OLake + Glue + Snowflake - A Deep Dive into Modern Data Partitioning


Sick of fighting with fragile ETL scripts or getting stuck in expensive, vendor-locked tools just to move your database data into a data lakehouse?
You’re not alone. Moving data from operational databases like MongoDB, PostgreSQL, and MySQL into modern analytics platforms shouldn’t be so difficult.
That’s why we built OLake — an open-source tool designed to be the simplest, fastest way to move data from your databases into a lakehouse built on open formats like Apache Iceberg.
OLake lets you quickly go from full data snapshots to near real-time updates. It handles large amounts of data fast, works with changing data structures, and uses open formats like Parquet and Iceberg—so you’re never locked in.
Why Iceberg?
When building OLake, picking Apache Iceberg as the output format wasn’t just a good choice — it was an obvious one. Iceberg isn’t just another way to write files to S3. It solves real problems that come with managing large-scale analytics on object storage. Here’s how:
1. Reliable Transactions
Need to update or delete rows directly in your S3 data lake? Iceberg makes that possible. It brings ACID transactions to object storage, making complex operations like CDC and ELT much more reliable and manageable than with older data lake formats.
2. Handles Schema Changes Smoothly
Data isn’t static, and your pipeline shouldn’t break when things change. Iceberg supports schema and partition evolution, so you can change table structures without rewriting all your data or breaking existing queries.
3. Consistent and Historical Data Access
Iceberg ensures consistent reads even when data is being updated, thanks to snapshot isolation. You can also roll back and query previous versions of your data — great for audits, debugging, or just re-running an old model.
4. Faster Queries
Iceberg tracks metadata in a way that lets query engines skip over files and partitions that aren’t relevant to a query. This cuts down on scanning and makes queries on large datasets much faster.
5. Open by Design
Iceberg is an open standard. You’re not locked into any one vendor or query engine. Tools like OLake for ingestion, and engines like Trino, Athena, and Spark, all work together with Iceberg tables stored in S3 — giving you full control and flexibility
This is where the combination of OLake, Apache Iceberg, AWS Glue Data Catalog, and Snowflake delivers a powerful, streamlined, and modern solution for building your data lakehouse.
- OLake: An open-source tool built for fast, lightweight, and easy data ingestion from databases like MongoDB, PostgreSQL, and MySQL.
- Amazon S3: Scalable, durable, and cost-effective object storage for your data lake.
- Apache Iceberg: A high-performance open table format that adds ACID transactions, schema evolution, and time travel to data stored in S3.
- AWS Glue Data Catalog: A centralized, managed metadata repository that serves as the Iceberg catalog, making your data on S3 easy to organize and discover.
- Snowflake: A powerful cloud-based data platform that can query Apache Iceberg tables stored in S3 directly—bringing all the performance and ease of Snowflake to your lakehouse, without duplicating data.
Together, these tools let you build an end-to-end pipeline from your operational databases to query-ready data in S3—without the need for heavy infrastructure or vendor lock-in
In this blog, we’ll explore the following steps:
- Setting up Amazon S3 and AWS Glue Data Catalog
- Ingesting Data from Databases into Apache Iceberg with OLake
- Querying Iceberg Tables with Snowflake
Step 1: Configure AWS Glue Catalog and S3 Permissions
To connect OLake to your data lakehouse destination, you need to set up the necessary AWS resources and grant OLake access:
1.1 S3 Bucket: Create a S3 bucket in your desired region. This will store the Apache Iceberg data and metadata files.
1.2 Update destination.json with AWS Glue Credentials .Ensure your configuration includes the appropriate credentials and region for Glue Catalog integration.
1.3 IAM Permissions: Create an IAM user or role for OLake. Attach a policy granting:
- S3 Access: Read, write and list permissions on your specific S3 bucket and path. Refer AWS S3 permissions for details
- Glue Catalog Access: Permissions to create, get and update tables/databases within your designated Glue database
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": [
"glue:CreateTable",
"glue:CreateDatabase",
"glue:GetTable",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:SearchTables",
"glue:UpdateDatabase",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:glue:ap-south-1:956834174860:catalog",
"arn:aws:glue:ap-south-1:956834174860:database/{AWS_GLUE_DATABASE_NAME}",
"arn:aws:glue:ap-south-1:956834174860:table/{AWS_GLUE_DATABASE_NAME}/*"
]
}
]
}
This policy allows OLake to manage data in S3 and register/update table definitions in Glue. Refer to the following doc for more details Glue Catalog Permissions
1.4 AWS Credentials: Make the credentials for this IAM identity accessible to your OLake environment (e.g., via environment variables when running Docker). OLake uses these to authenticate its AWS calls.
By setting up these basic AWS resources and granting OLake the necessary permissions, you create the destination for your database data in your S3-based Iceberg lakehouse, ready to be cataloged by Glue.
OLake integrates with AWS Glue to automatically register Iceberg tables, making them queryable in Snowflake.
Step 2: Data Ingestion from Database to Apache Iceberg Using Olake
2.1 Install Docker
Ensure Docker is installed and running on your local or cloud environment. OLake is Docker-based, making setup fast and portable
2.2 Prepare Your Database
Make sure the source database (e.g., PostgreSQL) is properly configured : Refer to the following doc link Step-by-Step Guide - Replicating PostgreSQL to Iceberg with OLake & AWS Glue
2.3 Configure OLake
You’ll need two configuration files
- source.json file with your database connection details
- destination.json file with your Writer (Apache Iceberg) connection details
You can read here for detailed version Olake Configuration
2.4 Run the Discover command to generate a streams.json file, which contains the list of available data streams from your source database. You can refer to the official OLake documentation for complete documentation
2.5 Run the Sync command to replicate data from your source database into Apache Iceberg tables stored on Amazon S3
Step 3 Setting Up Snowflake to Query Iceberg Tables via AWS Glue
External tables in Snowflake provide a way to query data stored outside of Snowflake—in cloud storage systems like Amazon S3, Azure Blob Storage, or Google Cloud Storage—without having to first load that data into the platform. Following are some of the benefits of using external tables in snowflake :
- No Data Movement : Query your data directly from cloud storage, eliminating the need for ETL pipelines or data loading processes.
- Cost Optimization : Reduce Snowflake storage costs by keeping data in your own cloud storage, paying only for compute when queries are run.
- Faster Access to Insights: Skip lengthy data loading steps and get immediate access to external datasets for analysis.
- Support for Open Formats: Work with widely adopted formats like Parquet, ORC, and Iceberg, enabling seamless integration with other tools in your data ecosystem.
- Interoperability and Flexibility: External tables make it easier to adopt a lakehouse architecture, allowing Snowflake to work alongside data lakes and other analytics engines (like Spark or Presto).
- Catalog Integration: Combine Snowflake with external metadata catalogs (e.g., AWS Glue, Hive Metastore) to manage schemas centrally and support advanced table formats like Apache Iceberg.
This approach is especially useful for organizations that maintain large datasets in data lakes and want to analyze them using Snowflake’s powerful SQL engine without duplicating or moving the data.
Similarly, Iceberg tables store both data and metadata externally, typically in cloud object storage. With Snowflake’s support for external volumes, you can query Iceberg tables directly, leveraging Snowflake’s performance while benefiting from open table formats and flexible storage. You can read more here External Tables in Snowflake.
Since we're using Olake to ingest data into Iceberg and managing metadata through the AWS Glue Catalog, Snowflake recognises these as external tables. To query them, we first need to mount the underlying storage as an external volume in Snowflake.
3.1. Configure an external volume
An external volume in Snowflake is an account-level object that lets you connect to your cloud storage— like Amazon S3—for working with Iceberg tables. It holds the IAM role or credentials snowflake needs to securely access your data, including table files, metadata, and manifests that define schema, partitions, and other table info. One external volume can be used for multiple Iceberg tables. You’ll need to set it up before creating any Iceberg tables in Snowflake.
CREATE OR REPLACE EXTERNAL VOLUME s3_iceberg_volume
STORAGE_LOCATIONS = (
(
NAME = 'iceberg-data-location'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL ='s3://bucket_name/' -- Optional: specify a base path
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::<account_id>:role/<role_name>'
STORAGE_AWS_EXTERNAL_ID = 'dummy_external_id' -- This will be updated
)
)
To check if the volume got created use this command:
DESCRIBE EXTERNAL VOLUME s3_iceberg_volume
If the volume got created successfully, you should be able to see an output like this :
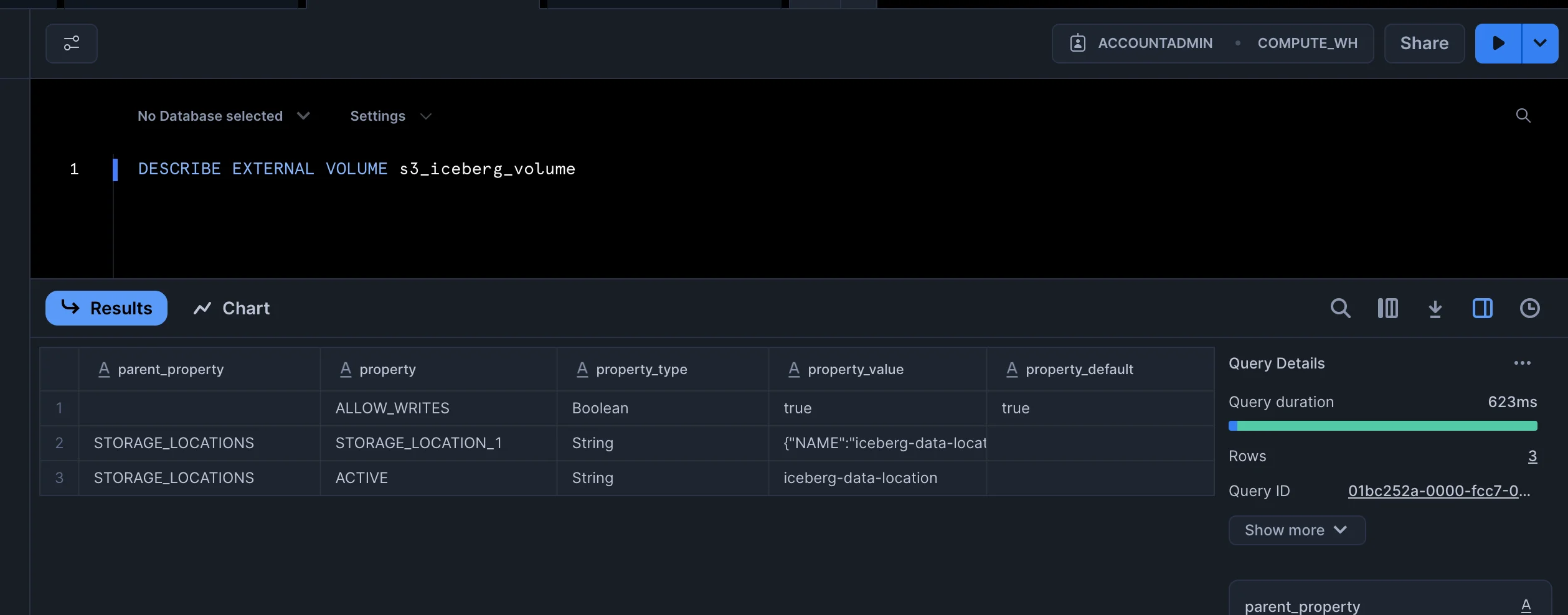
Copy the following from the output:
STORAGE_AWS_IAM_USER_ARNSTORAGE_AWS_EXTERNAL_IDYou will need to pass these values in IAM AWS trust policy created in Step 1.- Finish IAM Role Trust Policy (Back in AWS)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "<STORAGE_AWS_IAM_USER_ARN>"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "<STORAGE_AWS_EXTERNAL_ID>"
}
}
}
]
}
For more details you can refer to the following IAM Policy
3.2 Create a Catalog Integration
The CREATE CATALOG INTEGRATION command in Snowflake is used to create or replace a catalog integration for accessing Apache Iceberg tables. Snowflake supports the following external catalog types:
- Using AWS Glue as the Iceberg catalog
- Using object storage directly as the catalog
- Using Snowflake's Open Catalog
- Using the Apache Iceberg™ REST Catalog
We will be using the AWS Glue Catalog as the Iceberg Catalog
CREATE OR REPLACE CATALOG INTEGRATION glueCatalogInt
CATALOG_SOURCE = GLUE
CATALOG_NAMESPACE = '<database name where ingested tables are present in glue>'
TABLE_FORMAT = ICEBERG
GLUE_AWS_ROLE_ARN = 'arn:aws:iam::<aws account_id>:role/<role_name>'
GLUE_CATALOG_ID = '<aws account_id>'
GLUE_REGION = '<aws region>'
ENABLED = TRUE;
Once the catalog is created you can run the following command to check if the catalog has been created successfully :
DESCRIBE CATALOG INTEGRATION glueCatalogInt
You should see the output as shown below:
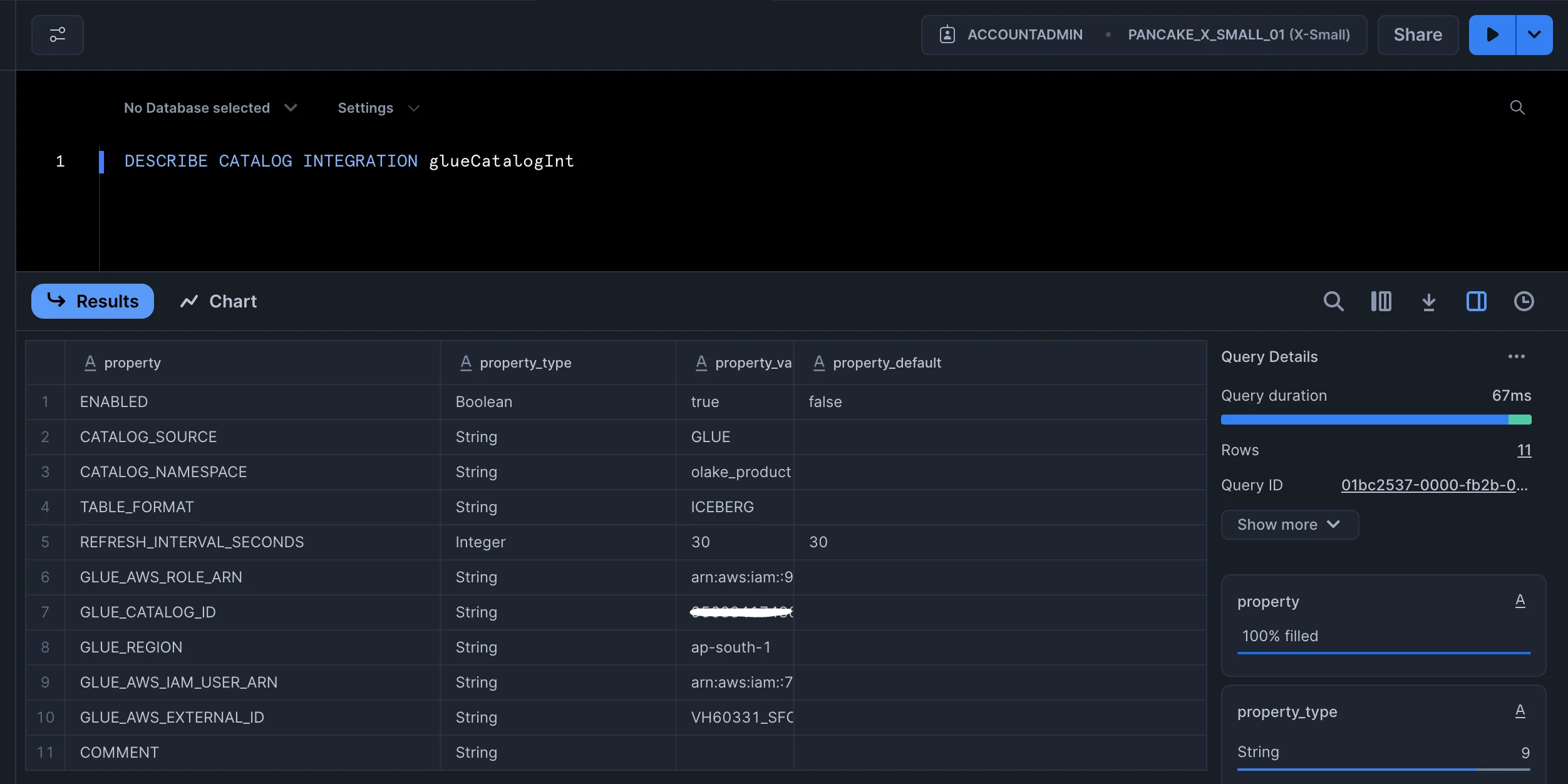
Copy the following from the output:
STORAGE_AWS_IAM_USER_ARNSTORAGE_AWS_EXTERNAL_IDYou will need to pass these values in trust policy just as in the previous step.
3.3 Creation of iceberg tables in snowflake
Iceberg tables can be created as follows
CREATE OR REPLACE ICEBERG TABLE <database_name>.<iceberg_table_name>
EXTERNAL_VOLUME = 's3_iceberg_volume'
CATALOG = 'GLUECATALOGINT'
CATALOG_TABLE_NAME = '<actual table in glue>'; -
Now you should be able to query this table in snowflake
3.4 Query the snowflake table
SELECT * FROM <database_name>.<iceberg_table_name>
You will be able to see the following query output as below :
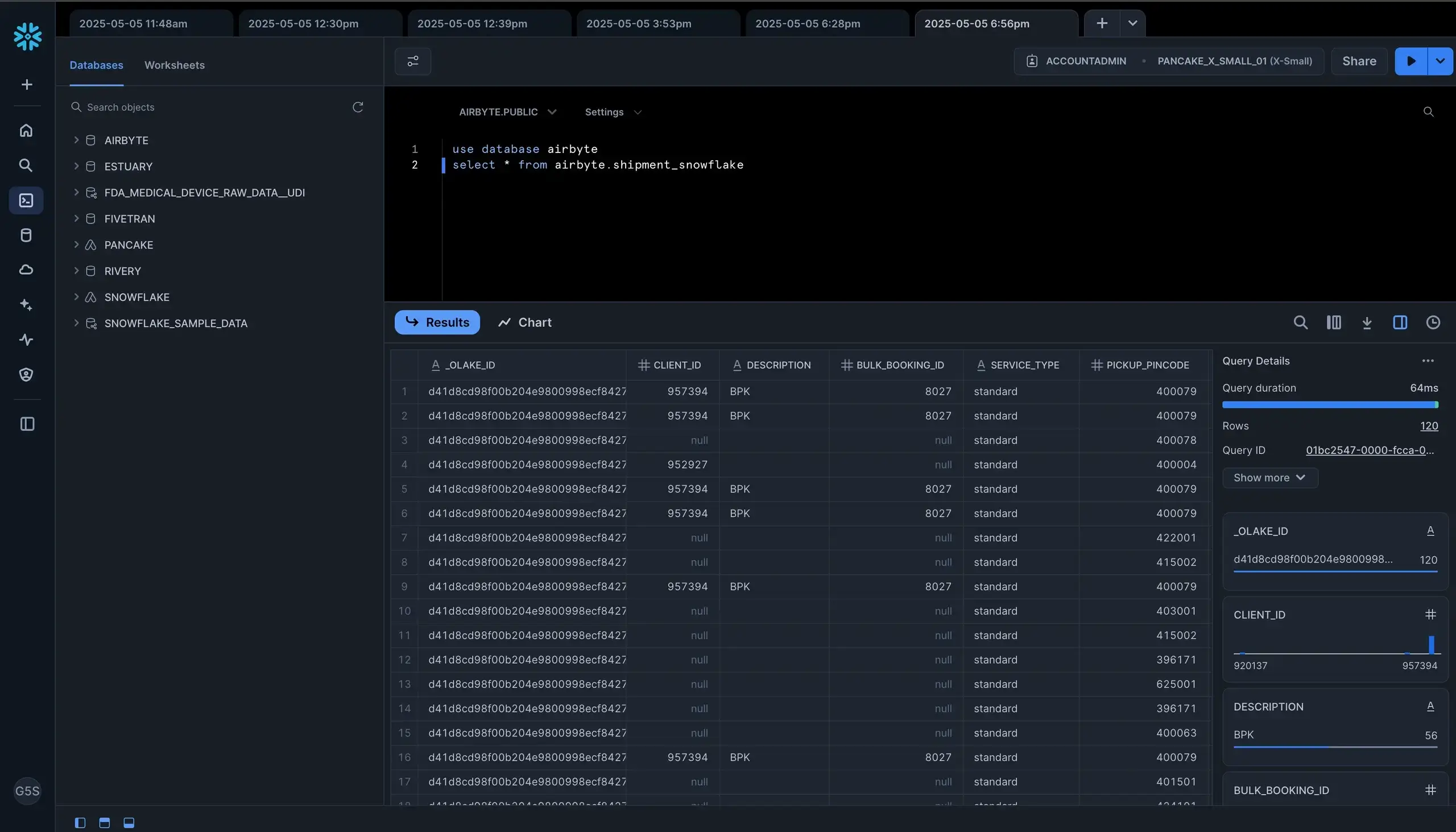
Ingesting data from databases into a data lake doesn’t have to be complicated. With OLake handling the ingestion, Iceberg adding structure, Glue managing the metadata, and Snowflake for querying, you can build a reliable setup without a lot of overhead. This combination gives you flexibility, keeps costs low, and makes your S3 data easy to work with. It offers a practical way for teams to modernize their data infrastructure while maintaining efficiency and ensuring long-term scalability.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.