Merge-on-Read vs Copy-on-Write in Apache Iceberg


If you're working with big data, you've probably heard about Apache Iceberg. But what makes it special, and why should you care about its different table formats?
Let's dive into how Iceberg handles data modifications, particularly focusing on a game-changing feature: equality deletes.
The Basics: Iceberg's Architecture
Apache Iceberg is built on a smart three-layer architecture that makes handling big data efficient and flexible. Each layer has a clear role, working together to enable features like time travel and schema evolution.
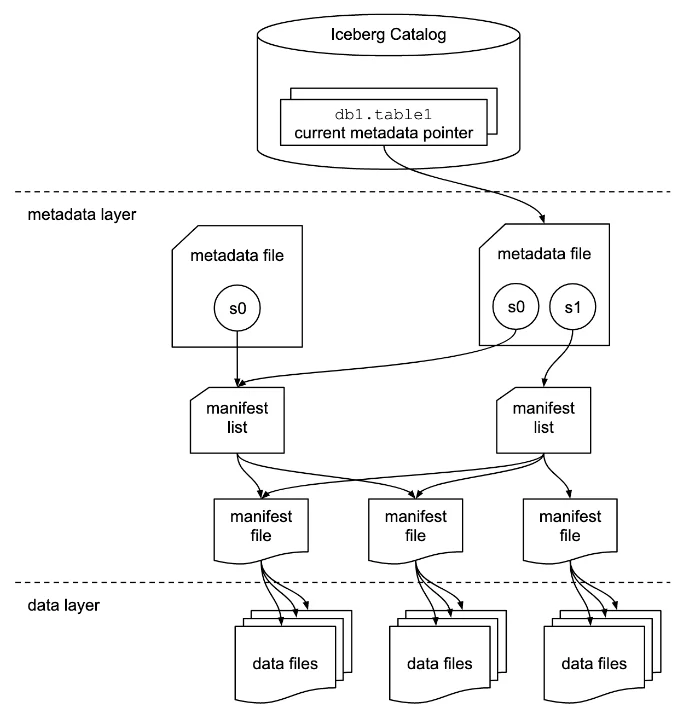
Image Credit: Apache Iceberg Documentation
1. The Catalog Layer: Your Data's Control Centre
Think of the catalog layer as the brain of your Iceberg table. It tracks the current state of your data using a single metadata pointer, always pointing to the latest snapshot.
This layer ensures atomicity, meaning your changes (updates or deletes) are either fully applied or not visible at all—critical for consistent results in high-concurrency environments.
2. The Metadata Layer - Your Data's Map
The metadata layer keeps detailed records of your table’s structure and history, enabling Iceberg’s advanced features:
- Metadata Files: Store table schema, partitioning, and snapshots.
- Manifest Lists: Index snapshot details like file locations and partition boundaries.
- Manifest Files: Contain detailed stats and file-level information for efficient query pruning and filtering.
This system ensures fast and targeted data retrieval without unnecessary scans.
3. The Data Layer: Your Data’s Foundation
The data layer holds your actual files, stored in formats like Parquet, ORC, or Avro. Unlike traditional systems, Iceberg tracks individual files rather than just partitions.
Modifications create new files instead of altering existing ones. This design enables concurrent reads and writes without locking, as writers generate new snapshots while readers access older ones seamlessly.
Two Approaches to Data Updates: COW vs MOR
When working with Apache Iceberg tables, you'll need to choose how your table handles row-level modifications. Copy-on-Write (COW) is the default approach, and it prioritises read performance over write efficiency.
Copy-on-Write (COW)
Think of COW as the "immediate cleanup" approach.
How Copy-on-Write Works
In Copy-on-Write, when you update or delete even a single row in a data file, Iceberg rewrites the entire file.
For example, if you have a 1GB data file and need to update just one record, a completely new 1GB file is created containing all unchanged records plus the modified one.
The new snapshot then points to this new file, while the old file becomes obsolete.
This might sound inefficient, but it serves a specific purpose. By maintaining complete data files that reflect the current state, COW eliminates the need for read queries to perform any reconciliation or merging operations. When a query needs to read data, it can directly access the files without checking for updates or deletes elsewhere.
Performance Characteristics
Copy-on-Write offers a clear trade-off:
- Read Performance: Queries run faster because they can read data files directly without any additional processing. There's no need to check separate delete files or merge updates.
- Write Performance: Updates and deletes are slower because they require rewriting entire files, even for small changes. This can impact performance significantly if you have large files or frequent modifications.
To maintain optimal performance with COW tables, regular compaction (compaction refers to the process of rewriting and merging small files into larger, more optimized files (parquet files, here) to improve performance) is essential. This helps manage file sizes and prevents the accumulation of many small files, which could impact query performance.
Merge-on-Read (MOR)
Merge-on-Read (MOR) is more like keeping a "to-do list" of changes.
How Merge-on-Read Works
Instead of immediately rewriting data files when changes occur, Merge-on-Read uses a clever combination of delete files and incremental updates. When you delete a record, Iceberg doesn't touch the original data file at all. Instead, it creates a small delete file that essentially says, "ignore this record when reading."
Similarly, when you update a record, Iceberg creates a delete file to mark the old version as obsolete and writes only the updated record to a new data file.
This method significantly speeds up write operations since you're only writing the changes rather than rewriting entire files. However, there's a trade-off: when you query the data, Iceberg needs to do some extra work. It has to check these delete files and merge the changes with the original data to give you the current view of your data.
Understanding Delete Files
Merge-on-Read employs two different types of delete files:
- Positional Delete Files: These store the exact location of deleted records in specific files, similar to seat numbers in a theatre.
- Equality Delete Files: These store the values of deleted records, acting more like a description of what to remove.
While positional deletes are efficient to read but slower to write, equality deletes are quicker to write but require more processing during reads.
Performance Considerations
The key to maintaining good performance with Merge-on-Read tables lies in regular compaction. Over time, as more changes accumulate in delete files and new data files, query performance can start to degrade. Compaction helps by periodically combining all these changes with the base files, creating a fresh, optimised set of data files.
When to Choose Merge-on-Read
Merge-on-Read shines in scenarios where write performance is crucial. If your application needs to handle frequent updates or deletes, particularly in real-time or near-real-time scenarios, MOR might be your best choice. Common use cases include maintaining user profiles, handling streaming updates, or managing any data that changes frequently.
The Power of Equality Deletes
Here's where things get interesting. Equality deletes are a clever way to handle deletions in Iceberg v2 tables, particularly beneficial in MOR scenarios.
Understanding Equality Deletes in Apache Iceberg
Unlike tracking specific positions of records, equality deletes work by identifying rows based on their values. For example, when you delete a record with a specific order ID, the equality delete file simply stores that condition (e.g., "delete where order_id = 1234") rather than tracking where the record resides.
Sequence Numbers: Maintaining Data Consistency
Each data file and delete file in Iceberg gets assigned a sequence number. When you delete a record, the delete file receives a higher sequence number than the existing data files. This ensures that newer records aren't mistakenly deleted if they match the deletion criteria.
Real-world Performance Testing
Team at AWS conducted a MOR vs COW update, delete and select query test with queries like:
/Example update statement
update reviews.all_reviews set star_rating=5 where product_category = 'Watches' and star_rating=4
//Example delete statement
delete from reviews.all_reviews where product_category = 'Watches' and star_rating=1
//Example select statement
select marketplace,customer_id, review_id,product_id,product_title,star_rating from reviews.all_reviews where product_category = 'Watches' and review_date between date('2005-01-01') and date('2005-03-31')
The following table was their result.
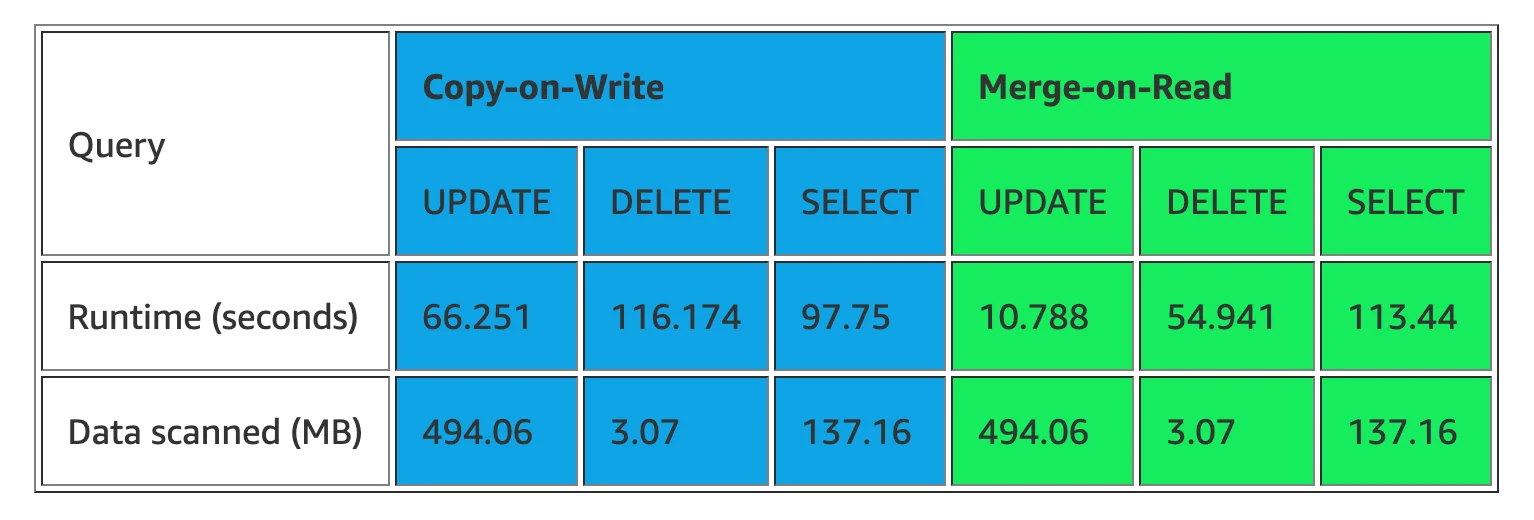
Read more about the above comparison result.
Our team at OLake also recently conducted a similar performance test comparing PostgreSQL operations with Iceberg reflection times on a substantial dataset of nearly 67 million rows.
| Operation | Rows Updated | PostgreSQL Operation Time | Iceberg Reflection Time |
|---|---|---|---|
| Small Update | 10 | 0:00:12 secs | 0:00:29 secs |
| Medium Update | 500,000 | 0:00:33 secs | 0:01:47 secs |
| Large Update | 5,000,000 | 0:11:55 mins | 0:02:05 secs |
Key Findings:
- Initial Dataset Size: 66,990,000 rows
- Scalability: Successfully handled updates from 10 to 5 million rows
- Performance Characteristics: While PostgreSQL operation time increased significantly with larger updates (from 12 seconds to nearly 12 minutes), Iceberg's reflection time remained relatively stable (only increasing from 29 seconds to about 2 minutes)
- Large-Scale Efficiency: Most impressively, for the 5-million-row update, Iceberg reflected changes in just over 2 minutes, while PostgreSQL took nearly 12 minutes
Important Implementation Notes:
- Tables must be set to REPLICATION FULL
- Users need proper REPLICATION permissions
- Primary keys are required for upsert operations (without them, only appends are possible)
Handling Upserts
Let's look at how upserts work in practice:
In COW Tables:
- Locate the file containing the record to update
- Rewrite the entire file with the updated record
- Update metadata to point to the new file
In MOR Tables with Equality Deletes:
- Create a delete file for the old record
- Write a new file containing only the updated record
- No need to touch the original file
For real-time applications dealing with millions of records, the MOR approach with equality deletes can significantly reduce write latency and improve overall system performance, as evidenced by our performance tests.
Choosing the Right Approach
Consider these factors when deciding between COW and MOR:
- Read-heavy workloads: Consider COW for better query performance.
- Write-heavy workloads: MOR with equality deletes might be your best bet.
- Real-time data requirements: MOR typically handles high-velocity writes better.
- Resource constraints: COW requires more storage and compute for writes.
Conclusion
Equality deletes in Apache Iceberg, particularly when paired with MOR, offer a powerful solution for handling real-time data modifications. The ability to handle millions of updates efficiently makes this approach ideal for high-velocity data scenarios.
While COW is better suited for read-heavy workloads, the flexibility of equality deletes provides a critical advantage for write-heavy applications. The choice between these approaches depends on your specific use case, read/write patterns, and system constraints.
Make your decision based on the needs of your application, and you'll unlock the full potential of Apache Iceberg.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.