger('tpch_benchmark')
def configure_spark_settings():
"""Configure Spark settings to optimize query execution"""
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
spark.conf.set("spark.sql.shuffle.partitions", "64")
logger.info("Spark configurations set: Adaptive Query Execution enabled, Coalesce Partitions enabled, shuffle partitions set to 64")
def run_tpch_query(query_num, sql_query):
"""Run a single TPC-H query with timing and logging"""
query_name = f"TPC-H Query {query_num}"
logger.info(f"Starting {query_name}")
start_time = time.perf_counter()
try:
# Execute the exact SQL query as provided
if query_num == 15 and isinstance(sql_query, list):
for i, sql_stmt in enumerate(sql_query):
logger.info(f"{query_name} - Executing statement {i+1}/3")
if i == 1:
# SELECT statement: return/display results to force execution
df = spark.sql(sql_stmt)
df.show()
else:
# CREATE VIEW and DROP VIEW statements
spark.sql(sql_stmt)
else:
# All other queries are single-statement
df = spark.sql(sql_query)
df.show()
end_time = time.perf_counter()
execution_time = end_time - start_time
logger.info(f"{query_name} completed successfully in {execution_time:.2f} seconds")
return {
'query_number': query_num,
'time_seconds': execution_time,
'status': 'SUCCESS'
}
except Exception as e:
end_time = time.perf_counter()
execution_time = end_time - start_time
logger.error(f"{query_name} failed after {execution_time:.2f} seconds - Error: {str(e)}")
return {
'query_number': query_num,
'time_seconds': execution_time,
'status': 'FAILED',
'error': str(e)
}
# All 22 TPC-H Queries exactly as provided in your file
tpch_queries = {
1: """SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM datazip.testing3.lineitem
WHERE l_shipdate <= DATE '1998-12-01' - INTERVAL '90' DAY
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus""",
2: """SELECT
s_acctbal,
s_name,
n_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
FROM
datazip.testing3.part,
datazip.testing3.supplier,
datazip.testing3.partsupp,
datazip.testing3.nation,
datazip.testing3.region
WHERE
p_partkey = ps_partkey
AND s_suppkey = ps_suppkey
AND p_size = 15
AND p_type LIKE '%BRASS'
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND ps_supplycost = (
SELECT MIN(ps_supplycost)
FROM datazip.testing3.partsupp, datazip.testing3.supplier, datazip.testing3.nation, datazip.testing3.region
WHERE p_partkey = ps_partkey
AND s_suppkey = ps_suppkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
)
ORDER BY
s_acctbal DESC,
n_name,
s_name,
p_partkey
LIMIT 100""",
3: """SELECT
l_orderkey,
SUM(l_extendedprice * (1 - l_discount)) AS revenue,
o_orderdate,
o_shippriority
FROM
datazip.testing3.customer,
datazip.testing3.orders,
datazip.testing3.lineitem
WHERE
c_mktsegment = 'BUILDING'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < DATE '1995-03-15'
AND l_shipdate > DATE '1995-03-15'
GROUP BY
l_orderkey,
o_orderdate,
o_shippriority
ORDER BY
revenue DESC,
o_orderdate
LIMIT 10""",
4: """SELECT
o_orderpriority,
COUNT(*) AS order_count
FROM datazip.testing3.orders
WHERE
o_orderdate >= DATE '1993-07-01'
AND o_orderdate < DATE '1993-07-01' + INTERVAL '3' MONTH
AND EXISTS (
SELECT *
FROM datazip.testing3.lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority""",
5: """SELECT
n_name,
SUM(l_extendedprice * (1 - l_discount)) AS revenue
FROM
datazip.testing3.customer,
datazip.testing3.orders,
datazip.testing3.lineitem,
datazip.testing3.supplier,
datazip.testing3.nation,
datazip.testing3.region
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
AND o_orderdate >= DATE '1994-01-01'
AND o_orderdate < DATE '1994-01-01' + INTERVAL '1' YEAR
GROUP BY n_name
ORDER BY revenue DESC""",
6: """SELECT SUM(l_extendedprice * l_discount) AS revenue
FROM datazip.testing3.lineitem
WHERE
l_shipdate >= DATE '1994-01-01'
AND l_shipdate < DATE '1994-01-01' + INTERVAL '1' YEAR
AND l_discount BETWEEN 0.06 - 0.01 AND 0.06 + 0.01
AND l_quantity < 24""",
7: """SELECT
supp_nation,
cust_nation,
l_year,
SUM(volume) AS revenue
FROM (
SELECT
n1.n_name AS supp_nation,
n2.n_name AS cust_nation,
EXTRACT(YEAR FROM l_shipdate) AS l_year,
l_extendedprice * (1 - l_discount) AS volume
FROM
datazip.testing3.supplier,
datazip.testing3.lineitem,
datazip.testing3.orders,
datazip.testing3.customer,
datazip.testing3.nation n1,
datazip.testing3.nation n2
WHERE
s_suppkey = l_suppkey
AND o_orderkey = l_orderkey
AND c_custkey = o_custkey
AND s_nationkey = n1.n_nationkey
AND c_nationkey = n2.n_nationkey
AND ((n1.n_name = 'FRANCE' AND n2.n_name = 'GERMANY')
OR (n1.n_name = 'GERMANY' AND n2.n_name = 'FRANCE'))
AND l_shipdate BETWEEN DATE '1995-01-01' AND DATE '1996-12-31'
) AS shipping
GROUP BY supp_nation, cust_nation, l_year
ORDER BY supp_nation, cust_nation, l_year""",
8: """SELECT
o_year,
SUM(CASE WHEN nation = 'BRAZIL' THEN volume ELSE 0 END) / SUM(volume) AS mkt_share
FROM (
SELECT
EXTRACT(YEAR FROM o_orderdate) AS o_year,
l_extendedprice * (1 - l_discount) AS volume,
n2.n_name AS nation
FROM
datazip.testing3.part,
datazip.testing3.supplier,
datazip.testing3.lineitem,
datazip.testing3.orders,
datazip.testing3.customer,
datazip.testing3.nation n1,
datazip.testing3.nation n2,
datazip.testing3.region
WHERE
p_partkey = l_partkey
AND s_suppkey = l_suppkey
AND l_orderkey = o_orderkey
AND o_custkey = c_custkey
AND c_nationkey = n1.n_nationkey
AND n1.n_regionkey = r_regionkey
AND r_name = 'AMERICA'
AND s_nationkey = n2.n_nationkey
AND o_orderdate BETWEEN DATE '1995-01-01' AND DATE '1996-12-31'
AND p_type = 'ECONOMY ANODIZED STEEL'
) AS all_nations
GROUP BY o_year
ORDER BY o_year""",
9: """SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity AS amount
FROM
datazip.testing3.part,
datazip.testing3.supplier,
datazip.testing3.lineitem,
datazip.testing3.partsupp,
datazip.testing3.orders,
datazip.testing3.nation
WHERE
s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name LIKE '%green%'
) AS profit
GROUP BY nation, o_year
ORDER BY nation, o_year DESC""",
10: """SELECT
c_custkey,
c_name,
SUM(l_extendedprice * (1 - l_discount)) AS revenue,
c_acctbal,
n_name,
c_address,
c_phone,
c_comment
FROM
datazip.testing3.customer,
datazip.testing3.orders,
datazip.testing3.lineitem,
datazip.testing3.nation
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate >= DATE '1993-10-01'
AND o_orderdate < DATE '1993-10-01' + INTERVAL '3' MONTH
AND l_returnflag = 'R'
AND c_nationkey = n_nationkey
GROUP BY
c_custkey,
c_name,
c_acctbal,
c_phone,
n_name,
c_address,
c_comment
ORDER BY revenue DESC
LIMIT 20""",
11: """SELECT
ps_partkey,
SUM(ps_supplycost * ps_availqty) AS value
FROM
datazip.testing3.partsupp,
datazip.testing3.supplier,
datazip.testing3.nation
WHERE
ps_suppkey = s_suppkey
AND s_nationkey = n_nationkey
AND n_name = 'GERMANY'
GROUP BY ps_partkey
HAVING SUM(ps_supplycost * ps_availqty) > (
SELECT SUM(ps_supplycost * ps_availqty) * 0.0001
FROM
datazip.testing3.partsupp,
datazip.testing3.supplier,
datazip.testing3.nation
WHERE
ps_suppkey = s_suppkey
AND s_nationkey = n_nationkey
AND n_name = 'GERMANY'
)
ORDER BY value DESC""",
12: """SELECT
l_shipmode,
SUM(CASE
WHEN o_orderpriority = '1-URGENT'
OR o_orderpriority = '2-HIGH'
THEN 1
ELSE 0
END) AS high_line_count,
SUM(CASE
WHEN o_orderpriority <> '1-URGENT'
AND o_orderpriority <> '2-HIGH'
THEN 1
ELSE 0
END) AS low_line_count
FROM
datazip.testing3.orders,
datazip.testing3.lineitem
WHERE
o_orderkey = l_orderkey
AND l_shipmode IN ('MAIL', 'SHIP')
AND l_commitdate < l_receiptdate
AND l_shipdate < l_commitdate
AND l_receiptdate >= DATE '1994-01-01'
AND l_receiptdate < DATE '1994-01-01' + INTERVAL '1' YEAR
GROUP BY l_shipmode
ORDER BY l_shipmode""",
13: """SELECT
c_count,
COUNT(*) AS custdist
FROM (
SELECT
c_custkey,
COUNT(o_orderkey) AS c_count
FROM
datazip.testing3.customer LEFT OUTER JOIN datazip.testing3.orders ON
c_custkey = o_custkey
AND o_comment NOT LIKE '%special%requests%'
GROUP BY c_custkey
) c_orders
GROUP BY c_count
ORDER BY custdist DESC, c_count DESC""",
14: """SELECT
100.00 * SUM(CASE
WHEN p_type LIKE 'PROMO%'
THEN l_extendedprice * (1 - l_discount)
ELSE 0
END) / SUM(l_extendedprice * (1 - l_discount)) AS promo_revenue
FROM
datazip.testing3.lineitem,
datazip.testing3.part
WHERE
l_partkey = p_partkey
AND l_shipdate >= DATE '1995-09-01'
AND l_shipdate < DATE '1995-09-01' + INTERVAL '1' MONTH""",
15: [
"""CREATE OR REPLACE TEMPORARY VIEW revenue0 AS
SELECT
l_suppkey AS supplier_no,
SUM(l_extendedprice * (1 - l_discount)) AS total_revenue
FROM datazip.testing3.lineitem
WHERE
l_shipdate >= DATE '1996-01-01'
AND l_shipdate < DATE '1996-01-01' + INTERVAL '3' MONTH
GROUP BY l_suppkey""",
"""SELECT
s_suppkey,
s_name,
s_address,
s_phone,
total_revenue
FROM
datazip.testing3.supplier,
revenue0
WHERE
s_suppkey = supplier_no
AND total_revenue = (
SELECT MAX(total_revenue) FROM revenue0
)
ORDER BY s_suppkey""",
"""DROP VIEW revenue0"""
]
,
16: """SELECT
p_brand,
p_type,
p_size,
COUNT(DISTINCT ps_suppkey) AS supplier_cnt
FROM
datazip.testing3.partsupp,
datazip.testing3.part
WHERE
p_partkey = ps_partkey
AND p_brand <> 'Brand#45'
AND p_type NOT LIKE 'MEDIUM POLISHED%'
AND p_size IN (49, 14, 23, 45, 19, 3, 36, 9)
AND ps_suppkey NOT IN (
SELECT s_suppkey
FROM datazip.testing3.supplier
WHERE s_comment LIKE '%Customer%Complaints%'
)
GROUP BY p_brand, p_type, p_size
ORDER BY supplier_cnt DESC, p_brand, p_type, p_size""",
17: """SELECT SUM(l_extendedprice) / 7.0 AS avg_yearly
FROM
datazip.testing3.lineitem,
datazip.testing3.part
WHERE
p_partkey = l_partkey
AND p_brand = 'Brand#23'
AND p_container = 'MED BOX'
AND l_quantity < (
SELECT 0.2 * AVG(l_quantity)
FROM datazip.testing3.lineitem
WHERE l_partkey = p_partkey
)""",
18: """SELECT
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice,
SUM(l_quantity) AS sum_qty
FROM
datazip.testing3.customer,
datazip.testing3.orders,
datazip.testing3.lineitem
WHERE
o_orderkey IN (
SELECT l_orderkey
FROM datazip.testing3.lineitem
GROUP BY l_orderkey
HAVING SUM(l_quantity) > 300
)
AND c_custkey = o_custkey
AND o_orderkey = l_orderkey
GROUP BY
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice
ORDER BY o_totalprice DESC, o_orderdate
LIMIT 100""",
19: """SELECT SUM(l_extendedprice * (1 - l_discount)) AS revenue
FROM
datazip.testing3.lineitem,
datazip.testing3.part
WHERE
(
p_partkey = l_partkey
AND p_brand = 'Brand#12'
AND p_container IN ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG')
AND l_quantity >= 1 AND l_quantity <= 1 + 10
AND p_size BETWEEN 1 AND 5
AND l_shipmode IN ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)
OR
(
p_partkey = l_partkey
AND p_brand = 'Brand#23'
AND p_container IN ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK')
AND l_quantity >= 10 AND l_quantity <= 10 + 10
AND p_size BETWEEN 1 AND 10
AND l_shipmode IN ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)
OR
(
p_partkey = l_partkey
AND p_brand = 'Brand#34'
AND p_container IN ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG')
AND l_quantity >= 20 AND l_quantity <= 20 + 10
AND p_size BETWEEN 1 AND 15
AND l_shipmode IN ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)""",
20: """SELECT
s_name,
s_address
FROM
datazip.testing3.supplier,
datazip.testing3.nation
WHERE
s_suppkey IN (
SELECT ps_suppkey
FROM datazip.testing3.partsupp
WHERE ps_partkey IN (
SELECT p_partkey
FROM datazip.testing3.part
WHERE p_name LIKE 'forest%'
)
AND ps_availqty > (
SELECT 0.5 * SUM(l_quantity)
FROM datazip.testing3.lineitem
WHERE l_partkey = ps_partkey
AND l_suppkey = ps_suppkey
AND l_shipdate >= DATE '1994-01-01'
AND l_shipdate < DATE '1994-01-01' + INTERVAL '1' YEAR
)
)
AND s_nationkey = n_nationkey
AND n_name = 'CANADA'
ORDER BY s_name""",
21: """SELECT
s_name,
COUNT(*) AS numwait
FROM
datazip.testing3.supplier,
datazip.testing3.lineitem l1,
datazip.testing3.orders,
datazip.testing3.nation
WHERE
s_suppkey = l1.l_suppkey
AND o_orderkey = l1.l_orderkey
AND o_orderstatus = 'F'
AND l1.l_receiptdate > l1.l_commitdate
AND EXISTS (
SELECT *
FROM datazip.testing3.lineitem l2
WHERE l2.l_orderkey = l1.l_orderkey
AND l2.l_suppkey <> l1.l_suppkey
)
AND NOT EXISTS (
SELECT *
FROM datazip.testing3.lineitem l3
WHERE l3.l_orderkey = l1.l_orderkey
AND l3.l_suppkey <> l1.l_suppkey
AND l3.l_receiptdate > l3.l_commitdate
)
AND s_nationkey = n_nationkey
AND n_name = 'SAUDI ARABIA'
GROUP BY s_name
ORDER BY numwait DESC, s_name
LIMIT 100""",
22: """SELECT
cntrycode,
COUNT(*) AS numcust,
SUM(c_acctbal) AS totacctbal
FROM (
SELECT
SUBSTRING(c_phone, 1, 2) AS cntrycode,
c_acctbal
FROM datazip.testing3.customer
WHERE SUBSTRING(c_phone, 1, 2) IN ('13', '31', '23', '29', '30', '18', '17')
AND c_acctbal > (
SELECT AVG(c_acctbal)
FROM datazip.testing3.customer
WHERE c_acctbal > 0.00
AND SUBSTRING(c_phone, 1, 2) IN ('13', '31', '23', '29', '30', '18', '17')
)
AND NOT EXISTS (
SELECT *
FROM datazip.testing3.orders
WHERE o_custkey = c_custkey
)
) AS custsale
GROUP BY cntrycode
ORDER BY cntrycode"""
}
# Run all 22 TPC-H queries with timing and logging
def run_all_tpch_queries():
all_results = []
total_start_time = time.perf_counter()
logger.info("Starting complete TPC-H benchmark run (22 queries)")
for query_num in range(1, 23): # 1 to 22
if query_num in tpch_queries:
result = run_tpch_query(query_num, tpch_queries[query_num])
all_results.append(result)
# Small pause between queries
time.sleep(0.5)
total_end_time = time.perf_counter()
total_time = total_end_time - total_start_time
logger.info(f"Complete TPC-H benchmark finished in {total_time:.2f} seconds")
# Print summary
print("\n" + "="*60)
print("TPC-H BENCHMARK RESULTS SUMMARY")
print("="*60)
successful_queries = 0
failed_queries = 0
total_query_time = 0
for result in all_results:
status_symbol = "✓" if result['status'] == 'SUCCESS' else "✗"
print(f"{status_symbol} Query {result['query_number']:2d}: {result['time_seconds']:8.2f}s - {result['status']}")
if result['status'] == 'SUCCESS':
successful_queries += 1
total_query_time += result['time_seconds']
else:
failed_queries += 1
print("="*60)
print(f"Successful queries: {successful_queries}/22")
print(f"Failed queries: {failed_queries}/22")
print(f"Total query execution time: {total_query_time:.2f} seconds")
print(f"Total benchmark time: {total_time:.2f} seconds")
print("="*60)
return all_results
# Execute the benchmark
if __name__ == "__main__":
benchmark_results = run_all_tpch_queries()
Code used to run the TPC-H queries for Iceberg:
Show query runner code — Iceberg
import time
import logging
import argparse
import os
from pyspark.sql import SparkSession
from typing import Optional, Union, List, Dict, Any
# Logging
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
logger = logging.getLogger("tpch_iceberg_benchmark")
def build_spark_session(app_name: str, catalog: str, warehouse: Optional[str], region: Optional[str]) -> SparkSession:
builder = (
SparkSession.builder
.appName(app_name)
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config(f"spark.sql.catalog.{catalog}", "org.apache.iceberg.spark.SparkCatalog")
.config(f"spark.sql.catalog.{catalog}.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog")
.config(f"spark.sql.catalog.{catalog}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO")
.config("spark.sql.defaultCatalog", catalog)
)
if warehouse:
builder = builder.config(f"spark.sql.catalog.{catalog}.warehouse", warehouse)
if region:
builder = builder.config(f"spark.sql.catalog.{catalog}.client.region", region)
# Reasonable Spark defaults for scans/joins
builder = (
builder
.config("spark.sql.adaptive.enabled", "true")
.config("spark.sql.adaptive.coalescePartitions.enabled", "true")
.config("spark.sql.broadcastTimeout", "1800")
.config("spark.network.timeout", "300s")
.config("spark.executor.heartbeatInterval", "60s")
)
spark = builder.getOrCreate()
return spark
def configure_spark_settings(spark: SparkSession, shuffle_partitions: int) -> None:
spark.conf.set("spark.sql.shuffle.partitions", str(shuffle_partitions))
logger.info(
f"Spark configured: AQE ON, Coalesce ON, shuffle partitions={shuffle_partitions}"
)
def run_tpch_query(spark: SparkSession, query_num: int, sql_query) -> Dict[str, Any]:
query_name = f"TPC-H Query {query_num}"
logger.info(f"Starting {query_name}")
start_time = time.perf_counter()
try:
if query_num == 15 and isinstance(sql_query, list):
for i, sql_stmt in enumerate(sql_query):
logger.info(f"{query_name} - Executing statement {i+1}/3")
if i == 1:
df = spark.sql(sql_stmt)
df.show()
else:
spark.sql(sql_stmt)
else:
df = spark.sql(sql_query)
df.show()
end_time = time.perf_counter()
execution_time = end_time - start_time
logger.info(f"{query_name} completed successfully in {execution_time:.2f} seconds")
return {"query_number": query_num, "time_seconds": execution_time, "status": "SUCCESS"}
except Exception as e:
end_time = time.perf_counter()
execution_time = end_time - start_time
logger.error(f"{query_name} failed after {execution_time:.2f} seconds - Error: {str(e)}")
return {
"query_number": query_num,
"time_seconds": execution_time,
"status": "FAILED",
"error": str(e),
}
def build_queries(catalog: str, database: str) -> Dict[int, Union[str, List[str]]]:
def tbl(name: str) -> str:
# backtick database and table because the db contains underscores and to be safe for any special chars
return f"{catalog}.`{database}`.`{name}`"
return {
1: f"""SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM {tbl('lineitem')}
WHERE l_shipdate <= DATE '1998-12-01' - INTERVAL '90' DAY
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus""",
2: f"""SELECT
s_acctbal,
s_name,
n_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
FROM
{tbl('part')},
{tbl('supplier')},
{tbl('partsupp')},
{tbl('nation')},
{tbl('region')}
WHERE
p_partkey = ps_partkey
AND s_suppkey = ps_suppkey
AND p_size = 15
AND p_type LIKE '%BRASS'
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND ps_supplycost = (
SELECT MIN(ps_supplycost)
FROM {tbl('partsupp')}, {tbl('supplier')}, {tbl('nation')}, {tbl('region')}
WHERE p_partkey = ps_partkey
AND s_suppkey = ps_suppkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
)
ORDER BY
s_acctbal DESC,
n_name,
s_name,
p_partkey
LIMIT 100""",
3: f"""SELECT
l_orderkey,
SUM(l_extendedprice * (1 - l_discount)) AS revenue,
o_orderdate,
o_shippriority
FROM
{tbl('customer')},
{tbl('orders')},
{tbl('lineitem')}
WHERE
c_mktsegment = 'BUILDING'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < DATE '1995-03-15'
AND l_shipdate > DATE '1995-03-15'
GROUP BY
l_orderkey,
o_orderdate,
o_shippriority
ORDER BY
revenue DESC,
o_orderdate
LIMIT 10""",
4: f"""SELECT
o_orderpriority,
COUNT(*) AS order_count
FROM {tbl('orders')}
WHERE
o_orderdate >= DATE '1993-07-01'
AND o_orderdate < DATE '1993-07-01' + INTERVAL '3' MONTH
AND EXISTS (
SELECT *
FROM {tbl('lineitem')}
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority""",
5: f"""SELECT
n_name,
SUM(l_extendedprice * (1 - l_discount)) AS revenue
FROM
{tbl('customer')},
{tbl('orders')},
{tbl('lineitem')},
{tbl('supplier')},
{tbl('nation')},
{tbl('region')}
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
AND o_orderdate >= DATE '1994-01-01'
AND o_orderdate < DATE '1994-01-01' + INTERVAL '1' YEAR
GROUP BY n_name
ORDER BY revenue DESC""",
6: f"""SELECT SUM(l_extendedprice * l_discount) AS revenue
FROM {tbl('lineitem')}
WHERE
l_shipdate >= DATE '1994-01-01'
AND l_shipdate < DATE '1994-01-01' + INTERVAL '1' YEAR
AND l_discount BETWEEN 0.06 - 0.01 AND 0.06 + 0.01
AND l_quantity < 24""",
7: f"""SELECT
supp_nation,
cust_nation,
l_year,
SUM(volume) AS revenue
FROM (
SELECT
n1.n_name AS supp_nation,
n2.n_name AS cust_nation,
EXTRACT(YEAR FROM l_shipdate) AS l_year,
l_extendedprice * (1 - l_discount) AS volume
FROM
{tbl('supplier')},
{tbl('lineitem')},
{tbl('orders')},
{tbl('customer')},
{tbl('nation')} n1,
{tbl('nation')} n2
WHERE
s_suppkey = l_suppkey
AND o_orderkey = l_orderkey
AND c_custkey = o_custkey
AND s_nationkey = n1.n_nationkey
AND c_nationkey = n2.n_nationkey
AND ((n1.n_name = 'FRANCE' AND n2.n_name = 'GERMANY')
OR (n1.n_name = 'GERMANY' AND n2.n_name = 'FRANCE'))
AND l_shipdate BETWEEN DATE '1995-01-01' AND DATE '1996-12-31'
) AS shipping
GROUP BY supp_nation, cust_nation, l_year
ORDER BY supp_nation, cust_nation, l_year""",
8: f"""SELECT
o_year,
SUM(CASE WHEN nation = 'BRAZIL' THEN volume ELSE 0 END) / SUM(volume) AS mkt_share
FROM (
SELECT
EXTRACT(YEAR FROM o_orderdate) AS o_year,
l_extendedprice * (1 - l_discount) AS volume,
n2.n_name AS nation
FROM
{tbl('part')},
{tbl('supplier')},
{tbl('lineitem')},
{tbl('orders')},
{tbl('customer')},
{tbl('nation')} n1,
{tbl('nation')} n2,
{tbl('region')}
WHERE
p_partkey = l_partkey
AND s_suppkey = l_suppkey
AND l_orderkey = o_orderkey
AND o_custkey = c_custkey
AND c_nationkey = n1.n_nationkey
AND n1.n_regionkey = r_regionkey
AND r_name = 'AMERICA'
AND s_nationkey = n2.n_nationkey
AND o_orderdate BETWEEN DATE '1995-01-01' AND DATE '1996-12-31'
AND p_type = 'ECONOMY ANODIZED STEEL'
) AS all_nations
GROUP BY o_year
ORDER BY o_year""",
9: f"""SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity AS amount
FROM
{tbl('part')},
{tbl('supplier')},
{tbl('lineitem')},
{tbl('partsupp')},
{tbl('orders')},
{tbl('nation')}
WHERE
s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name LIKE '%green%'
) AS profit
GROUP BY nation, o_year
ORDER BY nation, o_year DESC""",
10: f"""SELECT
c_custkey,
c_name,
SUM(l_extendedprice * (1 - l_discount)) AS revenue,
c_acctbal,
n_name,
c_address,
c_phone,
c_comment
FROM
{tbl('customer')},
{tbl('orders')},
{tbl('lineitem')},
{tbl('nation')}
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate >= DATE '1993-10-01'
AND o_orderdate < DATE '1993-10-01' + INTERVAL '3' MONTH
AND l_returnflag = 'R'
AND c_nationkey = n_nationkey
GROUP BY
c_custkey,
c_name,
c_acctbal,
c_phone,
n_name,
c_address,
c_comment
ORDER BY revenue DESC
LIMIT 20""",
11: f"""SELECT
ps_partkey,
SUM(ps_supplycost * ps_availqty) AS value
FROM
{tbl('partsupp')},
{tbl('supplier')},
{tbl('nation')}
WHERE
ps_suppkey = s_suppkey
AND s_nationkey = n_nationkey
AND n_name = 'GERMANY'
GROUP BY ps_partkey
HAVING SUM(ps_supplycost * ps_availqty) > (
SELECT SUM(ps_supplycost * ps_availqty) * 0.0001
FROM
{tbl('partsupp')},
{tbl('supplier')},
{tbl('nation')}
WHERE
ps_suppkey = s_suppkey
AND s_nationkey = n_nationkey
AND n_name = 'GERMANY'
)
ORDER BY value DESC""",
12: f"""SELECT
l_shipmode,
SUM(CASE
WHEN o_orderpriority = '1-URGENT'
OR o_orderpriority = '2-HIGH'
THEN 1
ELSE 0
END) AS high_line_count,
SUM(CASE
WHEN o_orderpriority <> '1-URGENT'
AND o_orderpriority <> '2-HIGH'
THEN 1
ELSE 0
END) AS low_line_count
FROM
{tbl('orders')},
{tbl('lineitem')}
WHERE
o_orderkey = l_orderkey
AND l_shipmode IN ('MAIL', 'SHIP')
AND l_commitdate < l_receiptdate
AND l_shipdate < l_commitdate
AND l_receiptdate >= DATE '1994-01-01'
AND l_receiptdate < DATE '1994-01-01' + INTERVAL '1' YEAR
GROUP BY l_shipmode
ORDER BY l_shipmode""",
13: f"""SELECT
c_count,
COUNT(*) AS custdist
FROM (
SELECT
c_custkey,
COUNT(o_orderkey) AS c_count
FROM
{tbl('customer')} LEFT OUTER JOIN {tbl('orders')} ON
c_custkey = o_custkey
AND o_comment NOT LIKE '%special%requests%'
GROUP BY c_custkey
) c_orders
GROUP BY c_count
ORDER BY custdist DESC, c_count DESC""",
14: f"""SELECT
100.00 * SUM(CASE
WHEN p_type LIKE 'PROMO%'
THEN l_extendedprice * (1 - l_discount)
ELSE 0
END) / SUM(l_extendedprice * (1 - l_discount)) AS promo_revenue
FROM
{tbl('lineitem')},
{tbl('part')}
WHERE
l_partkey = p_partkey
AND l_shipdate >= DATE '1995-09-01'
AND l_shipdate < DATE '1995-09-01' + INTERVAL '1' MONTH""",
15: [
f"""CREATE OR REPLACE TEMPORARY VIEW revenue0 AS
SELECT
l_suppkey AS supplier_no,
SUM(l_extendedprice * (1 - l_discount)) AS total_revenue
FROM {tbl('lineitem')}
WHERE
l_shipdate >= DATE '1996-01-01'
AND l_shipdate < DATE '1996-01-01' + INTERVAL '3' MONTH
GROUP BY l_suppkey""",
f"""SELECT
s_suppkey,
s_name,
s_address,
s_phone,
total_revenue
FROM
{tbl('supplier')},
revenue0
WHERE
s_suppkey = supplier_no
AND total_revenue = (
SELECT MAX(total_revenue) FROM revenue0
)
ORDER BY s_suppkey""",
"""DROP VIEW revenue0"""
],
16: f"""SELECT
p_brand,
p_type,
p_size,
COUNT(DISTINCT ps_suppkey) AS supplier_cnt
FROM
{tbl('partsupp')},
{tbl('part')}
WHERE
p_partkey = ps_partkey
AND p_brand <> 'Brand#45'
AND p_type NOT LIKE 'MEDIUM POLISHED%'
AND p_size IN (49, 14, 23, 45, 19, 3, 36, 9)
AND ps_suppkey NOT IN (
SELECT s_suppkey
FROM {tbl('supplier')}
WHERE s_comment LIKE '%Customer%Complaints%'
)
GROUP BY p_brand, p_type, p_size
ORDER BY supplier_cnt DESC, p_brand, p_type, p_size""",
17: f"""SELECT SUM(l_extendedprice) / 7.0 AS avg_yearly
FROM
{tbl('lineitem')},
{tbl('part')}
WHERE
p_partkey = l_partkey
AND p_brand = 'Brand#23'
AND p_container = 'MED BOX'
AND l_quantity < (
SELECT 0.2 * AVG(l_quantity)
FROM {tbl('lineitem')}
WHERE l_partkey = p_partkey
)""",
18: f"""SELECT
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice,
SUM(l_quantity) AS sum_qty
FROM
{tbl('customer')},
{tbl('orders')},
{tbl('lineitem')}
WHERE
o_orderkey IN (
SELECT l_orderkey
FROM {tbl('lineitem')}
GROUP BY l_orderkey
HAVING SUM(l_quantity) > 300
)
AND c_custkey = o_custkey
AND o_orderkey = l_orderkey
GROUP BY
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice
ORDER BY o_totalprice DESC, o_orderdate
LIMIT 100""",
19: f"""SELECT SUM(l_extendedprice * (1 - l_discount)) AS revenue
FROM
{tbl('lineitem')},
{tbl('part')}
WHERE
(
p_partkey = l_partkey
AND p_brand = 'Brand#12'
AND p_container IN ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG')
AND l_quantity >= 1 AND l_quantity <= 1 + 10
AND p_size BETWEEN 1 AND 5
AND l_shipmode IN ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)
OR
(
p_partkey = l_partkey
AND p_brand = 'Brand#23'
AND p_container IN ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK')
AND l_quantity >= 10 AND l_quantity <= 10 + 10
AND p_size BETWEEN 1 AND 10
AND l_shipmode IN ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)
OR
(
p_partkey = l_partkey
AND p_brand = 'Brand#34'
AND p_container IN ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG')
AND l_quantity >= 20 AND l_quantity <= 20 + 10
AND p_size BETWEEN 1 AND 15
AND l_shipmode IN ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)""",
20: f"""SELECT
s_name,
s_address
FROM
{tbl('supplier')},
{tbl('nation')}
WHERE
s_suppkey IN (
SELECT ps_suppkey
FROM {tbl('partsupp')}
WHERE ps_partkey IN (
SELECT p_partkey
FROM {tbl('part')}
WHERE p_name LIKE 'forest%'
)
AND ps_availqty > (
SELECT 0.5 * SUM(l_quantity)
FROM {tbl('lineitem')}
WHERE l_partkey = ps_partkey
AND l_suppkey = ps_suppkey
AND l_shipdate >= DATE '1994-01-01'
AND l_shipdate < DATE '1994-01-01' + INTERVAL '1' YEAR
)
)
AND s_nationkey = n_nationkey
AND n_name = 'CANADA'
ORDER BY s_name""",
21: f"""SELECT
s_name,
COUNT(*) AS numwait
FROM
{tbl('supplier')},
{tbl('lineitem')} l1,
{tbl('orders')},
{tbl('nation')}
WHERE
s_suppkey = l1.l_suppkey
AND o_orderkey = l1.l_orderkey
AND o_orderstatus = 'F'
AND l1.l_receiptdate > l1.l_commitdate
AND EXISTS (
SELECT *
FROM {tbl('lineitem')} l2
WHERE l2.l_orderkey = l1.l_orderkey
AND l2.l_suppkey <> l1.l_suppkey
)
AND NOT EXISTS (
SELECT *
FROM {tbl('lineitem')} l3
WHERE l3.l_orderkey = l1.l_orderkey
AND l3.l_suppkey <> l1.l_suppkey
AND l3.l_receiptdate > l3.l_commitdate
)
AND s_nationkey = n_nationkey
AND n_name = 'SAUDI ARABIA'
GROUP BY s_name
ORDER BY numwait DESC, s_name
LIMIT 100""",
22: f"""SELECT
cntrycode,
COUNT(*) AS numcust,
SUM(c_acctbal) AS totacctbal
FROM (
SELECT
SUBSTRING(c_phone, 1, 2) AS cntrycode,
c_acctbal
FROM {tbl('customer')}
WHERE SUBSTRING(c_phone, 1, 2) IN ('13', '31', '23', '29', '30', '18', '17')
AND c_acctbal > (
SELECT AVG(c_acctbal)
FROM {tbl('customer')}
WHERE c_acctbal > 0.00
AND SUBSTRING(c_phone, 1, 2) IN ('13', '31', '23', '29', '30', '18', '17')
)
AND NOT EXISTS (
SELECT *
FROM {tbl('orders')}
WHERE o_custkey = c_custkey
)
) AS custsale
GROUP BY cntrycode
ORDER BY cntrycode"""
}
def run_all_tpch_queries(spark: SparkSession, queries: Dict[int, Union[str, List[str]]]) -> List[Dict[str, Any]]:
all_results = []
total_start_time = time.perf_counter()
logger.info("Starting complete TPC-H benchmark run (22 queries)")
for query_num in range(1, 23):
if query_num in queries:
result = run_tpch_query(spark, query_num, queries[query_num])
all_results.append(result)
time.sleep(0.5)
total_end_time = time.perf_counter()
total_time = total_end_time - total_start_time
logger.info(f"Complete TPC-H benchmark finished in {total_time:.2f} seconds")
print("\n" + "=" * 60)
print("TPC-H BENCHMARK RESULTS SUMMARY")
print("=" * 60)
successful_queries = 0
failed_queries = 0
total_query_time = 0.0
for result in all_results:
status_symbol = "✓" if result["status"] == "SUCCESS" else "✗"
print(f"{status_symbol} Query {result['query_number']:2d}: {result['time_seconds']:8.2f}s - {result['status']}")
if result["status"] == "SUCCESS":
successful_queries += 1
total_query_time += result["time_seconds"]
else:
failed_queries += 1
print("=" * 60)
print(f"Successful queries: {successful_queries}/22")
print(f"Failed queries: {failed_queries}/22")
print(f"Total query execution time: {total_query_time:.2f} seconds")
print(f"Total benchmark time: {total_time:.2f} seconds")
print("=" * 60)
return all_results
def main():
parser = argparse.ArgumentParser(description="Run TPC-H on Iceberg (Glue catalog)")
parser.add_argument("--catalog", default="glue", help="Iceberg catalog name (default: glue)")
parser.add_argument("--database", default="postgres_postgres_tpch", help="Glue database name containing TPC-H tables")
parser.add_argument("--warehouse", default=os.environ.get("ICEBERG_WAREHOUSE"), help="S3 warehouse path, e.g., s3://bucket/warehouse/")
parser.add_argument("--region", default=os.environ.get("AWS_REGION"), help="AWS region for Glue/S3 (optional)")
parser.add_argument("--shuffle-partitions", type=int, default=64, help="spark.sql.shuffle.partitions")
args = parser.parse_args()
spark = build_spark_session(
app_name="TPC-H Iceberg Benchmark",
catalog=args.catalog,
warehouse=args.warehouse,
region=args.region,
)
configure_spark_settings(spark, args.shuffle_partitions)
queries = build_queries(args.catalog, args.database)
_ = run_all_tpch_queries(spark, queries)
if __name__ == "__main__":
main()
Spark submit used to run the TPC-H queries for Iceberg:
Show spark submit code — Iceberg
spark-submit --packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1,org.apache.iceberg:iceberg-aws-bundle:1.6.1 --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.glue=org.apache.iceberg.spark.SparkCatalog --conf spark.sql.catalog.glue.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.glue.io-impl=org.apache.iceberg.aws.s3.S3FileIO --conf spark.sql.catalog.glue.client.region=ap-south-1 --conf spark.sql.catalog.glue.warehouse=s3://dz-olake-testing/tpch_data/ --conf spark.sql.adaptive.enabled=true --conf spark.sql.adaptive.coalescePartitions.enabled=true --conf spark.sql.adaptive.skewJoin.enabled=true --conf spark.sql.autoBroadcastJoinThreshold=64m --conf spark.sql.files.maxPartitionBytes=64m --conf spark.sql.adaptive.shuffle.targetPostShuffleInputSize=64m --conf spark.sql.shuffle.partitions=256 --conf spark.sql.iceberg.vectorization.enabled=false --conf spark.sql.parquet.enableVectorizedReader=false --conf spark.executor.cores=4 --conf spark.executor.memory=12g --conf spark.executor.memoryOverhead=6g --conf spark.reducer.maxReqsInFlight=4 --conf spark.reducer.maxBlocksInFlightPerAddress=1 --conf spark.reducer.maxSizeInFlight=32m --conf spark.executor.extraJavaOptions="-Darrow.enable_unsafe_memory_access=false -Darrow.enable_null_check_for_get=true" --conf spark.driver.extraJavaOptions="-Darrow.enable_unsafe_memory_access=false -Darrow.enable_null_check_for_get=true" --conf spark.executorEnv.AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID --conf spark.executorEnv.AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY --conf spark.executorEnv.AWS_SESSION_TOKEN=$AWS_SESSION_TOKEN --conf spark.executorEnv.AWS_REGION=$AWS_DEFAULT_REGION --conf spark.yarn.appMasterEnv.AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID --conf spark.yarn.appMasterEnv.AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY --conf spark.yarn.appMasterEnv.AWS_SESSION_TOKEN=$AWS_SESSION_TOKEN --conf spark.yarn.appMasterEnv.AWS_REGION=$AWS_DEFAULT_REGION /home/hadoop/tpch_iceberg_benchmark.py --catalog glue --database "postgres_postgres_tpch" --region ap-south-1 --warehouse s3://dz-olake-testing/tpch_data/ --shuffle-partitions 128
The results are as follows:
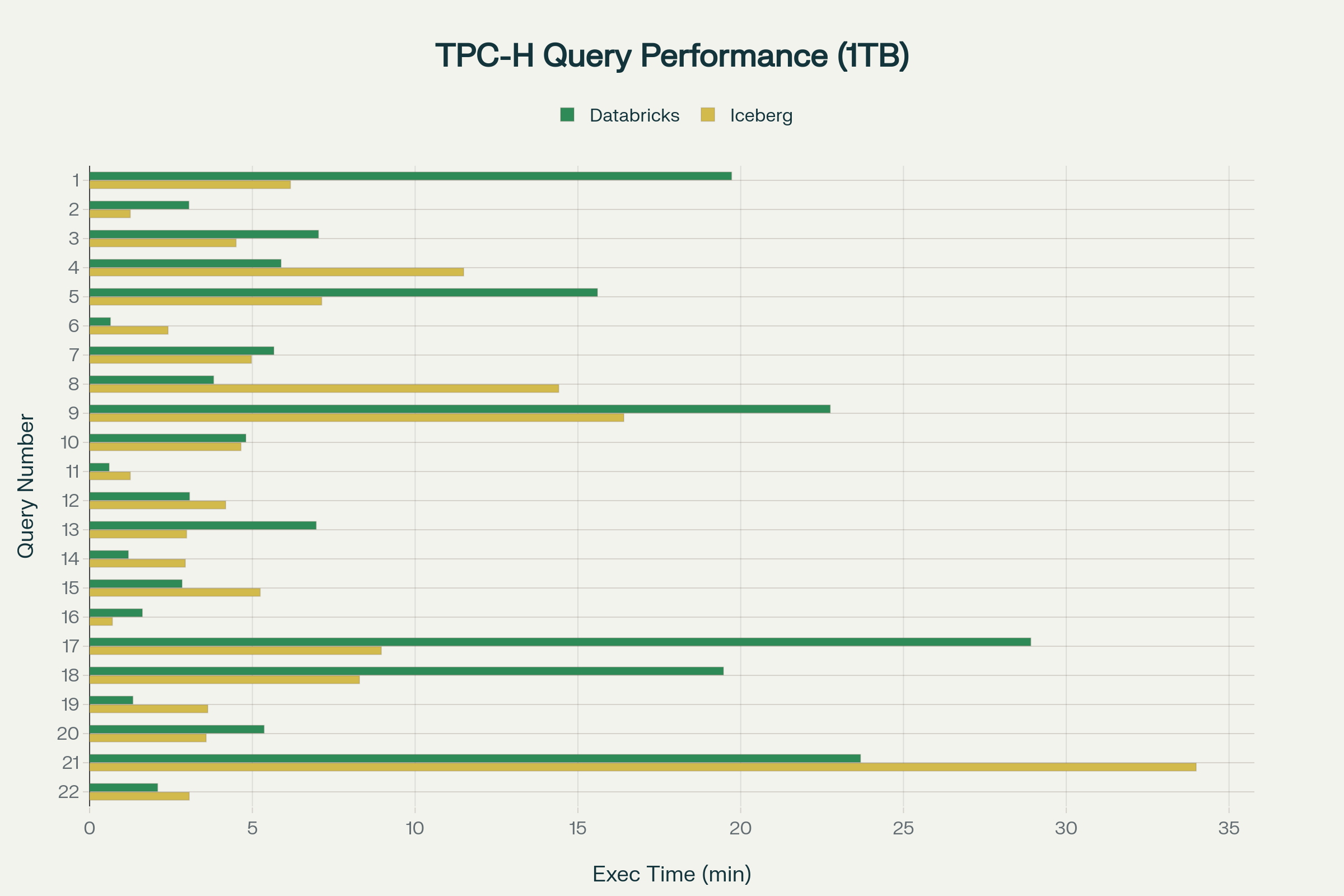
The Overall Picture
When the dust settled after running 8.6 billion rows through 22 complex analytical queries, the headline numbers told an interesting story:
-
Databricks Total Time: 11,163.94 seconds (186.07 minutes / 3.1 hours)
-
Iceberg Total Time: 9,132.47 seconds (152.21 minutes / 2.54 hours)
-
Time Difference: 2,031.47 seconds (33.86 minutes)
-
Overall Improvement: Iceberg finished 18.2% faster
Breaking Down Performance by Query Category
To understand what drives these performance differences, we need to look beyond individual query times and examine how each platform handles different categories of analytical workloads.
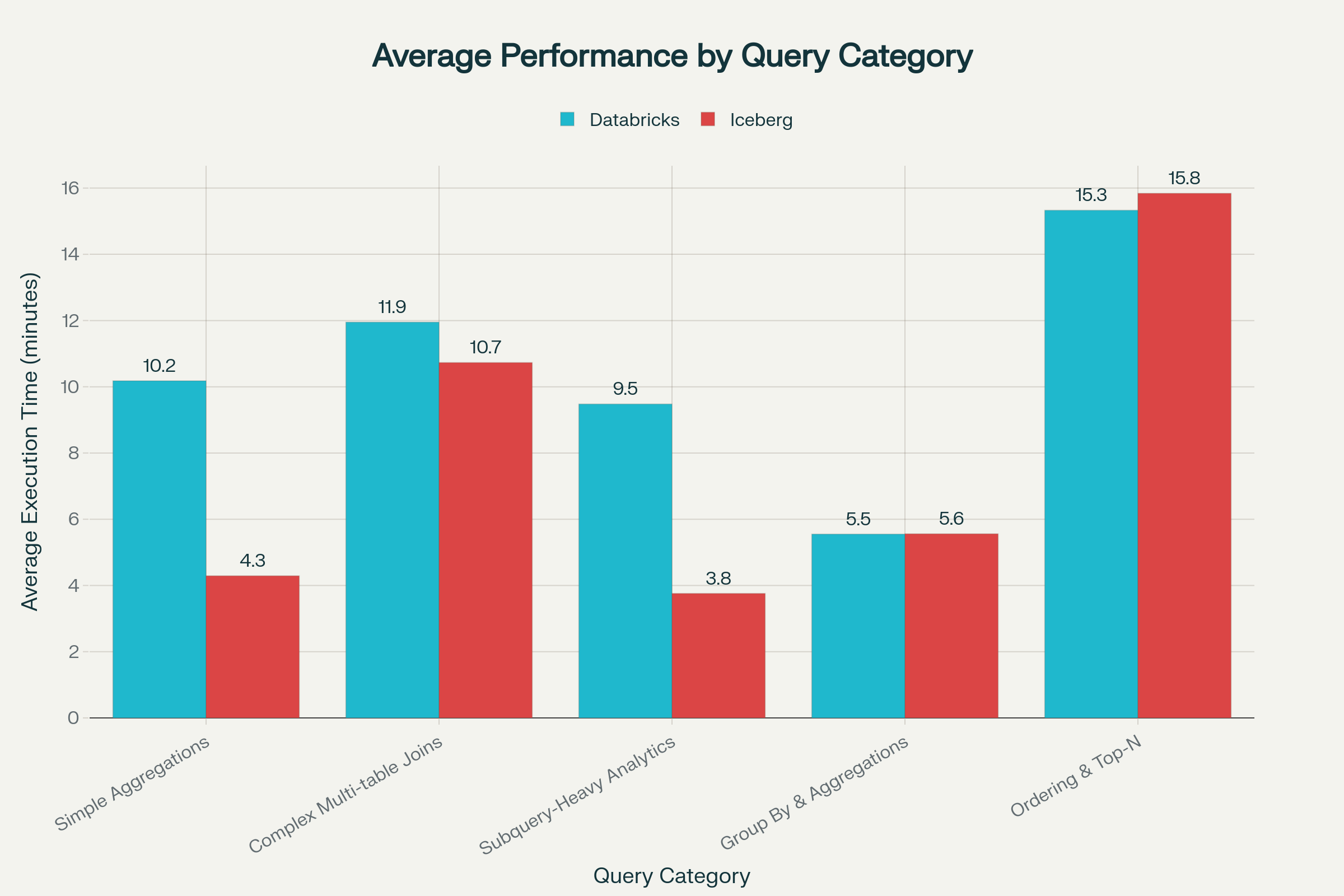
The table below provides the time taken by respective environments to finish specific query category of the TPCH queries:
| Query Category | Databricks | Iceberg | Conclusion |
|---|---|---|---|
| Simple Aggregations (Q1, Q6) | 10.18 minutes | 4.29 minutes | Iceberg is 57.9% faster. |
| Complex Multi-Table Joins (Q5, Q7, Q8, Q9) | 11.95 minutes | 10.73 minutes | Iceberg is 10.2% faster. |
| Subquery-Heavy Analytics (Q2, Q11, Q17, Q20) | 9.48 minutes | 3.76 minutes | Iceberg is 60.3% faster. |
| Group By & Aggregations (Q3, Q4, Q10, Q12, Q13) | 5.55 minutes | 5.56 minutes | Databricks is 0.2% faster. |
| Ordering & Top-N Queries (Q15, Q18, Q21) | 15.33 minutes | 15.84 minutes | Databricks is 3.3% faster. |
Analyzing the performance across various query categories, it’s evident that Iceberg not only excels in overall performance but also significantly outperforms Databricks in most individual categories. In the few cases where Databricks does perform better, the margin is minimal and the results are quite close.
Memory Utilization:
Beyond query performance metrics, analyzing memory utilization patterns on both platforms is equally important to understand how effectively each environment leverages its provisioned resources during workload execution.
- Databricks
- Iceberg
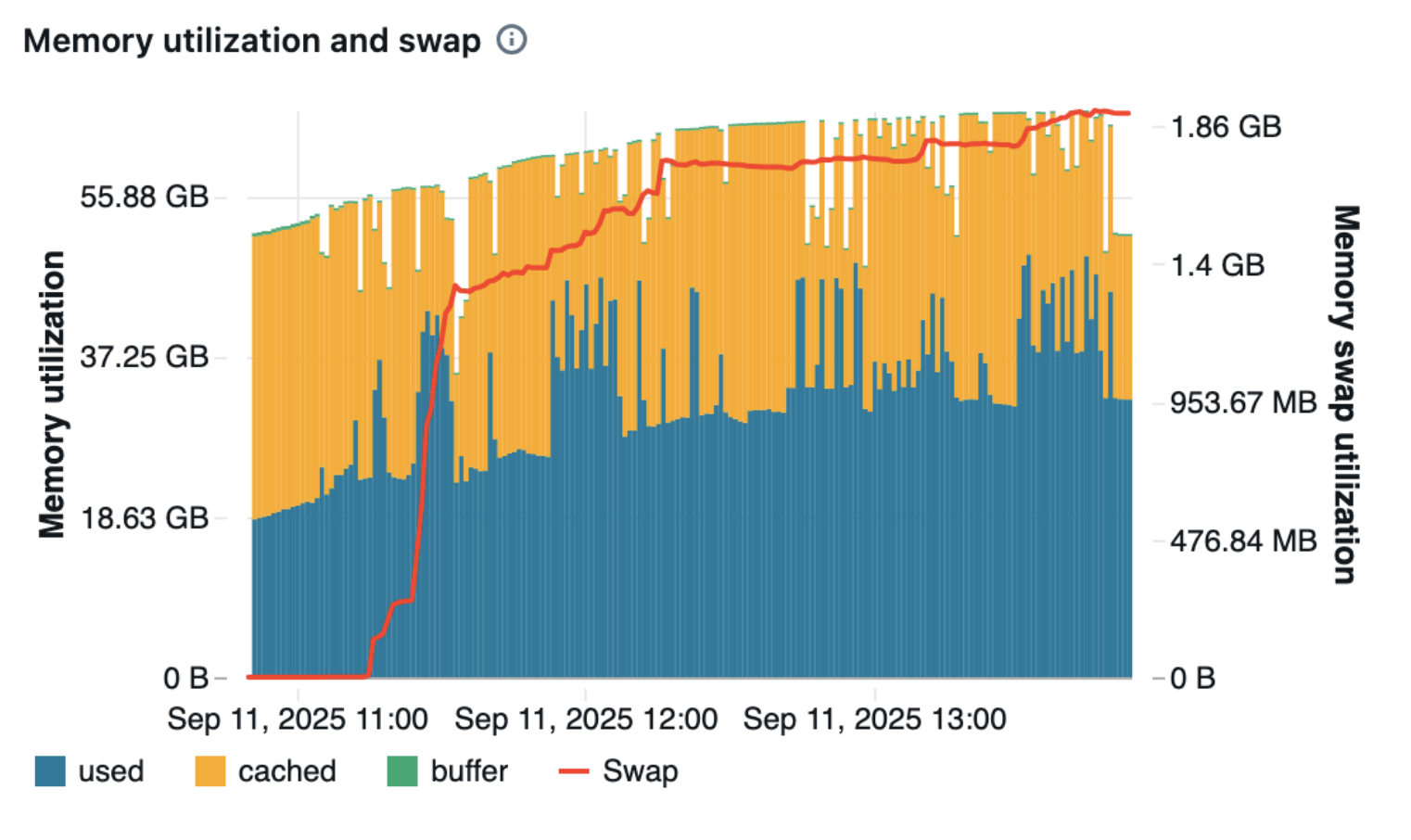
The cluster maintained a stable memory utilization between ~35–55 GB during the TPCH query execution.
The cluster spiked at first and then maintained a stable memory utilization during the complete TPCH query execution.
The Complexity Hypothesis: Where Does Each Platform Excel?
If your workload mainly involves simple, fast queries, Databricks is the better choice — it consistently delivers quicker results for lightweight operations.
However, if you’re running complex, long-running queries, Iceberg clearly takes the lead, performing about 38% faster on average.
Chapter 5: The Cost of Performance
Raw query execution time tells only part of the performance story. In cloud environments where you pay for every compute hour, resource efficiency matters as much as speed. A faster query that consumes significantly more resources may actually cost more to run—but as we'll see, that's not what happened here.
Our benchmark revealed a fascinating outcome: Iceberg finished 18.2% faster AND cost 83% less to run. Let's break down the numbers.
Databricks used 2 worker nodes throughout the benchmark, while Iceberg utilized all 3 core nodes from start to finish. This configuration difference—2 workers vs 3—might suggest higher resource consumption for Iceberg, but the actual cost story is dramatically different.
Cost Analysis: The Surprising Winner
1. Databricks Total Cost: $56.33
-
i. Data Transfer Cost:
- n2-standard-32 (@ $1.55/hr): $1.55 × 25.7 hours = $39
- 1 node × 0.4 DBU/hr × $0.55/DBU × 25.7 hours = $5.65
-
ii. TPCH Query Execution Cost:
- GCP Compute Cost: $9.63
- Master node (n2-standard-32 @ $1.55/hr): $1.55 × 3.10 hours = $4.80
- Worker nodes (2x n2-standard-16 @ $0.78/hr each): $0.78 × 2 × 3.10 hours = $4.83
- Databricks Platform Fee (DBUs):
- 3 nodes × 0.4 DBU/hr × $0.55/DBU × 3.10 hours = $2.05
- GCP Compute Cost: $9.63
2. Iceberg Total Cost: $21.95
-
i. Data Transfer Cost:
- Standard_D32s_v6 (@ $1.61/hr): $1.61 × 12 hours = $20
-
ii. TPCH Query Execution Cost:
- AWS EMR Cost (EC2 + EMR fees included): $1.95
- Master node (m6g.8xlarge) @ $0.308/hr: $0.308 × 2.54 hours = $0.78
- Core nodes (m6g.4xlarge) (3x @ $0.154/hr each): $0.154 × 3 × 2.54 hours = $1.17
- AWS EMR Cost (EC2 + EMR fees included): $1.95
The Verdict: Iceberg cost $34.38 less per benchmark run—that's 61% cheaper than Databricks while delivering 18.2% faster execution.
Production Impact: When Small Differences Become Big Numbers
For a single benchmark run, the $34.38 difference feels negligible. But extrapolate to production workloads, and the math becomes compelling:
Processing 1TB of TPC-H-equivalent analytics daily we can get to see the numbers increasing drastically.
| Platform | Daily | Monthly | Yearly |
|---|---|---|---|
| Databricks | $56.33 | $1689.90 | $20,278.80 |
| Iceberg | $21.95 | $658.50 | $7,902.00 |
Annual Savings with Iceberg: $12,376.80
These numbers assume you're running the exact benchmark "once" daily! Real-world workloads vary, but the magnitude of the cost difference remains.
Chapter 6: The Verdict
Considering both the cost and time taken for transferring data from the source to the destination, as well as executing the TPC-H benchmark queries, the comparative results are summarized below:
| Metric | Databricks | Iceberg + OLake | Conclusion |
|---|---|---|---|
| Data Transfer Speed | 25.7 hours | 12 hours | OLake is 2.1x faster. |
| Data Transfer Cost | $39 | $20 | OLake is 49% cheaper. |
| TPC-H Query Speed | 186 minutes | 152 minutes | Iceberg is 22% faster. |
| TPC-H Query Cost | $11.68 | $1.95 | Iceberg is 83% cheaper. |
| Total Cost | $50.71 | $21.96 | Iceberg+OLake is 57% cheaper. |
| Total Time | 28.8 hours | 14.53 hours | Iceberg+OLake is 49.55% faster. |
Overall, when evaluating both environments across the critical dimensions of cost efficiency, transfer speed, and query performance, the results indicate a clear operational advantage for one setup in terms of both time and monetary investment. These findings establish a strong baseline for future scalability and optimization decisions.
The Honest Assessment
Databricks' unified platform genuinely does reduce operational complexity. Managing Spark clusters, Glue Catalogs, and S3 configurations requires expertise that many teams don't have. That operational complexity has real cost.
But if your team can manage that complexity—or if you use managed services like AWS Glue or Databricks' own Iceberg support—Iceberg's 61% cost advantage combined with 18.2% faster query execution creates a compelling case.
The choice isn't about which platform is "better." It's about which trade-off aligns with your constraints: simplicity vs. efficiency, unified integration vs. cost optimization, managed convenience vs. hands-on control.
For now, our benchmark gives you data to inform your decision. Test with your actual workloads, evaluate your team's expertise, and choose the platform that unblocks your business.
Because the best data platform isn't the fastest or cheapest—it's the one your team can successfully operate that delivers business value.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.