All about Iceberg Partitioning and Partitioning Writing Strategies

Ever wondered how partitioning in big table formats like Apache Iceberg works out? And what partitioned writing strategies Iceberg can assist you with during ETL? Iceberg handles data partitioning very differently from any other data lake format (hive paritioning).
In this blog, we will dive into:
- How Iceberg partitioning works?
- Streaming Partitioned File Writing Strategies: Fanout Writer and Partitioned Fanout Writer
- Ordered Partitioned File Writing Strategies: Clustered Writer and Partitioned Writer
Whether you’re exploring Iceberg, understanding how Iceberg handles partitioning during ETL, or understanding the file writing strategies, this blog will get you covered.
What is a Partition Specification?
Iceberg stores information about Partitioning in terms of PartitionSpec. What do we actually mean when we say PartitionSpec, we mean something like this.
{
"spec-id": 1,
"fields": [
{
"source-id": 1,
"field-id": 1000,
"name": "country",
"transform": "identity"
}
]
}
This is how it looks like in a metadata.json file.
The spec-id helps track the specific partition specification used, particularly when partition evolution is involved. The field-id by default starts from 1000, others being column name and the specific transform to generate the partition value from the column. We won’t be talking about the multiple transforms that Iceberg supports, as this blog is more focused on the deeper engineering aspects of Iceberg. These four fields altogether represent a PartitionField.
A PartitionField defines one rule on how to transform a column into a partition value like, extracting year from timestamp or bucketing user ids into 10 groups. Ultimately, all these rules sum up to generate a PartitionKey which represents the location where the data gets stored for that particular partition.
How Partitioning Works During Query Execution
Let’s take a real world SQL query
SELECT * FROM orders WHERE order_date >= '2024-06-01' AND order_date < '2024-06-15'
AND region IN ('US', 'EU') AND order_amount > 1000
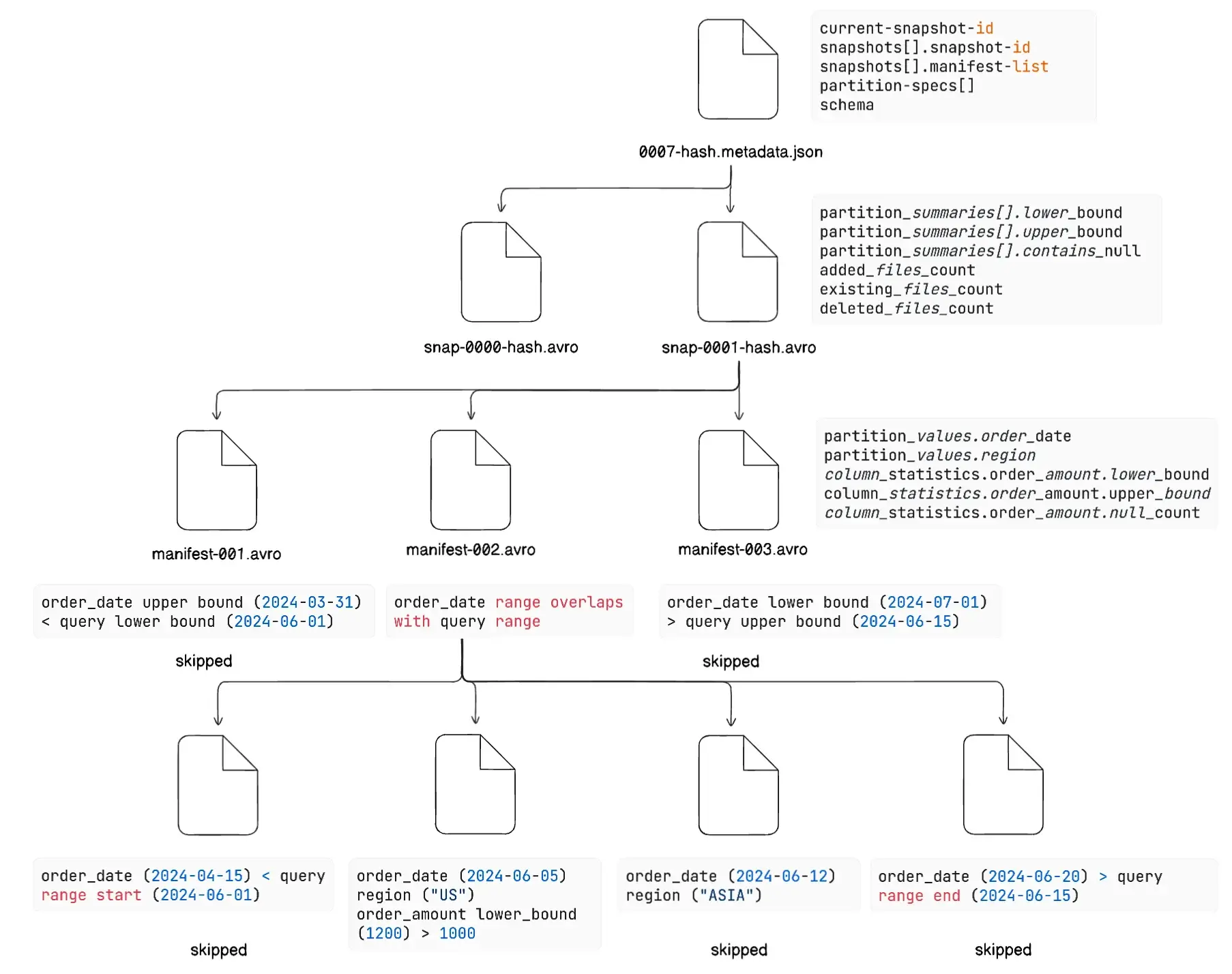
The query engine reads the latest metadata.json, and identifies the current snapshot-id and retrieves the snapshot’s manifest-list location. Then loads the partition specification to understand the partitioning, here [order_date, region] from the metadata along with the schema of the table.
- Here
0007-hash.metadata.jsondepicts the most recent state of the table, and in case you are familiar with using Apache Iceberg, you should know that0000-hash.metadata.jsonis created when the table is first initialised.
Then it moves on to read the manifest-list, its current snapshot, here snap-0001-hash.avro. It provides it with the high-level statistics for each manifest file. The engine examines partition bounds i.e., lower_bound and upper_bound, across all partitions in that manifest.
Practically it asks a question like, Does this manifest contain any partitions with order_date between '2024-06-01' and '2024-06-15'? Does this manifest contain any partitions with region in ('US', 'EU')? Along with it, it examines other parameters including added_data_files_count, existing_data_files_count, and deleted_data_files_count as well as the records count.
Here,
manifest-001.avro:order_dateupper bound (2024-03-31) < query lower bound (2024-06-01) thus skippedmanifest-002.avro:order_daterange overlaps with query range (kept)manifest-003.avro:order_datelower bound (2024-07-01) > query upper bound (2024-06-15), skipped
Now here, you should understand that without even reading each manifest file individually, we decide which manifest file to move forward with by reading its statistics from the manifest list. This is a very important concept in Iceberg partitioning because of its rich metadata nature, we will talk about it a bit more as we move down.
The manifest-002.avro includes each data file path along with metadata, partition values of every specific data file, its column level statistics for each column and the record count for each data file.
Here,
data-file-001.parquet:order_date(2024-04-15) < query range start (2024-06-01) thus, skippeddata-file-002.parquet:order_date(2024-06-05) within range,region(US) in (US, EU),order_amountlower_bound (1200) > 1000, all records > 1000, thus keptdata-file-003.parquet:order_date(2024-06-12) within range butregion(ASIA) not in (US, EU), thus skippeddata-file-004.parquet:order_date(2024-06-20) > query range end (2024-06-15) thus skipped
Again, you see that without even reading individual data-file-n.parquet file, we decide whether to read it or to skip it. This is called Partition Pruning, an extremely important partitioning feature of Iceberg as it gifts it with huge efficiency gains. As, here itself, you can see it reads only 1 data file out of all 4 data files, trust me, this comes out to be a huge boon in production level.
Along with it, there is a very important concept of Scan Planning with filters like bloom which transforms the SQL query into a highly optimised, parallel execution plan, but that would go out of scope for this blog, so won’t be discussing about it.
Real World Scale: Manifest Explosion
In real world, tables are mostly partitioned with queries having filters on these partitioned columns. This would lead to reading all manifest files (with tables having ton of manifests). Pinterest mentioned that they had a use case to list all partition of a table within 10 seconds in the UI.
To solve such scenarios, Iceberg provides Table level NDV with the help of Puffin Files, for column level statistics with blob type apache-datasketches-theta-v1.
Writing Strategies in Apache Iceberg
Fanout Writer| streaming data

It is a concurrent writing strategy, that can maintain multiple file writers open for every unique PartitionSpec and partition combination. It can handle multi-spec, multi-partition scenarios where data can belong to different partition specifications (due to Partition Evolution) and different partition values within those specs.
For each unique PartitionSpec and partition combination, the system creates a dedicated Rolling Data Writer. All writers remain active and open until they are explicitly closed. This strategy consumes higher memory with each writer maintaining write buffers, compression streams, and metadata builders but, this eliminates need for data pre-sorting, a very crucial advantage for streaming data coming in.
Partitioned Fan Out Writer | streaming data
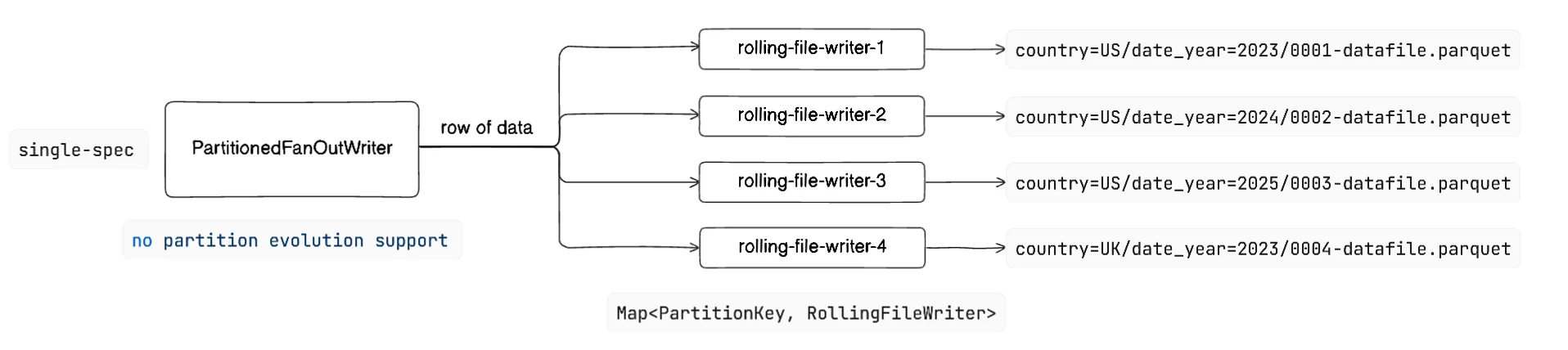
It is a concurrent writing strategy as well that operates within the constraints of a fixed partition specification while maintaining simultaneous open file writers for every unique partition value combination encountered during data ingestion. It provides no partition evolution support, and uses PartitionKey based routing.
It creates a dedicated Rolling File Writer for each PartitionKey and maps it into a data structure Map<PartitionKey, RollingFileWriter>. It has a linear memory growth with active partitions count, but this as well, eliminates the need for data being ordered and is ideal for streaming data but with no schema evolution or partition specification changes.
Clustered Writer | ordered data

It is a memory-efficient, sequential partition writing strategy that operates under the fundamental constraint of pre-clustered data ordering. This represents a low-memory, high-throughput approach optimised for scenarios where incoming data is already sorted by partition specification and partition values, enabling single-active-writer semantics with minimal memory footprint.
With each spec, all records belonging to the same partition value combination must be contiguous. It has O(1) memory usage regardless of partition count with only one file handle and buffer active at any time and supports PartitionSpec evolution through multi-spec capability, but it requires upstream clustering/sorting of data and cannot handle streaming data.
Partitioned Writer | ordered data

It is a single-specification, sequential partition writing strategy that operates within the constraints of a fixed partition specification while enforcing strict partition clustering requirements. This represents a memory-efficient, ordered-data approach optimized for scenarios where incoming data is pre-sorted by partition values within a single partition specification, enabling sequential partition processing with partition boundary validation.
It cannot handle partition specification evolution during writing session. It has only one RollingFileWriter active per partition at any time
Thus summarising,
| Requirement | Partitioned Writer | Clustered Writer | Fanout Writer | Partitioned Fanout Writer |
|---|---|---|---|---|
| Schema Evolution | Acceptable | Optimal | Optimal | Acceptable |
| Partition Evolution | Not Suitable | Optimal | Optimal | Not Suitable |
| Memory Efficiency | Optimal | Optimal | Not Suitable | Not Suitable |
| Random Data Order | Not Suitable | Not Suitable | Optimal | Optimal |
| High Partition Count | Optimal | Optimal | Not Suitable | Not Suitable |
| Streaming Workloads | Not Suitable | Not Suitable | Optimal | Optimal |
| Maximum Flexibility | Not Suitable | Acceptable | Optimal | Acceptable |
Wrapping Up
Partitioning is the heart of Iceberg’s performance, scalability, and metadata efficiency.
Whether you're querying massive datasets or writing from high-volume streams, Iceberg's PartitionSpec, Manifest Lists, and Writing Strategies give you the tools to build highly optimised data pipelines.
And remember: all of this happens without you having to worry about folders, MSCK repairs, or schema breakage.
Happy engineering!
Further Reading:
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.