OLake for Simple Iceberg Ingestion using Glue Catalog, Athena for Query


Tired of wrestling with brittle ETL scripts or complex, vendor-locked tools just to get your valuable database data into your modern data lakehouse? Moving data from operational databases to analytics platforms built on open formats like apache iceberg shouldn't be a source of toil and frustration.
Welcome to OLake – the open-source tool purpose-built to be the fastest, cleanest pipeline for this exact challenge, starting with MongoDB, Postgres and MySQL. Born from the need to eliminate performance bottlenecks and avoid vendor lock-in, OLake empowers you to transition seamlessly from initial snapshots to near real-time change data capture (CDC), achieve high throughput with parallel processing, adapt gracefully to schema changes, and keep your data truly open in formats like Parquet and Apache Iceberg. Ready to unlock your database data for high-performance analytics in a modern lakehouse?
Let's dive in.
Why Iceberg ?
When designing Olake, choosing Apache Iceberg as the destination format was a clear decision. Why? Because Iceberg isn't just another way to put files in S3; it's a leap forward that brings much-needed reliability and advanced capabilities to data lakes. Many in the industry see iceberg as the future standard for data engineering because it tackles fundamental challenges when working with data on object storage head-on:
1. Reliable Transactions:
Imagine performing atomic UPDATE or DELETE operations directly on your S3 data lake. Iceberg makes this possible by embedding ACID properties at the file layer, simplifying complex CDC and ELT patterns that were previously cumbersome and unreliable with traditional data lake formats.
2. Handling Evolving Data:
Data pipelines often break when schemas change. Iceberg provides built-in, robust mechanisms for schema evolution and partition evolution, allowing your data to adapt over time without requiring painful manual interventions or full data migrations.
3. Consistent Data Access:
Concurrent reads and writes can cause inconsistencies. Iceberg's snapshot system guarantees snapshot isolation for consistent reads and even lets you easily "time travel" to query historical versions of your data for auditing, debugging, and reproducible workflows.
4. Boosting Query Performance:
Iceberg's intelligent metadata structure allows query engines to eliminate scanning unnecessary data. By knowing exactly which files contain the relevant data, it enables highly effective file and partition pruning, leading to dramatically faster query times on large datasets in S3.
5. Championing Openness:
Built as an open specification, Iceberg ensures you're never locked into a single vendor or engine. Your Iceberg tables on S3 are accessible by a wide array of tools – ingestion platforms like OLake, processing engines, and query engines like Trino, Athena, and Spark SQL – providing ultimate flexibility.
This is where the combination of OLake, Apache Iceberg, AWS Glue Data Catalog, and Amazon Athena provides a powerful, simple, and serverless solution.
-
OLake: An open-source tool designed for simple, lightweight, and fast data ingestion from databases
-
Apache Iceberg: A high-performance open table format that brings reliability, schema evolution, and time travel to data files on S3
-
AWS Glue Data Catalog: A centralized, managed metadata repository that can act as the Iceberg catalog, making your S3 data discoverable
-
Amazon Athena: A serverless query engine that can directly query data in S3 using metadata from glue, perfect for interactive analytics
Together, these tools allow you to build an end-to-end pipeline from your database to query-ready data on S3 with minimal infrastructure to manage.
In this Blog we will be diving into the following sections
- Configuring AWS Glue catalog & S3 permissions
- Replicating database data to Apache Iceberg using Olake
- Querying iceberg data using Amazon Athena
Step 1: Configure AWS Glue Catalog and S3 Permissions
To connect OLake to your data lakehouse destination, you need to set up the necessary AWS resources and grant OLake access:
1.1 S3 Bucket:
Create a S3 bucket in your desired region. This will store the apache iceberg data and metadata files.
1.2 Update destination.json
Update your destination.json the with AWS Glue credentials .Ensure your configuration includes the appropriate credentials and region for Glue catalog integration.
1.3 IAM Permissions:
Create an IAM user or role for OLake. Attach a policy granting:
-
S3 Access: Read, write, and list permissions on your specific S3 bucket and path. Refer AWS S3 permissions for details
-
Glue Catalog Access: Permissions to create, get, and update tables/databases within your designated Glue database .
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": [
"glue:CreateTable",
"glue:CreateDatabase",
"glue:GetTable",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:SearchTables",
"glue:UpdateDatabase",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:glue:<aws_region>:<account_id>:catalog",
"arn:aws:glue:<aws_region>:<account_id>:database/{AWS_GLUE_DATABASE_NAME}",
"arn:aws:glue:<aws_region>:<account_id>:table/{AWS_GLUE_DATABASE_NAME}/*"
]
}
]
}
This policy allows OLake to manage data in S3 and register/update table definitions in Glue. Refer to the following doc for more information Glue Catalog Permissions
1.4 AWS Credentials:
Make the credentials for this IAM identity accessible to your OLake environment (e.g., via environment variables when running docker). OLake uses these to authenticate its AWS calls.
By setting up these basic AWS resources and granting OLake the necessary permissions, you create the destination for your database data in your S3-based Iceberg lakehouse, ready to be cataloged by Glue.
OLake integrates with AWS Glue to automatically register iceberg tables, making them queryable in Athena.
Step 2: Data Ingestion from Database to Apache Iceberg Using Olake
2.1 Install Docker
Ensure Docker is installed and running on your local or cloud environment. OLake is Docker-based, making setup fast and portable
2.2 Prepare Your Database
Make sure the source database (e.g., PostgreSQL) is properly configured : Refer to the following doc link Step-by-Step Guide - Replicating PostgreSQL to Iceberg with OLake & AWS Glue
2.3 Configure OLake
You’ll need two configuration files
-
source.jsonfile with your database connection details. -
destination.jsonfile with your Writer (Apache Iceberg) connection details.
You can read here for detailed version OLake Configuration for Postgres
2.4 Discover
Run the Discover command to generate a streams.json file, which contains the list of available data streams from your source database. You can refer to the official OLake documentation for complete documentation
2.5 Sync
Run the Sync command to replicate data from your source database into Apache Iceberg tables stored on Amazon S3
Step 3: Query Iceberg Data Using Amazon Athena
Once OLake has synced data into Iceberg tables and registered them with Glue, you can query it instantly using Amazon Athena
3.1 Open the AWS Console
-
Sign in to your AWS account
-
Search for Athena in the search bar and open the Athena console
3.2 Use the AWS Glue Data Catalog in Athena
-
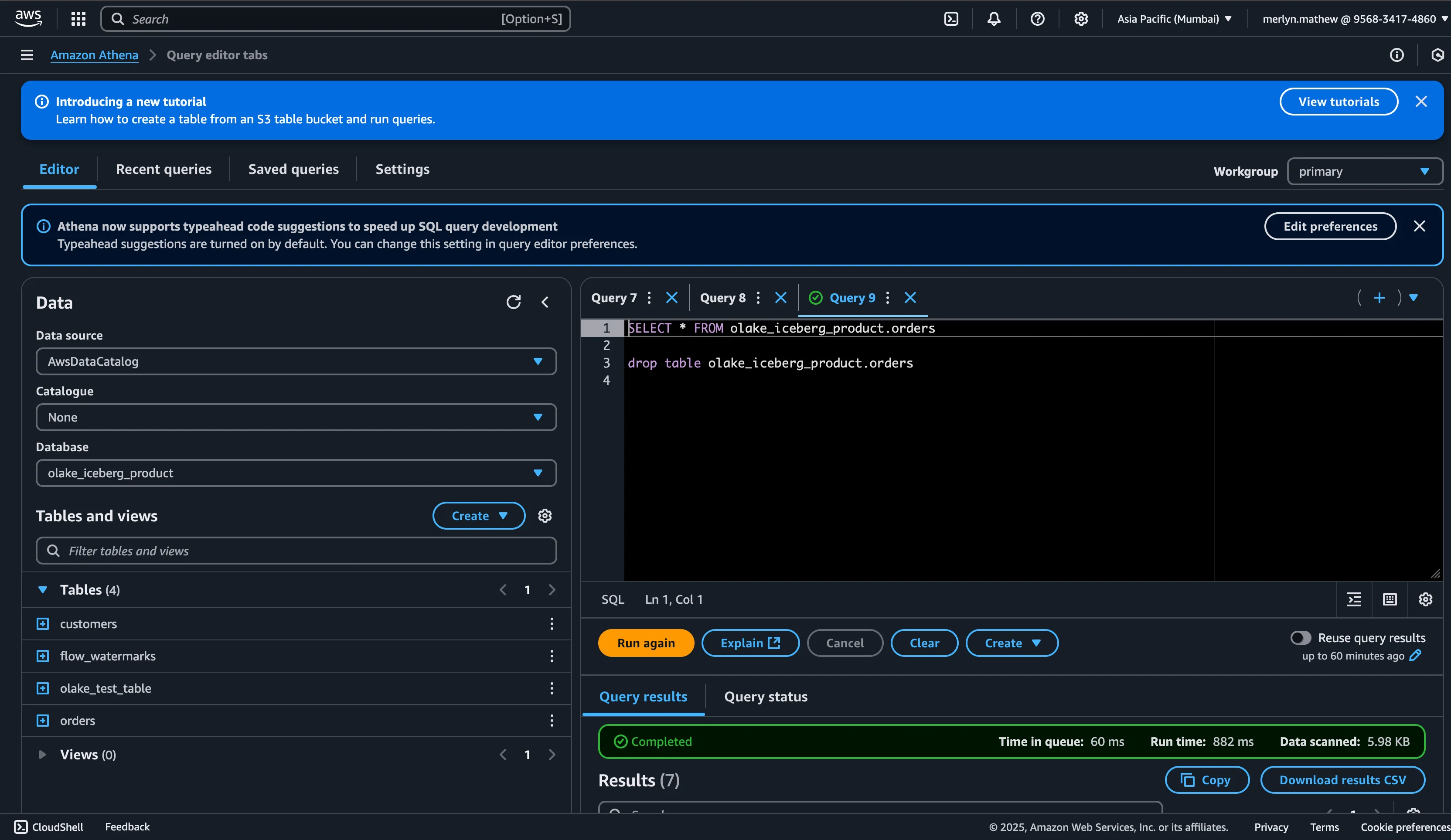
Use the AWS Glue catalog data catalog to connect to your data
-
By default, Athena uses
AwsDataCatalogif Glue is supported in your region. -
Go to the query editor
-
On the left sidebar under Data Source, select
AwsDataCatalog -
Expand the relevant database (as mentioned in the Olake writer cofig file) and tables section to see the Iceberg tables synced by Olake
3.3 Query Your Data
Use standard SQL to explore and analyze your data. Example:
SELECT *
FROM your_database_name.your_table_name
LIMIT 10;
You can run joins, filters, aggregations, and more — all without provisioning a single server
Wrapping Up
With OLake at the core, you can effortlessly create a scalable, cost-effective data lakehouse using open standards and fully managed AWS services.
This powerful combination offers:
-
Real-time data ingestion from databases like MongoDB and PostgreSQL
-
Open table formats powered by Apache Iceberg on Amazon S3
-
Seamless catalog integration using AWS Glue
-
Instant, serverless querying through Amazon Athena
No vendor lock-in. No complex infrastructure. Just fast, flexible, and future-proof analytics—ready to scale as your data grows.
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.