OLake for Simple Iceberg Ingestion using Glue Catalog, Trino for Query

Building a modern data lakehouse and effectively moving data into it from operational databases can often feel like a complex battle. Traditional methods frequently involve creating fragile ETL scripts, managing heavy infrastructure, or relying on expensive, vendor-locked solutions. Getting valuable insights from data residing in systems like MongoDB, PostgreSQL and MySQL shouldn't be hindered by the sheer difficulty of getting that data into your analytics platform.
OLake is an open-source solution built to simplify this process. It makes it easy to move data from your operational databases into a data lake, without the heavy lifting. When combined with Apache Iceberg, OLake brings structure and reliability to your data. Iceberg adds essential features like ACID transactions, schema evolution, and time travel, while storing your data efficiently on low-cost storage like amazon S3. It delivers powerful analytical capabilities directly on your S3 data lake, all while avoiding the complexity and constraints of traditional approaches.
Here’s how iceberg transforms data lakes and simplifies engineering challenges:
Ensuring Data Integrity
Iceberg brings full ACID transaction support to your S3 data lake. That means you can safely run updates, deletes, and merges directly on your data files—something that used to be complicated and error-prone with older data lake formats. This makes processes like change data capture (CDC) and ELT much simpler and more reliable
Handling Changing Data Structures
Your data will evolve over time—and iceberg is built to handle that. It supports schema changes like adding or dropping columns, as well as partition changes, without needing to rewrite all your data or risk breaking existing queries. This flexibility saves time and reduces the risk of errors.
Consistent Reads and Time Travel
Iceberg uses versioned metadata to give you snapshot isolation. That means your queries will return consistent results, even if data is being updated at the same time. You can also "time travel" by querying your data as it existed at a specific point in the past—useful for audits, debugging, and reproducible data science.
Faster Queries
Thanks to its smart metadata, iceberg can quickly figure out which files actually need to be read for a query. This reduces how much data gets scanned and speeds up query performance—especially when working with large datasets in S3.
Open and Flexible Architecture
Iceberg is built as an open standard. You're not locked into a single vendor or toolset. Iceberg tables work with a wide range of technologies—like OLake for ingestion and trino, athena, spark and others for querying. This gives you the freedom to build the architecture that fits your needs.
Why This Combination?
-
OLake: An open-source tool designed for simple, lightweight and fast data ingestion from databases
-
AWS S3: Scalable, durable, and cost-effective object storage for your data lake
-
Apache Iceberg: A high-performance open table format that brings reliability, schema evolution, and time travel to data files on S3
-
AWS Glue Data Catalog: A centralised, managed metadata repository that can act as the iceberg catalog, making your S3 data discoverable
-
Trino: Fast & distributed SQL query engine. Connects to many data sources
Together, these tools allow you to build an end-to-end pipeline from your database to query-ready data on S3 with minimal infrastructure to manage.
Prerequisites:
Before you begin, make sure you have the following:
-
Docker and Docker Compose: Installed and running on your local machine
-
AWS Account: With access to S3 and AWS glue
-
An S3 Bucket: Which will contain your iceberg table data files and metadata files
-
AWS Credentials: Configured on your local machine in a way accessible by the docker container (e.g.,
~/.aws/credentialsfile, environment variables, or if running docker on an EC2 instance, an attached IAM role) -
Trino CLI (optional but recommended): For easily connecting to and querying trino from your terminal
This blog post will guide you through setting up trino locally using docker to query your apache iceberg tables stored in S3, using AWS glue data catalog as the iceberg catalog ingested by OLake .
In this Blog we will be diving into the following sections
-
Configuring AWS glue catalog & S3 permissions
-
Replicating database data to apache iceberg using OLake
-
Querying iceberg data using trino
Step 1: Configure AWS Glue Catalog and S3 Permissions
To connect OLake to your data lakehouse destination, you need to set up the necessary AWS resources and grant OLake access:
1.1 S3 Bucket:
Create a S3 bucket in your desired region. This will store the apache iceberg data and metadata files.
1.2 Update destination.json
Update your destination.json the with AWS Glue credentials .Ensure your configuration includes the appropriate credentials and region for Glue catalog integration.
1.3 IAM Permissions:
Create an IAM user or role for OLake. Attach a policy granting:
-
S3 Access: Read, write, and list permissions on your specific S3 bucket and path. Refer AWS S3 permissions for details
-
Glue Catalog Access: Permissions to create, get, and update tables/databases within your designated Glue database .
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": [
"glue:CreateTable",
"glue:CreateDatabase",
"glue:GetTable",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:SearchTables",
"glue:UpdateDatabase",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:glue:<aws_region>:<account_id>:catalog",
"arn:aws:glue:<aws_region>:<account_id>:database/{AWS_GLUE_DATABASE_NAME}",
"arn:aws:glue:<aws_region>:<account_id>:table/{AWS_GLUE_DATABASE_NAME}/*"
]
}
]
}
This policy allows OLake to manage data in S3 and register/update table definitions in Glue. Refer to the following doc for more information Glue Catalog Permissions
1.4 AWS Credentials:
Make the credentials for this IAM identity accessible to your OLake environment (e.g., via environment variables when running docker). OLake uses these to authenticate its AWS calls.
By setting up these basic AWS resources and granting OLake the necessary permissions, you create the destination for your database data in your S3-based Iceberg lakehouse, ready to be cataloged by Glue.
OLake integrates with AWS Glue to automatically register iceberg tables, making them queryable in Trino.
Step 2: Data Ingestion from Database to Apache Iceberg Using OLake
1 Install Docker
Ensure Docker is installed and running on your local or cloud environment. OLake is docker-based, making setup fast and portable
2 Prepare Your Database
Make sure the source database (e.g., PostgreSQL) is properly configured : Refer to the following doc link Step-by-Step Guide - Replicating PostgreSQL to Iceberg with OLake & AWS Glue
3 Configure OLake
You’ll need two configuration files
-
source.json file with your database connection details
-
destination.json file with your writer (Apache Iceberg) connection details
You can read here for detailed version OLake Configuration
4 Discover
Run the Discover command to generate a streams.json file, which contains the list of available data streams from your source database. You can refer to the official OLake documentation for complete documentation
5 Sync
Run the Sync command to replicate data from your source database into apache iceberg tables stored on amazon S3
Step 3: Set Up Trino Configuration Files
We'll create a local directory structure to hold the trino configuration that we'll mount into the docker container.
mkdir -p trino-config/catalog
cd trino-config
1. Inside trino-config, create the following files :
jvm.config: JVM settings for trino (optional)
-Xmx8G # Allocate 8GB of memory (adjust as needed)
-XX:+UseG1Gc
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
node.properties: Basic node configuration.
Properties
node.id=coordinator # Unique ID for the node
node.environment=production # Environment name
coordinator=true # This node is the coordinator
discovery.uri=http://localhost:8080 # Discovery server address
config.properties: Trino server configuration
Properties
http-server.port=8080
query.max-memory=50GB # Max memory for a query across the cluster
query.max-memory-per-node=10GB # Max memory for a query on a single node
discovery-server.enabled=true
2. Configure the Iceberg Catalog for Glue and S3
Now, navigate into the catalog directory you created (cd catalog). Create a file named iceberg.properties (you can name this file anything ending in .properties; the filename will be your catalog name in trino).
Edit iceberg.properties and add the following configuration:
Properties
connector.name=iceberg ### Name of the connector ###
iceberg.catalog.type=glue ### Type of catalog ###
fs.native-s3.enabled=true
s3.region=<your-aws-region> ### **REQUIRED **: Your AWS region for the S3 bucket ###
Replace <your-aws-region> with your actual AWS region (e.g., us-east-1). Choose and configure one of the S3 authentication methods. Using the default credential provider chain is often the simplest if your AWS environment is already configured (e.g., via environment variables or ~/.aws/credentials).
Explanation:
-
connector.name=iceberg: Tells trino to use the iceberg connector -
iceberg.catalog.type=glue: Instructs the iceberg connector to use AWS glue data catalog to find the iceberg table metadata -
fs.native-s3.enabled=true: Enables trino's native S3 file system support, allowing it to read files directly from S3 -
s3.region: Specifies the region for the S3 bucket containing the data
3. Create the Docker Compose File
Go back to the parent directory (cd ..). Create a docker-compose.yml file:
services:
trino:
image: trinodb/trino:latest
container_name: trino
user: root # Consider if running as root is necessary, often 'trino' user is preferred if image supports it
ports:
- "8080:8080"
volumes:
- ./trino-config:/etc/trino
- ./trino-config/catalog:/etc/trino/catalog
environment:
- AWS_ACCESS_KEY_ID= "<<aws access key id>>"
- AWS_SECRET_ACCESS_KEY= "<<aws secret access key>>"
- AWS_REGION=ap-south-1
4. Launch Trino with Docker Compose
Open your terminal, navigate to the directory containing docker-compose.yml, and run:
docker-compose up -d
This will download the trino docker image (if not already present), create the container, and start the trino coordinator in detached mode
Verify that the container is running:
docker ps
You should see a container named trino with a status of Up. The health status might show starting initially and should eventually change to healthy
5. Connect to Trino and Query Your Iceberg Tables
Now that trino is running and configured, you can connect to it using the trino CLI.
Connect to the trino server running on your local machine's port 8080, specifying the iceberg catalog:
docker exec -it trino trino
Once inside the CLI you will be dropped into a prompt like
trino>
you can interact with your Iceberg tables here:
1. List CATALOGS:
SHOW CATALOGS;
This will show the catalogs , you should be able to see the iceberg catalog that we have added in iceberg.properties file
2. List your databases (schema):
SHOW SCHEMAS FROM <catalog name>;
This displays the list of all the databases that exist in s3
3. List tables in the database:
SHOW TABLES from <catalog name>.<database name>
This should list your iceberg table(s) in the database specified in <database name>.
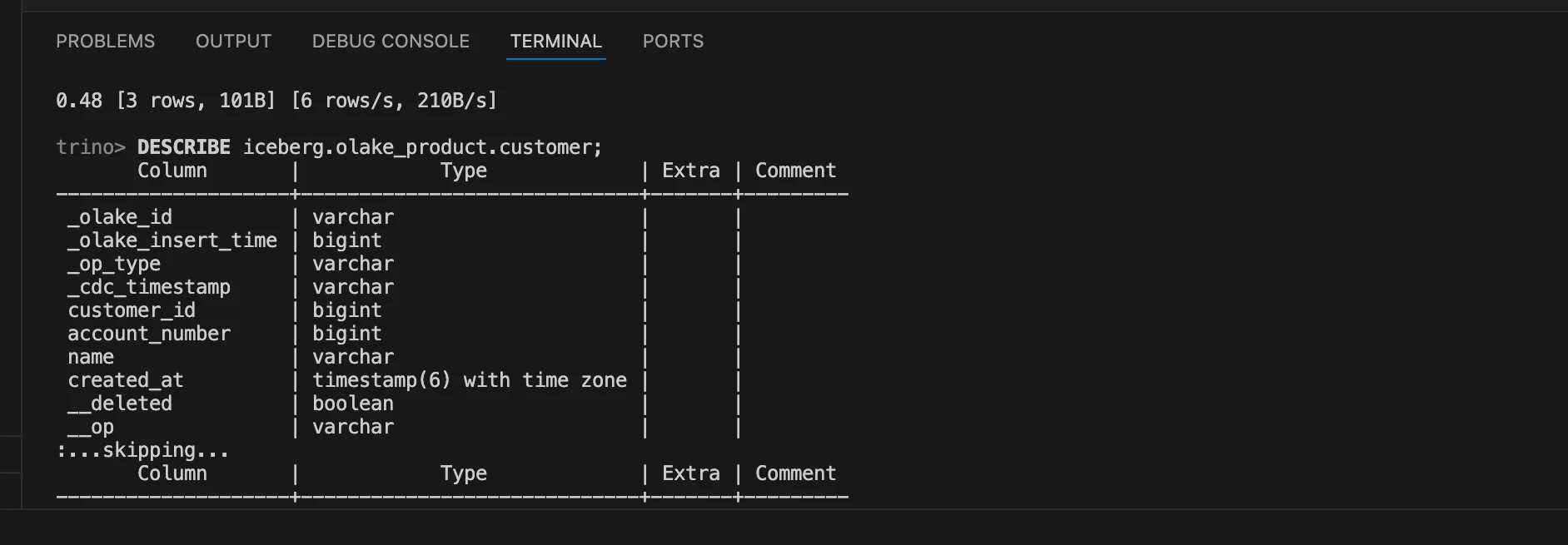
4. Describe your Iceberg table:
DESCRIBE <catalog name>.<database name>.<table name>;
Replace <table name> with the name of your table. You'll see the table schema
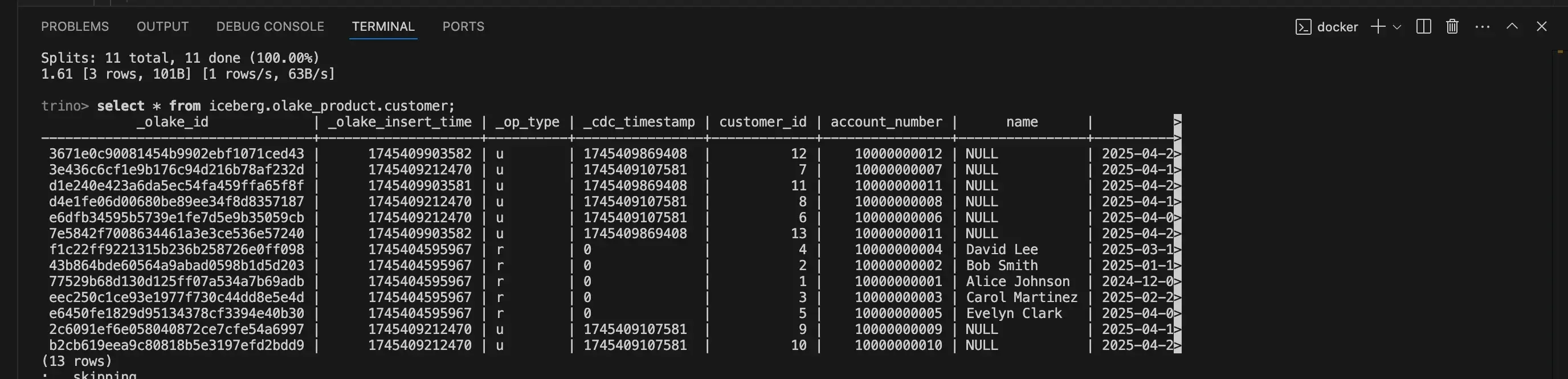
5. Query the table:
SELECT * FROM <your_iceberg_table_name> LIMIT 10;
Replace <your_iceberg_table_name> with your table name. This query will instruct trino to use the iceberg catalog (which uses glue) to find the latest metadata for the table, then use the S3 file system configuration (also in iceberg.properties) to read the necessary metadata and data files from S3 and return the results.
You will be viewing the query results as shown :
6. Exit the CLI:
exit;
How it Works:
When you run a query, trino's iceberg connector performs the following steps:
-
It contacts the configured Iceberg catalog (AWS glue in this case) to find the location of the Iceberg table's metadata files in S3
-
Using the S3 file system configuration provided in the same iceberg.properties catalog file, trino reads the iceberg metadata files from S3 to understand the table's schema, partitioning, snapshots, and the list of data files belonging to the relevant snapshot
-
Based on the query (e.g., filters, column selection), trino identifies the specific data files in S3 it needs to read
-
Using the S3 file system configuration again, trino reads the required portions of the data files directly from S3 and processes them to return the query results
Benefits of this Setup:
-
Simplicity: Docker makes it easy to get trino running without system-wide installations
-
Isolated Environment: Your trino instance runs in a container, not interfering with your host system
-
Direct S3 Access: Queries run directly against data files in S3, leveraging iceberg's performance features
-
Centralized Metadata: Uses your existing AWS glue data catalog
-
Ideal for Development/Testing: Quickly spins up a trino instance to test queries or explore data lake contents
Wrapping Up:
Setting up trino in docker to query iceberg tables in S3 using AWS glue is a powerful and flexible way to interact with your data lake. This local setup is perfect for development, testing, and ad-hoc analysis, giving you the full power of SQL on your open table format data without the overhead of a complex cluster deployment. With your trino container running, you're now ready to unlock the insights within your S3-based Iceberg data lake!
OLake
Achieve 5x speed data replication to Lakehouse format with OLake, our open source platform for efficient, quick and scalable big data ingestion for real-time analytics.